序言:Adam自2014年出現之後,一直是受人追捧的引數訓練神器,但最近越來越多的文章指出:Adam存在很多問題,效果甚至沒有簡單的SGD + Momentum好。因此,出現了很多改進的版本,比如AdamW,以及最近的ICLR-2018年最佳論文提出的Adam改進版Amsgrad。那麼,Adam究竟是否有效?改進版AdamW、Amsgrad與Adam之間存在什麼聯絡與區別?改進版是否真的比Adam更好呢?相信這篇文章將會給你一個清晰的答案。
Adam Roller-Coaster
Adamoptimizer的發展歷程就像坐過山車一樣。Adam最先於2014年提出,其核心是一個簡單而直觀的想法:當我們知道某些引數確實需要比其他引數移動地更快時,為什麼要對每個引數都使用相同的學習速率呢?由於最近的梯度的平方告訴我們可以從每個權重得到多少資訊,我們可以除以這一點,以確保即使變化最緩慢的權重也能獲得發光的機會。Adam借鑒了這個思路,在標準方法裡面加入了動量,並且(透過一些調整來保持早期Bathes不被biased)就是這樣!
Adam首次釋出後,深度學習社群在看到原始論文中的效果圖(下圖)之後,非常的興奮:

Adam和其他optimizer之間的比較
訓練速度加快了200%!“總的來說,我們發現Adam非常強大,非常適合解決機器學習的各種非凸最佳化問題” 論文總結道。但是,那是三年前了,是一個深度學習發展的一個黃金epochs。但也漸漸逐漸清晰,這一切並不如我們所希望的那樣。實際情況是,很少有研究論文使用Adam來訓練他們的模型,一些新的研究,如《The Marginal Value of Adaptive Gradient Methods in Machine Learning》建議不要使用Adam,並透過多個實驗中表明,傳統的SGD+momentum的方法得到的結果更好。
但是在2017年底,Adam似乎獲得了新生。Ilya Loshchilov和Frank Hutter在他們的論文《Fixing Weight Decay Regularization in Adam》中指出,所有的深度學習庫中的Adam optimizer中實現的weight decay方法似乎都是錯誤的,並提出了一種簡單的方法(他們稱之為AdamW)來解決它。儘管他們的結果略有不同,但從下圖的效果對比圖中可以發現,結果令人振奮,:
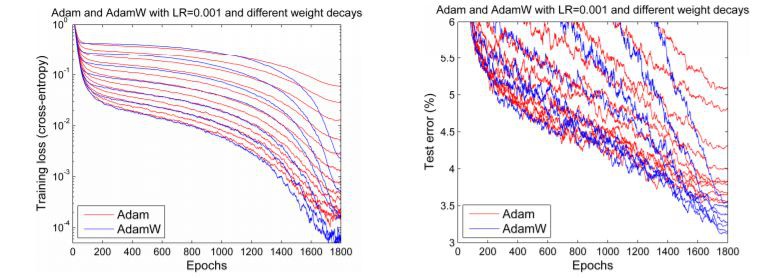
Adam和AdamW的對比
我們當然期待看到Adam的回歸,因為似乎最初的結果可能會再次被髮現。但事情並非如此。實際上,所有深度學習框架中,只有fastai,由Sylvain編寫的程式碼中的的演演算法實現修複了這一bug。如果沒有廣泛的框架可用性,大多數人仍舊會被old、“broken”adam所困擾。
但這不是唯一的問題。未來會遇到更多的問題。兩篇相互獨立的論文都明確指出並證明瞭Adam中存在的收斂性問題,儘管其中一人聲稱修複了這一問題(並獲得了ICLR-2018年的“最佳論文”獎),他們的演演算法稱為Amsgrad。但是,如果我們是否從這個最具戲劇性的歷史生活中學到了任何東西(至少在optimizer standards上是戲劇性的)呢?看起來似乎並沒有。事實上,博士生Jeremy Bernstein 已經指出,聲稱的收斂問題實際上只是因為超引數的選擇不當導致的,而且無論如何,Amsgrad也許無法解決這一問題。另一名博士生Filip Korzeniowski展示了一些早期的結果,這些結果似乎也支援這種關於Amsgrad的,令人沮喪的觀點。
脫離Roller-coaster
那麼對於我們這些只想快速且準確訓練模型的人來說,我們該怎麼辦呢?讓我們用經曆數百年時間的,科學的方式來解決這場爭論:透過實驗!我們會在短時間內告訴你所有細節,首先,給出一個結果概述:
· 適當調整,Adam是真的有效!我們在各種任務上都獲得了最新的成績(就訓練時間而言)
