
詞性標註(Part-of-Speech Tagging, POS)、命名物體識別(Name Entity Recognition,NER)和依存句法分析(Dependency Parsing)是自然語言處理中常用的基本任務,本文基於SpaCy python庫,透過一個具體的程式碼實踐任務,詳細解釋這三種NLP任務具體是什麼,以及在實踐中三個任務相互之間的關係。
介紹
說到資料科學時,我們經常想到的是數字的統計分析。但是,越來越多的情況下,社群會生成大量可以量化和分析的非結構化文字資料。比如,社交網路評論、產品評論、電子郵件、面試記錄。
為了分析文字,資料科學家經常使用自然語言處理( NLP )技術。在這篇部落格文章中,我們將講解3個常見的NLP任務,看看它們如何一起用於分析文字。我們將討論的三項任務是:
1、詞性標註——這是什麼型別的詞?
2、依存句法分析——這個詞和這個句子中的其他詞有什麼關係?
3、命名物體識別——這個詞是專有名詞嗎?
我們將基於spaCy python庫,將三種NLP任務綜合放在一起,分析它們是如何協同工作的。在這兒,我們將使用這些結構化的資料進行一些有趣的視覺化。
這種方法可以應用於任何問題,在這些問題擁有大量的文字資料,我們需要瞭解主要物體是誰,它們出現在檔案中的位置,以及它們在做什麼。例如,DocumentCloud在其“View Entities”分析選項中使用了與此類似的方法。
Token(符號)&詞性標註
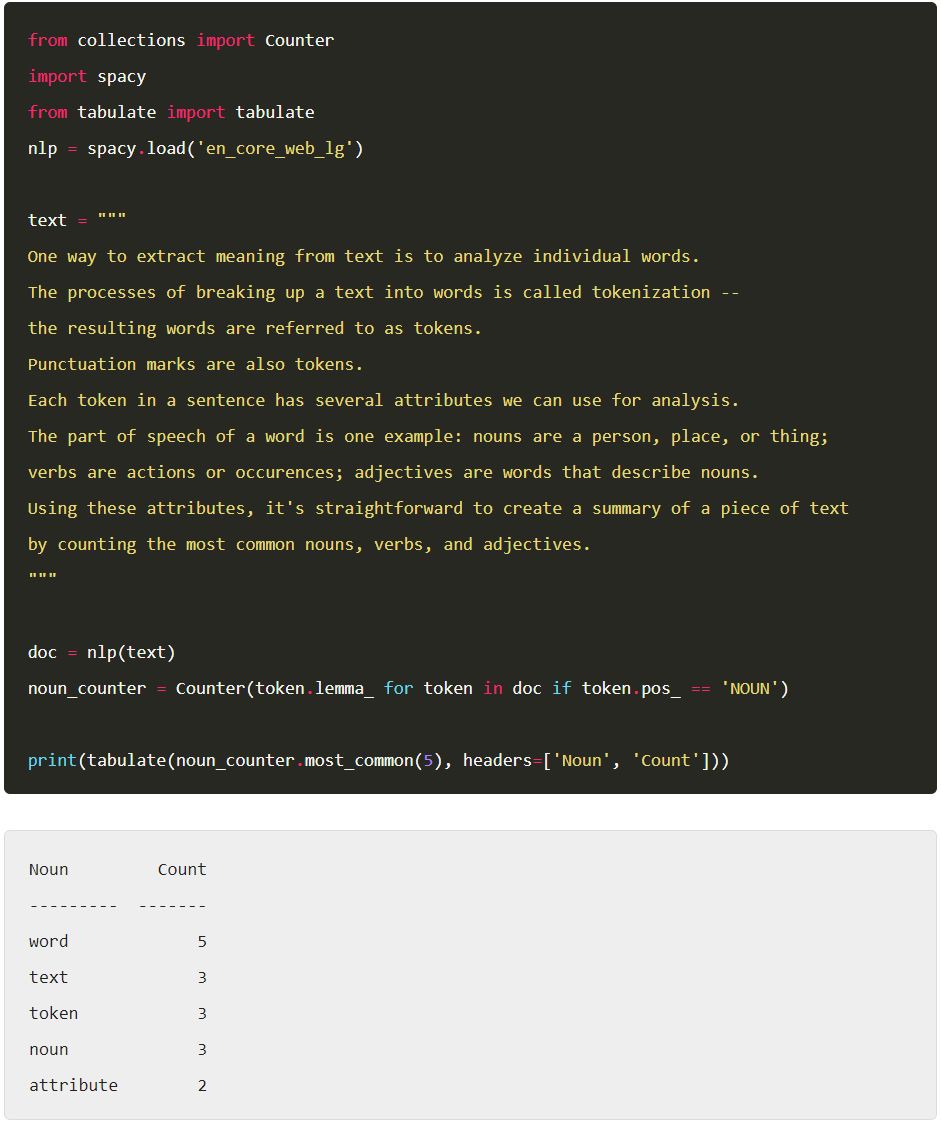
