
導讀:使用 Scrapy 爬取豌豆莢全網 70,000+ App,併進行探索性分析。若對資料抓取部分不感興趣,可以直接下拉到資料分析部分。
作者:蘇克1900
來源:第2大腦(ID:Mocun6)
01 分析背景
之前我們使用 Scrapy 爬取並分析了酷安網 6000+ App,為什麼這篇文章又在講抓 App 呢?
因為我喜歡折騰 App,哈哈。當然,主要是因為下麵這幾點:
-
之前抓取的網頁很簡單
在抓取酷安網時,我們使用 for 迴圈,遍歷了幾百頁就完成了所有內容的抓取,非常簡單,但現實往往不會這麼 easy,有時我們要抓的內容會比較龐大,比如抓取整個網站的資料,為了增強爬蟲技能,所以本文選擇了「豌豆莢」這個網站。
標的是: 爬取該網站所有分類下的 App 資訊並下載 App 圖示,數量在 70,000 左右,比酷安升了一個數量級。
-
再次練習使用強大的 Scrapy 框架
之前只是初步地使用了 Scrapy 進行抓取,還沒有充分領會到 Scrapy 有多麼牛逼,所以本文嘗試深入使用 Scrapy,增加隨機 UserAgent、代理 IP 和圖片下載等設定。
-
對比一下酷安和豌豆莢兩個網站
相信很多人都在使用豌豆莢下載 App,我則使用酷安較多,所以也想比較一下這兩個網站有什麼異同點。
話不多說,下麵開始抓取流程。
1. 分析標的
首先,我們來瞭解一下要抓取的標的網頁是什麼樣的。
可以看到該網站上的 App 分成了很多類,包括:「應用播放」、「系統工具」等,一共有 14 個大類別,每個大類下又細分了多個小類,例如,影音播放下包括:「影片」、「直播」等。
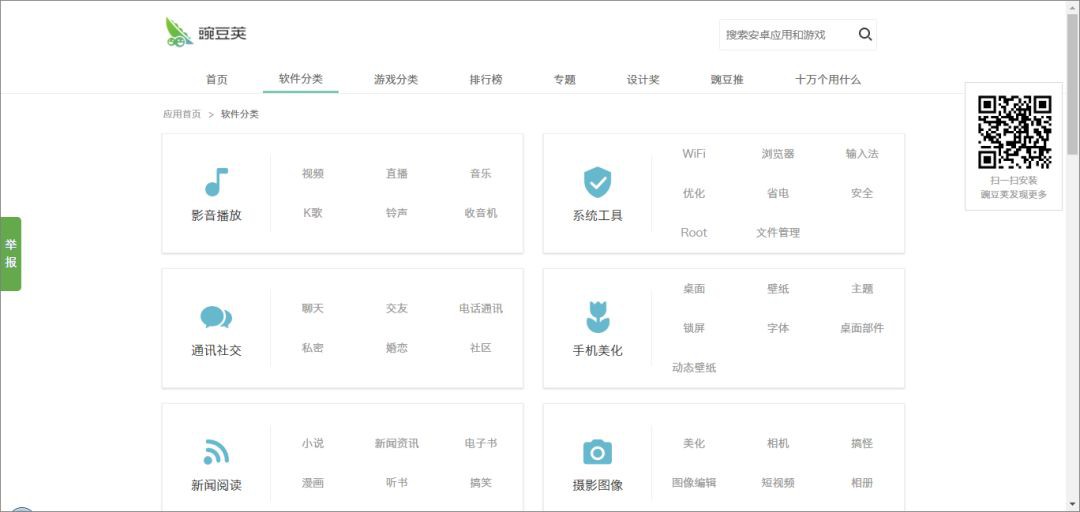
點選「影片」進入第二級子類頁面,可以看到每款 App 的部分資訊,包括:圖示、名稱、安裝數量、體積、評論等。
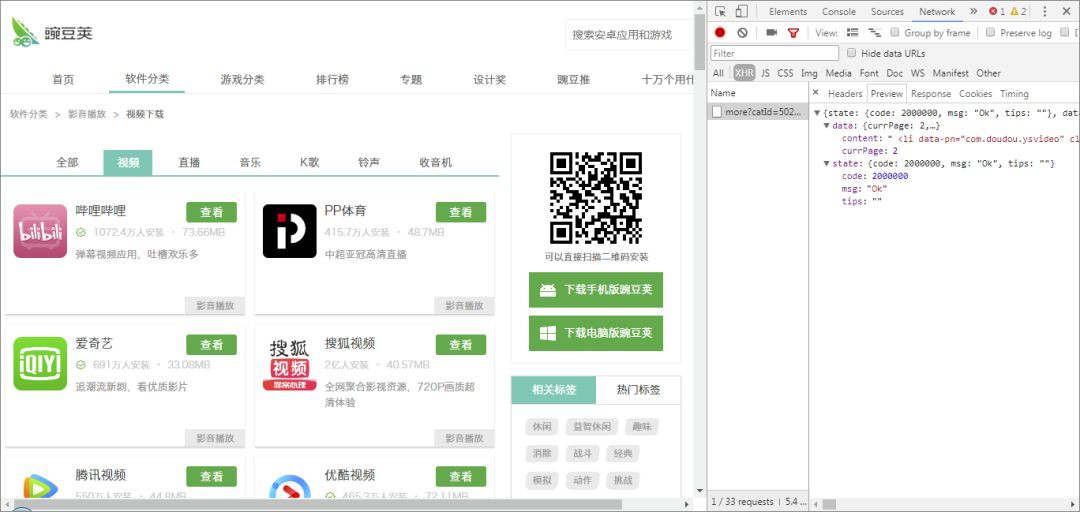
在之前的一篇文章中(見下方連結),我們分析了這個頁面:採用 AJAX 載入,GET 請求,引數很容易構造,但是具體頁數不確定,最後分別使用了 For 和 While 迴圈抓取了所有頁數的資料。
接著,我們可以再進入第三級頁面,也就是每款 App 的詳情頁,可以看到多了下載數、好評率、評論數這幾樣引數,抓取思路和第二級頁面大同小異,同時為了減小網站壓力,所以 App 詳情頁就不抓取了。
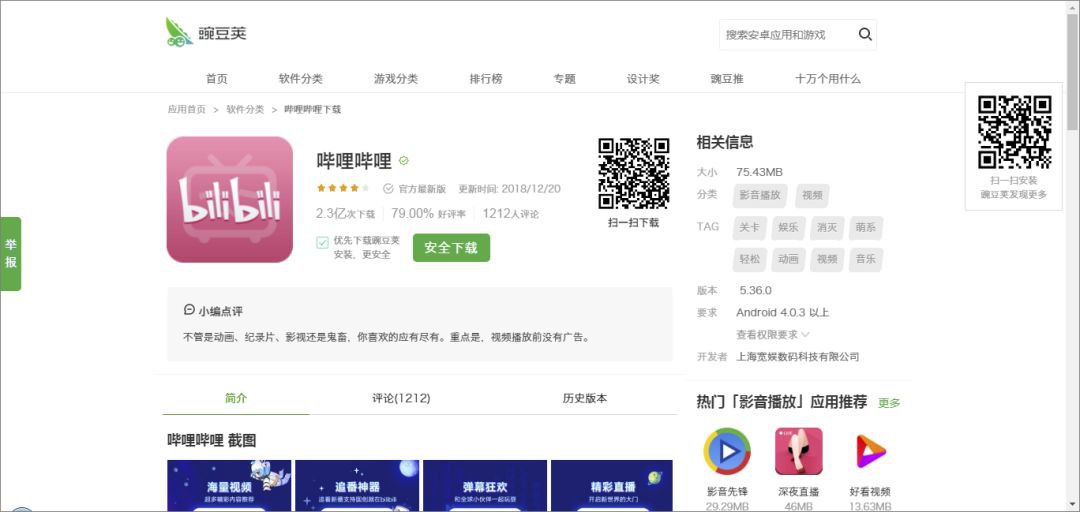
所以,這是一個分類多級頁面的抓取問題,依次抓取每一個大類下的全部子類資料。
學會了這種抓取思路,很多網站我們都可以去抓,比如很多人愛爬的「豆瓣電影」也是這樣的結構。
2. 分析內容
資料抓取完成後,本文主要是對分型別資料的進行簡單的探索性分析,包括這麼幾個方面:
-
下載量最多 / 最少的 App 總排名
-
下載量最多 / 最少的 App 分類 / 子分類排名
-
App 下載量區間分佈
-
App 名稱重名的有多少
-
和酷安 App 進行對比
3. 分析工具
-
Python
-
Scrapy
-
MongoDB
-
Pyecharts
-
Matplotlib
02 資料抓取
1. 網站分析
我們剛才已經初步對網站進行了分析,大致思路可以分為兩步,首先是提取所有子類的 URL 連結,然後分別抓取每個 URL 下的 App 資訊就行了。
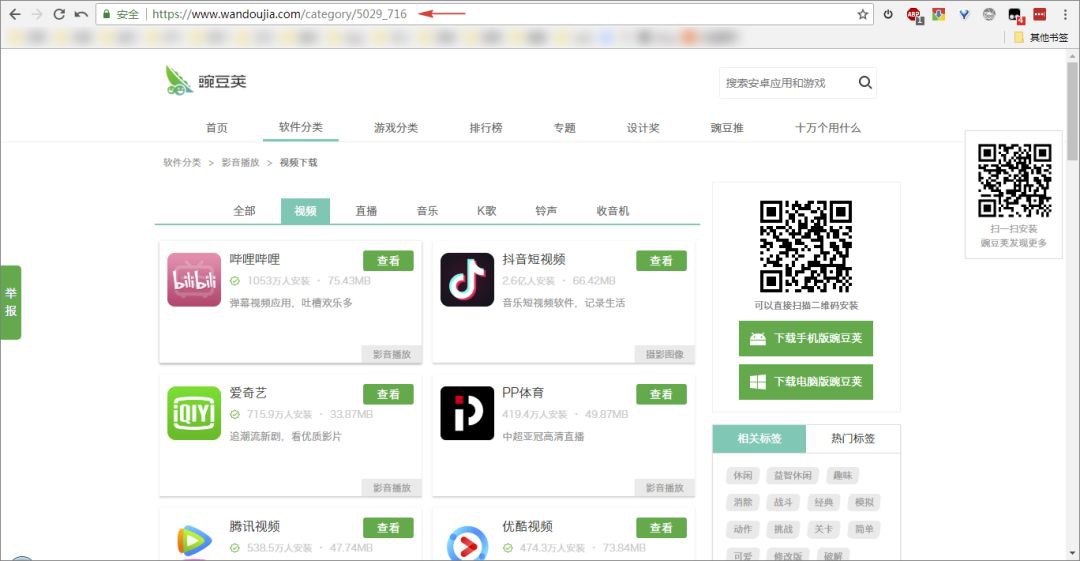
可以看到,子類的 URL 是由兩個數字構成,前面的數字表示分類編號,後面的數字表示子分類編號,得到了這兩個編號,就可以抓取該分類下的所有 App 資訊,那麼怎麼獲取這兩個數值程式碼呢?
