作者:Jose A Dianes ;翻譯:季洋 ;校對:丁楠雅
本文約5822字,建議閱讀20+分鐘。
本系列將介紹如何在現在工作中用兩種最流行的開源平臺玩轉資料科學。先來看一看資料分析過程中的關鍵步驟 – 探索性資料分析。
內容簡介
本系列將介紹如何在現在工作中用兩種最流行的開源平臺玩轉資料科學。本文先來看一看資料分析過程中的關鍵步驟 – 探索性資料分析(Exploratory Data Analysis,EDA)。
探索性資料分析發生在資料收集和資料清理之後,而在資料建模和分析結果視覺化展現之前。然而,這是一個可反覆的過程。做完某種EDA後,我們可以嘗試建立一些資料模型或者生成一些視覺化結果。同時,根據最新的分析結果我們又可以進行進一步的EDA,等等。所有的這些都是為了更快地找到線索,而不用糾結在資料細節和美觀上。EDA的主要目的是為了瞭解我們的資料,瞭解它的趨勢和質量,同時也是為了檢查我們的假設甚至開始構建我們的假設演演算法。
瞭解了以上內容,我們將解釋如何用描述統計學、基本繪圖和資料框來回答一些問題,同時指導我們做進一步的資料分析。
這系列教程的所有程式碼和應用程式可以從GitHub(https://github.com/jadianes/data-science-your-way)中得到。你可以隨意參與並同我們分享你的進度。
準備資料
我們將繼續使用在介紹資料框時已經裝載過的相同的資料集。因此你可以接著資料框相關教程繼續這個章節,或者重新學習資料準備教程 (https://www.codementor.io/python/tutorial/python-vs-r-for-data-science-data-frames-i)。
我們要回答的問題
在任何的資料分析過程中,總有一個或多個問題是我們要回答的。定義這些問題,是整個資料分析過程中最基本也是最重要的一個步驟。因為我們要在我們的結核病資料集中做探索性資料分析,有一些問題需要我們回答:
-
哪些國家擁有最高傳染性結核病發病率?
-
從1990年到2007年世界結核病的總體趨勢是什麼?
-
哪些國家沒有符合這個趨勢?
-
還有哪些關於這個疾病的真相可以從我們的資料中得到?
描述性統計
Python
在Python中,對一個pandas.DataFrame物件的基本的描述性統計方法是describe()。它等同於R語言中data.frame的summary()方法。
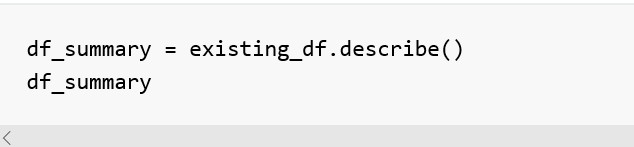
這裡列出了所有列的統計資訊,我們可以用以下方法來訪問每個列的彙總資訊:


Pandas包中有多得可怕的描述性統計方法(可參照檔案http://pandas.pydata.org/pandas-docs/stable/api.html#api-dataframe-stats)。其中一部分已經包含在了我們的summary物件中,但是還有更多的方法不在其中。在接下來的教程中我們將好好的利用它們來更好的瞭解我們的資料。
例如,我們可以得到西班牙(Spain)每年結核病發病量的變化百分比:


同時從以上結果得到最大值:

也可以對英國(United Kingdom)做同樣的操作:

