
一、抓取詳細的職位描述資訊
詳情頁分析
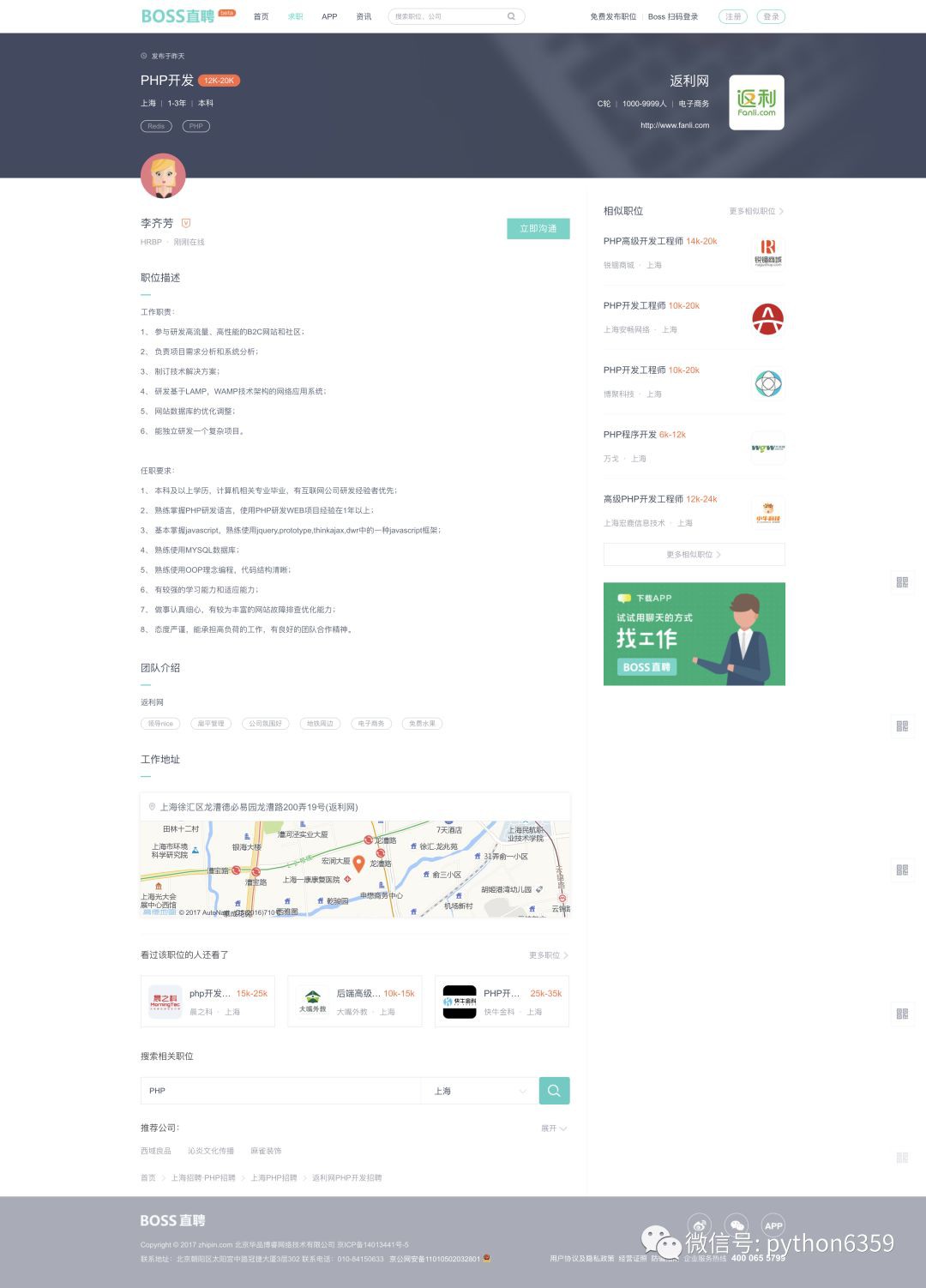
在詳情頁中,比較重要的就是職位描述和工作地址這兩個
由於在頁面程式碼中崗位職責和任職要求是在一個 div 中的,所以在抓的時候就不太好分,後續需要把這個連體嬰兒,分開分析。
爬蟲用到的庫
使用的庫有:
requests
BeautifulSoup4
pymongo
Python 程式碼
"""
@author: jtahstu
@contact: root@jtahstu.com
@site: http://www.jtahstu.com
"""
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
from pymongo import MongoClient
essay-headers = {
'x-devtools-emulate-network-conditions-client-id': "5f2fc4da-c727-43c0-aad4-37fce8e3ff39",
'upgrade-insecure-requests': "1",
'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36",
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
'dnt': "1",
'accept-encoding': "gzip, deflate",
'accept-language': "zh-CN,zh;q=0.8,en;q=0.6",
'cookie': "__c=1501326829; lastCity=101020100; __g=-; __l=r=https%3A%2F%2Fwww.google.com.hk%2F&l;=%2F; __a=38940428.1501326829..1501326829.20.1.20.20; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1501326839; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1502948718; __c=1501326829; lastCity=101020100; __g=-; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1501326839; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1502954829; __l=r=https%3A%2F%2Fwww.google.com.hk%2F&l;=%2F; __a=38940428.1501326829..1501326829.21.1.21.21",
'cache-control': "no-cache",
'postman-token': "76554687-c4df-0c17-7cc0-5bf3845c9831"
}
conn = MongoClient('127.0.0.1', 27017)
db = conn.iApp # 連線mydb資料庫,沒有則自動建立
def init():
items = db.jobs_php.find().sort('pid')
for item in items:
if 'detail' in item.keys(): # 在爬蟲掛掉再此爬取時,跳過已爬取的行
continue
detail_url = "https://www.zhipin.com/job_detail/%s.html?ka=search_list_1" % item['pid']
print(detail_url)
html = requests.get(detail_url, essay-headers=essay-headers)
if html.status_code != 200: # 爬的太快網站傳回403,這時等待解封吧
print('status_code is %d' % html.status_code)
break
soup = BeautifulSoup(html.text, "html.parser")
job = soup.select(".job-sec .text")
if len(job) < 1:
continue
item['detail'] = job[0].text.strip() # 職位描述
location = soup.select(".job-sec .job-location")
item['location'] = location[0].text.strip() # 工作地點
item['updated_at'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 實時爬取時間
res = save(item) # 儲存資料
print(res)
time.sleep(40) # 停停停
# 儲存資料到 MongoDB 中
def save(item):
return db.jobs_php.update_one({"_id": item['_id']}, {"$set": item})
if __name__ == "__main__":
init()
程式碼 easy,初學者都能看懂。
二、資料清洗
