導語:業務快速增長給搜尋帶來什麼樣的挑戰?針對類似場景如何設計通用的平臺?本文詳細講述Airbnb大型搜尋服務的演進之路。
去年,Airbnb到了需要可擴充套件、分散式儲存系統的時候了。例如,搜尋個性化資料超過了單機的承載能力。當我們提升了個性化服務的縱向擴充套件能力的時候,意識到其他服務也有同樣的需求,因此決定設計一個通用平臺,簡化其他服務需要做的事情。
除了通常的請求/響應樣式,其他服務有不同的需求,例如,從資料源(例如,MySQL資料庫)做週期性批次同步,引入新的資料源(例如,新的搜尋特性),從資料流中消費增量更新(我們的場景中是Kafka),或者提供資料分析能力,並且為網站流量提供低延遲的資料服務。隨著公司的持續增長,我們有很多應用積累了越來越多的資料。如果我們能挖掘出有用的資訊並且反饋給應用,那麼這些資料可以為我們的產品提供巨大價值。
摘要
讓我們從個性化搜尋開始。這需要保留我們的使用者行為歷史。要求能記錄實時使用者行為,並且能立即獲得記錄,以最佳化個性化搜尋結果(並且改善其他產品)。提供其他應用能用的資料快照(例如分析或者驗證)。需要週期性的聚合併且截斷歷史資料,批次匯入一批特徵(離線計算)到系統中。
這些需求貫穿公司很多應用。因此我們決定設計一個通用儲存平臺,以支援這些需求,並幫助其他服務負責人聚焦他們特殊的業務邏輯。我們計劃在這個系統中滿足下麵這些需求:
-
為網站流量提供低延遲操作(毫秒級別)
-
實時資料流提供增量更新
-
便捷高效的資料批次操作
-
保證公司增長的資料和流量可擴充套件
-
維護成本小
註意,我們將“批次操作”定義為快照和壓縮完整儲存庫的操作,用新快照替換現有快照以進行服務,將完整的新訊號合併到儲存庫中,用新集合替換現有訊號資料以及完整資料集上的任何其他操作。Nebula是一個平臺,我們這個儲存上滿足了所有的這些需求。
什麼是Nebula?
Nebula是一個無樣式版本化的資料儲存服務,提供實時隨機資料訪問和離線批次資料管理。它包含一個支援增量資料(最近一段時間的更新)的動態資料儲存的獨立服務,和一個支援批次操作的靜態資料儲存的快照資料儲存。我們選擇DynamoDB作為動態資料儲存(主要原因是它有很低的讀延遲,使用AWS的維護成本低),和HFileService(Airbnb內部使用的可擴充套件的靜態儲存,支援分割槽和本地硬碟到HFile格式的預處理)儲存靜態的快照。
隨機資料訪問的抽象儲存
Nebula為底層物理儲存提供了統一的API。API為應用提供了通用K-V儲存API,增量和靜態資料內部合併,這樣,應用不需要為實時資料和批次資料分別部署。所以,它能靈活的遷移到不同的物理儲存,上層應用不需要修改API。
Nebula使用版本化列式儲存,類似於BigTable和HBase。版本化列式儲存比起原始K-V儲存,能讓服務負責人更便捷地定義他們的資料模型。必要的時候,版本能解決衝突和跟蹤資料變更時間。應用每行和列能存多少個版本沒有任何限制。
Nebula支援級別的原子操作。併發寫同樣的會有不同的版本,這樣資料能合理的儲存。每列都有自己的版本,並且所有的寫直接追加到各自的列上(透過版本儲存)。使用者隨機訪問需要透過給定獲取一個或者多個版本的資料。獲取多列或者多行的多次請求可以合併到一個單獨的多請求中。
使用個性化資料的一個例子,資料模型如下:
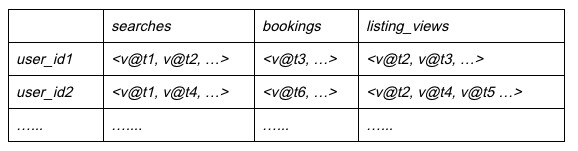
每行表示一個使用者的資料,每串列示一個使用者互動型別(又叫使用者事件),比如前面提到的搜尋,每個版本是使用者事件發生時候的時間戳。在產品中,我們有很多使用者事件,每個事件列積累了大量的不同時間戳的事件。
為了支援一個搜尋請求,搜尋服務查詢給定使用者對應的事件資料,用這些個性化資料在排序模型中決定向使用者展示的有序串列。因為這是搜尋請求路徑,所以我們有很嚴格的延遲和可用性要求。
