前言:前段時間接觸過一個流式計算的任務,使用了阿裡巴巴集團的JStorm,發現這個領域值得探索,就發現了這篇文章——Putting Apache Kafka To Use: A Practical Guide to Building a Stream Data Platform(Part 1)。在讀的過程中半總結半翻譯,形成本文,跟大家分享。
最近你可能聽說很多技術名詞,例如“流式處理”、“事件資料”以及“實時”等,與之相關的技術有Kafka、Storm、Samza或者是Spark的Steam Model。這些新興的技術令人興奮,不過還沒有多少人知道如何將這些技術新增到自己的技術棧中,如何實際應用於專案中。
這篇指南討論我們關於實時資料流的工程經驗:如何在你的公司內部搭建實時資料平臺、如何使用這些資料構建應用程式,所有這些都是基於實際經驗——我們在Linkdin花了五年時間構建Apache Kafka,將Linkdin轉換為流式資料架構,並幫助矽谷的很多技術公司完成了同樣的工作。
這份指南的第一部分是關於流式資料平臺(steam data platform)的概覽:什麼是流式資料平臺,為什麼要構建流式資料平臺;第二部分將深入細節,給出一些操作規範和最佳實踐。
何為流式資料平臺?
流式資料平臺:簡潔、輕量的事件處理我們在Linkein構建Apache Kafka的目的是讓它作為資料流的中央倉庫工作,但是為什麼要做這個工作,有下麵兩個原因:
-
資料整合:資料如何在各個系統之間流轉和傳輸;
-
流式處理:通常在資料倉庫或者Hadoop叢集中需要做豐富的資料分析,同時實現低延時。
接下來介紹下上述兩個理論的提出過程。起初我們並沒有意識到這些問題之間有聯絡,我們採取了臨時方案:只要需要,就在系統和應用程式之間建造資料通道或者給web服務傳送非同步請求。隨著時間推移,系統越來越複雜,我們在幾乎所有子系統之間都建立了不同的資料通道:
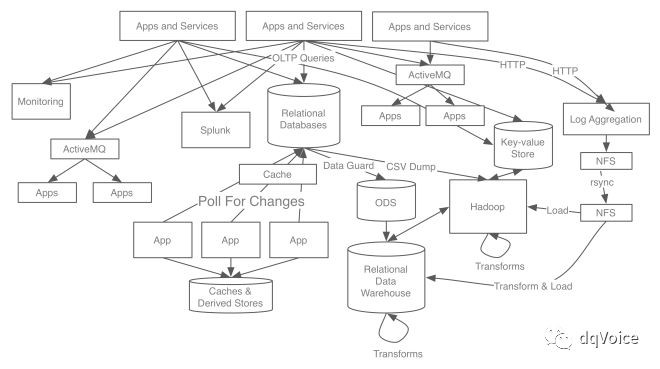
每個資料通道都有自己的問題:日誌資料的規模很大但是資料有缺失,並且資料傳輸的延遲很高;Oracle資料庫實體之間的資料傳輸速度快、準確而且實時性好,但是其他系統不能及時快速得獲得這些資料;Oracle資料庫的資料到Hadoop叢集的資料通道吞吐量很高,但是隻能進行批次操作;搜尋系統資料通道的延遲低,不過資料規模小,並且是直接連線資料庫;訊息系統資料通道的延遲低,但是不可靠且規模小。
隨著我們在全球各地新增資料中心,我們也要為這些資料流新增對應的副本;隨著系統規模的增長,對應的資料通道規模也應該相應得增長,整個系統面臨的壓力越來越大。我認為我的團隊與其說是由分散式系統工程師組成,還不如說是由一些管道工組成。
更糟的是,複雜性過高導致資料不可靠。由於資料的索引和儲存存在問題,導致我們的報告可信度降低。員工需要花費大量時間處理各種型別的臟資料,記得有在處理一起故障中,我們在兩個系統中發現一些非常類似但存在微小差異的資料,我們費了很大力氣檢查這兩個資料哪個是爭取額的,最後發現兩個都不對。
與此同時,我們除了要做資料遷移,還想對資料進行進一步的處理和分析。Hadoop平臺提供了批處理、資料打包和專案(ad hoc)處理能力,但是我們還需要一個實時性更好的資料處理平臺。我們的很多系統——特別是監控系統、搜尋索引的資料通道、資料分析應用以及安全分析應用,都需要秒級的響應速度,但是這型別的應用在上圖的系統架構中表現很差。
2010年左右,我們開始構建一個系統:專註於實時獲取流式資料(stream data),並規定各個系統之間的資料互動機制也以流式資料為承載,同時還允許對這些流式資料進行實時處理。這就是Apache Kafka的原型。
我們對整個系統的構想如下所示:

很長一段時間內我們都沒有為我們所構建的這個系統取名字,僅僅稱之為“Kafka stuff”或者“global commit log thingy”,隨著時間推移,我們開始將這個系統中的資料稱之為流式資料(steam data),而負責處理這種型別的資料的平臺稱之為流式資料平臺(steam data platform)。
最終我們的系統從前文描述的跟“義大利麵條”一樣雜亂進化為清晰的以流式資料平臺為中心的系統:
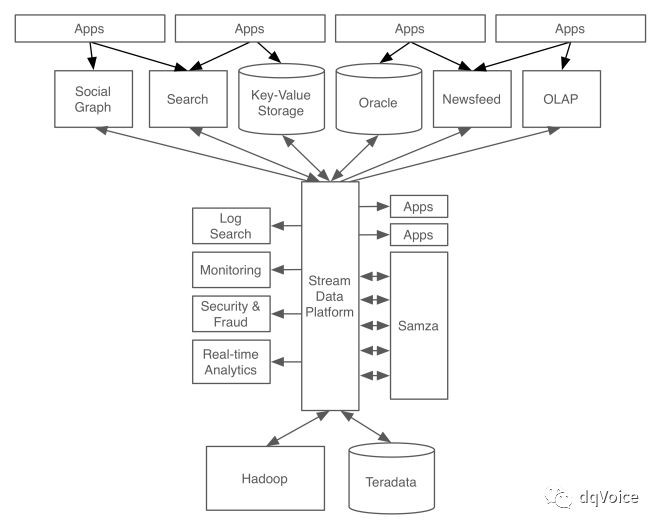
在這個系統中Kafka的角色是通用資料管道。每個子系統都可以很容易得接入到這個中央資料管道上;流式處理應用可以接入到該資料管道上,並對外提供經過處理後的流式資料。這種固定格式的資料型別成為各個子系統、應用和資料中心之間的通用語言。舉個例子說明:如果一個使用者更新了他的個人資訊,這個更新資訊會流入我們的系統處理層,在系統處理層會對該使用者的公司資訊、地理位置和其他屬性進行標準化處理;然後這個資料流會流入搜尋引擎和社群地圖用於查詢和檢索、這個資料也會流入推薦系統進行工作匹配;所有的這些動作只需要毫秒量級的時間,最後這些資料會流入Hadoop資料倉庫。
LinkedIn內部在大量使用這套系統,每天為數百個資料中心處理超過5000億事件請求,該系統已經成為其他系統的資料後臺、成為Hadoop叢集的資料管道,以及流式處理的Hub。
由於Kafka開源,因此有很多公司在做類似的事情:Kafka Powered By
接下來我們將論述流式資料平臺的一些細節:該平臺的工作原理、該平臺解決了什麼重要問題。
流式資料(Steam Data)
大部分業務邏輯可以理解為事件流(steam of events)。零售業有訂單流、交易流、物流資訊流、價格調整事件流,以及各類呼叫的傳回值等等;金融行業有訂單流、股票價格變更事件流,以及其他金融行業的資訊流;網站有點選流、關註流(impressions)、搜尋流等等。在大規模的軟體系統中還有請求流、錯誤流、機器監控資訊流和日誌流。總之,業務邏輯可以從整體上當作一種資料處理系統——接收多種輸入流並產生對應的輸出流(有時還會產生具體的物理產品)。
這種概念對於習慣於將資料想象為資料庫中的一行的同學可能有點陌生,接下來我們看一點關於事件流資料的實際例子。
事件觸發和事件流
資料庫中存放的是資料的當前狀態,當前狀態是過去的某些動作(action)的結果,這些動作就是事件。庫存表儲存購買和交易事件產生的結果,銀行結餘存放信貸和借記事件的結果;Web Server的延時圖是一系列HTTP請求的聚合。
當談論大資料時,很多人更青睞於記錄上述提到的這些事件流,併在此基礎上進行分析、最佳化和決策。某種層度上來說,這些事件流是傳統的資料庫沒有反應出來的一面:它們表示業務邏輯。
事件流資料在金融行業已經廣泛使用:股票發行、市場預測、股票交易等資料都可以當作是事件流,但是技術屆使得蒐集和使用這些資料的現代技術開始流行。Google將廣告點選流和廣告效果轉化為幾十億美金的收入。在web開發屆,這些事件資料又被稱為日誌資料,由於缺乏針對日誌處理的模組,這些日誌事件就存放在日誌檔案中。Hadoop之類的系統經常用於日誌處理,但是根據實際情況,稱之為“批次事件儲存和處理(batch event storage and processing)”更合適。
網路公司應該是最早開始記錄事件流的公司,蒐集網站上的事件資料非常容易:在某些特定節點加一些程式碼即可記錄和跟蹤每個使用者在改網站上的行為。即使是一個單頁面或者是某個流行網站上的移動視窗也能記錄很多類似的行為資料用於分析和監控。
你可能聽說過“機器產生的資料”這個概念,其實跟事件資料表示相同的含義。某種程度上所有的資料都是機器產生的,因為這些資料來自計算機系統。
還有很多人在談論裝置資料和“物聯網(internet of things)”。不同的人對這些名詞有各自的理解,但是這個物聯網的核心也在於針對某些資料集進行分析和決策,只不過我們這裡的分析物件是大規模網路系統,而物聯網的分析物件是工業裝置或者消費產品。