回到分類頁面,定位檢視資訊,可以看到分類資訊都包裹在每個 li 節點中,子分類 URL 則又在子節點 a 的 href 屬性中,大分類一共有 14 個,子分類一共有 88 個。
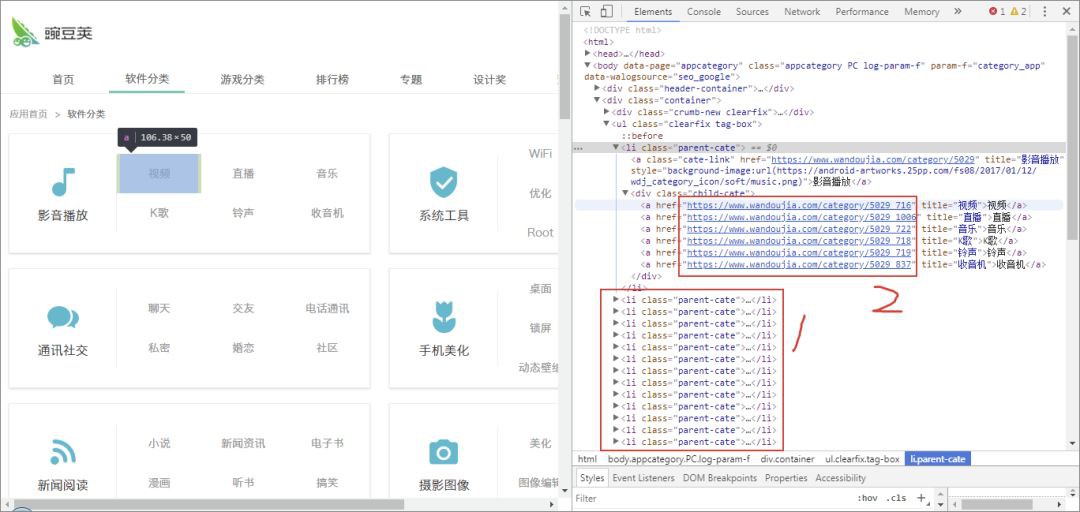
到這兒,思路就很清晰了,我們可以用 CSS 提取出全部子分類的 URL,然後分別抓取所需資訊即可。
另外還需註意一點,該網站的首頁資訊是靜態載入的,從第 2 頁開始是採用了 Ajax 動態載入,URL 不同,需要分別進行解析提取。
2. Scrapy抓取
我們要爬取兩部分內容,一是 APP 的資料資訊,包括前面所說的:名稱、安裝數量、體積、評論等,二是下載每款 App 的圖示,分檔案夾進行存放。
由於該網站有一定的反爬措施,所以我們需要新增隨機 UA 和代理 IP,這裡隨機 UA 使用 scrapy-fake-useragent 庫,一行程式碼就能搞定,代理 IP 直接上阿布雲付費代理,幾塊錢搞定簡單省事。
下麵,就直接上程式碼了。
items.py
1import scrapy
2
3class WandoujiaItem(scrapy.Item):
4 cate_name = scrapy.Field() #分類名
5 child_cate_name = scrapy.Field() #分類編號
6 app_name = scrapy.Field() # 子分類名
7 install = scrapy.Field() # 子分類編號
8 volume = scrapy.Field() # 體積
9 comment = scrapy.Field() # 評論
10 icon_url = scrapy.Field() # 圖示url
middles.py
中介軟體主要用於設定代理 IP。
1import base64
2proxyServer = "http://http-dyn.abuyun.com:9020"
3proxyUser = "你的資訊"
4proxyPass = "你的資訊"
5
6proxyAuth = "Basic " + base64.urlsafe_b64encode(bytes((proxyUser + ":" + proxyPass), "ascii")).decode("utf8")
7class AbuyunProxyMiddleware(object):
8 def process_request(self, request, spider):
9 request.meta["proxy"] = proxyServer
10 request.essay-headers["Proxy-Authorization"] = proxyAuth
11 logging.debug('Using Proxy:%s'%proxyServer)
pipelines.py
該檔案用於儲存資料到 MongoDB 和下載圖示到分類檔案夾中。
儲存到 MongoDB:
1MongoDB 儲存
2class MongoPipeline(object):
3 def __init__(self,mongo_url,mongo_db):
4 self.mongo_url = mongo_url
5 self.mongo_db = mongo_db
6
7 @classmethod
8 def from_crawler(cls,crawler):
9 return cls(
10 mongo_url = crawler.settings.get('MONGO_URL'),
11 mongo_db = crawler.settings.get('MONGO_DB')
12 )
13
14 def open_spider(self,spider):
15 self.client = pymongo.MongoClient(self.mongo_url)
16 self.db = self.client[self.mongo_db]
17
18 def process_item(self,item,spider):
19 name = item.__class__.__name__
20 # self.db[name].insert(dict(item))
21 self.db[name].update_one(item, {'$set': item}, upsert=True)
22 return item
23
24 def close_spider(self,spider):
25 self.client.close()
按檔案夾下載圖示:
1# 分檔案夾下載
2class ImagedownloadPipeline(ImagesPipeline):
3 def get_media_requests(self,item,info):
4 if item['icon_url']:
5 yield scrapy.Request(item['icon_url'],meta={'item':item})
6
7 def file_path(self, request, response=None, info=None):
8 name = request.meta['item']['app_name']
9 cate_name = request.meta['item']['cate_name']
10 child_cate_name = request.meta['item']['child_cate_name']
11
12 path1 = r'/wandoujia/%s/%s' %(cate_name,child_cate_name)
13 path = r'{}\{}.{}'.format(path1, name, 'jpg')
14 return path
15
16 def item_completed(self,results,item,info):
17 image_path = [x['path'] for ok,x in results if ok]
18 if not image_path:
19 raise DropItem('Item contains no images')
20 return item
settings.py
1BOT_NAME = 'wandoujia'
2SPIDER_MODULES = ['wandoujia.spiders']
3NEWSPIDER_MODULE = 'wandoujia.spiders'
4
5MONGO_URL = 'localhost'
6MONGO_DB = 'wandoujia'
7
8# 是否遵循機器人規則
9ROBOTSTXT_OBEY = False
10# 下載設定延遲 由於買的阿布雲一秒只能請求5次,所以每個請求設定了 0.2s延遲
11DOWNLOAD_DELAY = 0.2
12
13DOWNLOADER_MIDDLEWARES = {
14 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
15 'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 100, # 隨機UA
16 'wandoujia.middlewares.AbuyunProxyMiddleware': 200 # 阿布雲代理
17 )
18
19ITEM_PIPELINES = {
20 'wandoujia.pipelines.MongoPipeline': 300,
21 'wandoujia.pipelines.ImagedownloadPipeline': 400,
22}
23
24# URL不去重
25DUPEFILTER_CLASS = 'scrapy.dupefilters.BaseDupeFilter'
wandou.py
主程式這裡列出關鍵的部分:
1def __init__(self):
2 self.cate_url = 'https://www.wandoujia.com/category/app'
3 # 子分類首頁url
4 self.url = 'https://www.wandoujia.com/category/'
5 # 子分類 ajax請求頁url
6 self.ajax_url = 'https://www.wandoujia.com/wdjweb/api/category/more?'
