Linux核心在做SNAT(源地址轉換)時存在一個已知的資源競爭問題,這可能導致SYN包被丟棄。SNAT預設是在Docker和Flannel的對外連線上進行的,使用iptables的masquerade(地址偽裝)規則。這個資源競爭可能發生在多個容器併發地嘗試與同一個外部地址建立連線的時候。在一些場景下,兩個連線可能分配到同一個埠用以地址轉換,這最終導致一個或多個包被丟棄以及至少1秒的連線時延。
這個資源競爭問題在Linux核心程式碼中有提及,但是沒有太多相關的檔案。雖然Linux核心已經支援設定一個flag來規避這個問題,但直到最近iptables的masquerade規則才支援。
同樣的資源競爭情況也存在於DNAT(目的地址轉換)。在Kubernetes中,這意味著訪問ClusterIP時可能會丟包。當你從Pod傳送一個請求到ClusterIP,kube-proxy(透過iptables)預設將ClsuterIP替換成你要訪問的Service的某個Pod IP。DNS是Kubernetes最常見的Service之一,這個資源競爭問題可能使DNS解析域名時產生間歇性的延時,參見Kubernetes社群Issue 56903。
這篇文章嘗試解釋是我們怎樣研究這個問題的,在容器網路的場景下解釋這個資源競爭包含什麼問題以及我們怎樣規避它。
在過去的一年我們和站點運維團隊一起來構建PaaS(Platform as a Service)。在2017年9月,經過幾個月的評估之後,我們開始把基於Capistrano/Marathon/Bash的應用遷移到Kubernetes。
我們搭建的平臺依賴於執行在Ubuntu Xenial虛機上的Kubernetes 1.8,其中使用的Docker版本為17.06,並以host-gateway樣式執行Flannel 1.9.0。
遷移過程中我們註意到,應用在Kubernetes執行之後,連線超時有增加。在我們把第一個基於Scala的應用遷移上來後,這個現象變得更加明顯。幾乎每一秒都有一個請求的響應變得非常慢,而不是通常的幾百微秒。這是個普通的RESTful應用,查詢平臺上的其它服務,收集、處理資料,然後傳回資料到客戶端,並沒有什麼不尋常之處。
響應慢的請求的響應時間很奇怪。幾乎全部都被延遲了整整1秒或者3秒!我們決定是時候研究這個問題了。
我們的待辦事項串列中有一項是監控KubeDNS的執行狀況。依賴於HTTP客戶端,域名解析時間可能是連線時間的一部分,我們決定先處理這項任務,確定這個元件執行正常。我們寫了一個簡單的DaemonSet,它會直接查詢KubeDNS和我們資料中心的域名伺服器,然後把響應時間傳送到InfluxDB。這些圖表反映的快速響應時間立刻讓我們立刻排除是域名解析導致問題的可能性。
下一步首先理解那些超時真正意味著什麼。負責這個Scala應用的團隊做了些改動使得響應慢的請求在後臺繼續傳送,並且記錄它丟擲超時錯誤給客戶端之後的持續時間。我們在這個應用執行的Kubernetes節點上做了些網路追蹤,並嘗試將響應慢的請求和網路轉儲的內容進行匹配。
Fig.1 容器的視角,10.244.38.20嘗試連線10.16.46.24的80埠
結果表明超時是用來初始化連線的第一個網路包(包帶有SYN標記)的重傳輸導致的。這很好解釋了響應慢的請求的持續時間,因為這種型別的包的重傳輸的延時,第二次嘗試是1秒之後,第三次是3秒,然後6秒,12秒,24秒等等。
這是一個有趣的發現,因為只丟失SYN標記的包排除了是隨機的網路故障的原因,說明更可能是某個網路裝置或者SYN洪泛保護演演算法主動丟棄新連線。
