
作者:醬油哥,清華程式猿、IT非主流
專欄地址:https://zhuanlan.zhihu.com/c_147297848
要點搶先看
1.csv資料的讀取
2.利用常用函式獲取均值、中位數、方差、標準差等統計量
3.利用常用函式分析價格的加權均值、收益率、年化波動率等常用指標 4.處理資料中的日期
我們最後會介紹一下NumPy庫中的一些非常實用和常用的函式方法。
要知道,NumPy的常用數學和統計分析的函式非常多,如果我們一個一個的分散來講,一來非常枯燥,二來呢也記不住,就彷彿又回到了昏昏欲睡的課堂,今天我們用一個背景例子來串聯一下這些零散的知識點。
我們透過分析蘋果公司的股票價格,來串講NumPy的常用函式用法
我們在我們python檔案的同級目錄下放置資料檔案AAPL.csv,用excel檔案可以開啟看看裡面是什麼樣的:

依次是日期,收盤價、成交量、開盤價、最高價和最低價 在CSV檔案中,每一列資料資料是被“,”隔開的,為了突出重點簡化程式,我們把第一行去掉,就像下麵這樣
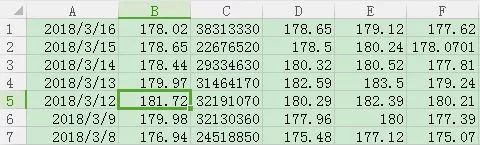
首先,我們讀取“收盤價”和“成交量”這兩列,即第1列和第2列(csv也是從第0列開始的)
import numpy as np
c, v = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1, 2), unpack=True)
print(c)
print(v)
[ 178.02 178.65 178.44 179.97 181.72 179.98 176.94 175.03 176.67 176.82 176.21 175. 178.12 178.39 178.97 175.5 172.5 171.07 171.85 172.43 172.99 167.37 164.34 162.71 156.41 155.15 159.54 163.03 156.49 160.5 167.78 167.43 166.97 167.96 171.51 171.11 174.22 177.04 177. 178.46 179.26 179.1 176.19 177.09 175.28 174.29 174.33 174.35 175. 173.03 172.23 172.26 169.23 171.08 170.6 170.57 175.01 175.01 174.35 174.54 176.42]
[ 38313330. 22676520. 29334630. 31464170. 32191070. 32130360. 24518850. 31686450. 23273160. 27825140. 38426060. 48706170. 37568080. 38885510. 37353670. 33772050. 30953760. 37378070. 33690660. 40113790. 50908540. 40382890. 32483310. 60774900. 70583530. 54145930. 51467440. 68171940. 72215320. 85957050. 44453230. 32234520. 45635470. 50565420. 39075250. 41438280. 51368540. 32395870. 27052000. 31306390. 31087330. 34260230. 29512410. 25302200. 18653380. 23751690. 21532200. 20523870. 23589930. 22342650. 29461040. 25400540. 25938760. 16412270. 21477380. 33113340. 16339690. 20848660. 23451420. 27393660. 29385650.]
這樣,我們就完成了第一個任務,將csv資料檔案中儲存的資料,讀取到我們兩個ndarray陣列c和v中了。
接下來,我們小試牛刀,對收盤價進行最簡單的資料處理,求取他的平均值。
第一種,非常簡單,就是我們最常見到的算數平均值
import numpy as np
c, v = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1, 2), unpack=True)
mean_c = np.mean(c) print(mean_c)
172.614918033
第二種,是加權平均值,我們用成交量來加權平均價格
即,用成交量的值來作為權重,某個價格的成交量越高,該價格所佔的權重就越大。
import numpy as np
c, v = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1, 2), unpack=True)
vwap = np.average(c, weights=v)
print(vwap)
170.950010035
再來說說取值範圍,找找最大值和最小值
我們找找收盤價的最大值和最小值,以及最大值和最小值之間的差異
import numpy as np
c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True)
print(np.max(c))
print(np.min(c))
print(np.ptp(c))
181.72
155.15
26.57
接下來我們進行簡單的統計分析
我們先來求取收盤價的中位數
import numpy as np
c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True)
print(np.max(c))
print(np.min(c))
print(np.median(c))
181.72
155.15
174.35
求取方差
另外一個我們關心的統計量就是方差,方差能夠體現變數變化的程度。在我們的例子中,方差還可以告訴我們投資風險的大小。那些股價變動過於劇烈的股票一定會給持有者帶來麻煩
import numpy as np
c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True)
print(np.var(c))
37.5985528621
我們回顧一下方差的定義,方差指的是各個資料與所有資料算數平均數的離差平方和的均值
import numpy as np
c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True)
print(np.mean((c - c.mean())**2))
37.5985528621
上下對比一下,看看,結果是一模一樣的。