從文字中提取含義(meaning)的一種方法是分析單個單詞。將文字分解成單詞的過程稱為tokenization——產生的單詞稱為token(tokens)。標點符號也是tokens。句子中的每一個token都有幾個我們可以用來分析的屬性。比如說一個詞的詞性:人、地方或事物是名詞;動作或事件是動詞;描述名詞的詞是形容詞。使用這些屬性,透過透過簡單的計算最常見的名詞、動詞和形容詞來建立一段文字的摘要。
使用spaCy,我們可以tokenize一段文字,並訪問每個token(token)的詞性屬性。作為一個示例應用程式,一下程式碼給出了一個實體,我們先對一段話進行標簽化,然後計算其中最常見的名詞。我們還將對這些token進行歸類,定義一個詞為根節點,方便我們對其他的詞進行標準化。
依存句法分析
單詞之間也是有關係的,有幾種型別的關係。例如,名詞可以成為句子的主語,表示它執行了一個動作(一個動詞),如“吉爾笑了”。名詞也可以是句子的賓語,表示被句子的主語所作用,就像這句話中的約翰一樣:”吉爾嘲笑約翰。”
依存句法分析是理解句子中單詞之間關係的一種方法。雖然吉爾和約翰都是句子“吉爾嘲笑約翰”中的名詞,但吉爾是笑的主體,約翰是被嘲笑的物件。依存關係是一種更細粒度的屬性,可以透過句子中的關係來理解單詞的含義。
這些詞之間的關係會變得複雜,這取決於句子的結構。依存句法分析的結果是以動詞為根的樹形資料結構。
讓我們來看一下“The quick brown fox jumps over the lazy dog” 的依存關係分析。

