

一、概述
分散式檔案系統是分散式領域的一個基礎應用,其中最著名的毫無疑問是 HDFS/GFS。如今該領域已經趨向於成熟,但瞭解它的設計要點和思想,對我們將來面臨類似場景 / 問題時,具有借鑒意義。並且,分散式檔案系統並非只有 HDFS/GFS 這一種形態,在它之外,還有其他形態各異、各有千秋的產品形態,對它們的瞭解,也對擴充套件我們的視野有所俾益。本文試圖分析和思考,在分散式檔案系統領域,我們要解決哪些問題、有些什麼樣的方案、以及各自的選擇依據。
二、過去的樣子
在幾十年以前,分散式檔案系統就已經出現了,以 Sun 在 1984 年開發的“Network File System (NFS)”為代表,那時候解決的主要問題,是網路形態的磁碟,把磁碟從主機中獨立出來。這樣不僅可以獲得更大的容量,而且還可以隨時切換主機,還可以實現資料共享、備份、容災等,因為資料是電腦中最重要的資產。NFS 的資料通訊圖如下。

部署在主機上的客戶端,透過 TCP/IP 協議把檔案命令轉發到遠端檔案 Server 上執行,整個過程對主機使用者透明。
到了網際網路時代,流量和資料快速增長,分散式檔案系統所要解決的主要場景變了,開始需要非常大的磁碟空間,這在磁碟體繫上垂直擴容是無法達到的,必須要分散式,同時分散式架構下,主機都是可靠性不是非常好的普通伺服器,因此容錯、高可用、持久化、伸縮性等指標,就成為必須要考量的特性。
三、對分散式檔案系統的要求
對一個分散式檔案系統而言,有一些特性是必須要滿足的,否則就無法有競爭力。主要如下:
-
應該符合 POSIX 的檔案介面標準,使該系統易於使用,同時對於使用者的遺留系統也無需改造;
-
對使用者透明,能夠像使用本地檔案系統那樣直接使用;
-
持久化,保證資料不會丟失;
-
具有伸縮性,當資料壓力逐漸增長時能順利擴容;
-
具有可靠的安全機制,保證資料安全;
-
資料一致性,只要檔案內容不發生變化,什麼時候去讀,得到的內容應該都是一樣的。
除此之外,還有些特性是分散式加分項,具體如下:
-
支援的空間越大越好;
-
支援的併發訪問請求越多越好;
-
效能越快越好;
-
硬體資源的利用率越高越合理,就越好。
四、架構模型
從業務模型和邏輯架構上,分散式檔案系統需要這幾類元件:
-
儲存元件:負責儲存檔案資料,它要保證檔案的持久化、副本間資料一致、資料塊的分配 / 合併等等;
-
管理元件:負責 meta 資訊,即檔案資料的元資訊,包括檔案存放在哪臺伺服器上、檔案大小、許可權等,除此之外,還要負責對儲存元件的管理,包括儲存元件所在的伺服器是否正常存活、是否需要資料遷移等;
-
介面元件:提供介面服務給應用使用,形態包括 SDK(Java/C/C++ 等)、CLI 命令列終端、以及支援 FUSE 掛載機制。
而在部署架構上,有著“中心化”和“無中心化”兩種路線分歧,即是否把“管理元件”作為分散式檔案系統的中心管理節點。兩種路線都有很優秀的產品,下麵分別介紹它們的區別。
有中心節點
以 GFS 為代表,中心節點負責檔案定位、維護檔案 meta 資訊、故障檢測、資料遷移等管理控制的職能,下圖是 GFS 的架構圖。

該圖中 GFS master 即為 GFS 的中心節點,GF chunkserver 為 GFS 的儲存節點。其操作路徑如下:
-
Client 向中心節點請求“查詢某個檔案的某部分資料”;
-
中心節點傳回檔案所在的位置 (哪臺 chunkserver 上的哪個檔案) 以及位元組區間資訊;
-
Client 根據中心節點傳回的資訊,向對應的 chunk server 直接傳送資料讀取的請求;
-
chunk server 傳回資料。
在這種方案裡,一般中心節點並不參與真正的資料讀寫,而是將檔案 meta 資訊傳回給 Client 之後,即由 Client 與資料節點直接通訊。其主要目的是降低中心節點的負載,防止其成為瓶頸。這種有中心節點的方案,在各種儲存類系統中得到了廣泛應用,因為中心節點易控制、功能強大。
無中心節點
以 ceph 為代表,每個節點都是自治的、自管理的,整個 ceph 叢集只包含一類節點,如下圖 (最下層紅色的 RADOS 就是 ceph 定義的“同時包含 meta 資料和檔案資料”的節點)。

無中心化的最大優點是解決了中心節點自身的瓶頸,這也就是 ceph 號稱可以無限向上擴容的原因。但由 Client 直接和 Server 通訊,那麼 Client 必須要知道,當對某個檔案進行操作時,它該訪問叢集中的哪個節點。ceph 提供了一個很強大的原創演演算法來解決這個問題——CRUSH 演演算法。
五、持久化
對於檔案系統來說,持久化是根本,只要 Client 收到了 Server 儲存成功的回應之後,資料就不應該丟失。這主要是透過多副本的方式來解決,但在分散式環境下,多副本有這幾個問題要面對。
-
如何保證每個副本的資料是一致的?
