MySQL一直瞭解得都不多,之前寫sql準備提交生產環境之前的時候,老員工幫我檢查了下sql,讓修改了一下儲存引擎,當時我使用的是Myisam,後面改成InnoDB了。為什麼要改成這樣,之前都沒有聽過儲存引擎,於是網上查了一下。
事實上使用不同的儲存引擎也是有很大區別的,下麵猿友們可以瞭解一下。
一、儲存引擎的比較
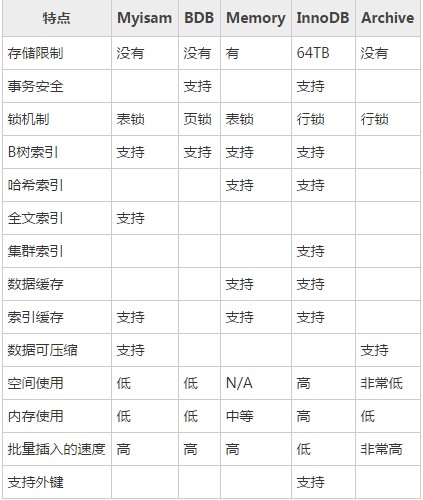
註:上面提到的B樹索引並沒有指出是B-Tree和B+Tree索引,但是B-樹和B+樹的定義是有區別的。
在 MySQL 中,主要有四種型別的索引,分別為: B-Tree 索引, Hash 索引, Fulltext 索引和 R-Tree 索引。
B-Tree 索引是 MySQL 資料庫中使用最為頻繁的索引型別,除了 Archive 儲存引擎之外的其他所有的儲存引擎都支援 B-Tree 索引。Archive 引擎直到 MySQL 5.1 才支援索引,而且只支援索引單個 AUTO_INCREMENT 列。
不僅僅在 MySQL 中是如此,實際上在其他的很多資料庫管理系統中B-Tree 索引也同樣是作為最主要的索引型別,這主要是因為 B-Tree 索引的儲存結構在資料庫的資料檢索中有非常優異的表現。
一般來說, MySQL 中的 B-Tree 索引的物理檔案大多都是以 Balance Tree 的結構來儲存的,也就是所有實際需要的資料都存放於 Tree 的 Leaf Node(葉子節點) ,而且到任何一個 Leaf Node 的最短路徑的長度都是完全相同的,所以我們大家都稱之為 B-Tree 索引。當然,可能各種資料庫(或 MySQL 的各種儲存引擎)在存放自己的 B-Tree 索引的時候會對儲存結構稍作改造。如 Innodb 儲存引擎的 B-Tree 索引實際使用的儲存結構實際上是 B+Tree,也就是在 B-Tree 資料結構的基礎上做了很小的改造,在每一個Leaf Node 上面出了存放索引鍵的相關資訊之外,還儲存了指向與該 Leaf Node 相鄰的後一個 LeafNode 的指標資訊(增加了順序訪問指標),這主要是為了加快檢索多個相鄰 Leaf Node 的效率考慮。
InnoDB是Mysql的預設儲存引擎(Mysql5.5.5之前是MyISAM)
可能對於沒有瞭解過索引的猿友這樣看這篇文章十分吃力,這類猿友有必要先對Mysql索引有個大體的瞭解,可以看看另外一篇文章: 資料庫查詢最佳化——Mysql索引 http://blog.csdn.net/u013142781/article/details/51424174看完這篇文章我們再回頭看看上面的文字說明吧。
接下來我們先看看B-樹、B+樹的概念。弄清楚,為什麼加了索引查詢速度會加快?