依存關係也是token屬性,spaCy有一個很好的API,可以訪問不同的token屬性。下麵我們將打印出每個token的文字、其依存關係以及其parent(頭)token的文字。

出於分析的目的,我們關心任何具有nobj關係的token,表明它們是句子中的物件。在例句中,這意味著我們想要捕捉“狐狸”這個詞。
命名物體識別
最後是命名物體識別。命名物體是句子的專有名詞。計算機已經非常擅長於判斷在句子中是否存在物體,以及區分它們是什麼型別的物體。
spaCy可以處理document level的命名物體識別,因為一個物體的名稱可以跨越多個token。使用IOB方案將分別表示單個token物體的一部分,分別表示token物體的開始、內部和外部。
在下麵的程式碼中,我們將列印初檔案中所有命名物體。然後,我們將列印每個token、其IOB註釋、其物體型別(如果它是物體的一部分)。我們將使用的例句是“Jill laughed at John Johnson.”

實體解析:NLPing聖經
上面提到的每種方法本身都很棒,但是當我們將這些方法結合起來提取遵循語言樣式的資訊時,自然語言處理的真正力量就顯示出來了。我們可以使用詞性標註、依存句法分析和命名物體識別來理解大量文字中的所有參與者(actors)及其行為(actions)。聖經是一個很好的例子,因為它很長且具有豐富的角色。
如下圖所示,我們正在匯入的資料包含每個聖經章節一個物件。經文被用作聖經部分的參考資料,通常包含一句或多句經文。我們將仔細閱讀每一節,提取主題,確定它是否是一個人,並抽出這個人所做的動作。
首先,讓我們將聖經以JSON格式從GitHub儲存庫中載入。然後,我們將抽出每一節中的文字,透過spaCy進行依存解析和tagging,並將結果存入檔案。

我們用3分鐘左右的時間將JSON中的文字解析成verse_docs,大約每秒160節。作為參考,以下是bible_JSON的前3行:

使用token屬性
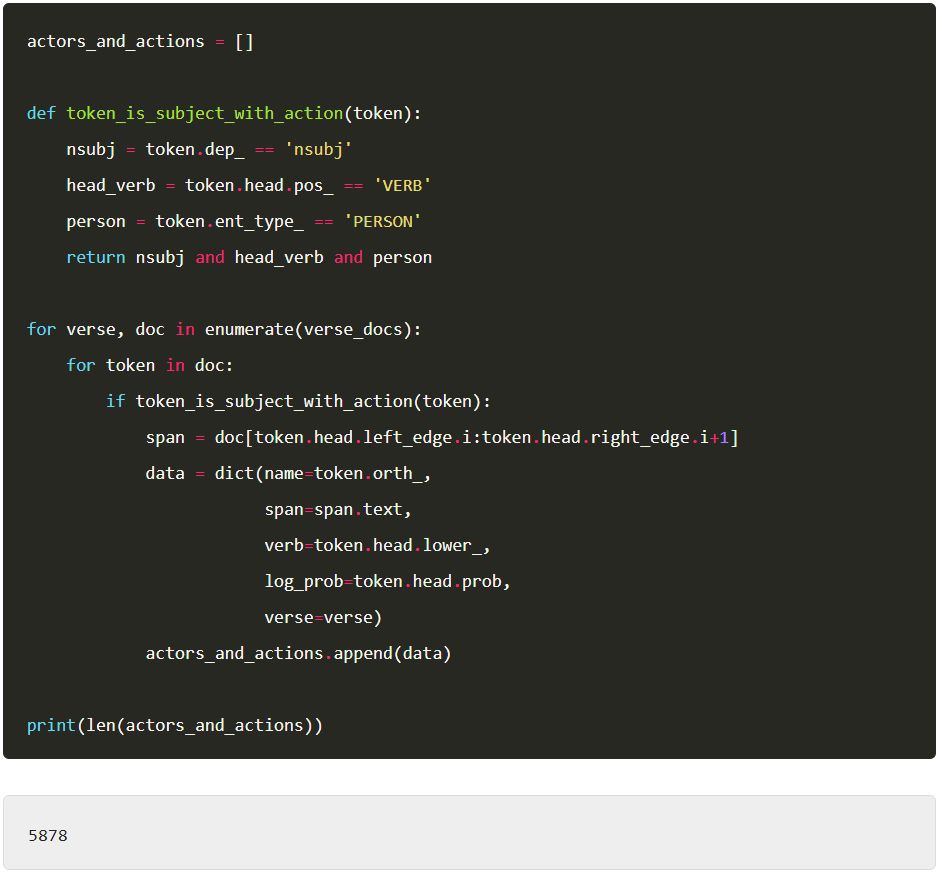
為了提取actors和actions,我們將迭代一首詩中的所有token,並考慮3個因素:
1. token是句子的主語嗎(它是依存關係nsubj嗎?) 。
2. 是一個動詞token的parent嗎?(這通常應該是真的,但是有時POS標記器和依存解析之間會有衝突,所以必須小心處理。另外,可能還存在其他一些奇怪的邊緣案例(edge cases)。
3. token是一個人名物體嗎?我們不想提取任何非人的名詞。(為了簡單起見,我們只提取名字)
如果我們的token滿足上述三個條件,我們將收集以下屬性:
1. 名詞/物體token。
2. 從名詞到動詞之間的短語(span/phrase)。
3. 動詞。
4. 標準英文文字中動詞出現的機率(在這裡使用使用這些記錄是因為這些機率通常都很小)。
5. 詩號(verse number)。
分析
我們已經抽取出了一份包含所有actor及其actions的串列。為了加快分析,需要做兩件事:
1、找出每個人最常見的action(動詞)。
2、找出每個人最獨特的action。它們往往是英語文字中出現機率最低的動詞。