o 在DAWNBench競賽中,通訓練CIFAR10達到> 94%的準確度,評測當採用Augmentation時,只需要18個epoch;或不採用Augmentation時,只需要30個epochs;
o 採用Cars Stanford Dataset資料集,訓練60個epochs,fine-tuning Resnet50達到90%的精確度(之前達到相同的結果需要600 epochs);
o 從頭開始訓練AWD LSTM或QRNN,需要90個epochs(或單個GPU上需要1個半小時),在Wikitext-2資料集上的達到state-of-the-art的perplexity(之前的report的對於LSTM需要750個epochs,對於QRNN需要500個epochs)。
· 這意味著我們已經看到(我們第一次意識到)在論文《Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates》使用Adam所獲得的超級收斂效果(Super-Convergence)!超級收斂是在採用較大的學習率訓練神經網路時發生的一種現象,使訓練速度加快一倍。在瞭解這一現象之前,將CIFAR10訓練達到94%的準確度大約需要100個epochs。
· 與之前的工作相比,我們看到Adam在我們嘗試過的每個CNN影象問題上獲得與SGD + Momentum一樣的精確度,只要它經過適當調整,並且它幾乎總是更快一點。
· Amsgrad是一個糟糕的“fix”的這一suggestion是正確的。我們一直發現,與普通的Adam / AdamW相比,Amsgrad在準確度(或其他相關指標)方面沒有獲得任何提升。
當你聽到有人們說Adam沒有像SGD + Momentum那樣generalize的時候,你幾乎總會發現,根本原因使他們為他們的模型選擇了較差的超引數。Adam通常需要比SGD更多的regularization,因此在從SGD切換到Adam時,請務必調整正則化超引數。
以下是本文其餘部分的概述:
1 AdamW
1.1 瞭解AdamW
1.2 實現AdamW
1.3 AdamW實驗的結果
2 Amsgrad
2.1 瞭解Amsgrad
2.2 實現Amsgrad
2.3 Amsgrad實驗的結果
3 完整結果表
1 AdamW
1.1 瞭解AdamW:weight decay or L2正規?
L2正則是一種減少過擬合的一種經典方法,它在損失函式中加入對模型所有權重的平方和,乘以給定的超引數(本文中的所有方程都使用python,numpy,和pytorch表示):
final_loss = loss + wd * all_weights.pow(2).sum() / 2
…其中wd是要設定的l2正則的超引數。這也稱為weight decay,因為在應用普通的SGD時,它相當於採用如下所示來更新權重:
w = w – lr * w.grad – lr * wd * w
(註意,w 2相對於w的導數是2w。)在這個等式中,我們看到我們如何在每一步中減去一小部分權重,因此成為衰減。
我們檢視過的所有深度學習庫,都使用了第一種形式。(實際上,它幾乎總是透過向gradients中新增wd * w來實現,而不是去改變損失函式:我們不希望在有更簡單的方法時,透過修改損失來增加更多計算量。)
那麼為什麼要區分這兩個概念,它們是否起到了相同的作用呢?答案是,它們對於vanilla SGD來說是一樣的東西,但只要我們在公式中增加動量項,或者使用像Adam這樣更複雜的一階或二階的optimizer,L2正則化(第一個等式)和權重衰減(第二個等式)就會變得不同。在本文的其餘部分,當我們談論weight decay時,我們將始終參考第二個公式(梯度更新時,稍微減輕權重)並談談L2正則化,如果我們想提一下經典的方法。
