
來源:程式人生
ID:coder_life

圖片源自網路
作者
Python進階者
如需轉載,請聯絡原作者授權。
今天小編給大家分享一下如何利用Python網路爬蟲抓取微信朋友圈的動態資訊,實際上如果單獨的去爬取朋友圈的話,難度會非常大,因為微信沒有提供向網易雲音樂這樣的API介面,所以很容易找不到門。不過不要慌,小編在網上找到了第三方工具,它可以將朋友圈進行匯出,之後便可以像我們正常爬蟲網頁一樣進行抓取資訊了。
【出書啦】就提供了這樣一種服務,支援朋友圈匯出,併排版生成微信書。本文的主要參考資料來源於這篇博文:
https://www.cnblogs.com/sheng-jie/p/7776495.html ,感謝大佬提供的介面和思路。具體的教程如下。
一、獲取朋友圈資料入口
1、關註公眾號【出書啦】

2、之後在主頁中點選【創作書籍】–>【微信書】。

3、點選【開始製作】–>【新增隨機分配的出書啦小編為好友即可】,長按二維碼之後便可以進行新增好友了。
4、之後耐心等待微信書製作,待完成之後,會收到小編髮送的訊息提醒,如下圖所示。
至此,我們已經將微信朋友圈的資料入口搞定了,並且獲取了外鏈。
確保朋友圈設定為【全部開放】,預設就是全部開放,如果不知道怎麼設定的話,請自行百度吧。

5、點選該外鏈,之後進入網頁,需要使用微信掃碼授權登入。
6、掃碼授權之後,就可以進入到微信書網頁版了,如下圖所示。
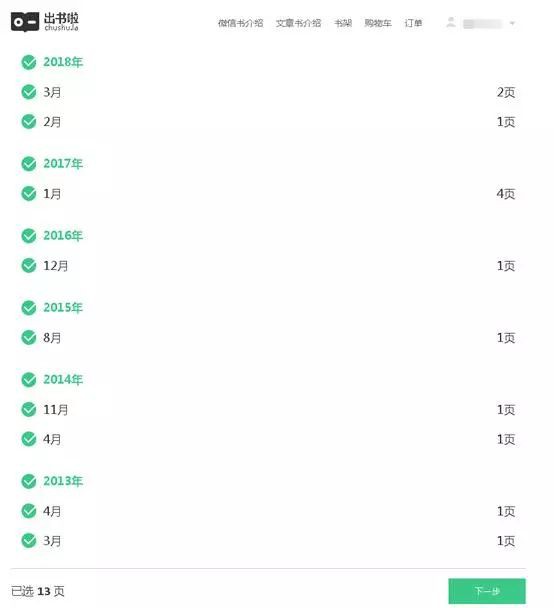
7、接下來我們就可以正常的寫爬蟲程式進行抓取資訊了。在這裡,小編採用的是Scrapy爬蟲框架,Python用的是3版本,整合開發環境用的是Pycharm。下圖是微信書的首頁,圖片是小編自己自定義的。

二、建立爬蟲專案
1、確保您的電腦上已經安裝好了Scrapy。之後選定一個檔案夾,在該檔案夾下進入命令列,輸入執行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬蟲專案。
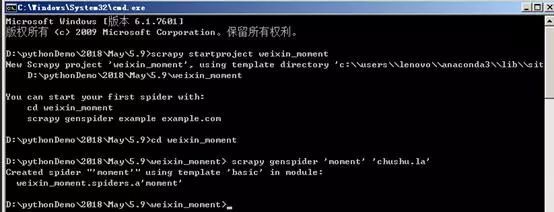
2、在命令列中輸入cd weixin_moment,進入建立的weixin_moment目錄。之後輸入命令:
scrapy genspider ‘moment’ ‘chushu.la’
,建立朋友圈爬蟲,如下圖所示。
3、執行以上兩步後的檔案夾結構如下:
三、分析網頁資料
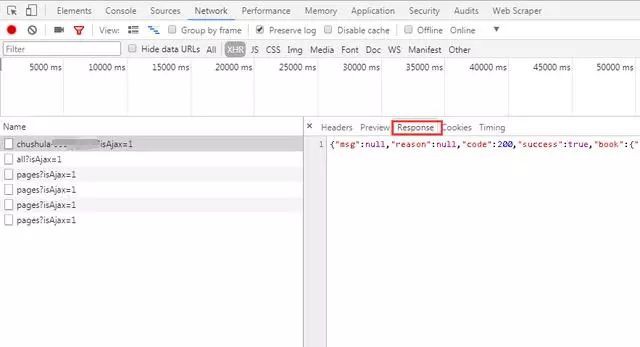
1、進入微信書首頁,按下F12,建議使用谷歌瀏覽器,審查元素,點選“Network”選項卡,然後勾選“Preserve log”,表示儲存日誌,如下圖所示。可以看到主頁的請求方式是get,傳回的狀態碼是200,代表請求成功。