如果我們要瞭解索引值(year),我們用argmax 方法(或Pandas新版本中的idmax呼叫方法)如下:
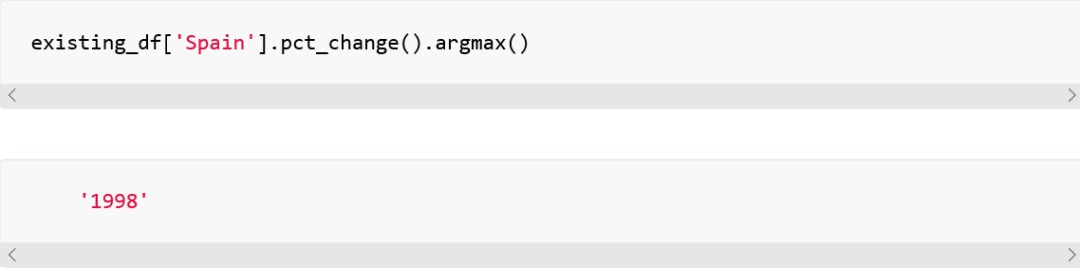
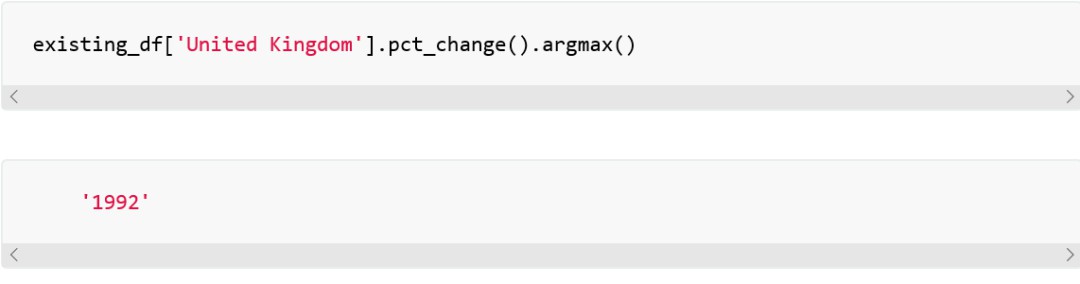
也就是說,1998年和1992年分別是西班牙和英國肺結核發病量增長最糟糕的年。
R
在R語言中基本的描述性統計方法,如我們說過的,是summary()。

這個方法傳回一個表格物件,使我們擁有了一個包含各列統計資訊的資料框。表格物件有利於我們觀察資料,但作為資料框卻不利於我們訪問和索引資料。基本上,我們是把它當作矩陣,透過坐標位來訪問其中的資料。透過這種方法,如果我們要得到第一列,Afghanistan的相關資料,我們該這樣做:

有個竅門可以透過列名訪問資料,那就是將原始資料框中的列名和which()方法一起使用。我們還可以在結果集上構建一個新的資料框。
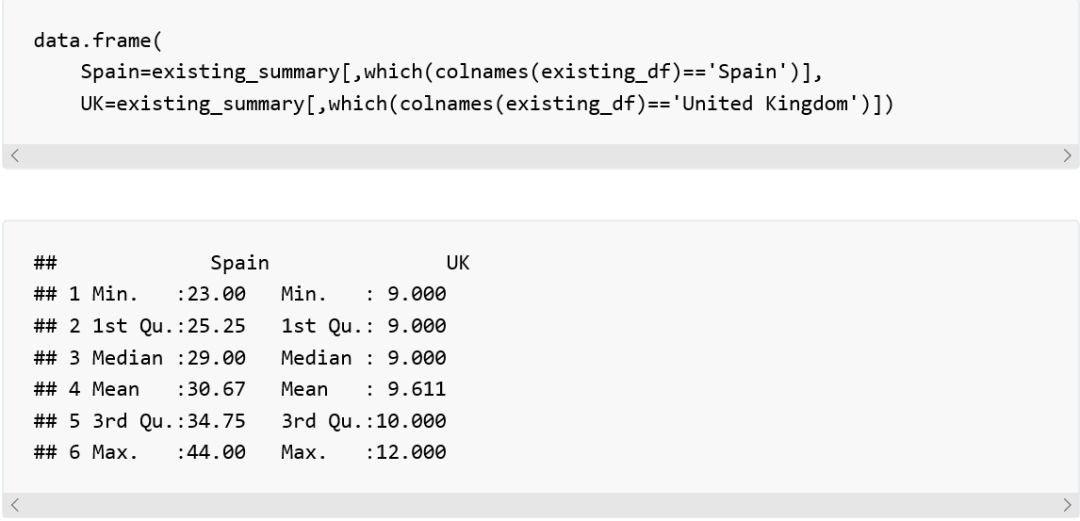
R做為一種函式式語言,我們可以對向量使用函式方法例如sum、 mean、 sd等等。記住一個資料框就是一個向量的串列(也就是說各個列都是一個值的向量),如此我們便可以很容易地用這些函式作用於列上。最終我們將這些函式和lapply或sapply一起使用並作用於資料框的多列資料上。
不管怎樣,在R語言中有一家族的函式可以作用於列資料或行資料上以直接得到均值或和值。這樣做比用apply函式更有效,並且還允許我們將他們不光用在列資料上,更可用在行資料上。例如,你輸入‘?colSums’命令,幫助頁面會彈出所有這些函式的描述性說明。
比如我們想得到每年的平均病發量,我們只需要一個簡單的函式呼叫:

圖表繪製
在這個章節中我們要看一看在Python/Pandas和R中的基本的繪圖製表功能。然而,還有其它如ggplot2(http://ggplot2.org/)這樣繪圖功能更強大語言包可以選擇。ggplot2最初是為R語言建立的,Yhat(https://yhathq.com/)的人又提供了它的Python語言的實現(http://ggplot.yhathq.com/)。
Python
Pandas包中DataFrame物件實現的即時可用的作圖方法有3個之多(請參閱檔案http://pandas.pydata.org/pandas-docs/stable/api.html#id11。)第一個方法是一個基本的線圖繪製,作用於索引中的連續變數。當我們用IPython notebook工具繪圖時,這第一條線也許我們會用得著:


或者我們可以用箱線圖來得到給定連續變數的摘要檢視:


還有一個histogram()方法,但是我們現在還不能將它作用於我們這種型別的資料。
R
和ggplot2相比,R語言的基礎繪圖不是非常精密複雜,但它還是功能強大同時又操作便利的。它的很多資料型別都自定義並實現了plot()方法,可以允許我們簡單地呼叫方法對它們進行繪圖。然而並不總是如此便利,更多的情況是我們需要將正確的元素集傳給我們的基礎繪圖函式。
正像之前用Python/Pandas繪製線型圖,我們也從基礎的線型圖繪製開始:


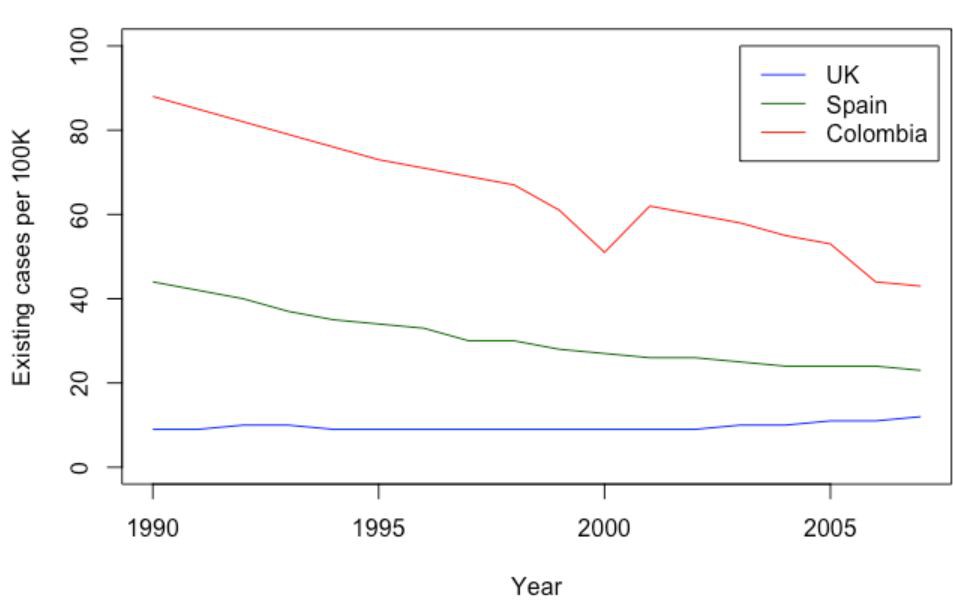
你可以比較出在Pandas中繪製三條連續變數線型圖是多麼容易,而用R的基礎繪圖繪製相同的圖程式碼是多麼冗長。我們至少需要三個函式呼叫,先是為了圖形和線,然後還有圖的標註,等等。R語言的基本繪圖的真正用意就是繪製快速而不完善的圖。
現在讓我們來使用箱線圖:

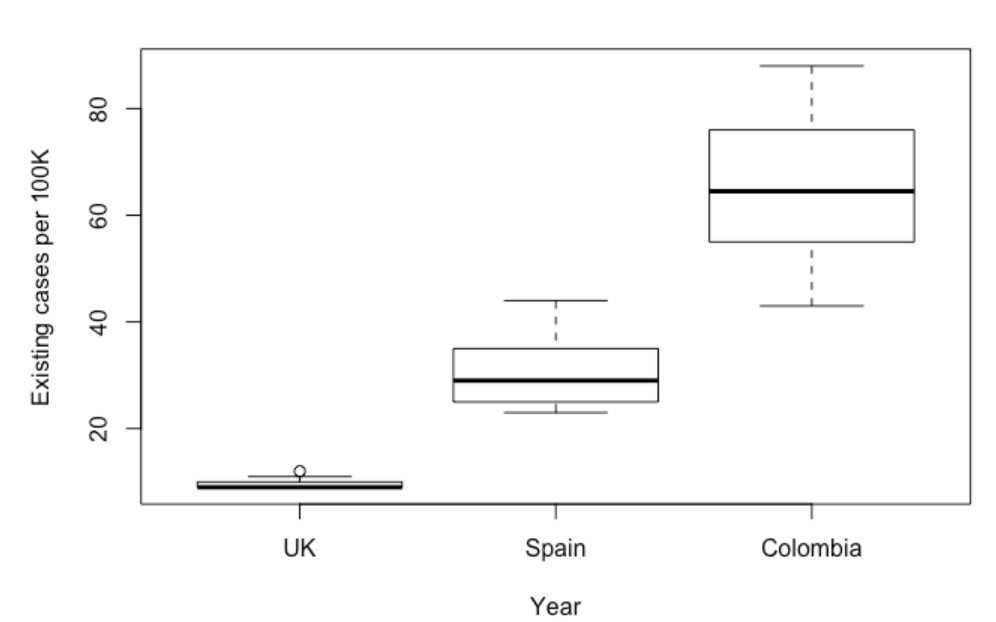
這是一段簡短的箱線圖程式碼,我們甚至沒有要圖的顏色和圖例說明。
回答問題
現在讓我們開始正真好玩的章節。一旦我們瞭解了我們的工具(從之前的資料框教程到當下這個教程),我們就可以用它們來回答關於傳染性肺結核病在全球的發病率和盛行率的一些問題。
問題:我們想知道,每年,哪個國家存在的、新的傳染性肺結核病例最多?
Python
如果我們只是想得到病例最多的國家,我們可以利用apply和argmax函式。記住,預設的,apply作用於列資料(在我們的例子裡是國家列),而我們希望它作用於每一年。如此這樣,我們需要在使用資料框之前顛倒它的行列位置,或傳入引數axis=1。


但是這樣做過分簡單了。另外,我們要得到的是位於最後四分割槽的國家。而我們首先要做的是找出全球的總的發病趨勢。
全球傳染性肺結核發病趨勢:
為了探索全球總趨勢,我們需要對三個資料集中所有國家的每年的資料分別求和。

現在我們要建立一個新的資料框,裡麵包含各個之前得到的和集,然後用資料框的plot()方法進行繪圖。



看上去全球每十萬人中現存病例總數歷年來呈整體下降趨勢。然而新的病例總數呈上升趨勢,雖然2005年後好像有所下降。所以怎麼可能在新的病例總數增長的情況下現存病例總數下降呢?其中一個原因可能是我們可以在圖中觀察到的上升的每十萬人的因病死亡人數,但是我們不得不考慮其主要原因是因為人們得到了治療而恢復了健康。康復率加上死亡率大於新的病發率。總之,看上去新的發病率增加了,而同時我們治癒它們的水平也更好了。我們需要改進預防措施和傳染病控制能力。
超出整體趨勢的國家
所以之前是全球作為一個整體的總趨勢。那麼哪些國家呈現不同的趨勢呢(更糟糕)?為了找出這些國家,首先我們需要瞭解每個國家平均年死亡率的分佈情況。

我們可以畫出這些分佈圖從而瞭解這些國家年平均分佈情況。


我們要得到那些機率大於四分位間距(IQR、50%)1.5倍的國家。
先得到上限值:

現在我們可以利用這些值來得到從1990年到2007年平均機率大於這些上限值的國家。

我們有多少比例的國家是超出整體趨勢的?對於死亡率:


對於存在病率(患病率):


對於新病率(發生率):


現在我們可以用這些指標來對我們原始的資料框做篩選。

這是一個嚴肅的事情。根據傳染性肺結核病的分佈,我們有超過全球三分之一的國家在現存病率、新病率和死亡率上超出普遍機率。然而如果我們以四分位間距(IQR)的5倍為上限呢?讓我們重覆之前的過程。

那麼現在的比例是多少呢?