-
如何分散副本,以使災難發生時,不至於所有副本都被損壞?
-
怎麼檢測被損壞或資料過期的副本,以及如何處理?
-
該傳回哪個副本給 Client?
如何保證每個副本的資料是一致的
同步寫入是保證副本資料一致的最直接的辦法。當 Client 寫入一個檔案的時候,Server 會等待所有副本都被成功寫入,再傳回給 Client。
這種方式簡單、有保障,唯一的缺陷就是效能會受到影響。假設有 3 個副本,如果每個副本需要 N 秒,則可能會阻塞 Client 3N 秒的時間,有幾種方式,可以對其進行最佳化:
-
並行寫:由一個副本作為主副本,並行傳送資料給其他副本;
-
鏈式寫:幾個副本組成一個鏈 (chain),並不是等內容都接受到了再往後傳播,而是像流一樣,邊接收上游傳遞過來的資料,一邊傳遞給下游。
還有一種方式是採用 CAP 中所說的 W+R>N 的方式,比如 3 副本 (N=3) 的情況,W=2,R=2,即成功寫入 2 個就認為成功,讀的時候也要從 2 個副本中讀。這種方式透過犧牲一定的讀成本,來降低寫成本,同時增加寫入的可用性。這種方式在分散式檔案系統中用地比較少。
如何分散副本,以使災難發生時,不至於所有副本都被損壞
這主要避免的是某機房或某城市發生自然環境故障的情況,所以有一個副本應該分配地比較遠。它的副作用是會帶來這個副本的寫入效能可能會有一定的下降,因為它離 Client 最遠。所以如果在物理條件上無法保證夠用的網路頻寬的話,則讀寫副本的策略上需要做一定考慮。可以參考同步寫入只寫 2 副本、較遠副本非同步寫入的方式,同時為了保證一致性,讀取的時候又要註意一些,避免讀取到非同步寫入副本的過時資料。
怎麼檢測被損壞或資料過期的副本,以及如何處理
如果有中心節點,則資料節點定期和中心節點進行通訊,彙報自己的資料塊的相關資訊,中心節點將其與自己維護的資訊進行對比。如果某個資料塊的 checksum 不對,則表明該資料塊被損壞了;如果某個資料塊的 version 不對,則表明該資料塊過期了。
如果沒有中心節點,以 ceph 為例,它在自己的節點叢集中維護了一個比較小的 monitor 叢集,資料節點向這個 monitor 叢集彙報自己的情況,由其來判定是否被損壞或過期。
當發現被損壞或過期副本,將它從 meta 資訊中移除,再重新建立一份新的副本就好了,移除的副本在隨後的回收機制中會被收回。
該傳回哪個副本給 Client
這裡的策略就比較多了,比如 round-robin、速度最快的節點、成功率最高的節點、CPU 資源最空閑的節點、甚至就固定選第一個作為主節點,也可以選擇離自己最近的一個,這樣對整體的操作完成時間會有一定節約。
六、伸縮性
儲存節點的伸縮
當在叢集中加入一臺新的儲存節點,則它主動向中心節點註冊,提供自己的資訊,當後續有建立檔案或者給已有檔案增加資料塊的時候,中心節點就可以分配到這臺新節點了,比較簡單。但有一些問題需要考慮。
-
如何儘量使各儲存節點的負載相對均衡?