現在我們來看看每天的收益率,這個計算式子很簡單: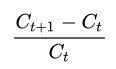 ,即用今天的收盤價減去昨天的收盤價,再除以昨天的收盤價格。同時我們發揮NumPy的優勢,利用向量運算,可以一次性算出所有交易日的收益率
,即用今天的收盤價減去昨天的收盤價,再除以昨天的收盤價格。同時我們發揮NumPy的優勢,利用向量運算,可以一次性算出所有交易日的收益率
diff函式時用陣列的第N項減第N-1項,得到一個n-1項的一維陣列。本例中我們註意到陣列中日期越近的收盤價,陣列索引越小,因此得取一個相反數,綜上程式碼:
import numpy as np
c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True)
returns = -np.diff(c)/c[1:]
print(returns)
[-0.00352645 0.00117687 -0.00850142 -0.0096302 0.00966774 0.01718097 0.01091242 -0.00928284 -0.00084832 0.00346178 0.00691429 -0.01751628 -0.00151354 -0.00324077 0.01977208 0.0173913 0.00835915 -0.00453884 -0.00336368 -0.00323718 0.0335783 0.01843739 0.01001782 0.04027875 0.00812117 -0.02751661 -0.0214071 0.04179181 -0.02498442 -0.04339015 0.00209043 0.00275499 -0.00589426 -0.0206985 0.00233768 -0.01785099 -0.0159286 0.00022599 -0.00818111 -0.00446279 0.00089336 0.01651626 -0.00508216 0.01032634 0.00568019 -0.00022945 -0.00011471 -0.00371429 0.01138531 0.00464495 -0.00017416 0.01790463 -0.01081365 0.0028136 0.00017588 -0.02536998 -0. 0.00378549 -0.00108858 -0.01065639]
然後觀察一下每日收益的標準差,就可以看看收益的波動大不大了:
import numpy as np
c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True)
returns = -np.diff(c)/c[1:]
print(np.std(returns))
0.0150780328454
如果我們想看看哪些天的收益率是正的,很簡單,還記得where陳述句嗎,拿來使用吧
import numpy as np
c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True)
returns = -np.diff(c)/c[1:]
print(np.where(returns>0))
(array([ 1, 4, 5, 6, 9, 10, 14, 15, 16, 20, 21, 22, 23, 24, 27, 30, 31, 34, 37, 40, 41, 43, 44, 48, 49, 51, 53, 54, 57], dtype=int64),)
專業上我們對價格變動可以用一個叫做“波動率”的指標進行度量。計算歷史波動率時需要用到對數收益率,對數收益率很簡單,就是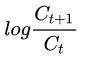 ,依照對數的性質,他等於
,依照對數的性質,他等於 ,在計算年化波動率時,要用樣本中所有的對數收益率的標準差除以其均值,再除以交易日倒數的平方根,一年交易日取252天。
,在計算年化波動率時,要用樣本中所有的對數收益率的標準差除以其均值,再除以交易日倒數的平方根,一年交易日取252天。
我們簡單的看一下下麵的程式碼
import numpy as np
c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(1,), unpack=True)
logreturns = -np.diff(np.log(c))
volatility = np.std(logreturns) / np.mean(logreturns)
annual_volatility = volatility / np.sqrt(1./252.)
print(volatility)
print(annual_volatility)
100.096757388
1588.98676256
這裡我們再強調一點就是:sqrt方法中應用了除法計算,這裡必須使用浮點數進行運算。月度波動率也是同理用1./12.即可
我們可以常常會發現,在資料分析的過程中,對於日期的處理和分析也是一個很重要的內容。
我們先試圖用老辦法來從csv檔案中把日期資料讀出來
import numpy as np
dates,c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(0,1), unpack=True)
Traceback (most recent call last):
File "E:/12homework/12homework.py", line 2, in
dates,c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(0,1), unpack=True)
File "C:\Python34\lib\site-packages\numpy\lib\npyio.py", line 930, in loadtxt
items = [conv(val) for (conv, val) in zip(converters, vals)]
File "C:\Python34\lib\site-packages\numpy\lib\npyio.py", line 930, in
items = [conv(val) for (conv, val) in zip(converters, vals)]
File "C:\Python34\lib\site-packages\numpy\lib\npyio.py", line 659, in floatconv
return float(x)
ValueError: could not convert string to float: b'2018/3/16'