資料能透過增量資料流(包含個人使用者事件)以單元格為單位和離線管道批次(壓縮歷史資料或者按列引導/合併/替換資料)的方式被更新。
內建批次資料處理
Nebula使用離線管道為每個倉庫的增量資料做快照,與前面的快照合併,然後使用新的快照提供服務。這些任務跟線上服務分開執行,對網站流量的影響非常小。
管道可以根據要求進行高階配置。例如,每個應用可以定義他們自己的策略,如何合併新老資料(例如,新資料改寫老資料,使用版本聚合,丟棄老資料等等),如何壓縮歷史資料(保留N個版本,刪除某段時間之前的資料等等),如何排程管道,等等。
Nebula給使用者提供定義良好的介面,用於他們定製資料並且自動載入到系統中。使用者可以將他們的資料放在公共的地方,修改一些Nebula配置,然後管道將選擇並且合併資料到系統中以供使用。
應用負責人能在資料快照上,將他們的特殊需求定製的邏輯放到管道上。他們的邏輯將在最新的快照資料上執行,所以,這是一個處理邏輯的有效方式。
在個性化搜尋場景中,我們在下列情況下使用管道:
-
定期生成快照,合併增量資料和靜態資料
-
按列進行壓縮和過濾過期事件,保證資料大小可控
-
離線特徵計算以建立新的特徵,批次匯入新特徵到儲存中
-
定製驗證使用者事件的邏輯,合理的狀態檢查
所有的個性化資料都版本化,不管什麼時候發現資料問題,Nebula可以回滾到以前的好快照,併在版本(時間戳)之前丟棄任何不良資料。回滾邏輯根據應用決定,但是Nebula的批次介面讓回滾邏輯實現很簡單。
架構
這是整個系統的架構(如下)和設計選型。

一個Nebula讀請求查詢兩個資料源。增量資料儲存僅僅包含最新的資料,快照儲存包含完整的資料。兩個儲存都支援讀查詢,但是隻有動態儲存接收寫請求。快照儲存的更新透過切換底層快照。資料儲存透過Zookeeper協作。
動態資料儲存DynamoDB
我們選擇DynamoDB是因為低延遲的要求,但是也可以根據其他要求使用其他的物理儲存(例如HBase)替換。作為Nebula的底層儲存,物理儲存只需要支援主鍵和排序二級索引。儘管底層實現不同上層介面卻是一致的,對於系統上的任何應用(和使用者)來說,替換物理儲存是透明的。
我們不準備去設計另外的物理儲存,使用DynamoDB作為底層的儲存能讓我們非常快速的組建一個系統。
資料輸入流被寫入動態儲存中;它允許隨機更新,並且支援很高的QPS。DynamoDB的讀延遲很低,所以能很好的滿足我們平均10毫秒的延遲要求。我們做了一個最佳化,為了保證DynamoDB表的大小容易管理,每天將資料分割槽到新的表。所以,我們的每個表僅僅佔據一部分DynamoDB的分割槽以保證有高的QPS。
批次資料儲存HFileService
Nebula根據動態更新合併起來的實時檢視的最新快照儲存在HFileService叢集中。
HFileService以低延遲高吞吐量從本地磁碟中提供靜態的HFiles(快照格式)。而且,資料載入過程對讀請求幾乎沒有影響,所以離線資料合併操作不影響對資料的實時訪問。
HFileService透過動態分片機制對資料分割槽,所以水平擴充套件能力依賴資料的總大小。儘管是靜態資料,複製策略非常簡單並且能隨著流量的增長去調整。
使用離線管道做快照、壓縮和定製邏輯
Nebula支援線上隨機資料訪問和批次操作。批次操作不影響線上訪問。下圖描述Nebula的離線架構:

定期從增量儲存匯出批次更新資料到分散式檔案系統(Amazon S3)。資料匯出之後,啟動一個離線Spark任務將批次更新和歷史資料合併。我們經常有其他的離線產生資料的情況,例如機器學習特徵,需要批次上傳到系統中。合併階段經常有這樣的情況,新快照透過合併批次更新、歷史資料和定製離線資料進行建立。我們在合併過程中新增合理的檢查,避免壞資料進入到我們的系統。