2、點選“Response”(伺服器響應),可以看到系統傳回的資料是JSON格式的。說明我們之後在程式中需要對JSON格式的資料進行處理。
3、點選微信書的“導航”視窗,可以看到資料是按月份進行載入的。當點選導航按鈕,其載入對應月份的朋友圈資料。

4、當點選【2014/04】月份,之後檢視伺服器響應資料,可以看到頁面上顯示的資料和伺服器的響應是相對應的。

5、檢視請求方式,可以看到此時的請求方式變成了POST。細心的夥伴可以看到在點選“下個月”或者其他導航月份的時候,主頁的URL是始終沒有變化的,說明該網頁是動態載入的。之後對比多個網頁請求,我們可以看到在“Request Payload”下邊的資料包引數不斷的發生變化,如下圖所示。

6、展開伺服器響應的資料,將資料放到JSON線上解析器裡,如下圖所示:

可以看到朋友圈的資料儲存在paras /data節點下。
接下來將寫程式,進行資料抓取。接著往下繼續深入。
四、程式碼實現
1、修改Scrapy專案中的items.py檔案。我們需要獲取的資料是朋友圈和釋出日期,因此在這裡定義好日期和動態兩個屬性,如下圖所示。

2、修改實現爬蟲邏輯的主檔案moment.py,首先要匯入模組,尤其是要主要將items.py中的WeixinMomentItem類匯入進來,這點要特別小心別被遺漏了。之後修改start_requests方法,具體的程式碼實現如下圖。
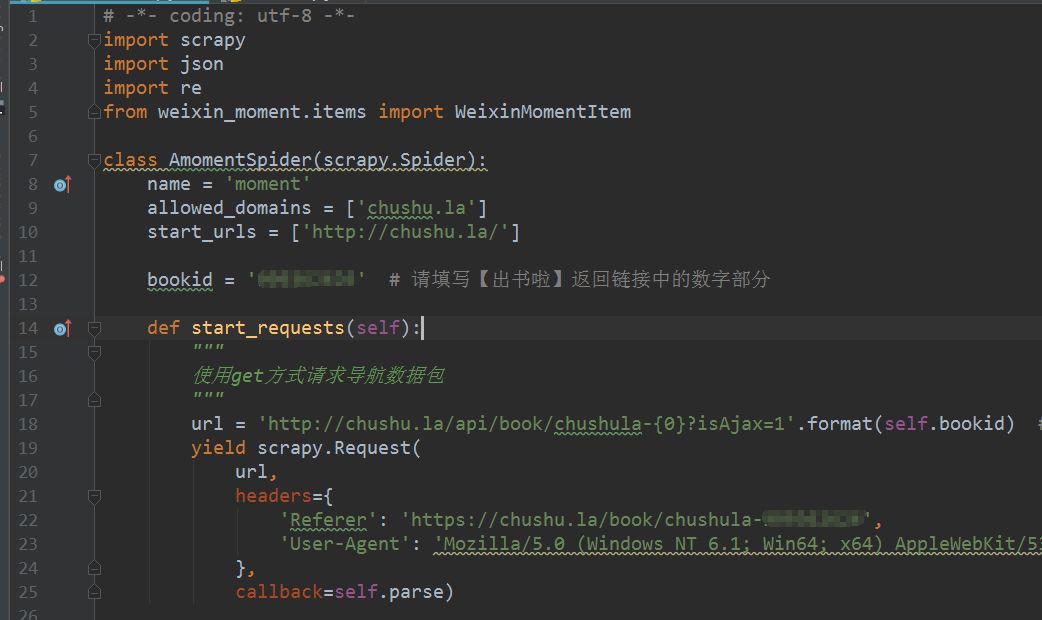
3、修改parse方法,對導航資料包進行解析,程式碼實現稍微複雜一些,如下圖所示。