以SGD + momentum為例。使用L2正則化,並新增wd * w衰減項到公式中(如前所述),但不直接從權重中減去梯度。首先我們計算移動平均值(moving average):
moving_avg = alpha * moving_avg + (1-alpha) * (w.grad + wd*w)
…這個移動平均值將乘以學習率並從w中減去。因此,與將從w取得的正則化相關聯的部分是lr *(1-alpha)* wd * w加上前一步的moving_avg值。
另一方面,weight decay的梯度更新如下式:
moving_avg = alpha * moving_avg + (1-alpha) * w.grad w = w – lr * moving_avg – lr * wd * w
我們可以看到,從與正則化相關聯的w中減去的部分在兩種方法中是不同的。當使用Adam optimizer時,它會變得更加不同:在L2正則化的情況下,我們將這個wd * w新增到gradients,然後計算gradients及其平方值的移動平均值,然後再使用它們進行梯度更新。而weight decay的方法只是在進行更新,然後減去每個權重。
顯然,這是兩種不同的方法。在嘗試了這個之後,Ilya Loshchilov和Frank Hutter在他們的文章中建議我們應該使用Adam的權重衰減,而不是經典深度學習庫實現的L2正則化方法。
1.2 實現AdamW
我們應該怎麼做?基於fastai庫為例,具體來說,如果使用fit函式,只需新增引數 use_wd_sched = True:
learn.fit(lr, 1, wds=1e-4, use_wd_sched=
True)
如果您更喜歡新的API,則可以在每個訓練階段使用引數wd_loss = False(計算損失函式時,不使用weight decay):
phases = [TrainingPhase(1, optim.Adam, lr, wds=1-e4, wd_loss=False)]
learn.fit_opt_sched(phases)
以下給出基於fast庫的一個簡單實現。在optimizer的step函式的內部,只使用gradients來更新引數,根本不使用引數本身的值(除了weight decay,但我們將在外圍處理)。然後我們可以在optimizer處理之前,簡單地執行權重衰減。在計算梯度之後仍然必須進行相同操作(否則會影響gradients值),所以在訓練迴圈中,你必須找到這個位置。
loss.backward()
#Do the weight decay here!
optimizer.step()
當然,optimizer應該設定為wd = 0,否則它會進行L2正則化,這正是我們現在不想要的。現在,在那個位置,我們必須迴圈所有引數,並做weight decay更新。你的引數應該都在optimizer的字典param_groups中,因此迴圈看起來像這樣:
loss.backward()
for group in optimizer.param_groups():
for param in group[‘params’]:
param.data = param.data.add(-wd * group[‘lr’], param.data)
optimizer.step()
1.3 AdamW實驗的結果:它有效嗎?
我們在計算機視覺問題上第一次進行測試得到的結果非常令人驚訝。具體來說,我們採用Adam+L2正規化在30個epochs內獲得的準確率(這是SGD透過去1 cycle policy達到94%準確度所需要的必要時間)的平均為93.96%,其中一半超過了94%。使用Adam + weight decay則達到94%和94.25%之間。為此,我們發現使用1 cycle policy時,beta2的最佳值為0.99。我們將beta1引數視為SGD的動量(意味著它隨著學習率的增長從0.95變為0.85,然後當學習率變低時再回到0.95)。