7 # 實體化分類標簽
8 self.wandou_category = Get_category()
9def start_requests(self):
10 yield scrapy.Request(self.cate_url,callback=self.get_category)
11
12def get_category(self,response):
13 cate_content = self.wandou_category.parse_category(response)
14 # ...
這裡,首先定義幾個 URL,包括:分類頁面、子分類首頁、子分類 AJAX 頁,也就是第 2 頁開始的 URL,然後又定義了一個類 Get_category() 專門用於提取全部的子分類 URL,稍後我們將展開該類的程式碼。
程式從 start_requests 開始執行,解析首頁獲得響應,呼叫 get_category() 方法,然後使用 Get_category() 類中的 parse_category() 方法提取出所有 URL,具體程式碼如下:
1class Get_category():
2 def parse_category(self, response):
3 category = response.css('.parent-cate')
4 data = [{
5 'cate_name': item.css('.cate-link::text').extract_first(),
6 'cate_code': self.get_category_code(item),
7 'child_cate_codes': self.get_child_category(item),
8 } for item in category]
9 return data
10
11 # 獲取所有主分類標簽數值程式碼
12 def get_category_code(self, item):
13 cate_url = item.css('.cate-link::attr("href")').extract_first()
14 pattern = re.compile(r'.*/(\d+)') # 提取主類標簽程式碼
15 cate_code = re.search(pattern, cate_url)
16 return cate_code.group(1)
17
18 # 獲取所有子分類名稱和編碼
19 def get_child_category(self, item):
20 child_cate = item.css('.child-cate a')
21 child_cate_url = [{
22 'child_cate_name': child.css('::text').extract_first(),
23 'child_cate_code': self.get_child_category_code(child)
24 } for child in child_cate]
25 return child_cate_url
26
27 # 正則提取子分類編碼
28 def get_child_category_code(self, child):
29 child_cate_url = child.css('::attr("href")').extract_first()
30 pattern = re.compile(r'.*_(\d+)') # 提取小類標簽編號
31 child_cate_code = re.search(pattern, child_cate_url)
32 return child_cate_code.group(1)
這裡,除了分類名稱 cate_name 可以很方便地直接提取出來,分類編碼和子分類的子分類的名稱和編碼,我們使用了 get_category_code() 等三個方法進行提取。提取方法使用了 CSS 和正則運算式,比較簡單。
最終提取的分類名稱和編碼結果如下,利用這些編碼,我們就可以構造 URL 請求開始提取每個子分類下的 App 資訊了。
1{'cate_name': '影音播放', 'cate_code': '5029', 'child_cate_codes': [
2 {'child_cate_name': '影片', 'child_cate_code': '716'},
3 {'child_cate_name': '直播', 'child_cate_code': '1006'},
4 ...
5 ]},
6{'cate_name': '系統工具', 'cate_code': '5018', 'child_cate_codes': [
7 {'child_cate_name': 'WiFi', 'child_cate_code': '895'},
8 {'child_cate_name': '瀏覽器', 'child_cate_code': '599'},
9 ...
10 ]},
11...
接著前面的 get_category() 繼續往下寫,提取 App 的資訊:
1def get_category(self,response):
2 cate_content = self.wandou_category.parse_category(response)
3 # ...
4 for item in cate_content:
5 child_cate = item['child_cate_codes']
6 for cate in child_cate:
7 cate_code = item['cate_code']
8 cate_name = item['cate_name']
9 child_cate_code = cate['child_cate_code']
10 child_cate_name = cate['child_cate_name']
11
12 page = 1 # 設定爬取起始頁數
13 if page == 1:
14 # 構造首頁url
15 category_url = '{}{}_{}' .format(self.url, cate_code, child_cate_code)
16 else:
17 params = {
18 'catId': cate_code, # 類別
19 'subCatId': child_cate_code, # 子類別
20 'page': page,
21 }
22 category_url = self.ajax_url + urlencode(params)
23 dict = {'page':page,'cate_name':cate_name,'cate_code':cate_code,'child_cate_name':child_cate_name,'child_cate_code':child_cate_code}
24 yield scrapy.Request(category_url,callback=self.parse,meta=dict)
這裡,依次提取出全部的分類名稱和編碼,用於構造請求的 URL。
由於首頁的 URL 和第 2 頁開始的 URL 形式不同,所以使用了 if 陳述句分別進行構造。接下來,請求該 URL 然後呼叫 self.parse() 方法進行解析,這裡使用了 meta 引數用於傳遞相關引數。
1def parse(self, response):
2 if len(response.body) >= 100: # 判斷該頁是否爬完,數值定為100是因為無內容時長度是87
3 page = response.meta['page']
4 cate_name = response.meta['cate_name']
5 cate_code = response.meta['cate_code']
6 child_cate_name = response.meta['child_cate_name']
7 child_cate_code = response.meta['child_cate_code']
8
9 if page == 1:
10 contents = response
11 else:
12 jsonresponse = json.loads(response.body_as_unicode())
13 contents = jsonresponse['data']['content']
14 # response 是json,json內容是html,html 為文字不能直接使用.css 提取,要先轉換
15 contents = scrapy.Selector(text=contents, type="html")
16
17 contents = contents.css('.card')
18 for content in contents:
19 # num += 1
20 item = WandoujiaItem()
21 item['cate_name'] = cate_name
22 item['child_cate_name'] = child_cate_name
23 item['app_name'] = self.clean_name(content.css('.name::text').extract_first())
24 item['install'] = content.css('.install-count::text').extract_first()
25 item['volume'] = content.css('.meta span:last-child::text').extract_first()
26 item['comment'] = content.css('.comment::text').extract_first().strip()
27 item['icon_url'] = self.get_icon_url(content.css('.icon-wrap a img'),page)
28 yield item
29
30 # 遞迴爬下一頁
31 page += 1
32 params = {
33 'catId': cate_code, # 大類別