讓我們得到相應的資料框。

讓我們把註意力放在傳染病控制上,來看一看這個新的資料框:


讓我們生成一些圖表來加深一下印象。



我們有了22個國家,在這些國家中新病的年平均率大於全球新病率中間值的5倍。讓我們建立一個國家代表了這22個國家的平均值:


現在讓我們再建立一個國家代表了其它國家的平均值:


現在讓我們用這兩個平均國家繪圖:


新病率的增長趨勢在平均特超國家(超出上限的22個國家的平均值代表)上非常顯著,這麼顯著的趨勢很難在改善國家(22個國家之外的其它國家的平均值代表)中觀察到。在90年代,這些國家的傳染性肺結核病的發病數量有一個可怕的上漲。然而讓我們看一下真實的資料。


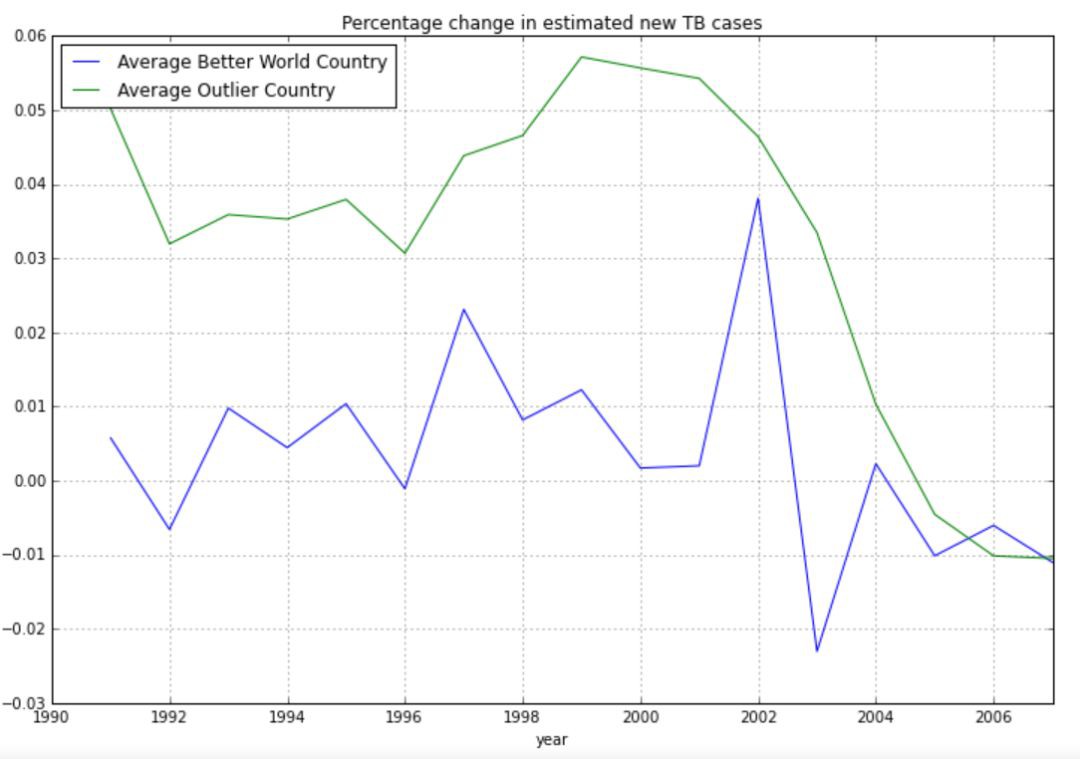
根據這張圖,改善和異常國家的發病率增長趨勢在同一時間發生了相同的波動和恢復,並且在大約2002年的時候有事情發生。在下一章節中我們將嘗試找出到底發生了什麼。
R
我們已經瞭解到在R中我們可以用max函式作用於資料框的列上以得到列的最大值。額外的,我們還可以用which.max來得到最大值的位置(等同於在Pandas中使用argmax)。如果我們使用行列換位的資料框,我們可以用函式lapply或sapply對每一個年列進行操作,然後得到一串列或一向量的指標值(我們將會用sapply函式傳回一個向量)。我們只需要做一點微調,利用一個包含國家名的向量來使操作傳回國家名而不是國家所在的位置。