二、B-樹、B+樹概念
B樹
即二叉搜尋樹:
1、所有非葉子結點至多擁有兩個兒子(Left和Right);
2、所有結點儲存一個關鍵字;
3、非葉子結點的左指標指向小於其關鍵字的子樹,右指標指向大於其關鍵字的子樹;
如:
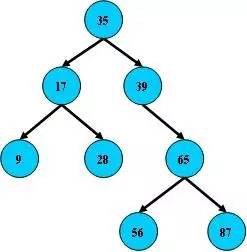
B-樹
是一種多路搜尋樹(並不是二叉的):
1、定義任意非葉子結點最多隻有M個兒子;且M>2;
2、根結點的兒子數為[2, M];
3、除根結點以外的非葉子結點的兒子數為[M/2, M];
4、每個結點存放至少M/2-1(取上整)和至多M-1個關鍵字;(至少2個關鍵字)
5、非葉子結點的關鍵字個數=指向兒子的指標個數-1;
6、非葉子結點的關鍵字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7、非葉子結點的指標:P[1], P[2], …, P[M];其中P[1]指向關鍵字小於K[1]的子樹,P[M]指向關鍵字大於K[M-1]的子樹,其它P[i]指向關鍵字屬於(K[i-1], K[i])的子樹;
8、所有葉子結點位於同一層;
如:(M=3)
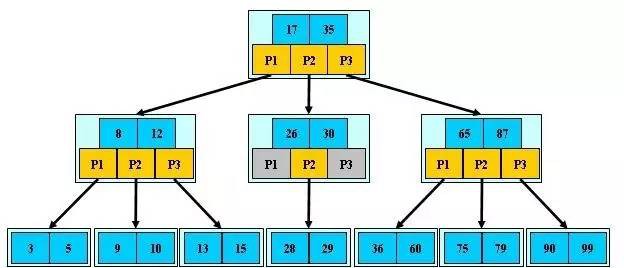
B-樹的搜尋,從根結點開始,對結點內的關鍵字(有序)序列進行二分查詢,如果命中則結束,否則進入查詢關鍵字所屬範圍的兒子結點;重覆,直到所對應的兒子指標為空,或已經是葉子結點;
B-樹的特性:
1、關鍵字集合分佈在整顆樹中;
2、任何一個關鍵字出現且只出現在一個結點中;
3、搜尋有可能在非葉子結點結束;
4、其搜尋效能等價於在關鍵字全集內做一次二分查詢;
5、自動層次控制;
由於限制了除根結點以外的非葉子結點,至少含有M/2個兒子,確保了結點的至少利用率。
所以B-樹的效能總是等價於二分查詢(與M值無關),也就沒有B樹平衡的問題;
由於M/2的限制,在插入結點時,如果結點已滿,需要將結點分裂為兩個各佔M/2的結點;刪除結點時,需將兩個不足M/2的兄弟結點合併;
B+樹
B+樹是B-樹的變體,也是一種多路搜尋樹:
1、其定義基本與B-樹同,除了:
2、非葉子結點的子樹指標與關鍵字個數相同;
3、非葉子結點的子樹指標P[i],指向關鍵字值屬於[K[i], K[i+1])的子樹(B-樹是開區間);
5、為所有葉子結點增加一個鏈指標;
6、所有關鍵字都在葉子結點出現;
如:(M=3)
B+的搜尋與B-樹也基本相同,區別是B+樹只有達到葉子結點才命中(B-樹可以在
非葉子結點命中),其效能也等價於在關鍵字全集做一次二分查詢;
B+的特性:
1、所有關鍵字都出現在葉子結點的連結串列中(稠密索引),且連結串列中的關鍵字恰好是有序的;
2、不可能在非葉子結點命中;
3、非葉子結點相當於是葉子結點的索引(稀疏索引),葉子結點相當於是儲存(關鍵字)資料的資料層;
4、更適合檔案索引系統;
瞭解B-/B+樹的概念之後,我們繼續分析B+樹提高效率的原理。
三、B+樹索引原理
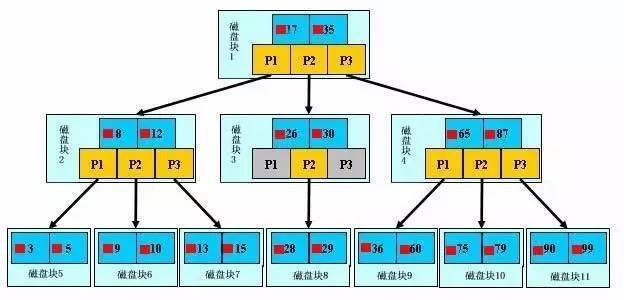
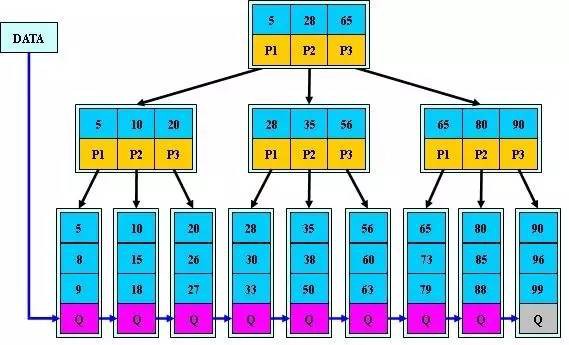
如上圖,是一顆b+樹,關於b+樹的定義可以參見B+樹,這裡只說一些重點,淺藍色的塊我們稱之為一個磁碟塊,可以看到每個磁碟塊包含幾個資料項(深藍色所示)和指標(黃色所示),如磁碟塊1包含資料項17和35,包含指標P1、P2、P3,P1表示小於17的磁碟塊,P2表示在17和35之間的磁碟塊,P3表示大於35的磁碟塊。真實的資料存在於葉子節點即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非葉子節點只不儲存真實的資料,只儲存指引搜尋方向的資料項,如17、35並不真實存在於資料表中。
b+樹的查詢過程