資料庫是事件流
事件流資料很適合描述日誌資料或諸如訂單、交易、點選和貿易這些具備明顯事件特徵的資料。和大多數開發人員相同,你可能將自己系統的大部分資料儲存在各種資料庫中:關係型資料庫(Oracle、MySQL和Postgres)或者新興的分散式資料庫(MongoDB、Cassandra和Couchbase),這些資料可能不容易理解為事件或者事件流。
但實際上,資料庫中儲存的資料也可理解為一種事件流(event steam),簡單來說,資料庫可以理解為建立資料備份或者建立備庫的過程。做資料備份的主要方法是週期性得匯出資料庫內容,然後將這些資料匯入到備庫中。如果我很少進行資料備份,或者是我的資料量不大,那麼可以進行全量備份。實際上,隨著備份頻率的提高,全量備份不再可行:如果兩天做一次全量備份,將會耗費兩倍的系統資源、如果每個小時做一次全量備份,則會耗費24倍的系統資源。在大規模資料的備份中,顯然增量備份更加有效:只增加新建立的、更新的資料和刪除對應的資料。利用增量備份,如過我們將備份頻率提高為原來的1倍,則每次備份的數量將減少幾乎一半,消耗的系統資源也差不多。
那麼為什麼我們不盡可能提高增量備份的頻率呢?我們可以做到,但是最後只會得到一系列單行資料改變的記錄——這種事件流稱之為變更記錄,很多資料庫系統都有負責這個工作的模組(Oracle資料庫系統中的XStreams和GoldenGate、MySQL有binlog replication、Postgres有Logical Log Steaming Replication)。
綜上,資料庫的變更過程也可以作為事件流的一部分。你可以透過這些事件流同步Hadoop叢集、同步備庫或者搜尋索引;你還可以將這些事件流接入到特定的應用或者流式處理應用中,從而發掘或者分析出新的結論。
流式資料平臺解決的問題?
流式資料平臺有兩個主要應用:
-
資料整合:流式資料平臺蒐集事件流或者資料變更資訊,並將這些變更輸送到其他資料系統,例如關係型資料庫、key-value儲存系統、Hadoop或者其他資料倉庫。
-
流式處理:對流式資料進行持續、實時的處理和轉化,並將結果在整個系統內開放。
在角色1中,流式資料平臺就像資料流的中央集線器。與之互動的應用程式不需要考慮資料源的細節,所有的資料流都以同一種資料格式表示;流式資料平臺還可以作為其他子系統之間的緩衝區(buffer)——資料的提供者不需要關心最終消費和處理這些資料的其他系統。這意味著資料的消費者與資料源可以完全解耦合。
如果你需要部署一個新的系統,你只需要將新系統接入到流式資料平臺,而不需要為每個特定的需求選擇(並管理)各自的資料庫和應用程式。不論資料最初來自日誌檔案、資料庫、Hadoop叢集或者流式處理系統,這些資料流都使用相同的格式。在流式資料平臺上部署新系統非常容易,新系統只需要跟流式資料平臺互動,而不需要跟各種具體的資料源互動。
Hadoop叢集的設計標的是管理公司的全量資料,直接從HDFS中獲取資料是非常耗費時間的方案,而且直接獲取的資料不能直接用於實時處理和同步。但是,這個問題可以反過來看:Hadoop等資料倉庫可以主動將結果以流式資料的格式推送給其他子系統中。
流式資料平臺的角色2包含資料聚合用例,系統蒐集各類資料形成資料流,然後存入Hadoop叢集歸檔,這個過程就是一個持續的流式資料處理。流式處理的輸出還是資料流,同樣可以載入到其他資料系統中。
流式處理可以使用透過簡單的應用程式碼實現,這些處理程式碼處理事件流並產生新的事件流,這類工作可以透過一些流行的流式處理框架完成——Storm、Samza或Spark Streaming,這些框架提供了豐富的API介面。這些框架發展得都不錯,同時它們跟Apache Kafka的互動都很好。
流式資料平臺需要提供的能力?