全球傳染性肺結核發病趨勢:
再次,為了探索全球的總趨勢,我們需要將三個資料集中的所有國家的數值按年相加。
但是首先我們需要載入另外兩個資料集以得到死亡數量和新病數量。
以下截圖資料下載連結不完整,分別為:https://docs.google.com/spreadsheets/d/12uWVH_IlmzJX_75bJ3IH5E-Gqx6-zfbDKNvZqYjUuso/pub?gid=0&output;=CSV
https://docs.google.com/spreadsheets/d/1Pl51PcEGlO9Hp4Uh0x2_QM0xVb53p2UDBMPwcnSjFTk/pub?gid=0&output;=csv
同時現在是按行求和。我們需要將傳回的數字向量轉化為資料框。

現在我們可以用目前我們已經學到的技巧來繪出各線圖。為了得到一個包含各總數的向量以傳給每個繪圖函式,我們使用了以列名為索引的資料框。
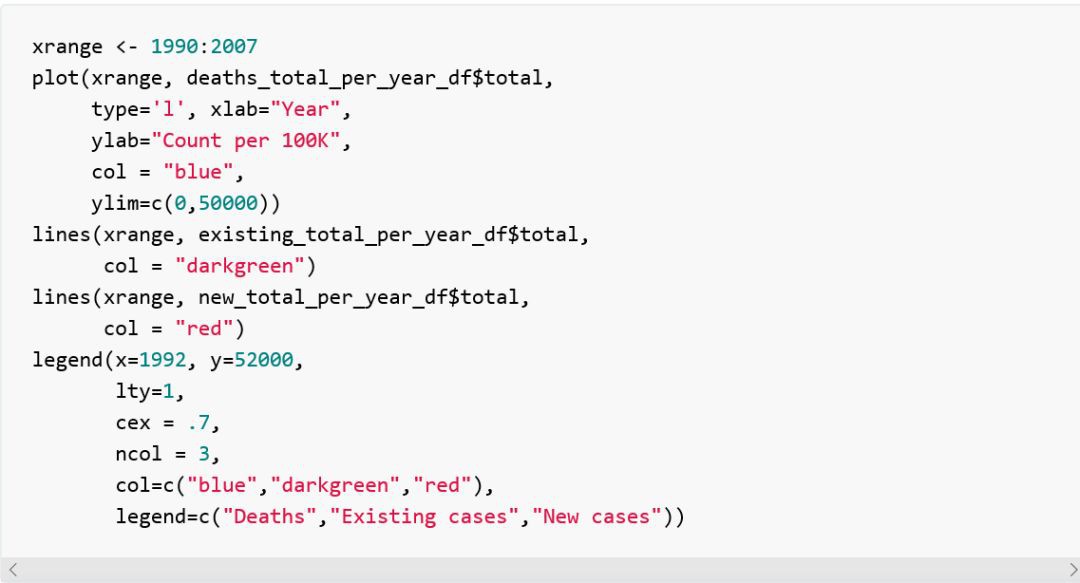

從上圖中得到的結論顯然和我們用Python時得到的相同。
超出整體趨勢的國家:
所以哪些國家是超出整體趨勢的呢(更糟糕)?再一次,為了找出答案,我們首先需要瞭解每個國家的年平均分佈情況。我們用函式colMeans 以達到目的。

我們可以繪製出分佈圖以對各個國家的年平均值的分佈情況有所瞭解。我們對單個國家不是非常感興趣,我們感興趣的是分佈情況本身。


再一次我們可以在圖上看到有三部分走勢,開始部分緩慢地上升,接下來第二部分上升走勢,最後一個尖起的峰值明顯地不同於其它部分。
這次讓我們跳過1.5倍的四分位間距部分,直接來到5倍四分位間距。在R語言中,我們要採用不同的方法。我們將使用函式quantile()來得到四分位間距從而判斷離群值的臨界值。
因為我們已經從Python章節中知道了結果,讓我們只對新病率找出離群國家,如此一來我們要再次繪製之前的圖。

離群比例:


讓我們從中得到一個資料框,只包含離群的國家資訊。

現在我們已經準備好了繪製圖形。


我們可以明顯看到使用Pandas基本繪圖與R基本繪圖的優勢!
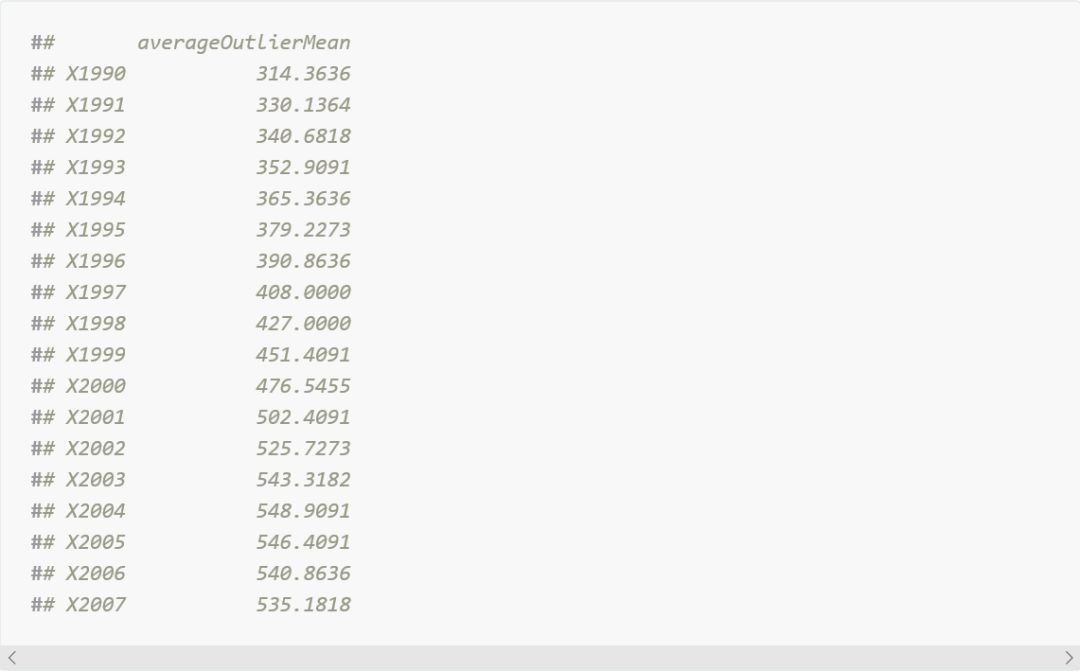
到目前為止結果是相符的。我們有22個國家,平均每年的新病例數大於分佈中值的5倍。讓我們來建立一個國家代表這個平均值,在這裡我們使用rowMeans()。