按預設方式安裝Docker後,每一個容器在虛擬網路介面(veth)的IP連線到Docker主機上的一個Linux網橋(例如:cni0,docker0),主介面(例如eth0)同樣也連線著這個網橋。容器之間透過這個網橋互相通訊。如果一個容器嘗試訪問Docker主機外部的地址,這個包經過這個網橋,透過eth0路由到伺服器外部。
以下的例子改編自一個預設的Docker配置來匹配網路捕獲結果中的網路設定:
Fig.2 現實中veth介面以對的形式出現,但在我們的場景中這關係不大
我們已經隨機選擇檢視在這個網橋上的包,接下來繼續檢視虛機的主網路介面eth0。然後根據結果集中看網路基礎設施或者虛機。
Fig.3 從veth0,cni0和eth0捕獲的結果,10.244.38.20嘗試連線10.16.46.24的80埠
網路的捕獲結果顯示第一個SYN包在時刻13:42:23.828339從容器網路介面(veth)離開,經過網橋(cni0)(在13:42:23.828339的重覆的行)。經過1秒在時刻13:42:24.826211,源容器沒有從10.16.46.24得到響應,便重傳輸這個包。重覆地,這個包會先出現在容器的網路介面,然後是網橋。在下一行,我們可以看到這個包在時刻13:42:24.826263,IP地址和埠從10.244.38.20:38050轉換成10.16.34.2:10011之後,離開eth0。下麵的幾行抓包顯示了遠端的服務是怎樣響應的。
這個地址轉換意味著什麼將會在這篇文章的後面部分詳細解釋。因為我們沒看到在13:42:23時刻的第一次嘗試連線的SYN包離開eth0,此時可以認為該包已經在cni0和eth0之間的某個地方丟失。那些包就這樣丟失相當讓人驚訝,因為虛機的負載和請求速率都低。我們重覆進行了多次測試,但得到的結果都一樣。
為了理解這篇文章的剩餘部分,最好有一些關於SNAT(源地址轉換)的知識。接下來的這節是關於這個主題的簡單說明,如果你已經瞭解SNAT和conntrack,可以跳過它。
按預設方式安裝Docker後,容器有自己的IP,並且如果在同一個Docker主機網路,能夠使用它們的IP互相通訊。然而,從主機外部你無法透過容器的IP來訪問它。外部的機器要想與容器通訊,你通常需要在主機網路介面暴露容器的埠,然後使用主機IP來訪問。這是因為容器IP沒有到外部的路由,但主機IP有。網路基礎設施不清楚每一個Docker主機網路內部的IP,因此位於不同主機網路的容器之間的通訊是不可能的(Swarm或者其他網路後端的情況可能不一樣)。
透過host-gateway樣式的Flannel和一些其它的Kubernetes網路外掛,Pod能夠訪問在同一個叢集的其它主機上的Pod。你可以從一個pod訪問另一個pod,無論它執行在哪個節點,但是不能從叢集外的虛機訪問Pod。可以使用Calico等來實現這個,但使用以host-gw樣式執行的Flannel無法實現。
如果從外部主機無法直接訪問容器,容器也就不可能和外部服務通訊。如果一個容器請求外部的服務,由於容器IP是不可路由的,遠端伺服器不知道應該把響應發到哪裡。但事實上只要每個主機對容器到外部的連線做一次SNAT就能實現。
我們的Docker主機能夠和資料中心的其它機器通訊,它們有可路由的IP。當一個容器嘗試訪問一個外部服務時,執行容器的主機將網路包中的容器IP用用它本身的IP替換。對於外部服務,看起來像是和主機建立了連線。當響應傳回到主機的時候,它進行一個逆轉換(把網路包中的主機IP替換成容器IP)。對於容器,這個操作完全是透明的,它不知道發生了這樣的一個轉換。
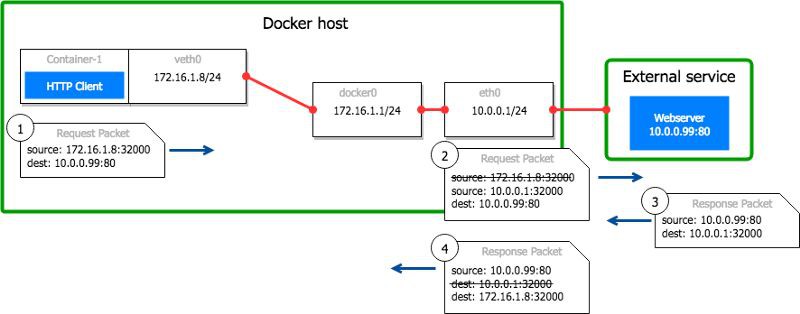
例如:一個Docker主機10.0.0.1上執行著一個名為container-1的容器,它的IP為172.16.1.8。容器內部的行程初始化一個訪問10.0.0.99:80的連線。它系結本地容器埠32000。