2.1 校正釋出日期
"time" : "釋出於03月31日",
"time" : "釋出於昨天",
"time" : "釋出於11:31",
這裡拿到的都是這種格式的,所以簡單處理下
import datetime
from pymongo import MongoClient
db = MongoClient('127.0.0.1', 27017).iApp
def update(data):
return db.jobs_php.update_one({"_id": data['_id']}, {"$set": data})
# 把時間校正過來
def clear_time():
items = db.jobs_php.find({})
for item in items:
if not item['time'].find('布於'):
continue
item['time'] = item['time'].replace("釋出於", "2017-")
item['time'] = item['time'].replace("月", "-")
item['time'] = item['time'].replace("日", "")
if item['time'].find("昨天") > 0:
item['time'] = str(datetime.date.today() - datetime.timedelta(days=1))
elif item['time'].find(":") > 0:
item['time'] = str(datetime.date.today())
update(item)
print('ok')
2.2 校正薪水以數字儲存
'''
"salary" : "5K-12K",
#處理成下麵的格式
"salary" : {
"low" : 5000,
"high" : 12000,
"avg" : 8500.0
},
'''
# 薪水處理成數字,符合 xk-yk 的資料處理,不符合的跳過
def clear_salary():
items = db.jobs_lagou_php.find({})
for item in items:
if type(item['salary']) == type({}):
continue
salary_list = item['salary'].lower().replace("k", "000").split("-")
if len(salary_list) != 2:
print(salary_list)
continue
try:
salary_list = [int(x) for x in salary_list]
except:
print(salary_list)
continue
item['salary'] = {
'low': salary_list[0],
'high': salary_list[1],
'avg': (salary_list[0] + salary_list[1]) / 2
}
update(item)
print('ok')
這裡在處理 Boss 直聘的資料時,比較簡單正常,但是後續抓到拉勾網的資料,拉勾網的資料有些不太規範。比如有‘20k以上’這種描述
2.3 根據 工作經驗年限 劃分招聘等級
# 校正拉勾網工作年限描述,以 Boss直聘描述為準
def update_lagou_workyear():
items = db.jobs_lagou_php.find({})
for item in items:
if item['workYear'] == '應屆畢業生':
item['workYear'] = '應屆生'
elif item['workYear'] == '1年以下':
item['workYear'] = '1年以內'
elif item['workYear'] == '不限':
item['workYear'] = '經驗不限'
update_lagou(item)
print('ok')
# 設定招聘的水平,分兩次執行
def set_level():
items = db.jobs_zhipin_php.find({})
# items = db.jobs_lagou_php.find({})
for item in items:
if item['workYear'] == '應屆生':
item['level'] = 1
elif item['workYear'] == '1年以內':
item['level'] = 2
elif item['workYear'] == '1-3年':
item['level'] = 3
elif item['workYear'] == '3-5年':
item['level'] = 4
elif item['workYear'] == '5-10年':
item['level'] = 5
elif item['workYear'] == '10年以上':
item['level'] = 6
elif item['workYear'] == '經驗不限':
item['level'] = 10
update(item)
print('ok')
這裡有點坑的就是,一般要求經驗不限的崗位,需求基本都寫在任職要求裡了,所以為了統計的準確性,這個等級的資料,後面會被捨棄掉。

轉載宣告
作者:jtahstu
源自:http://www.jtahstu.com/blog/scrapy_zhipin_detail.html