讓我們看看按動詞計數和最常見動詞排列的top-15名actor。

看起來聖經裡的很多人都說過話,除了Solomon之外,他做了很多事情。
從動詞出現的機率來看,最獨特的動詞是什麼呢?(先刪除重覆詞,這樣每個詞都是獨一無二的)
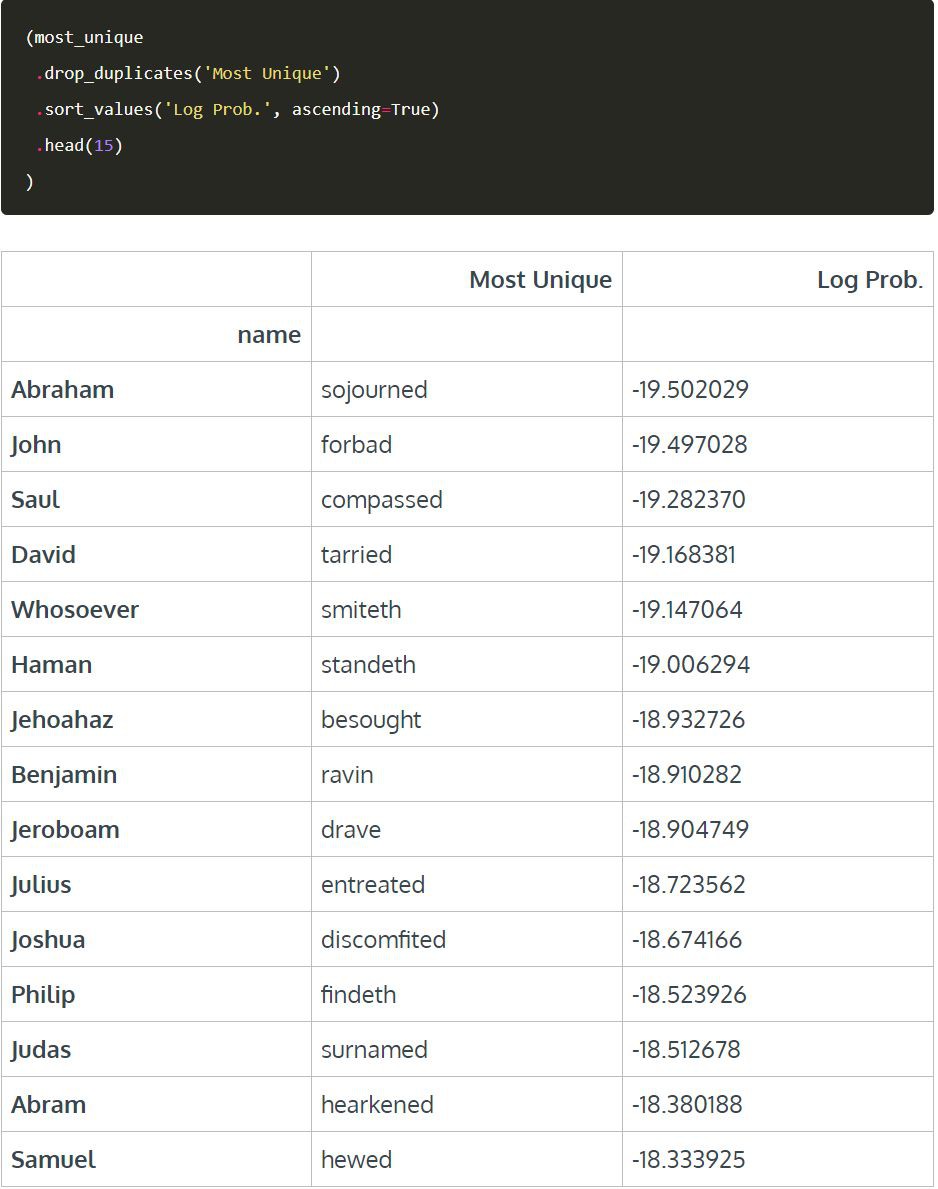
看來我們似乎有一些有趣的新單詞要學!我最喜歡的是discomfited和ravin。
視覺化
接下來讓我們視覺化我們的結果。選擇行動最多的前50個名字,併在畫出這些actions在整篇文章出現過的詩句。我們也將在聖經的每本書開始處畫垂直線做標記。名字按首次出現的順序排序。
我們可以看一下在聖經中的那些部分,這些人物最活躍。
我們將新增一些分隔符來區分聖經的不同章節。我本人不是聖經學者,所以我使用瞭如下分隔符:
舊約:
摩西五經,或法律書籍:Genesis, Exodus, Leviticus, Numbers, and Deuteronomy。
舊約歷史書:oshua, Judges, Ruth, 1 Samuel, 2 Samuel, 1 Kings, 2 Kings, 1 Chronicles, 2 Chronicles, Ezra, Nehemiah, and Esther。
智慧文學:Job, Psalms, Proverbs, Ecclesiastes, and Song of Solomon。
先知: Isaiah, Jeremiah, Lamentations, Ezekiel, Daniel, Hosea, Joel, Amos, Obadiah, Jonah, Micah, Nahum, Habakkuk, Zephaniah, Haggai, Zechariah, 和Malachi。
新約:
福音書:馬修、馬克、盧克和約翰。
新約歷史書:Acts
書信: Romans, 1 Corinthians, 2 Corinthians, Galatians, Ephesians, Philippians, Colossians, 1 Thessalonians, 2 Thessalonians, 1 Timothy, 2 Timothy, Titus, Philemon, Hebrews, James, 1 Peter, 2 Peter, 1 John, 2 John, 3 John, and Jude.。
預言/啟示文學:啟示
此外,我們將用紅色的指示線將舊約和新約分開。