-
怎樣保證新加入的節點,不會因短期負載壓力過大而崩塌?
-
如果需要資料遷移,那如何使其對業務層透明?
如何儘量使各儲存節點的負載相對均衡
首先要有評價儲存節點負載的指標。有多種方式,可以從磁碟空間使用率考慮,也可以從磁碟使用率 +CPU 使用情況 + 網路流量情況等做綜合判斷。一般來說,磁碟使用率是核心指標。
其次在分配新空間的時候,優先選擇資源使用率小的儲存節點;而對已存在的儲存節點,如果負載已經過載、或者資源使用情況不均衡,則需要做資料遷移。
怎樣保證新加入的節點,不會因短期負載壓力過大而崩塌
當系統發現當前新加入了一臺儲存節點,顯然它的資源使用率是最低的,那麼所有的寫流量都路由到這臺儲存節點來,那就可能造成這臺新節點短期負載過大。因此,在資源分配的時候,需要有預熱時間,在一個時間段內,緩慢地將寫壓力路由過來,直到達成新的均衡。
如果需要資料遷移,那如何使其對業務層透明?
在有中心節點的情況下,這個工作比較好做,中心節點就包辦了——判斷哪臺儲存節點壓力較大,判斷把哪些檔案遷移到何處,更新自己的 meta 資訊,遷移過程中的寫入怎麼辦,發生重新命名怎麼辦。無需上層應用來處理。
如果沒有中心節點,那代價比較大,在系統的整體設計上,也是要考慮到這種情況,比如 ceph,它要採取邏輯位置和物理位置兩層結構,對 Client 暴露的是邏輯層 (pool 和 place group),這個在遷移過程中是不變的,而下層物理層資料塊的移動,只是邏輯層所取用的物理塊的地址發生了變化,在 Client 看來,邏輯塊的位置並不會發生改變。
中心節點的伸縮
如果有中心節點,還要考慮它的伸縮性。由於中心節點作為控制中心,是主從樣式,那麼在伸縮性上就受到比較大的限制,是有上限的,不能超過單臺物理機的規模。我們可以考慮各種手段,儘量地抬高這個上限。有幾種方式可以考慮:
以大資料塊的形式來儲存檔案——比如 HDFS 的資料塊的大小是 64M,ceph 的的資料塊的大小是 4M,都遠遠超過單機檔案系統的 4k。它的意義在於大幅減少 meta data 的數量,使中心節點的單機記憶體就能夠支援足夠多的磁碟空間 meta 資訊。
中心節點採取多級的方式——頂級中心節點只儲存目錄的 meta data,其指定某目錄的檔案去哪臺次級總控節點去找,然後再透過該次級總控節點找到檔案真正的儲存節點;
中心節點共享儲存裝置——部署多臺中心節點,但它們共享同一個儲存外設 / 資料庫,meta 資訊都放在這裡,中心節點自身是無狀態的。這種樣式下,中心節點的請求處理能力大為增強,但效能會受一定影響。iRODS 就是採用這種方式。
七、高可用性
中心節點的高可用
中心節點的高可用,不僅要保證自身應用的高可用,還得保證 meta data 的資料高可用。
meta data 的高可用主要是資料持久化,並且需要備份機制保證不丟。一般方法是增加一個從節點,主節點的資料實時同步到從節點上。也有採用共享磁碟,透過 raid1 的硬體資源來保障高可用。顯然增加從節點的主備方式更易於部署。
meta data 的資料持久化策略有以下幾種方式。
-
直接儲存到儲存引擎上,一般是資料庫。直接以檔案形式儲存到磁碟上,也不是不可以,但因為 meta 資訊是結構化資料,這樣相當於自己研發出一套小型資料庫來,複雜化了。
-
儲存日誌資料到磁碟檔案 (類似 MySQL 的 binlog 或 Redis 的 aof),系統啟動時在記憶體中重建成結果資料,提供服務。修改時先修改磁碟日誌檔案,然後更新記憶體資料。這種方式簡單易用。