L2正則化或權重衰減的準確性
更令人印象深刻的是,使用Test Time Augmentation(即對測試集上的一個影象,取四個和他相同data-augmented版本的預測的平均值作為最終預測結果),我們可以在18個epochs內達到94%的準確率(平均預測值為93.98%) )!透過簡單的Adam和L2正規,超過20個epochs時,達到94%。
在這些比較中要考慮的一件事是,改變我們正則的方式會改變weight decay或學習率的最佳值。在我們進行的測試中,L2正則化的最佳學習率是1e-6(最大學習率為1e-3),而0.3是weight decay的最佳值(學習率為3e-3)。在我們的所有測試中,數量級的差異非常一致,主要原因是,L2正則於梯度的平均範數(相當小)相除後,變得非常有效,且Adam使用的學習速率非常小(因此,weight decay的更新需要更強的繫數)。
那麼,使用Adam時,權重衰減總是比L2正規化更好嗎?我們還沒有發現一個明顯更糟的情況,但對於遷移學習問題或RNN而言(例如在Stanford cars資料集上對Resnet50進行微調),它沒有獲得更好的結果。
2 Amsgrad
2.1 瞭解Amsgrad
最近 Sashank J. Reddi,Satyen Kale和Sanjiv Kumar 在ICLR-2018的最佳論文《On the Convergence of Adam and Beyond》了中提出了Amsgrad。透過分析Adam optimizer的收斂證明,他們發現更新規則中的存在錯誤,且可能導致演演算法收斂到sub-optimal point。他們設計了理論實驗,展示了Adam失敗的場景,並提出了一個簡單的解決方案。
為了理解錯誤和修複,讓我們先看看Adam的更新公式:
avg_grads = beta1 * avg_grads + (1-beta1) * w.grad
avg_squared = beta2 * (avg_squared) +
(1-beta2) * (w.grad ** 2)
w = w – lr * avg_grads / sqrt(avg_squ
ared)
我們剛剛忽略了bias項(對訓練開始時很有用),專註於重點。作者發現的Adam的proof中的存在的錯誤是它需要值(quantity)
lr / sqrt(avg_squared)
…這是我們在平均梯度方向上採取的step,隨著訓練過程減少。由於學習率通常是恆定的或降低的(除了像我們這樣,試圖獲得超收斂的瘋狂的人),作者提出的修正是透過新增另一個變數來跟蹤他們的最大值來強制avg_squared值增加。
2.2 實現Amsgrad
相關文章獲得了ICLR 2018的最佳論文獎,並非常受歡迎,以至於它已經在兩個主要的深度學習庫都實現了,pytorch和Keras。除了使用Amsgrad = True開啟選項外,幾乎沒有什麼可做的。
這將上一節中的權重更新程式碼更改為以下內容:
avg_grads = beta1 * avg_grads + (1-beta1) * w.grad
avg_squared = beta2 * (avg_squared) +
(1-beta2) * (w.grad ** 2)
max_squared = max(avg_squared,
max_squared)
w = w – lr * avg_grads / sqrt(max_squ
ared)
2.3 Amsgrad實驗的結果:除了很多噪音意外什麼也沒有
事實證明,Amsgrad結果令人失望。在我們的實驗中,沒有一個實驗證明它是有點幫助的,即使確實Amsgrad發現的最小值有時略低於(在損失方面)Adam達到的指標(精度,f1得分) …)最終結果總是惡化(參見我們的introduction,或更多的例子:https://fdlm.github.io/post/amsgrad/)
Adam optimizer在深度學習中的收斂性證明(proof of convergence)(因為它是針對凸問題的)以及它們在其中發現的錯誤對於與現實生活中的實際問題無關的合成實驗來說是至關重要的。實際測試表明,當avg_squared gradients想要減少時,最好的結果是這樣做。
這表明,即使關註理論可以獲得一些新想法,但它也不能取代實驗(以及很多實驗!)來確保這些想法能真正幫助從業者訓練出更好的模型。
附錄:完整結果
從頭開始訓練CIFAR10(模型是一個比較寬的resnet 22,最終的結果是五個測試集上測平均錯誤率):

在Stanford Cars資料集上,對Resnet50進行微調(前20個epochs不改變學習率,後40個epochs採用不同的學習率學習):

使用github repo中的超引數訓練AWD LSTM (結果顯示驗證/測試集的perplexity,有或沒有快取指標(cache pointer)):

QRNN相同,不採用LSTM:

對於這項特定任務,我們使用了1cycle policy的修改版本,更快地增加學習速率,然後在再次下降之前具有更長時間的高恆定學習速率。

Adam和其他optimizer之間的比較
https://github.com/sgugger/Adam-experime
nts提供了所有相關超引數的值以及用於得到這些結果的程式碼。
往期精彩內容推薦
AI教父-深度學習之父-Geffery Hinton個人簡介
精品推薦-2018年Google官方Tensorflow峰會影片教程完整版分享
模型彙總24 – 深度學習中Attention Mechanism詳細介紹:原理、分類及應用



DeepLearning_NLP


深度學習與NLP
商務合作請聯絡微訊號:lqfarmerlq
