

在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @Cratial。本文是東京大學發表於 CVPR 2018 的工作,論文提出了基於域適應的弱監督學習策略,在源域擁有充足的實體級標註的資料,但標的域僅有少量影象級標註的資料的情況下,盡可能準確地實現對標的域資料的物體檢測。
如果你對本文工作感興趣,點選底部閱讀原文即可檢視原論文。
關於作者:吳仕超,東北大學碩士生,研究方向為腦機介面、駕駛疲勞檢測和機器學習。
■ 論文 | Cross-Domain Weakly-Supervised Object Detection through Progressive Domain Adaptation
■ 連結 | https://www.paperweekly.site/papers/2106
■ 原始碼 | https://github.com/naoto0804/cross-domain-detection
引出主題
雖然深度學習技術在物體檢測方面取得了巨大的成功,但目前的物體檢測技術主要面向的物件是真實場景下的影象,而對於像水彩畫這種非真實場景下的物體檢測任務來說,一般很難獲取大量帶有標註的資料集,因此物體檢測問題就變得比較棘手。
為解決這一問題,本文提出了基於域適應的弱監督學習策略,其可以描述為:(1)選取一個帶有實體級標註的源域資料;(2)僅有影象級標註的標的域資料;(3)標的域資料的類別是源域資料類別的全集或子集。
論文的任務就是在源域擁有充足的實體級標註的資料,但標的域僅有少量影象級標註的資料的情況下,盡可能準確地實現對標的域資料的物體檢測。這個任務的難點主要在於標的域沒有實體級的標註,因此無法直接利用標的資料集對基於源資料集訓練的模型進行微調。
針對這一問題,作者提出了兩種解決方法:
1. 域遷移(domain transform,DT):即利用影象轉換技術,如CycleGAN將源域資料轉換為和標的資料相似的帶有實體級的影象;
2. 偽標記(pseudo-labeling,PL):利用偽標記來對標的域資料產生偽實體級標註。兩種方法如圖 1 所示:
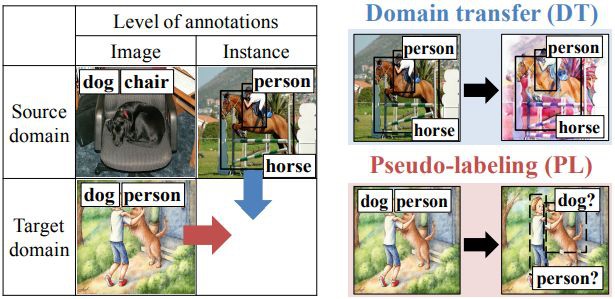
▲ 圖1
為驗證該策略的有效性,作者分別採集並手工標註了三個分別具有實體級標註的標的資料集:Clipart1k,Watercolor2k,Comic2k。
資料集及程式碼見:
https://naoto0804.github.io/cross_domain_detection/
資料集描述
筆者認為這篇文章最大的貢獻之處不僅僅在於其提出的基於弱監督學習的標的檢測方法,更重要的是作者所建立的資料集,為將來這方面工作的進行提供了資料支援。

▲ 圖2
在本文中,作者選取的源域資料集為 PASCAL VOC 資料集,同時作者收集並標註了 3 個標的域資料集,其示例如圖 2 所示。資料集的具體資訊如表 1 所示:

▲ 表1
方法
本文的方法如圖 3 所示,首先我們對源域影象進行域遷移訓練得到域遷移影象,然後對於基於源域資料集訓練得到的模型,再透過域遷移影象對模型進行微調,最後再使用透過偽標記方法獲取的資料對模型進行進一步的微調。