34 'subCatId': child_cate_code, # 小類別
35 'page': page,
36 }
37 ajax_url = self.ajax_url + urlencode(params)
38 dict = {'page':page,'cate_name':cate_name,'cate_code':cate_code,'child_cate_name':child_cate_name,'child_cate_code':child_cate_code}
39 yield scrapy.Request(ajax_url,callback=self.parse,meta=dict)
最後,parse() 方法用來解析提取最終我們需要的 App 名稱、安裝量等資訊,解析完成一頁後,page 進行遞增,然後重覆呼叫 parse() 方法迴圈解析,直到解析完全部分類的最後一頁。
最終,幾個小時後,我們就可以完成全部 App 資訊的抓取,我這裡得到 73,755 條資訊和 72,150 個圖示,兩個數值不一樣是因為有些 App 只有資訊沒有圖示。
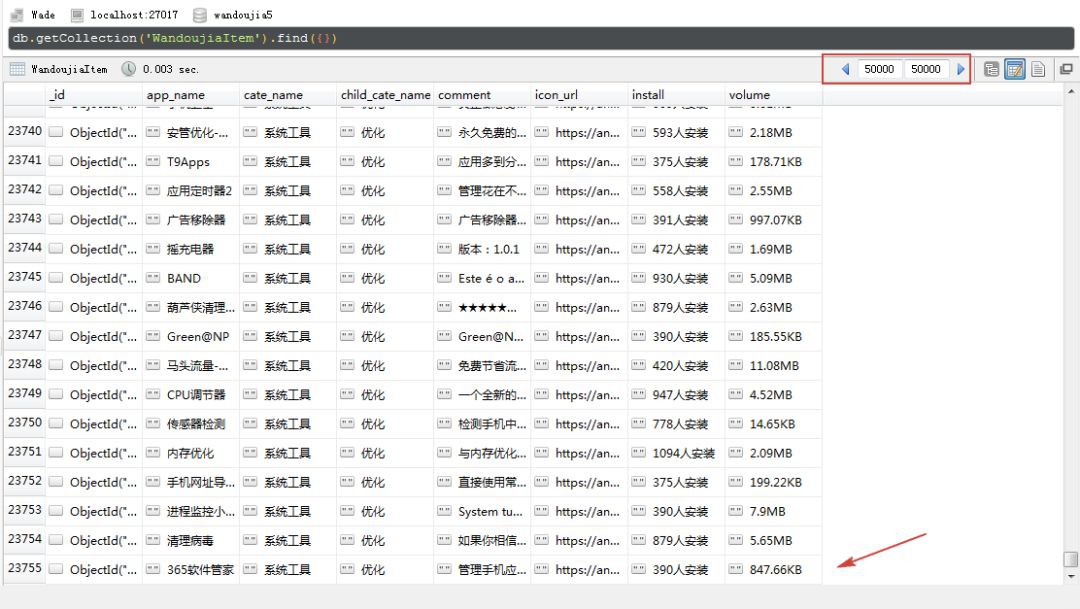
圖示下載:
下麵將對提取的資訊,進行簡單的探索性分析。
03 資料分析
1. 總體情況
首先來看一下 App 的安裝量情況,畢竟 70000 多款 App,自然很感興趣哪些 App 使用地最多,哪些又使用地最少。
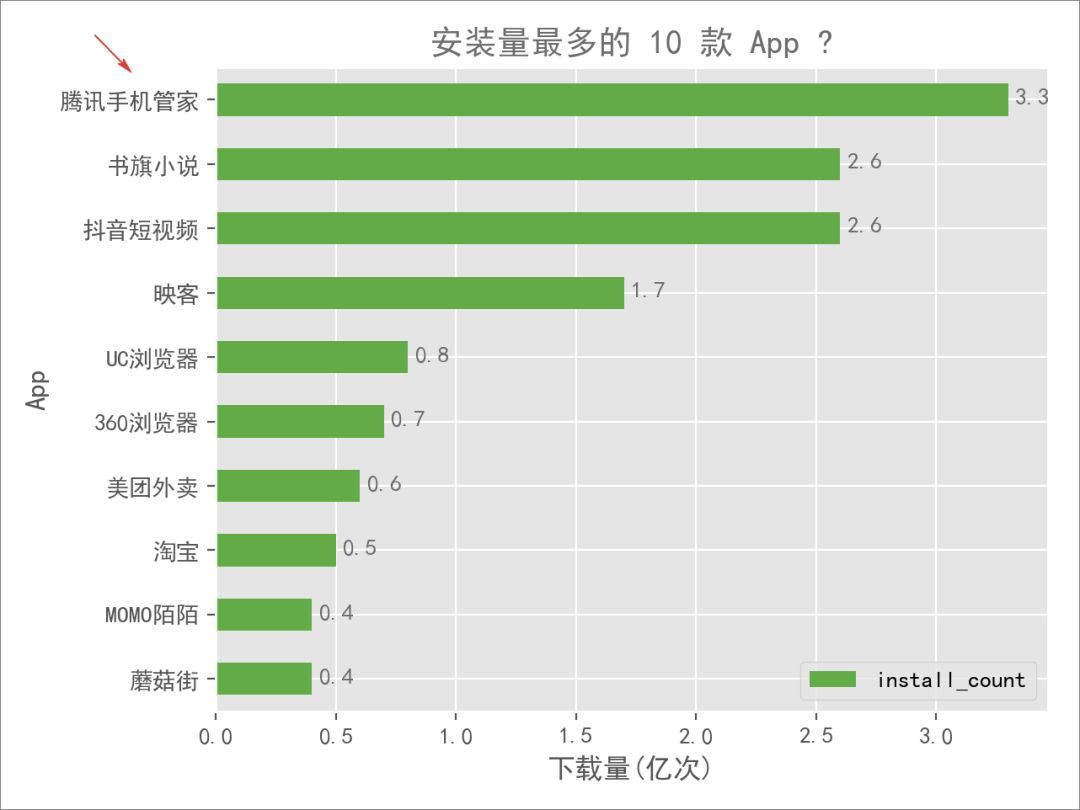
程式碼實現如下:
1plt.style.use('ggplot')
2colors = '#6D6D6D' #字型顏色
3colorline = '#63AB47' #紅色CC2824 #豌豆莢綠
4fontsize_title = 20
5fontsize_text = 10
6
7# 下載量總排名
8def analysis_maxmin(data):
9 data_max = (data[:10]).sort_values(by='install_count')
10 data_max['install_count'] = (data_max['install_count'] / 100000000).round(1)
11 data_max.plot.barh(x='app_name',y='install_count',color=colorline)
12 for y, x in enumerate(list((data_max['install_count']))):
13 plt.text(x + 0.1, y - 0.08, '%s' %
14 round(x, 1), ha='center', color=colors)
15
16 plt.title('安裝量最多的 10 款 App ?',color=colors)
17 plt.xlabel('下載量(億次)')
18 plt.ylabel('App')
19 plt.tight_layout()
20 # plt.savefig('安裝量最多的App.png',dpi=200)
21 plt.show()
看了上圖,有兩個「沒想到」:
-
排名第一的居然是一款手機管理軟體
對豌豆莢網上的這個第一名感到意外,一是、好奇大家都那麼愛手機清理或者怕中毒麼?畢竟,我自己的手機都「裸奔」了好些年;二是、第一名居然不是鵝廠的其他產品,比如:微信或者QQ。
-
榜單放眼望去,以為會出現的沒有出現,沒有想到的卻出現了
前十名中,居然出現了書旗小說、印客這些比較少聽過的名字,而國民 App 微信、支付寶等甚至都沒有出現在這個榜單中。
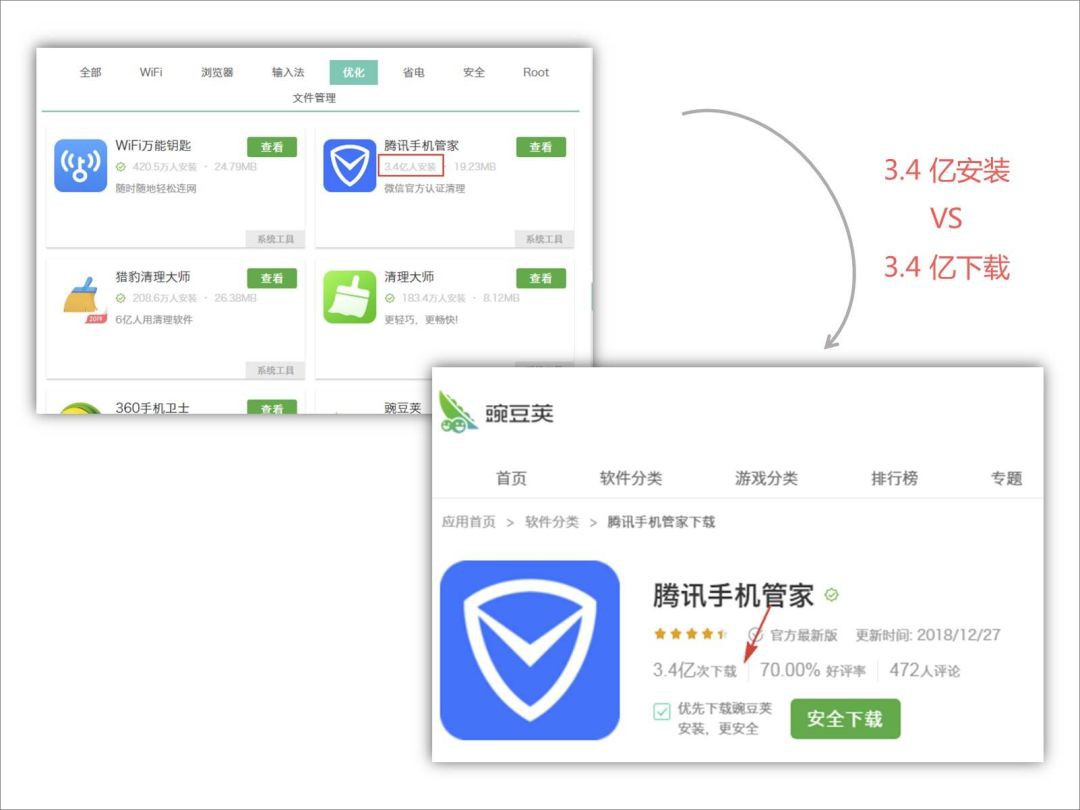
帶著疑問和好奇,分別找到了「騰訊手機管家」和「微信」兩款 App 的主頁:
騰訊手機管家下載和安裝量:
微信下載和安裝量:
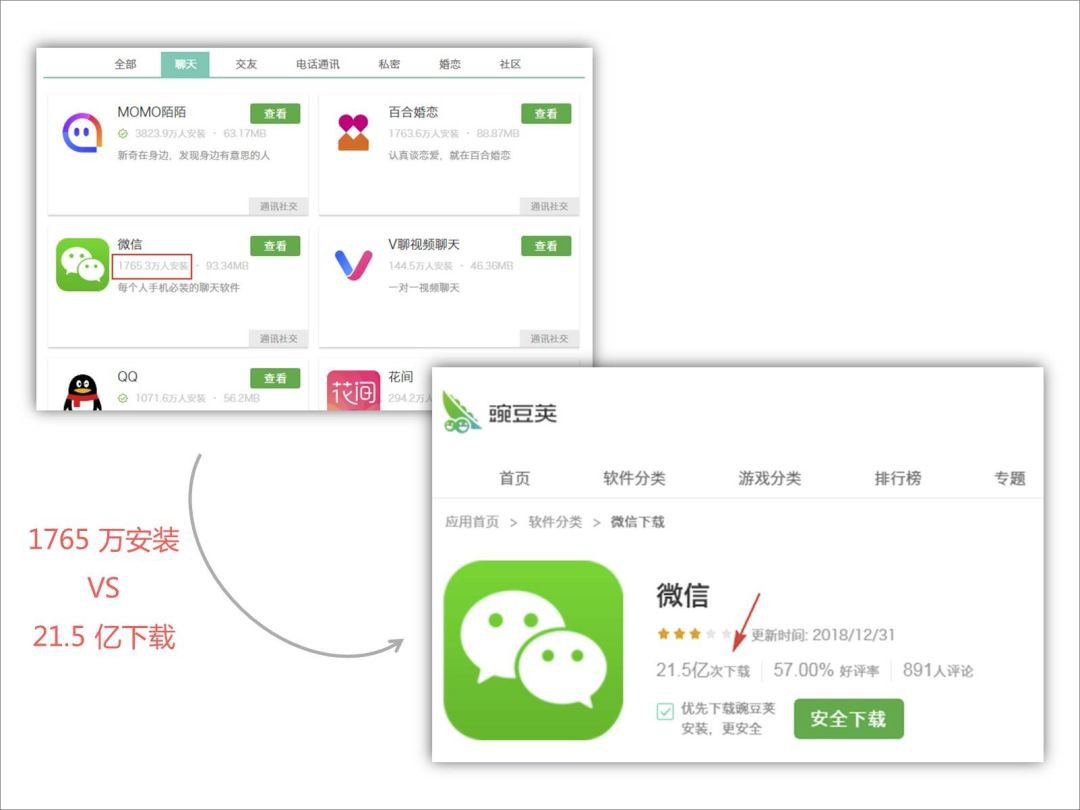
這是什麼情況???
騰訊管家 3 億多的下載量等同於安裝量,而微信 20 多億的下載量,只有區區一千多萬的安裝量,兩組資料對比,大致反映了兩個問題:
-
要麼是騰訊管家的下載量實際並沒有那麼多
-
要麼是微信的下載量寫少了
不管是哪個問題,都反映了一個問題:該網站做得不夠走心啊。
為了證明這個觀點,將前十名的安裝量和下載量都作了對比,發現很多 App 的安裝量和下載量是一樣的,也就是說:這些 App 的實際安裝量並沒有那麼多,而如果這樣的話,那麼這份榜單就有很大水分了。
難道,辛辛苦苦爬了那麼久,就得到這樣的結果?
不死心,接著再看看安裝量最少的 App 是什麼情況,這裡找出了其中最少的 10 款:
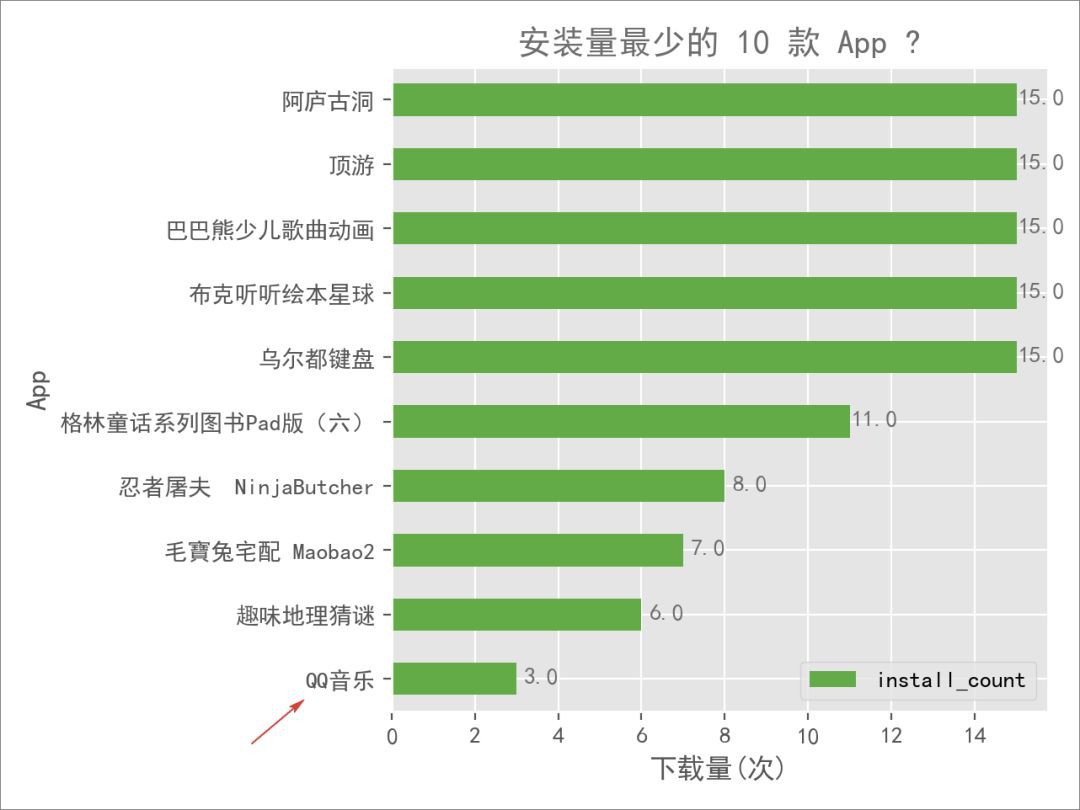
掃了一眼,更加沒想到了:
「QQ 音樂」竟然是倒數第一,只有 3 次安裝量!
這和剛剛上市、市值千億的 QQ 音樂是同一款產品?
再次核實了一下:
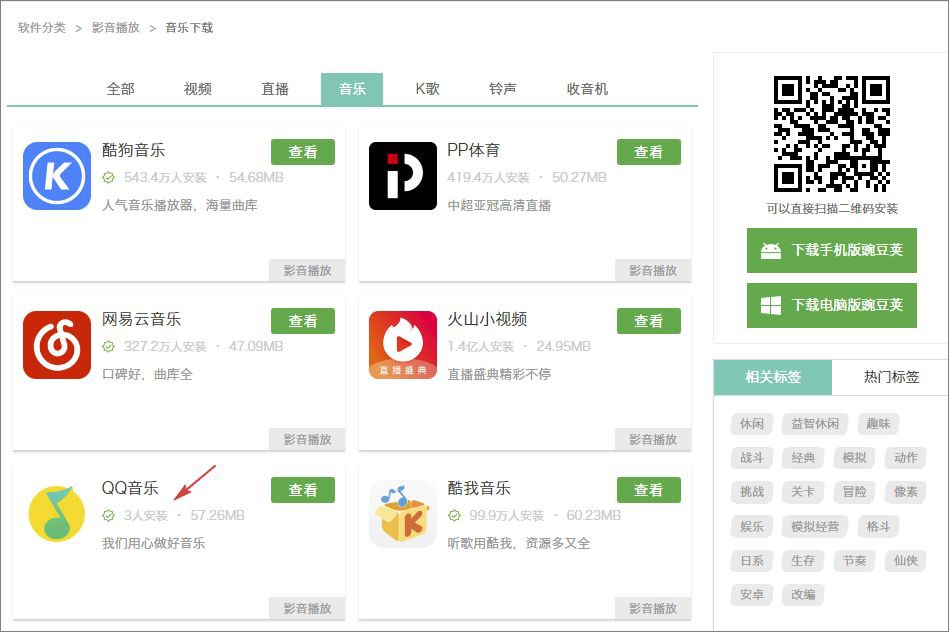
沒有看錯,是寫著3人安裝!
這是已經不走心到什麼程度了?這個安裝量,鵝廠還能「用心做好音樂」?