我們發現他報錯了,錯誤資訊是不能將一個位元組型別的物件轉換為浮點型別物件。原因是因為NumPy是面向浮點數運算的,那麼我們對症下藥,對日期字串進行一些轉換處理。
我們先假定日期是一個字串型別(下載的網路資料中往往是將字串透過utf-8編碼成位元組碼,這個可以見第一季中字元編碼相關內容的介紹)
import numpy as np import datetime
strdate = '2017/3/16'
d = datetime.datetime.strptime(strdate,'%Y/%m/%d')
print(type(d))
print(d)
<class 'datetime.datetime'>
2017-03-16 00:00:00
透過python標準庫中的datetime函式包,我們透過指定匹配的格式%Y/%m/%d
將日期字串轉換為了datetime型別物件,Y大寫匹配完整的四位數記年,y小寫就是兩位數,例如17。
datetime物件有一個date方法,把datetime物件中的time部分去掉,變成一個純的日期,再呼叫weekday可以轉換為一週中的第幾天,這裡是從週日開始算起的。
import numpy as np import datetime
strdate = '2018/3/16'
d = datetime.datetime.strptime(strdate,'%Y/%m/%d')
print(d.date())
print(d.date().weekday())
2018-03-16 4
最後,我們回到這份蘋果公司股價的csv檔案,來做一個綜合分析,來看看周幾的平均收盤價最高,周幾的最低:
import numpy as np import datetime
def datestr2num(bytedate):
return datetime.datetime.strptime(
bytedate.decode('utf-8'),'%Y/%m/%d').date().weekday()
dates,c = np.loadtxt('AAPL.csv', delimiter=',', usecols=(0,1),
converters={0: datestr2num}, unpack=True)
averages = np.zeros(5)
for i in range(5):
index = np.where(dates == i)
prices = np.take(c, index)
avg = np.mean(prices)
averages[i] = avg print("Day {} prices: {},avg={}".format(i,prices,avg))
top = np.max(averages)
top_index = np.argmax(averages)
bot = np.min(averages)
bot_index = np.argmin(averages)
print('highest:{}, top day is {}'.format(top,top_index))
print('lowest:{},bottom day is {}'.format(bot,bot_index))
Day 0 prices: [[ 181.72 176.82 178.97 162.71 156.49 167.96 177. 174.35 176.42]],avg=172.49333333333334
Day 1 prices: [[ 179.97 176.67 178.39 171.85 164.34 163.03 166.97 177.04 176.19 174.33 172.26 170.57 174.54]],avg=172.78076923076924
Day 2 prices: [[ 178.44 175.03 178.12 171.07 167.37 159.54 167.43 174.22 179.1 174.29 172.23 170.6 174.35]],avg=172.44538461538463
Day 3 prices: [[ 178.65 176.94 175. 172.5 172.99 155.15 167.78 171.11 179.26 175.28 173.03 171.08 175.01]],avg=172.59846153846152
Day 4 prices: [[ 178.02 179.98 176.21 175.5 172.43 156.41 160.5 171.51 178.46 177.09 175. 169.23 175.01]],avg=172.71923076923073
highest:172.78076923076924, top day is 1
lowest:172.44538461538463,bottom day is 2
簡要的再分析一下:由於從csv中讀取的資料型別為bytes,所以我們寫了一個轉換函式,先將bytes型別的日期資料進行解碼(字串編解碼詳見第一季),然後再用上一段程式介紹的方法轉換為一個表示周幾的數字
而np.loadtxt函式中的引數converters={0: datestr2num},就是說針對第一列的資料,我們利用這個轉換函式將其轉化為一個數字,並將這個整形元素構成的陣列賦值給dates變數。
後面的處理就很簡單了,用迴圈依次取出每個工作日的收盤價構成的陣列,對其求平均值。然後得到週一到週五,五個平均值的最大值、最小值。
最後我們再介紹兩個實用函式,一個是陣列的裁剪函式,即把比給定值還小的值設定為給定值,比給定值大的值設定為給定上限
import numpy as np
a = np.arange(5)
print(a.clip(1,3))
[1 1 2 3 3]
第二個是一個篩選函式,傳回一個根據給定條件篩選後得到的結果陣列
import numpy as np
a = np.arange(5)
print(a.compress(a > 2))
[3 4]
這一小節中,我們利用NumPy的一些實用函式,對蘋果公司的股價進行了一些非常非常簡單的分析,目的是透過這個實體來串講一下這些實用的資料處理函式。
其實NumPy的功能非常非常多,遠不止這些,但是沒有必要去一個一個學。並且另一方面,NumPy的方法都過於原始和底層,雖然功能很豐富,但是使用起來也很繁雜。這裡我們為大家打一個基礎,後面的章節就不會再一一介紹裡面的各種函式了。後面我要介紹基於NumPy之上的一些更高層的方法庫,功能更強大,使用也更簡單。
《Python人工智慧和全棧開發》2018年07月23日即將在北京開課,120天衝擊Python年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
- END -


更多Python好文請點選【閱讀原文】哦
↓↓↓