現在讓我們建立一個國家代表其他國家。

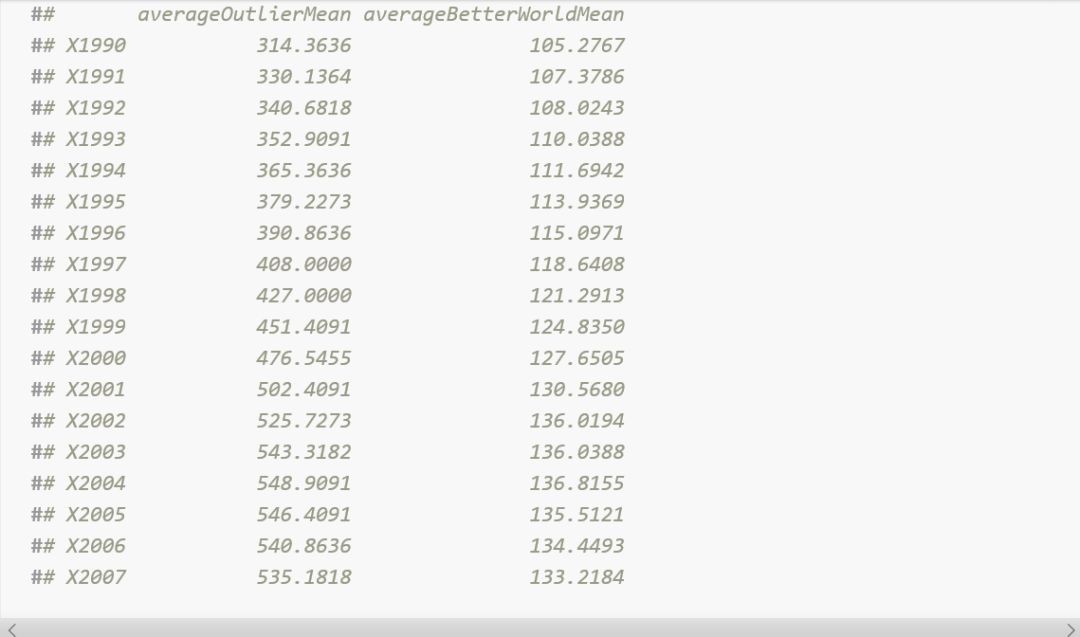
現在將這兩個國家放在一起。


谷歌一下關於肺結核病的事件以及日期
在此章節中我們只用Python來分析。關於谷歌檢索,其實我們只是直接訪問維基百科關於這個疾病的目錄(https://en.wikipedia.org/wiki/Tuberculosis#Epidemiology)。
在疫情章節我們可以找到如下內容:
-
肺結核病的發病總數從2005年開始下降,而新病發現量則從2002年開始就已經下降了。
-
這一點已經被我們之前的分析證實了。
-
中國取得了尤其顯著的進展,從1990年到2010年,傳染性肺結核病的死亡率下降了大約80%。讓我們來看一下:


-
在2007年,預估傳染性肺結核病的新病發生率最高的國家是史瓦濟蘭,10萬人中有1200起病例。


在維基百科中還有更多的發現是我們可以透過分析這些Google資料或其它Gapminder提供的資料來證實的。例如,傳染性肺結核病和艾滋病經常被關聯起來,同它們一起關聯起來還有貧困水平。將它們相關的資料集關聯起來,探索它們各自的變化趨勢將會很有意思。讀者們可以去試著分析一下並和我們分享你們的發現。
探索其它網頁
除Gapminder網站之外的關於結核病其它有趣的資源:
蓋茨基金會網站:
http://www.gatesfoundation.org/What-We-Do/Global-Health/Tuberculosis
http://www.gatesfoundation.org/Media-Center/Press-Releases/2007/09/New-Grants-to-Fight-Tuberculosis-Epidemic
總結
探索性資料分析是資料分析的一個關鍵步驟。在此階段我們開始使接下來的工作逐漸成型。它發生於任一資料視覺化或機器學習工作之前,向我們展示我們的資料或假設的好壞。
傳統上,R語言是大多數探索性資料分析工作選擇的武器,雖然使用其它的展示能力更佳的繪圖程式庫是相當方便的,如gglot2。事實上,當我們用Python時,Pandas中所包含的基本的繪圖功能使這個步驟更加清晰和便捷。不管怎樣,我們這裡回答的這些問題都非常簡單而且沒有包含多變數和資料編碼。在這種複雜的情況下,一個進階的程式庫如ggplot2將大放光彩。除了能給我們更漂亮的繪圖之外,它的豐富的變現手法和重用性將大大地節省我們的時間。
儘管我們的分析和圖表都如此簡單,我們依然能夠證明一個論點,那就是像肺結核這樣的疾病引發的人道危機是多麼嚴重,特別是考慮到這種疾病在更加發達的國家被相對更好地控制了。我們已經看到了一些程式設計技巧和大量的求知慾,從而允許我們在此之上建立一些認知和其它的全球化問題。
請記住這系列教程的所有程式碼和應用程式可以從GitHub(https://github.com/jadianes/data-science-your-way)中得到。
你可以隨意參與並同我們分享你的進度!
原文標題:
Data Science with Python & R: Exploratory Data Analysis
原文連結:
https://www.codementor.io/jadianes/data-science-python-r-exploratory-data-analysis-visualization-du107jjms
譯者簡介:季洋,蘇州某IT公司技術總監,從業20年,現在主要負責Java專案的方案和管理工作。對大資料、資料挖掘和分析專案躍躍欲試卻苦於沒有機會和資料。目前正在摸索和學習中,也報了一些線上課程,希望對資料建模的應用場景有進一步的瞭解。不能成為巨人,只希望可以站在巨人的肩膀上瞭解資料科學這個有趣的世界。
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
80%的運營註定了打雜?因為你沒有搭建出一套有效的使用者運營體系
商務請加qq:365242293
更多相關知識請回覆:“ 月光寶盒 ”;
資料分析(ID : ecshujufenxi )網際網路科技與資料圈自己的微信,也是WeMedia自媒體聯盟成員之一,WeMedia聯盟改寫5000萬人群。