▲ 圖3
域遷移(DT)
正如前面所提到的,本文主要解決的問題是標的域和源域分佈不同的標的檢測問題,而這部分旨在透過變換將源域資料分佈變換為標的域分佈,本文作者使用的是 CycleGAN [1] 來實現這種變換。
偽標記(PL)
對於只用影象級標註(即每個影象上包含哪幾種類別)的標的域資料集,我們需要獲取其偽實體級標註。首先,對於標的域資料中的每一幅影象 x ,使用基於源域訓練的模型得到輸出 d=(p,b,c) ,其中 b 是得到的 bounding box, c 是得到的類別, p 是屬於該類的機率。根據這個結果,對於影象中所包含的每個類別,透過選取 top-1 機率的結果來作為標的影象的 bounding box,從而來實現對標的影象的偽標註。
實驗
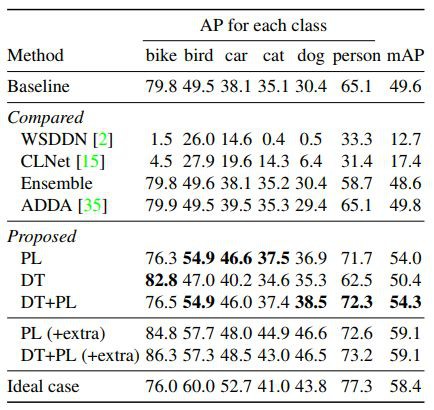
為證明方法的有效性,作者分別利用 PL、DT、DT+PL 的微調方法進行了實驗,在 Clipart1k 資料集上的實驗結果如表2所示。其中,基線(Baseline)是利用 SSD300 直接在標的域影象上進行實驗的結果,而理想情況(Ideal case)是利用帶實體級標註的標的域資料對模型進行微調的結果。此外,作者還利用基於弱監督檢測的方法 ContextLocNet [2]、WSDDN [3] 及無監督域適應的方法 ADDA [4] 來做對比實驗。

▲ 表2
從表 2 可以看出,作者提出的微調策略能夠在檢測效能上有較大的提升。此外,從表 2 中可以看出經過 DT 變換的微調方法可以很大程度地提升檢測效能,而在不使用影象級標註的 PL 資料域進行微調的方法不僅不能提高效能,而且會導致效能有所下降,所以影象級的標簽對物體檢測是很重要的。
此外,作者在 YOLOv2 及 Faster R-CNN 上進行了同樣的實驗,實驗結果同樣證明瞭該微調策略的有效性。實驗結果如表 3 所示:
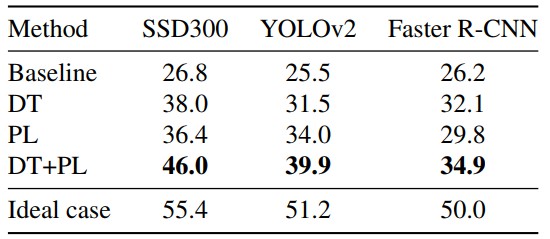
▲ 表3
為驗證本文方法的有效性,作者採用論文 [5] 提供的方法對檢測效果進行分析,分析結果如圖 4 所示。從圖中可以看出基於 DT 變換的微調模型能夠很好的提高物體檢測的效能,相對於 DT 來說,基於 DT+PL 的微調策略能夠進一步地提高檢測的效能,尤其是在容易將物體誤分成不相似類別物體的分類任務上(Sim 將物體識別成與該物體類似但不相同的類別,Oth 將物體識別成其他不相似的類別)。這也進一步說明瞭為何影象級標註可以提高物體檢測的效能。

▲ 圖4
此外,作者還對另外兩個資料集進行了實驗,實驗結果分別如表 4、5 所示:
▲ 表4

▲ 表5
總結
在本文中,作者為將當前的物體檢測技術應用到一些非現實場景,即缺少大量實體級標註的場景,如水彩畫的標的檢測等任務,而提出了一套全新的訓練策略,並建立了一些資料集來為將來這方面的工作做鋪墊。筆者認為這項工作是非常有意義的,就人本身而言,我們不僅可以很好地分辨實際場景中的物體,同樣可以很好地檢測到一些例如動畫、水彩畫中的物體,即使有時我們很少接觸這些,而基於深度學習的物體檢測技術也應該具備這種能力。
參考文獻
[1]. J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image- to-image translation using cycle-consistent adversarial net- works. In ICCV, 2017.
[2]. V. Kantorov, M. Oquab, M. Cho, and I. Laptev. Context- LocNet: Context-aware deep network models for weakly supervised localization. In ECCV, 2016.
[3]. H. Bilen and A. Vedaldi. Weakly supervised deep detection networks. In CVPR, 2016.
[4]. E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. In CVPR, 2017.
[5]. D. Hoiem, Y. Chodpathumwan, and Q. Dai. Diagnosing error in object detectors. In ECCV, 2012.
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視原論文