出現在聖經裡面的Actions,按照它們第一次出現的位置排序。

視覺化分析
在聖經的開頭,創世紀裡,神被多次提到。
上帝不再被用作新約全書中的物體。
我們在使徒行傳中第一次看到保羅。(福音書之後的第一本書)
聖經中的智慧和詩歌部分沒有太多物體。
耶穌的一生在福音書中被詳細記載。
彼拉多出現在每一部福音書的末尾。
這種方法的問題
物體識別無法區分同名的兩個不同的人。比如:King Saul(舊約),Paul(使徒)被稱為Saul,直到Acts書的中間部分。
有些名詞不是實際的物體。
一些名詞可以用更多的背景關係和全名。(彼拉多)
下一步
一如既往,有一些方法可以擴充套件和改進這一分析。寫這篇文章時,我想到了幾個:
1 .使用依存關係查詢物體之間的關係,並透過網路分析方法理解字元。
2. 改進物體提取方法以捕獲單個名稱以外的物體。
3. 對非個人物體及其語言關係進行分析——聖經中提到了哪些位置?
總結:
我們只需要使用文字中的token級屬性就可以做一些有趣的分析。在這篇部落格文章中,我們介紹了三個關鍵的NLP工具:
詞性標註——這是什麼型別的詞?
依存句法分析——這個詞和這個句子中的其他詞有什麼關係?
命名物體識別——這個詞是專有名詞嗎?
我們一起運用這三種工具來發現聖經中的主要角色是誰,以及他們採取了什麼行動。對這些actor和及他麼的動作進行了視覺化,以瞭解每個actor的主要action在哪裡。
往期精彩內容推薦
合成註意力推理神經網路-Christopher Manning-ICLR2018
2018/2019/校招/春招/秋招/自然語言處理/深度學習/機器學習知識要點及面試筆記
五一重磅-李飛飛團隊主講-CS231-2018(春)基於CNN的視覺識別課程分享
精品推薦-2018年Google官方Tensorflow峰會影片教程完整版分享



DeepLearning_NLP


深度學習與NLP
商務合作請聯絡微訊號:lqfarmerlq
覺得還不錯,記得點選下方小廣告哦!!