主要發現
相對於2016年的報告,2018年《Top 20 Python AI and Machine Learning projects on Github》報告主要有如下幾個變化:
-
從貢獻者(Contributors)的基數看,Tensorflow已上升至排名第一;Scikit-learn下降至第二,但其貢獻者基數仍很大。
-
從貢獻者數量的增長率看,增長最快的專案分別為:TensorFlow(169%)、Deap(86%)、Chainer(83%)、Gensim(81%)、Neon(66%)、Nilearn(50%)
-
2018年的新專案:Keras(貢獻者數:629)和PyTorch(貢獻者數:399)。
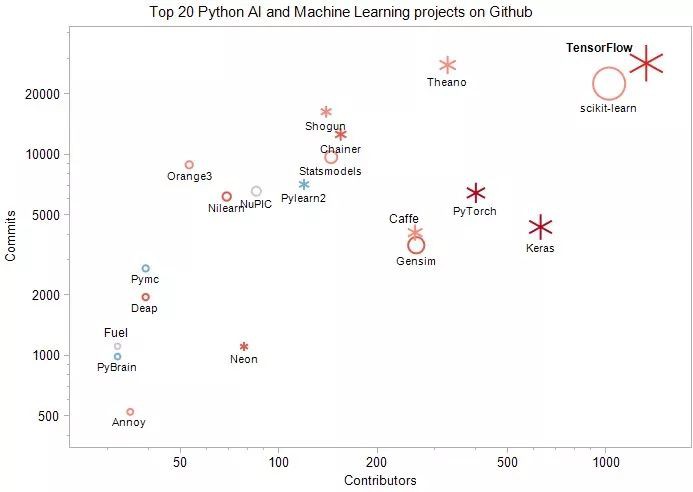
圖中,點的【大小】代表的是貢獻者數量的絕對值;【顏色】代表的是貢獻者數量的變化:紅色越高,藍色越低;【形狀】代表的是專案型別:雪花為深度學習專案。
-
TensorFlow:最初由Google Brain Team研發,旨在促進機器學習方面的科學研究,並使研究原型轉換為生產系統變得快速簡單。Contributors: 1324 (增長168% ), Commits: 28476, Stars: 92359. Github URL: Tensorflow
-
Scikit-learn:建立在NumPy,SciPy和matplotlib等的Python機器學習包。Contributors: 1019 (增長39% ), Commits: 22575, Github URL: Scikit-learn
-
Keras:可以執行在TensorFlow,CNTK或Theano上的一種高層神經網路API。Contributors: 629 (new), Commits: 4371, Github URL: Keras.
-
PyTorch:支援GPU加速的張量和動態神經網路。Contributors: 399 (new), Commits: 6458, Github URL: pytorch.
-
Theano:支援以較高的效率定義,最佳化和評估涉及多維陣列的數學運算式。Contributors: 327 (24% up), Commits: 27931, Github URL: Theano
-
Gensim :一種支援可擴充套件的統計語意,分析用於語意結構的文字檔案,檢索語意相似的檔案等功能的Python庫。Contributors: 262 (81% up), Commits: 3549, Github URL: Gensim
-
Caffe:由伯克利視覺和學習中心(BVLC)和社群貢獻者開發的深度學習框架 Contributors: 260 (21% up), Commits: 4099, Github URL: Caffe
-
Chainer:一種獨立的深度學習框架,以較為靈活,直觀和高效能的方式實現了多種深度學習模型,其中包括最新的模型,如遞迴神經網路和變分自動編碼器。Contributors: 154 (84% up), Commits: 12613, Github URL: Chainer
-
Statsmodels:實現統計學基本功能的模組,Contributors: 144 (33% up), Commits: 9729, Github URL: Statsmodels
-
Shogun:一種機器學習工具箱,以統一與高效的方式實現了機器學習方法,方便整合多種資料表示、演演算法型別和通用工具。Contributors: 139 (32% up), Commits: 16362, Github URL: Shogun
-
Pylearn2:一種是一個機器學習庫,其大部分功能都建立在Theano之上,支援使用數學運算式編寫Pylearn2外掛(新模型,演演算法等)。Contributors: 119 (3.5% up), Commits: 7119, Github URL: Pylearn2
-
NuPIC:基於一種叫做分層時間儲存器(Hierarchical Temporal Memory,HTM)的新大腦皮層理論的探索型專案,目前仍在不斷探索和擴充套件之中。Contributors: 85 (12% up), Commits: 6588, Github URL: NuPIC
-
Neon:Nervana提供的基於Python的深度學習庫,其易用性和效能均為較高。Contributors: 78 (66% up), Commits: 1112, Github URL: Neon
-
Nilearn :一種用於在NeuroImaging資料上進行統計學習的Python模組,它利用scikit-learn Python工具箱進行多變數統計,並提供預測建模,分類,解碼或連線分析等應用。 Contributors: 69 (50% up), Commits: 6198, Github URL: Nilearn
-
Orange3:一種新手和專家均可以使用的機器學習和資料視覺化工具箱,支援互動式資料分析。Contributors: 53 (33% up), Commits: 8915, Github URL: Orange3
-
Pymc: 一種實現貝葉斯統計模型和擬合演演算法的Python模組,包括馬爾可夫鏈蒙特卡羅。Contributors: 39 (5.4% up), Commits: 2721, Github URL: Pymc
-
Deap:一種用於快速原型設計和測試思想的新型演化計算框架。它試圖使演演算法明確,資料結構透明,與多處理和SCOOP等並行機制較好地整合。 Contributors: 39 (86% up), Commits: 1960, Github URL: Deap
-
Annoy(Approximate Nearest Neighbors Oh Yeah):一種用於搜尋接近給定查詢點的空間點。 它還可以建立對映到記憶體的大型只讀基於檔案的資料結構,以便多個行程可以共享相同的資料。 Contributors: 35 (46% up), Commits: 527, Github URL: Annoy
-
PyBrain:一種模組化的機器學習庫,使用簡單,支援使用者測試和分析自己的演演算法。 Contributors: 32 (3% up), Commits: 992, Github URL: PyBrain
-
Fuel:一種資料管道式框架,不僅提供機器學習演演算法,而且還提供所需資料,將由Blocks和Pylearn2神經網路庫使用。 Contributors: 32 (10% up), Commits: 1116, Github URL: Fuel
【特別宣告】本文原作者為KDnuggets的Ilan Reinstein ,來源https://www.kdnuggets.com/2018/02/top-20-python-ai-machine-learning-open-source-projects.html 。由朝樂門翻譯和編輯。
本文轉自:資料科學DataScience 已獲授權;
END
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