當前記憶體服務 + 日誌檔案持久化是主流方式。一是純記憶體操作,效率很高,日誌檔案的寫也是順序寫;二是不依賴外部元件,獨立部署。
為瞭解決日誌檔案會隨著時間增長越來越大的問題,以讓系統能以儘快啟動和恢復,需要輔助以記憶體快照的方式——定期將記憶體 dump 儲存,只保留在 dump 時刻之後的日誌檔案。這樣當恢復時,從最新一次的記憶體 dump 檔案開始,找其對應的 checkpoint 之後的日誌檔案開始重播。
儲存節點的高可用
在前面“持久化”章節,在保證資料副本不丟失的情況下,也就保證了其的高可用性。
八、效能最佳化和快取一致性
這些年隨著基礎設施的發展,區域網內千兆甚至萬兆的頻寬已經比較普遍,以萬兆計算,每秒傳輸大約 1250M 位元組的資料,而 SATA 磁碟的讀寫速度這些年基本達到瓶頸,在 300-500M/s 附近,也就是純讀寫的話,網路已經超過了磁碟的能力,不再是瓶頸了,像 NAS 網路磁碟這些年也開始普及起來。
但這並不代表,沒有必要對讀寫進行最佳化,畢竟網路讀寫的速度還是遠慢於記憶體的讀寫。常見的最佳化方法主要有:
-
記憶體中快取檔案內容;
-
預載入資料塊,以避免客戶端等待;
-
合併讀寫請求,也就是將單次請求做些積累,以批次方式傳送給 Server 端。
快取的使用在提高讀寫效能的同時,也會帶來資料不一致的問題:
-
會出現更新丟失的現象。當多個 Client 在一個時間段內,先後寫入同一個檔案時,先寫入的 Client 可能會丟失其寫入內容,因為可能會被後寫入的 Client 的內容改寫掉;
-
資料可見性問題。Client 讀取的是自己的快取,在其過期之前,如果別的 Client 更新了檔案內容,它是看不到的;也就是說,在同一時間,不同 Client 讀取同一個檔案,內容可能不一致。
這類問題有幾種方法:
-
檔案只讀不改:一旦檔案被 create 了,就只能讀不能修改。這樣 Client 端的快取,就不存在不一致的問題;
-
透過鎖:用鎖的話還要考慮不同的粒度。寫的時候是否允許其他 Client 讀? 讀的時候是否允許其他 Client 寫? 這是在效能和一致性之間的權衡,作為檔案系統來說,由於對業務並沒有約束性,所以要做出合理的權衡,比較困難,因此最好是提供不同粒度的鎖,由業務端來選擇。但這樣的副作用是,業務端的使用成本抬高了。
九、安全性
由於分散式檔案儲存系統,肯定是一個多客戶端使用、多租戶的一個產品,而它又儲存了可能是很重要的資訊,所以安全性是它的重要部分。
主流檔案系統的許可權模型有以下這麼幾種。
DAC: 全稱是 Discretionary Access Control,就是我們熟悉的 Unix 類許可權框架,以 user-group-privilege 為三級體系,其中 user 就是 owner,group 包括 owner 所在 group 和非 owner 所在的 group、privilege 有 read、write 和 execute。這套體系主要是以 owner 為出發點,owner 允許誰對哪些檔案具有什麼樣的許可權。
MAC: 全稱是 Mandatory Access Control,它是從資源的機密程度來劃分。比如分為“普通”、“機密”、“絕密”這三層,每個使用者可能對應不同的機密閱讀許可權。這種許可權體系起源於安全機構或軍隊的系統中,會比較常見。它的許可權是由管理員來控制和設定的。Linux 中的 SELinux 就是 MAC 的一種實現,為了彌補 DAC 的缺陷和安全風險而提供出來。關於 SELinux 所解決的問題可以參考 What is SELinux?