如圖所示,如果要查詢資料項29,那麼首先會把磁碟塊1由磁碟載入到記憶體,此時發生一次IO,在記憶體中用二分查詢確定29在17和35之間,鎖定磁碟塊1的P2指標,記憶體時間因為非常短(相比磁碟的IO)可以忽略不計,透過磁碟塊1的P2指標的磁碟地址把磁碟塊3由磁碟載入到記憶體,發生第二次IO,29在26和30之間,鎖定磁碟塊3的P2指標,透過指標載入磁碟塊8到記憶體,發生第三次IO,同時記憶體中做二分查詢找到29,結束查詢,總計三次IO。真實的情況是,3層的b+樹可以表示上百萬的資料,如果上百萬的資料查詢只需要三次IO,效能提高將是巨大的,如果沒有索引,每個資料項都要發生一次IO,那麼總共需要百萬次的IO,顯然成本非常非常高。
b+樹性質
1、透過上面的分析,我們知道IO次數取決於b+數的高度h,假設當前資料表的資料為N,每個磁碟塊的資料項的數量是m,則有h=㏒(m+1)N,當資料量N一定的情況下,m越大,h越小;而m = 磁碟塊的大小 / 資料項的大小,磁碟塊的大小也就是一個資料頁的大小,是固定的,如果資料項佔的空間越小,資料項的數量越多,樹的高度越低。這就是為什麼每個資料項,即索引欄位要儘量的小,比如int佔4位元組,要比bigint8位元組少一半。這也是為什麼b+樹要求把真實的資料放到葉子節點而不是內層節點,一旦放到內層節點,磁碟塊的資料項會大幅度下降,導致樹增高。當資料項等於1時將會退化成線性表。
2、當b+樹的資料項是複合的資料結構,比如(name,age,sex)的時候,b+數是按照從左到右的順序來建立搜尋樹的,比如當(張三,20,F)這樣的資料來檢索的時候,b+樹會優先比較name來確定下一步的所搜方向,如果name相同再依次比較age和sex,最後得到檢索的資料;但當(20,F)這樣的沒有name的資料來的時候,b+樹就不知道下一步該查哪個節點,因為建立搜尋樹的時候name就是第一個比較因子,必須要先根據name來搜尋才能知道下一步去哪裡查詢。比如當(張三,F)這樣的資料來檢索時,b+樹可以用name來指定搜尋方向,但下一個欄位age的缺失,所以只能把名字等於張三的資料都找到,然後再匹配性別是F的資料了, 這個是非常重要的性質,即索引的最左匹配特性。
慢查詢最佳化
關於MySQL索引原理是比較枯燥的東西,大家只需要有一個感性的認識,並不需要理解得非常透徹和深入。我們回頭來看看一開始我們說的慢查詢,瞭解完索引原理之後,大家是不是有什麼想法呢?先總結一下索引的幾大基本原則
四、建索引的幾大原則
1、最左字首匹配原則,非常重要的原則,mysql會一直向右匹配直到遇到範圍查詢(>、 3 and d = 4 如果建立(a,b,c,d)順序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調整。
2、=和in可以亂序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意順序,mysql的查詢最佳化器會幫你最佳化成索引可以識別的形式
3、儘量選擇區分度高的列作為索引,區分度的公式是count(distinct col)/count(*),表示欄位不重覆的比例,比例越大我們掃描的記錄數越少,唯一鍵的區分度是1,而一些狀態、性別欄位可能在大資料面前區分度就是0,那可能有人會問,這個比例有什麼經驗值嗎?使用場景不同,這個值也很難確定,一般需要join的欄位我們都要求是0.1以上,即平均1條掃描10條記錄
4、索引列不能參與計算,保持列“乾凈”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很簡單,b+樹中存的都是資料表中的欄位值,但進行檢索時,需要把所有元素都應用函式才能比較,顯然成本太大。所以陳述句應該寫成create_time = unix_timestamp(’2014-05-29’);
5、儘量的擴充套件索引,不要新建索引。比如表中已經有a的索引,現在要加(a,b)的索引,那麼只需要修改原來的索引即可