說實話,到這兒已經不想再往下分析下去了,擔心爬扒出更多沒想到的東西,不過辛苦爬了這麼久,還是再往下看看吧。
看了首尾,我們再看看整體,瞭解一下全部 App 的安裝數量分佈,這裡去除了有很大水分的前十名 App。
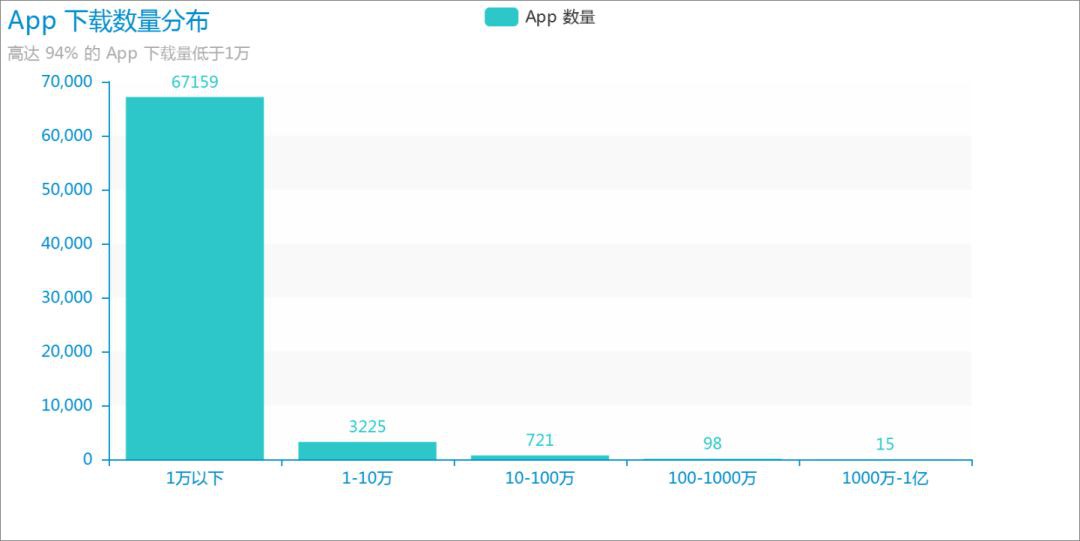
很驚訝地發現,竟然有多達 67,195 款,佔總數的 94% 的 App 的安裝量不足 1萬!
如果這個網站的所有資料都是真的話,那麼上面排名第一的手機管家,它一款就差不多抵得上這 6 萬多款 App 的安裝量!
對於多數 App 開發者,只能說:現實很殘酷,辛辛苦苦開發出來的 App,使用者不超過 1萬人的可能性高達近 95%。
程式碼實現如下:
1def analysis_distribution(data):
2 data = data.loc[10:,:]
3 data['install_count'] = data['install_count'].apply(lambda x:x/10000)
4 bins = [0,1,10,100,1000,10000]
5 group_names = ['1萬以下','1-10萬','10-100萬','100-1000萬','1000萬-1億']
6 cats = pd.cut(data['install_count'],bins,labels=group_names)
7 cats = pd.value_counts(cats)
8 bar = Bar('App 下載數量分佈','高達 94% 的 App 下載量低於1萬')
9 bar.use_theme('macarons')
10 bar.add(
11 'App 數量',
12 list(cats.index),
13 list(cats.values),
14 is_label_show = True,
15 xaxis_interval = 0,
16 is_splitline_show = 0,
17 )
18 bar.render(path='App下載數量分佈.png',pixel_ration=1)
2. 分類情況
下麵,我們來看看各分類下的 App 情況,不再看安裝量,而看數量,以排出幹擾。
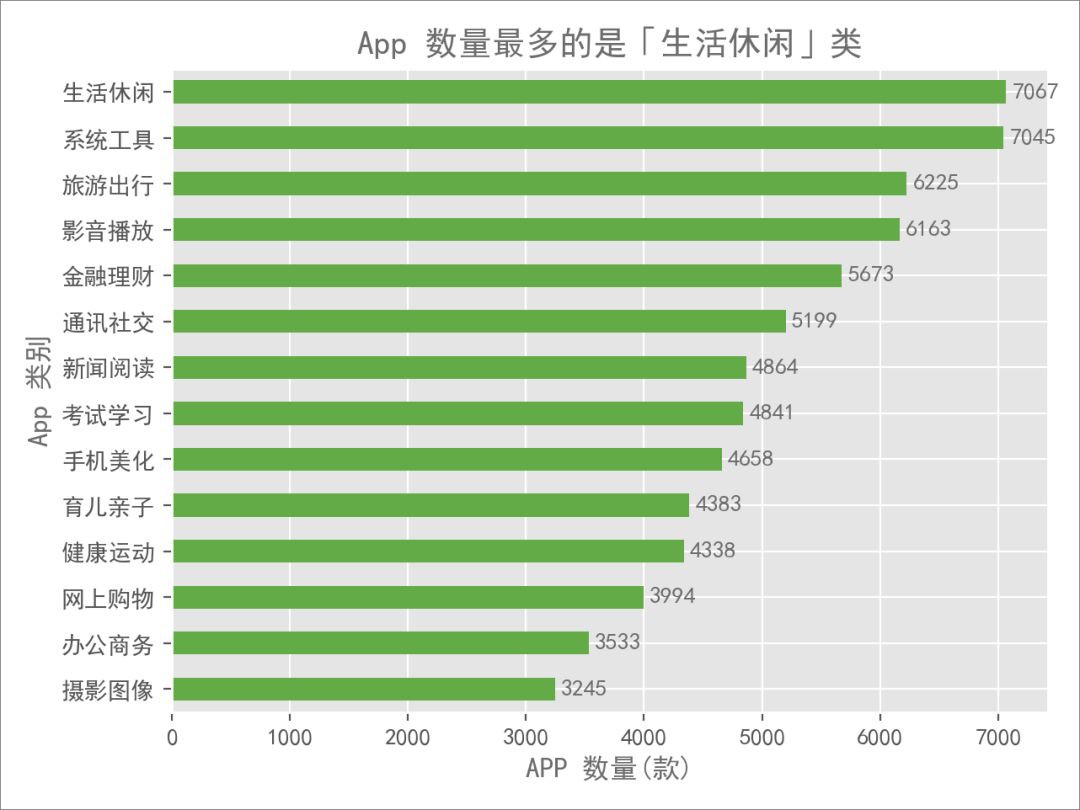
可以看到 14 個大分類中,每個分類的 App 數量差距都不大,數量最多的「生活休閑」是「攝影影象」的兩倍多一點。
接著,我們進一步看看 88 個子分類的 App 數量情況,篩選出數量最多和最少的 10 個子類:
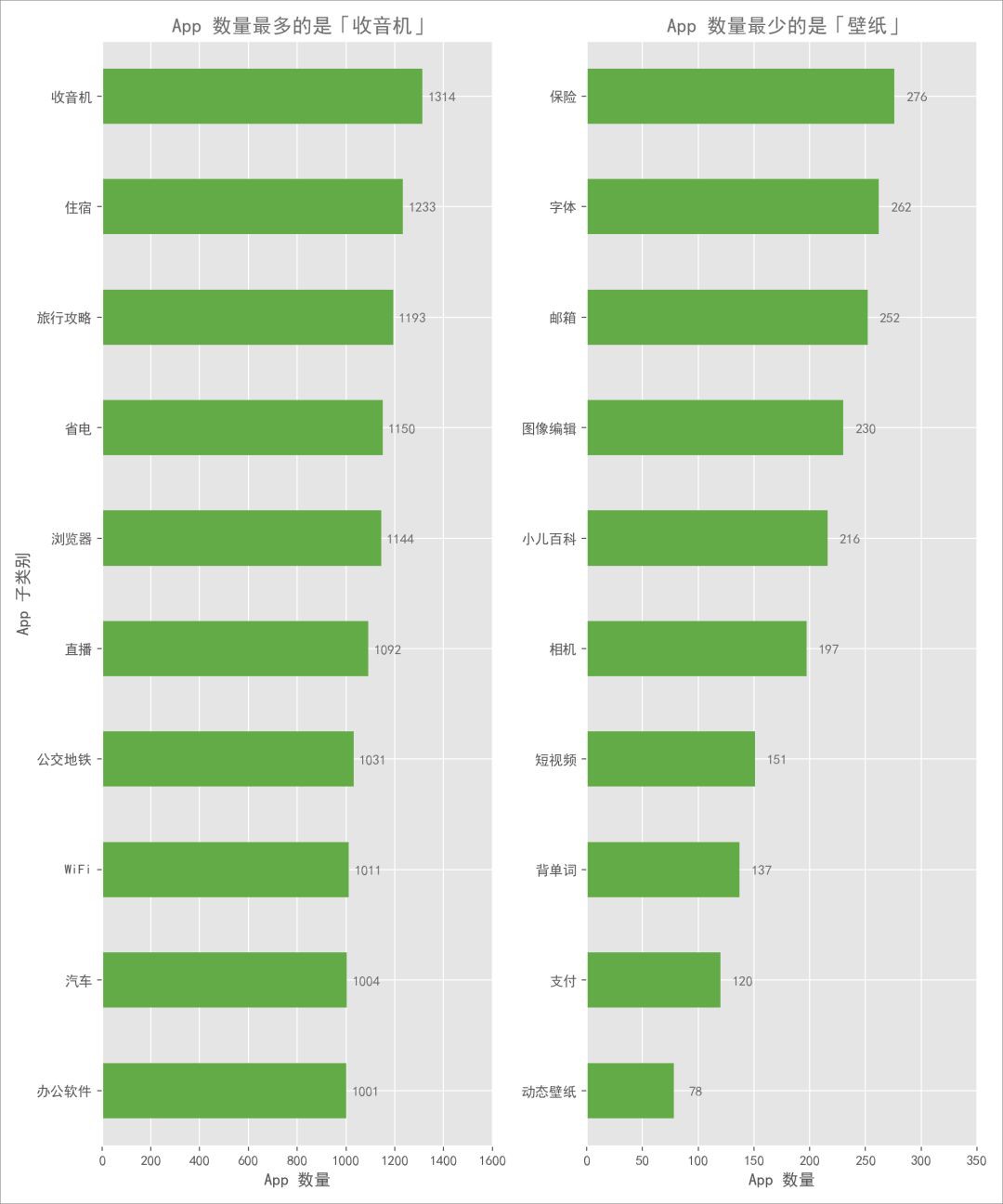
可以發現兩點有意思的現象:
-
「收音機」類別 App 數量最多,達到 1,300 多款
這個很意外,當下收音機完全可以說是個老古董了,居然還有那麼人去開發。
-
App 子類數量差距較大
最多的「收音機」是最少的「動態桌布」近 20 倍,如果我是一個 App 開發者,那我更願意去嘗試開發些小眾類的 App,競爭小一點,比如:「背單詞」、「小兒百科」這些。
看完了總體和分類情況,突然想到一個問題:這麼多 App,有沒有重名的呢?