-
這個包離開容器到達Docker主機,源地址為172.16.1.8:32000。
-
Docker主機將源地址由172.16.1.8:32000替換為10.0.0.1:32000,並把包轉發給10.0.0.99:80。Linux用一個表格追蹤轉換過程,以便在包的響應中能夠進行逆向轉換。
-
遠端服務10.0.0.99:80處理這個請求並傳迴響應給主機。
-
響應傳回到主機的32000埠。Linux看到這是一個已經轉換的連線的響應,便把目的地址從10.0.0.1:32000修改為172.16.1.8:32000,把包轉發給容器。
Linux的netfilter框架能夠在核心網路棧的不同地方進行許多的網路操作,例如:包過濾等操作。但對我們來說更感興趣的是IP地址和埠的轉換。Iptables是一個可以讓我們用命令列來配置netfilter的工具。預設的Docker安裝會新增一些iptables規則,來對向外的連線做SNAT。在我們的Kubernetes叢集,Flannel做同樣的事(實際上,它們都配置iptables來做masqurade(地址偽裝,SNAT的一種))。
Fig.5 從容器(在這個例子中是172.17.0.0/16)發出的包到除網橋(docker0)之外的地方都會進行masqurade
當一個從容器到外部服務的連線發出後,因為Docker/Flannel新增的iptables規則它會被netfilter處理。netfilter的NAT模組進行SNAT的操作,它將向外傳輸的包中的源地址替換主機IP,並且在核心中新增一個條目來記錄這個轉換。這個條目確保同一個連線後續的包會用同樣的方式修改以保持一致性。它也確保外部服務的響應到達主機的時候,核心知道如何相應地修改包地址。
這些條目儲存在內核的conntrack表(conntrack是netfilter的另一個模組)中。你可以透過命令sudo conntrack -L來檢視這個表的內容。
Fig.6 主機10.0.0.1上從容器172.16.1.8:32000到10.0.0.99:80的連線
伺服器能夠使用三元組{IP, 埠, 協議}來與其他主機通訊,而且一次只能使用一個三元組。如果你的SNAT池只有一個IP,並且使用HTTP(底層TCP協議)連線到同一個遠端服務,這意味著兩個向外的連線允許變化的只有源埠。
如果一個埠被已經建立的連線佔用,另一個容器嘗試使用相同的本地埠訪問同一個服務,netfilter不僅要改變該容器的源IP,還包括源埠。
兩個併發的連線的例子:Docker主機10.0.0.1上執行著另外一個名為container-2的容器,其IP是172.16.1.9。
-
container-1 以IP 172.16.1.8,使用本地埠32000,嘗試建立到 10.0.0.99:80的連線。
-
container-2 以IP 172.16.1.9,使用本地埠32000,嘗試建立到 10.0.0.99:80的連線。
-
來自container-1的包到達主機,源IP為172.16.1.8:32000。在表中沒有10.0.0.1:32000的條目,所以埠32000可以被保留。主機將源IP從172.16.1.8:32000替換為10.0.0.1:32000。它在conntrack表格中增加了一個條目,來記錄從172.16.1.8:32000到10.0.0.99:80的TCP連線,源地址被轉換成了10.0.0.1:32000。
-
來自container-2的包到達主機,源IP為172.16.1.9:32000。由於10.0.0.1:32000已經被用來與10.0.0.99:80的TCP通訊,主機使用第一個可用的埠(1024),把源IP從172.16.1.8:32000替換為10.0.0.1:1024。在conntrack表格中增加了一個條目,來記錄從172.16.1.9:32000到10.0.0.99:80的TCP連線,源地址被轉換成了10.0.0.1:1024。