最新的快照存在S3上,等待下一輪合併。它也會被儲存到我們的歷史資料儲存中。貫穿整個匯出-合併-載入過程,實時儲存一直保留這些匯出到S3的增量資料,直到新的快照生成成功並且儲存到歷史資料儲存中才會刪除。這保證了讀請求總透過實時和歷史儲存能獲取到完整資料。
S3上的完整快照被用於其他的離線資料分析。
流式更新輸出
除了對快照的隨機訪問和批次處理,Nebula還支援流式更新,以保證應用及時感知資料的更新。透過DynamoDB的流API來支援流式更新。一個單獨的元件使用Kinesis消費者中的流,並將其釋出到特定的Kafka流中,因此任何感興趣的服務都可以訂閱它。
其他場景:搜尋索引基礎設施
說完了Nebula,接下來講講我們如何使用Nebula重構Airbnb的搜尋索引。我們先聊一下為何要重構。
由於Airbnb大部分使用Rails / MySQL作為前端,因此搜尋索引會監聽(並且仍然)對資料庫表進行更改,維護當前搜尋索引檔案的快取,並使用新檔案更新搜尋實體(如果有任何更改)。由於使用輪詢載入器載入,以及從資料一致性的資料源定期同步,因此效能不確定。新的搜尋機器可以透過從快取中緩慢流式傳輸來引導其索引。
下麵是我們決定使用這個系統的原因:
-
端到端的低延遲操作(平均時間小於1秒)
-
能夠透過批次任務離線處理並且合併消費的特徵到索引中
-
能夠使用實時特徵
-
離線生成索引(能夠共享索引到離線分片)
-
快速回滾有問題的分片
-
快速擴充套件新的搜尋實體
-
審核搜尋索引檔案的更新
-
索引資料增長的時候可擴充套件
Nebula系統上面的這些特性很完美的解決了我們所有的需求。版本化列式儲存意味著我們能審核搜尋檔案,支援批次任務意味著我們能離線生成索引(以及合併串列特徵)並且直接部署到搜尋中。因為這些索引基於快照構建和部署,出現壞的索引資料我們能快速的回滾。新生成的索引被用於新的搜尋實體快速啟動(僅僅透過下載索引)。
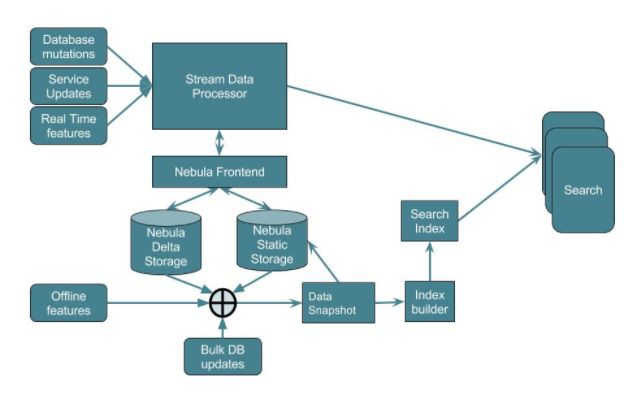
上圖展示了基於Nebula的搜尋架構。資料快照作為離線資料合併的一部分每天生成。索引構建器的作業對此快照進行操作以構建分片索引,然後像普通的二進位制部署一樣定期部署搜尋。這個系統使用了Nebula的特性,只需要實現定製邏輯關聯搜尋索引。
展望
我們在Nebula之上構建了很多服務,包括剛剛提到的搜尋索引管道,個性化基礎設施,Airbnb的價格服務資料倉庫。為每個應用提供了很多TB的資料,平均延遲在10毫秒。我們想鼓勵其他的團隊使用Nebula構建更多的應用。
我們也計劃把我們的系統跟我們的數倉深度結合,即,儲存歷史快照到Hive,共享更多資料流消費邏輯,等等。為分析功能提高資料的可用性和一致性,讓系統管理和操作更便捷,這樣對開發者來說才能更容易構建他們的應用。
鳴謝
很多人的付出才把這個系統做起來。我們想感謝Alex Guziel為這個專案所做的突出貢獻,感謝Jun He, Liyin Tang, Jingwei Lu等人的慷慨相助,還有很多人透過搜尋,應用基礎設施,資料基礎設施,產品基礎設施和其他團隊所有以各種方式幫助的人。
原文地址:
https://medium.com/airbnb-engineering/nebula-as-a-storage-platform-to-build-airbnbs-search-backends-ecc577b05f06
相關閱讀:
本文作者 Charles He, Soumyadip Banerjee, Tao Tao, Krishna Puttaswamy,鄧啟明翻譯。轉載本文請註明出處,歡迎更多小夥伴加入翻譯及投稿文章的行列,詳情請戳公眾號選單「聯絡我們」。
高可用架構
改變網際網路的構建方式

長按二維碼 關註「高可用架構」公眾號