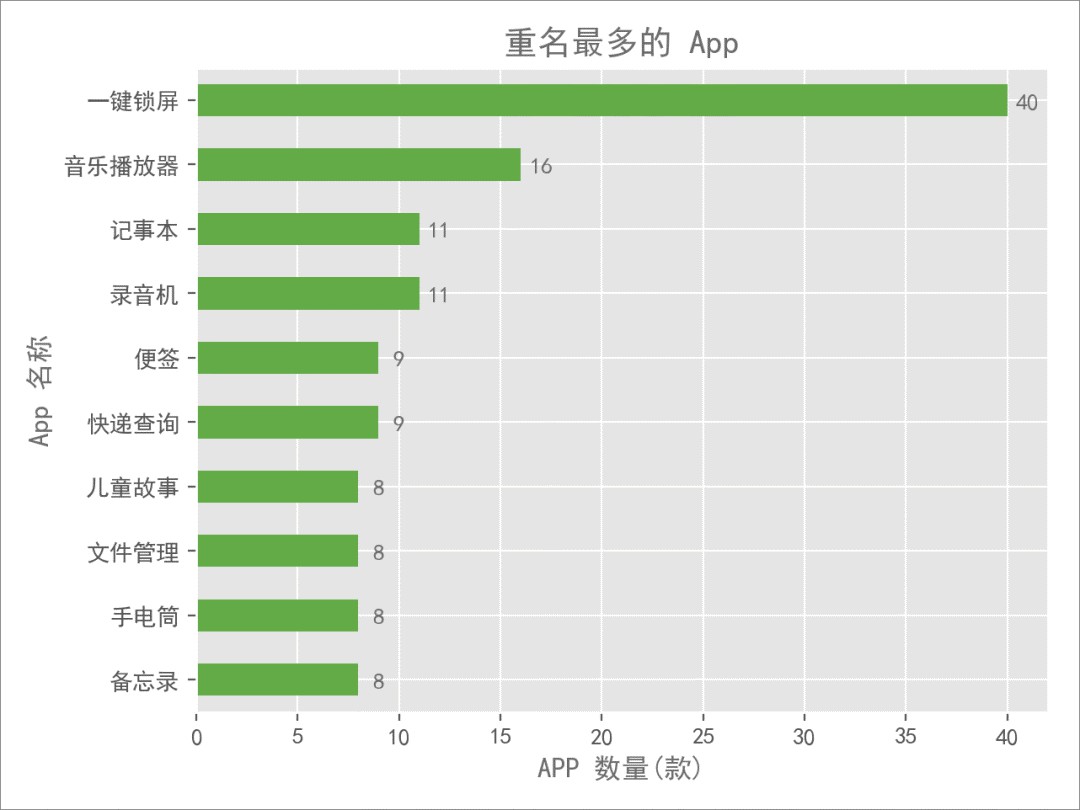
驚奇地發現,叫「一鍵鎖屏」的 App 多達 40 款,這個功能 App 很難再想出別的名字了麼? 現在很多手機都支援觸控鎖屏了,比一鍵鎖屏操作更加方便。
接下來,我們簡單對比下豌豆莢和酷安兩個網站的 App 情況。
3. 對比酷安
二者最直觀的一個區別是在 App 數量上,豌豆莢擁有絕對的優勢,達到了酷安的十倍之多,那麼我們自然感興趣:
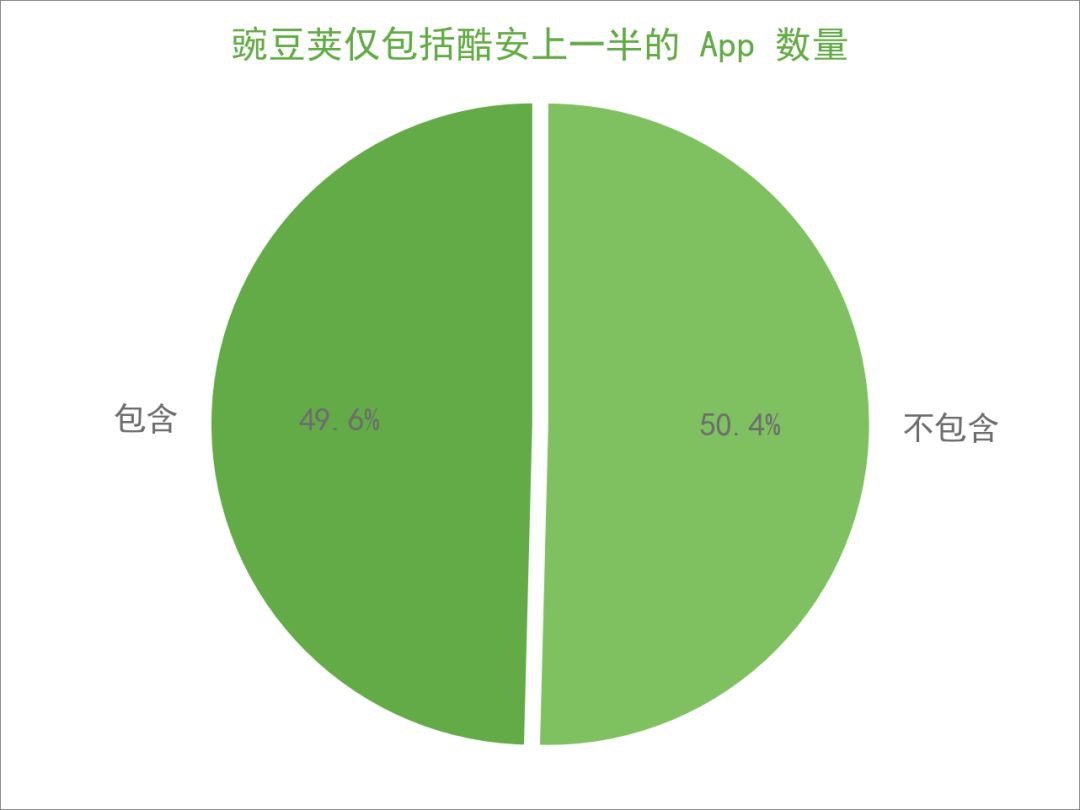
豌豆莢是否包括了酷安上所有的 App ?