-
l需要註意的是從網頁中獲取的response是bytes型別,需要顯示的轉為str型別才可以進行解析,否則會報錯。
-
l在POST請求的限定下,需要構造引數,需要特別註意的是引數中的年、月和索引都需要是字串型別的,否則伺服器會傳回400狀態碼,表示請求引數錯誤,導致程式執行的時候報錯。
-
l在請求引數還需要加入請求頭,尤其是Referer(反盜鏈)務必要加上,否則在重定向的時候找不到網頁入口,導致報錯。
-
l上述的程式碼構造方式並不是唯一的寫法,也可以是其他的。
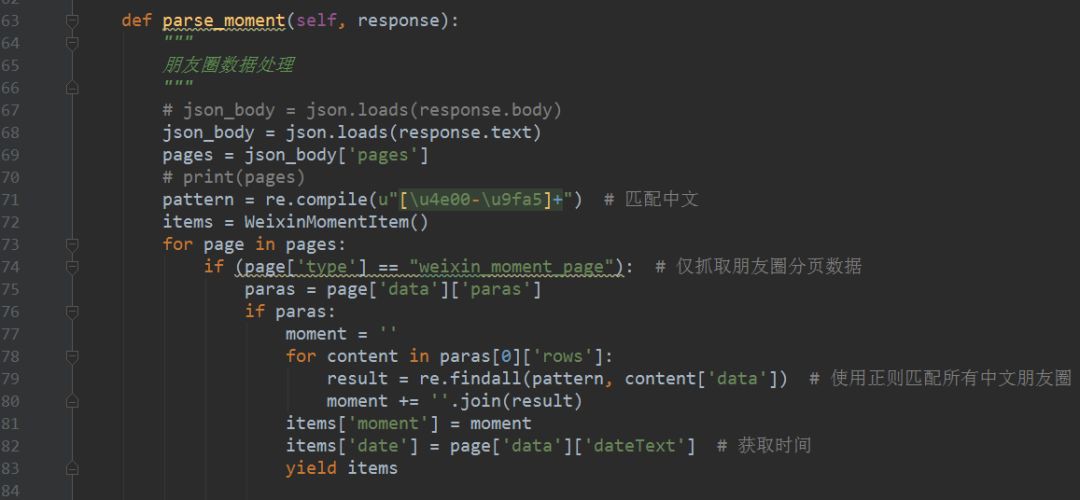
4、定義parse_moment函式,來抽取朋友圈資料,傳回的資料以JSON載入的,用JSON去提取資料,具體的程式碼實現如下圖所示。
5、在setting.py檔案中將ITEM_PIPELINES取消註釋,表示資料透過該管道進行處理。

6、之後就可以在命令列中進行程式運行了,在命令列中輸入
scrapy crawl moment -o moment.json
,之後可以得到朋友圈的資料,在控制臺上輸出的資訊如下圖所示。

7、爾後我們得到一個moment.json檔案,裡面儲存的是我們朋友圈資料,如下圖所示。
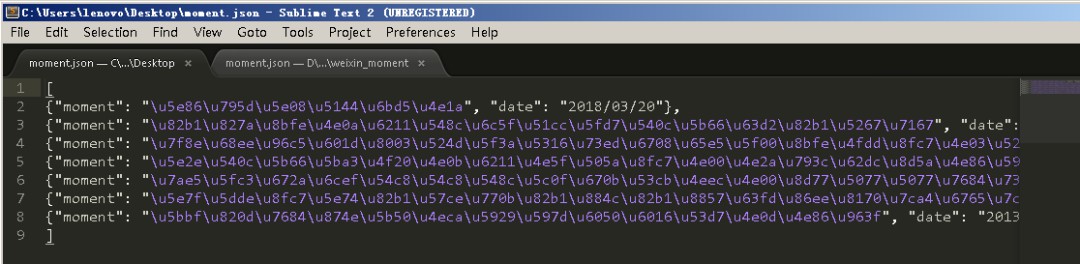
8、嗯,你確實沒有看錯,裡邊得到的資料確實讓人看不懂,但是這個並不是亂碼,而是編碼的問題。解決這個問題的方式是將原來的moment.json檔案刪除,之後重新在命令列中輸入下麵的命令:
scrapy crawl moment -o moment.json -s FEED_EXPORT_ENCODING=utf-8,
此時可以看到編碼問題已經解決了,如下圖所示。

《Linux雲端計算及運維架構師高薪實戰班》2018年08月27日即將開課中,120天衝擊Linux運維年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


更多Linux好文請點選【閱讀原文】哦
↓↓↓