在上文中我提到了一些不同的用例,每個用例都有對應的事件流,但是每個事件流的需求又有所不同——有些事件流要求快速響應、有些事件流要求高吞吐量、有些事件流要求可擴充套件性等等。如果我們想讓一個平臺滿足這些不同的需求,這個平臺應該提供什麼能力?
我認為對於一個流式資料平臺,應該滿足下列關鍵需求:
-
它必須足夠可靠,以便於處理嚴苛的更新,例如將某個資料庫的更新日誌變更為搜尋索引的儲存,能夠順序傳輸資料並保證不丟失資料;
-
它必須具備足夠大的吞吐量,用於處理大規模日誌或者事件資料;
-
它必須具備緩衝或者持久化資料的能力,用於與Hadoop這類批處理系統互動。
-
它必須能夠為實時處理程式實時提供資料,即延時要足夠低;
-
它必須具備良好的擴充套件性,可以應付整個公司的滿負載執行,並能夠整合成百上千個不同團隊的應用程式,這些應用以外掛的形式與流式資料平臺整合。
-
它必須能和實時處理框架良好得互動
流式資料平臺是整個公司的核心繫統,用於管理各種型別的資料流,如果該系統不能提供良好的可靠性以及可擴充套件性,系統會隨著資料量的增長而再次遭遇瓶頸;如果該系統不支援批處理和實時處理,那麼就不能與Hadoop或者Storm這類系統整合。
Apache Kafka
Apache Kafka是專門處理流式資料的分散式系統,它具備良好的容錯性、高吞吐量、支援橫向擴充套件,並允許地理位置分佈的流式資料處理。
Kafka常常被歸類於訊息處理系統,它確實扮演了類似的角色,但同時也提供了其他的抽象介面。在Kafka中最關鍵的抽象資料結構是用於記錄更新的commit log:

資料生產者向commit log佇列中傳送記錄流,其他消費者可以像水流一樣在毫秒級延時處理這些日誌的最新資訊。每個資料消費者在commit log中有一個自己的位置(指標),並獨立移動,這使得可靠、順序更新能夠分散式得傳送給每個消費者。
這個commit log的作用非常關鍵:可以多個生產者和消費者共享,並改寫一個叢集中的多臺機器,每臺機器都可用作容錯保障;可以提供一個並行模型,其具備的順序消費的特點使得Kafka可以用於記錄資料庫的變更。
Kafka是一個現代的分散式系統,儲存在一個叢集的資料(副本和分片儲存)可以水平擴張和縮小,同時上層應用對此毫無感知。資料消費者的機器數量可以隨資料規模的增長而水平增加,同時可以自動應對資料處理過程中發生的錯誤。
Kafka的一個關鍵設計是對持久化的處理相當好,Kafka的訊息代理(broker)可以儲存TB量級的資料,這使得Kafka能夠完成一些傳統資料庫無法勝任的任務:
-
接入Kafka的Hadoop叢集或者其他離線系統可以放心得停機維護,間隔幾小時或者幾天后再平滑接入,因為在它停機期間到達的流式資料被儲存在Kafka的上行叢集。
-
在首次執行同步資料庫的任務時可以執行全量備份,以便讓下行消費者訪問全量資料。
上述這些特性使得Kafka能夠提供比傳統的訊息系統更廣的應用範圍。
事件驅動的應用
自從我們將Kafka開源後,我們有很多機會與其他想做類似的事情的公司交流和合作:研究如何Kafka系統的部署以及Kafka在該公司內部技術架構的角色如何隨著時間演進和改變。
初次部署常常用於單個的大規模應用:日誌資料處理,並接入Hadoop叢集;也可能是其他資料流,該資料流的規模太大以至於超出了該公司原有的訊息系統的處理能力。
從這些用例延伸開來,在接入Hadoop叢集後,很快就需要提供實時資料處理的能力,現存的應用需要擴充套件和重構,利用現有的實時處理框架更高效得處理流式資料。以LinkedIn為例,我們最開始是利用Kafka處理job資訊流,並將job資訊存入Hadoop叢集,然後很多ETL-centric的應用需求開始出現,這些job資訊流開始用於其他子系統,如下圖所示:

在這張圖中,job的定義不需要一些定製就可以與其他子系統互動,當上游應用(移動應用)上出現新的工作資訊時,就會透過Kafka傳送一個全域性事件,下游的資料處理應用只需要響應這個事件即可。
流式資料平臺與現存中介軟體的關係
我們簡單講下流式資料平臺與現存的類似系統的關係。
訊息系統(Messaging)
流式資料平臺類似於企業訊息系統——它接收訊息事件,並把它們釋出到對應事件的訂閱者。不過,二者有三個重要的不同:
-
訊息系統通常是作為某個應用中的一個元件來部署,不同的應用中有不同的訊息系統,而流式資料平臺希望成為整個企業的資料流Hub。
-
訊息系統與批處理系統(資料倉庫或者Hadoop叢集)的互動性很差,因為訊息系統的資料儲存容量有限;
-
訊息系統並未提供與實時處理框架整合的API介面。
換句話說,流式資料平臺可以看作在公司級別(訊息系統的級別是專案)設計的訊息系統。
資料聚合工具(Data Integration Tools)
為了便於跟其他系統整合,流式資料平臺做了很多工作。它的角色跟Informatica這類工具不同,流式資料平臺是可以讓任何系統接入,並可以圍繞該平臺構建不同的應用。
流式資料平臺與資料聚合工具有一點重合的實踐:使用一個統一的資料流抽象,保證資料格式相同,這樣可以避免很多資料清洗任務。我會在這個系列文章的第二篇仔細論述這個主題。
企業服務匯流排(Enterprise Service Buses)
我認為流式資料平臺借鑒了很多企業服務匯流排的設計思想,不過提供了更好的實現方案。企業服務匯流排面臨的挑戰就是自身的資料傳輸效率很低;企業服務匯流排在部署時也面臨一些挑戰:不適合多租戶使用(PS,此處需要看下原文,歡迎指導)。
流式資料平臺的優勢在於資料的傳輸與系統本身解耦合,資料的傳輸由各個應用自身完成,這樣就能避免平臺自身成為瓶頸。
變更記錄系統(Change Capture Systems)
常規的資料庫系統都有類似的日誌機制,例如Golden Gate,然而這個日誌記錄機制僅限於資料庫使用,並不能作為通用的事件記錄平臺。這些資料庫自帶的日誌記錄機制主要用於同型別資料庫(eg:Oracle-to-Oracle)之前的互相備份。
資料倉庫和Hadoop
流式資料平臺並不能替代資料倉庫,恰恰相反,它為資料倉庫提供資料源。它的身份是一個資料管道,將資料傳輸到資料倉庫,用於長期轉化、資料分析和批處理。這個資料管道也為資料倉庫提供對外輸出結果資料的功能。
流式處理系統(Steam Processing Systems)
常用的流式處理框架,例如Storm、Samza或Spark Streaming可以很容易得跟流式資料平臺整合。這些流式資料處理框架提供了豐富的API介面,可以簡化資料轉化和處理。
流式資料平臺的落地與實踐
我們不只是提出了一個很好的想法,我們面臨的需求很適合將自己的想法落地。過去五年我們都在構建Kafka系統,幫助其他公司落地流式資料平臺。今天,在矽谷有很多公司在實踐這套設計思路,每個使用者的行為都被實時記錄並處理。
前瞻
我們一直在思考如何使用公司掌握的資料,因此構建了Confluent平臺,該平臺上有一些工具用來幫助其他公司部署和使用Apache Kafka。如果你希望在自己的公司部署流式資料處理平臺,那麼Confluent平臺對你絕對有用。
還有一些用的資源:
-
我之前寫過的blog post和小書,討論的主題包括Kafka中的日誌抽象、資料流和資料系統架構等;
-
Kafka的官方檔案也很有用;
-
在這裡有關於Confluent平臺的更多介紹
這個教程的下篇將會論述在構建和管理資料流平臺中的一些實踐經驗。