-
遠端服務響應來自10.0.0.1:32000和10.0.0.1:1024的連線。
-
Docker主機接收到埠32000的響應,將標的地址改為172.16.1.8:32000。
-
Docker主機接收到埠1024的響應,將標的地址改為172.16.1.9:32000。
註意:當一個主機有多個IP可以用來SNAT操作時,這些IP可視為SNAT池的一部分。這不是我們這個例子的情況。
我們的包在網橋和eth0之間丟失的,這正是發生SNAT的地方。如果因為某些原因導致Linux核心無法分配一個空閑的源埠來做地址轉換,我們將不可能看到這個包出eth0。有一個簡單的測試可以來驗證這個猜想。嘗試pod到pod的通訊,並記錄響應慢的連線的數目。我們進行了這個測試,並得到很好的結果。沒有一個包被丟棄。
之前我們一度認為大部分連線總是會被轉換成相同的host:port是導致這個問題的原因。然而,此時我們認為問題可能是錯誤配置SYN洪泛保護導致的。我們閱讀了網路核心引數的描述,希望找到一些我們不清楚的機制。但我們沒有找到和這個問題相關的東西。我們已經增加了conntrack表的大小,核心日誌也沒有報什麼錯誤。
我們想到的第二個事情是埠復用。如果埠資源耗盡,沒有可用的埠來做SNAT 操作,包很可能被丟棄或者被拒絕。我們決定研究下conntrack表。這沒帶來太大的幫助,因為這個表格並未被充分使用。但是我們發現conntrack軟體包有一個命令來顯示一些統計資訊(conntrack -S)。有一個欄位立刻引起我們的註意,當執行那個命令時“insert_field”的值是一個非零值。
我們再一次執行測試程式,同時密切關註那個欄位值的變化。發現這個值的增加與丟失的包數量相同。
幫助頁面關於那個欄位的描述很清楚,但不是很有幫助:“嘗試插入表但失敗的條目數(在相同的條目已經存在的情況下)。”
在哪種情形下插入表會失敗?在一個低負載的伺服器上包被丟棄聽起來不像是一個正常行為。
從netfilter的使用者郵件串列中獲取幫助的嘗試無功而返後,我們決定自己弄清這個問題。
Netfilter NAT以及Conntrack核心模組

在閱讀完核心netfilter的程式碼後,我們決定重編譯它,並加入一些日誌來更好地理解真正發生了什麼。以下是我們瞭解到的。
NAT程式碼在POSTROUTING鏈上被呼叫兩次。首先是透過修改源地址和/或埠來修改包的結構,然後如果包在這這個過程中間沒有丟失的話,核心在conntrack表中記錄這個轉換。這意味著在SNAT埠分配和插入conntrack表之間有一個時延,如果有衝突的話可能最終導致插入失敗以及丟包。這正是我們所看到的。
當在TCP連線上做SNAT的時候,NAT模組會做以下嘗試:
-
如果包的源地址是在標的NAT池中,且{IP, 埠,協議}三元組是可用的,傳回(包沒有改變)。
-
找到池中最少使用的IP,用之來替換包中的源IP。
-
檢查埠是否在允許的範圍(預設1024-64512),並且帶這個埠的三元組是否可用。如果可用則傳回(源IP已經改變,埠未改變)。(註意:SNAT的埠範圍不受核心引數net.ipv4.ip_local_port_range的影響。)
-
埠不可用,核心透過透過呼叫 nf_nat_l4proto_unique_tuple()請求TCP層找到一個未使用的埠來做SNAT。
當主機上只執行著一個容器,NAT模組最可能在第三步傳回。容器內部行程使用到的本地埠會被保留並用以對外的連線。當在Docker主機上執行多個容器時,很可能一個連線的源埠已經被另一個容器的連線使用。在那種情況下,透過nf_nat_l4proto_unique_tuple()呼叫來找到另一個可用的埠進行NAT操作。