如果是,「你有的我都有,你沒有的我也有」,那麼酷安就沒什麼優勢了。統計之後,發現豌豆莢僅包括了 3,018 款,也就是一半左右,剩下的另一半則沒有包括。
這裡面固然存在兩個平臺上 App 名稱不一致的現象,但更有理由相信酷安很多小眾的精品 App 是獨有的,豌豆莢裡並沒有。
程式碼實現如下:
1include = data3.shape[0]
2notinclude = data2.shape[0] - data3.shape[0]
3sizes= [include,notinclude]
4labels = [u'包含',u'不包含']
5explode = [0,0.05]
6plt.pie(
7 sizes,
8 autopct = '%.1f%%',
9 labels = labels,
10 colors = [colorline,'#7FC161'], # 豌豆莢綠
11 shadow = False,
12 startangle = 90,
13 explode = explode,
14 textprops = {'fontsize':14,'color':colors}
15)
16plt.title('豌豆莢僅包括酷安上一半的 App 數量',color=colorline,fontsize=16)
17plt.axis('equal')
18plt.axis('off')
19plt.tight_layout()
20plt.savefig('包含不保包含對比.png',dpi=200)
21plt.show()
接下來,我們看看所包含的 App 當中,在兩個平臺上的下載量是怎麼樣的:
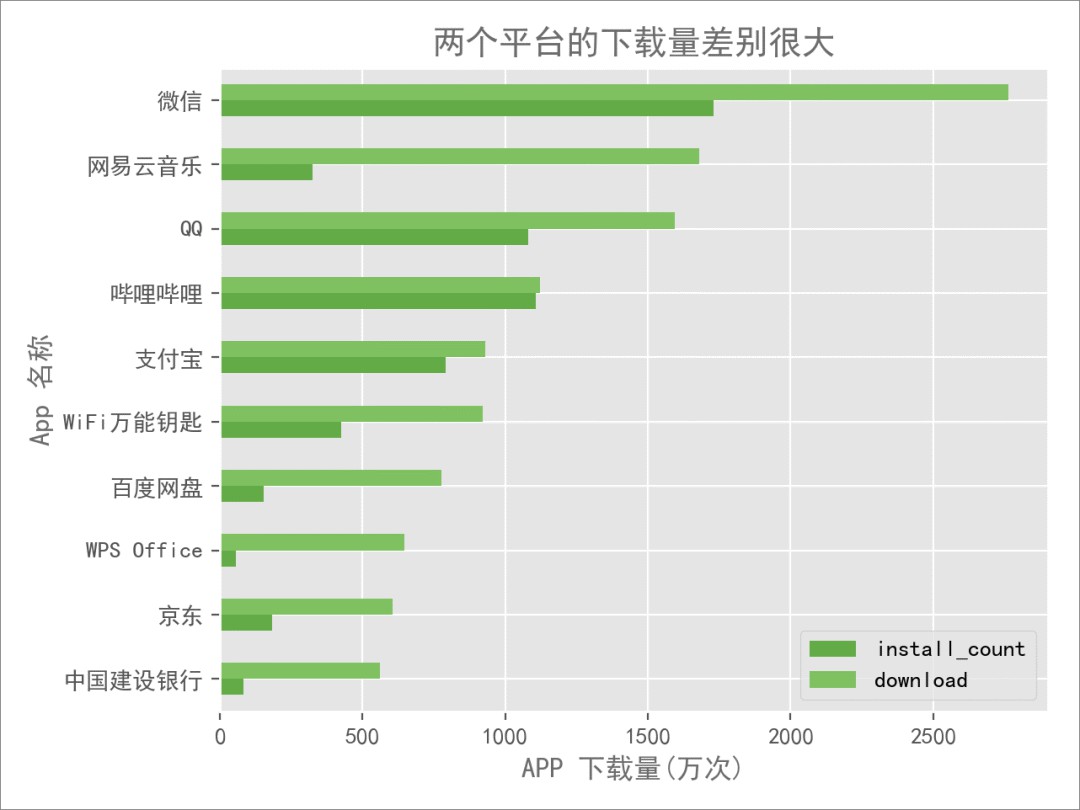
可以看到,兩個平臺上 App 下載數量差距還是很明顯。
最後,我面再看看豌豆莢上沒有包括哪些APP:
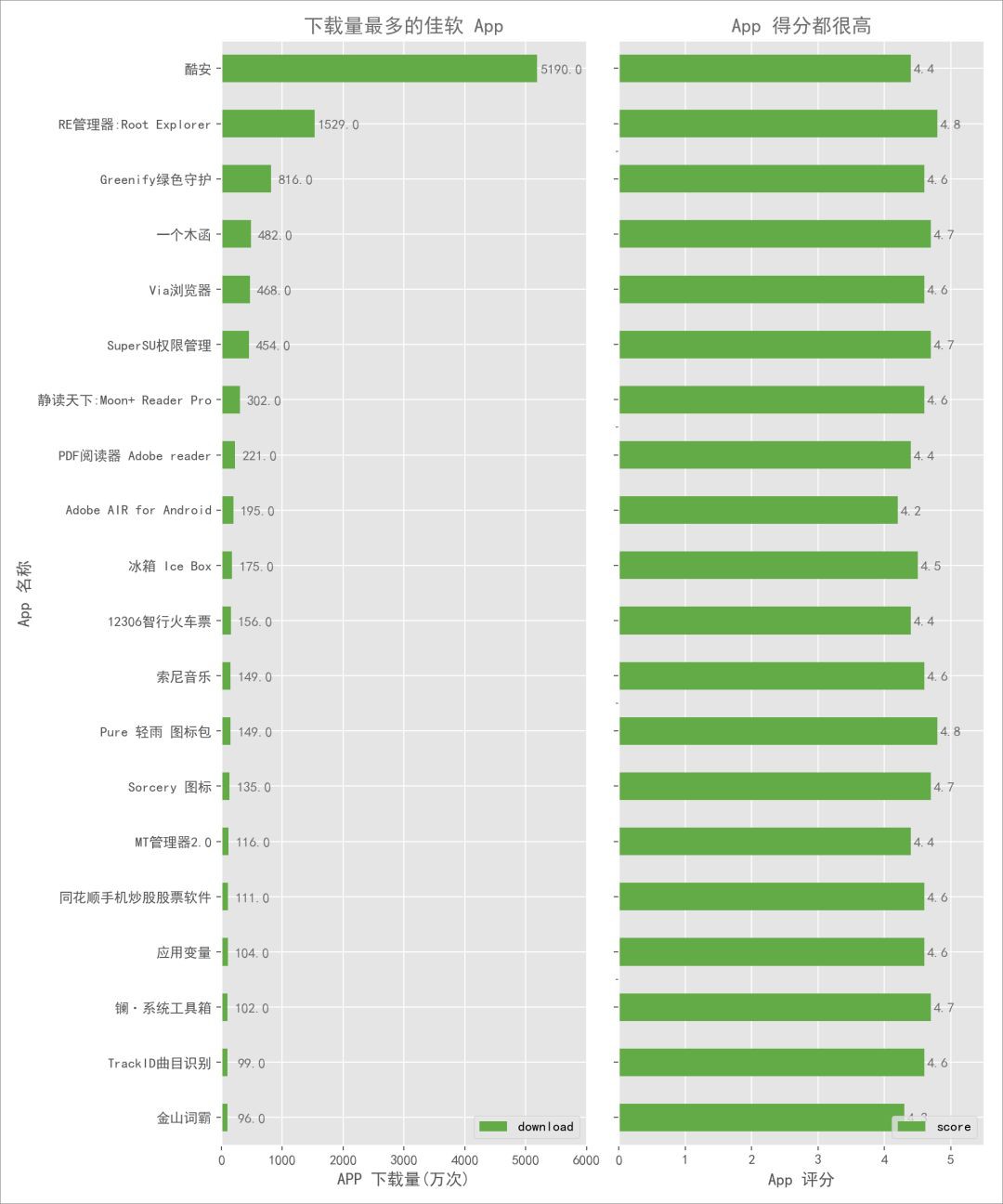
發現很多神器都沒有包括,比如:RE、綠色守護、一個木函等等。豌豆莢和酷安的對比就到這裡,如果用一句話來總結,我可能會說:
豌豆莢太牛逼了, App 數量是酷安的十倍,所以我選酷安。
以上,就是利用 Scrapy 爬取分類多級頁面併進行分析的一次實戰。

我們正在繪製一份大資料粉絲畫像——
2019大資料粉絲有獎調查問捲上線了
歡迎長按二維碼或點選閱讀原文填寫

我們每週一將從參與者中
隨機抽取3名幸運小夥伴
每位將獲贈近期出版的技術類圖書1本
更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單
大資料 | 揭秘 | 人工智慧 | AI
Python | 機器學習 | 深度學習 | 神經網路
視覺化 | 區塊鏈 | 乾貨 | 數學
猜你想看
Q: 你每天使用時間最長的App是哪個?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