-
從一個初始位置開始搜尋並複製最近一次分配的埠。
-
遞增1。
-
呼叫nf_nat_used_tuple()檢查埠是否已被使用。如果已被使用,重覆上一步。
-
用剛分配的埠更新最近一次分配的埠並傳回。
由於埠分配和把連線插入conntrack表之間有延時,因此當nf_nat_used_tuple()被並行呼叫時,對同一個埠的nf_nat_used_tuple()多次呼叫可能均回真——當埠分配以相同的初始值開始時,這種現象尤為明顯。在我們的測試中,大多數埠分配衝突來自於時間間隔在0~2us內初始化的連線。
netfilter也支援兩種其它的演演算法來找到可用的埠:
NF_NAT_RANGE_PROTO_RANDOM降低了兩個執行緒以同一個初始埠開始搜尋的次數,但是仍然有很多的錯誤。只有使用NF_NAT_RANGE_PROTO_RANDOM_FULLY才能顯著減少conntrack表插入錯誤的次數。在一臺Docker測試虛機,使用預設的masquerade規則,10到80個執行緒併發請求連線同一個主機有2%-4%的插入錯誤。
當在核心強制使用完全隨機時,錯誤降到了0(後來在真真實的叢集中也接近0)。
需要在masquerade規則中設定flag NF_NAT_RANGE_PROTO_RANDOM_FULLY。在我們的Kubernetes的環境中,flannel負責新增這些規則。在Docker映象構建的時候,它使用從原始碼編譯的iptables。iptables工具不支援設定這個flag,但是我們已經提交了一個小補丁增加這個特性,補丁已經合入(譯者註:在iptables 1.6.2版本釋出)。
我們現在使用一個修改後的打了這個補丁的flannel版本,在masquerade規則中增加了flag –ramdom-fully。我們使用一個簡單的Daemonset從每一個節點上獲取conntrack的統計結併傳送到InfluxDB來監控conntrack表的插入錯誤。我們已經使用這補丁將近一個月了,整個叢集中的錯誤的數目從每幾秒一次下降到每幾個小時一次。
儘管Kubernetes被大量地使用,但是我們非常驚訝於這個資源競爭問題卻沒有充分地被討論。我們的多數應用連線到相同的服務後端的事實使得這個問題變得更加明顯。
可以採取一些其它的措施來緩解這一問題,例如:為這些服務配置DNS輪詢,或者多增加一些IP到主機的NAT池。
在接下來的幾個月裡,我們將研究一個service mesh怎樣才能不傳送如此多的流量到中心服務後端。我們很可能會研究下Kubernetes網路的可路由Pod IP能否完全擺脫SNAT,這也能幫助我們在Kubernetes上大量部署Akka和Elixir叢集。
原文連結:https://tech.xing.com/a-reason-for-unexplained-connection-timeouts-on-kubernetes-docker-abd041cf7e02
Kubernetes專案實戰訓練將於2018年8月17日在深圳開課,3天時間帶你係統掌握Kubernetes。本次培訓包括:Docker介紹、Docker映象、網路、儲存、容器安全;Kubernetes架構、設計理念、常用物件、網路、儲存、網路隔離、服務發現與負載均衡;Kubernetes核心元件、Pod、外掛、微服務、雲原生、Kubernetes Operator、叢集災備、Helm等,點選下方圖片檢視詳情。
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。
![]()
微信掃一掃
使用小程式