RBAC: 全稱是 Role Based Access Control,是基於角色 (role) 建立的許可權體系。角色擁有什麼樣的資源許可權,使用者歸到哪個角色,這對應企業 / 公司的組織機構非常合適。RBAC 也可以具體化,就演變成 DAC 或 MAC 的許可權模型。
市面上的分散式檔案系統有不同的選擇,像 ceph 就提供了類似 DAC 但又略有區別的許可權體系,Hadoop 自身就是依賴於作業系統的許可權框架,同時其生態圈內有 Apache Sentry 提供了基於 RBAC 的許可權體系來做補充。
十、其他
空間分配
有連續空間和連結串列空間兩種。連續空間的優勢是讀寫快,按順序即可,劣勢是造成磁碟碎片,更麻煩的是,隨著連續的大塊磁碟空間被分配滿而必須尋找空洞時,連續分配需要提前知道待寫入檔案的大小,以便找到合適大小的空間,而待寫入檔案的大小,往往又是無法提前知道的 (比如可編輯的 word 檔案,它的內容可以隨時增大);
而連結串列空間的優勢是磁碟碎片很少,劣勢是讀寫很慢,尤其是隨機讀,要從連結串列首個檔案塊一個一個地往下找。
為瞭解決這個問題,出現了索引表——把檔案和資料塊的對應關係也儲存一份,存在索引節點中 (一般稱為 i 節點),作業系統會將 i 節點載入到記憶體,從而程式隨機尋找資料塊時,在記憶體中就可以完成了。透過這種方式來解決磁碟連結串列的劣勢,如果索引節點的內容太大,導致記憶體無法載入,還有可能形成多級索引結構。
檔案刪除
實時刪除還是延時刪除? 實時刪除的優勢是可以快速釋放磁碟空間;延時刪除只是在刪除動作執行的時候,置個標識位,後續在某個時間點再來批次刪除,它的優勢是檔案仍然可以階段性地保留,最大程度地避免了誤刪除,缺點是磁碟空間仍然被佔著。在分散式檔案系統中,磁碟空間都是比較充裕的資源,因此幾乎都採用邏輯刪除,以對資料可以進行恢復,同時在一段時間之後 (可能是 2 天或 3 天,這引數一般都可配置),再對被刪除的資源進行回收。
怎麼回收被刪除或無用的資料? 可以從檔案的 meta 資訊出發——如果 meta 資訊的“檔案 – 資料塊”對映表中包含了某個資料塊,則它就是有用的;如果不包含,則表明該資料塊已經是無效的了。所以,刪除檔案,其實是刪除 meta 中的“檔案 – 資料塊”對映資訊 (如果要保留一段時間,則是把這對映資訊移到另外一個地方去)。
面向小檔案的分散式檔案系統
有很多這樣的場景,比如電商——那麼多的商品圖片、個人頭像,比如社交網站——那麼多的照片,它們具有的特性,可以簡單歸納下:
-
每個檔案都不大;
-
數量特別巨大;
-
讀多寫少;
-
不會修改。
針對這種業務場景,主流的實現方式是仍然是以大資料塊的形式儲存,小檔案以邏輯儲存的方式存在,即檔案 meta 資訊記錄其是在哪個大資料塊上,以及在該資料塊上的 offset 和 length 是多少,形成一個邏輯上的獨立檔案。這樣既復用了大資料塊系統的優勢和技術積累,又減少了 meta 資訊。
檔案指紋和去重
檔案指紋就是根據檔案內容,經過演演算法,計算出檔案的唯一標識。如果兩個檔案的指紋相同,則檔案內容相同。在使用網路雲盤的時候,發現有時候上傳檔案非常地快,就是檔案指紋發揮作用。雲盤服務商透過判斷該檔案的指紋,發現之前已經有人上傳過了,則不需要真的上傳該檔案,只要增加一個取用即可。在檔案系統中,透過檔案指紋可以用來去重、也可以用來判斷檔案內容是否損壞、或者對比檔案副本內容是否一致,是一個基礎元件。
檔案指紋的演演算法也比較多,有熟悉的 md5、sha256、也有 google 專門針對文字領域的 simhash 和 minhash 等。
十一、總結
分散式檔案系統內容龐雜,要考慮的問題遠不止上面所說的這些,其具體實現也更為複雜。本文只是儘量從分散式檔案系統所要考慮的問題出發,給予一個簡要的分析和設計,如果將來遇到類似的場景需要解決,可以想到“有這種解決方案”,然後再來深入研究。
同時,市面上也是存在多種分散式檔案系統的形態,下麵就是有研究小組曾經對常見的幾種分散式檔案系統的設計比較。
幾種分散式檔案系統的比較
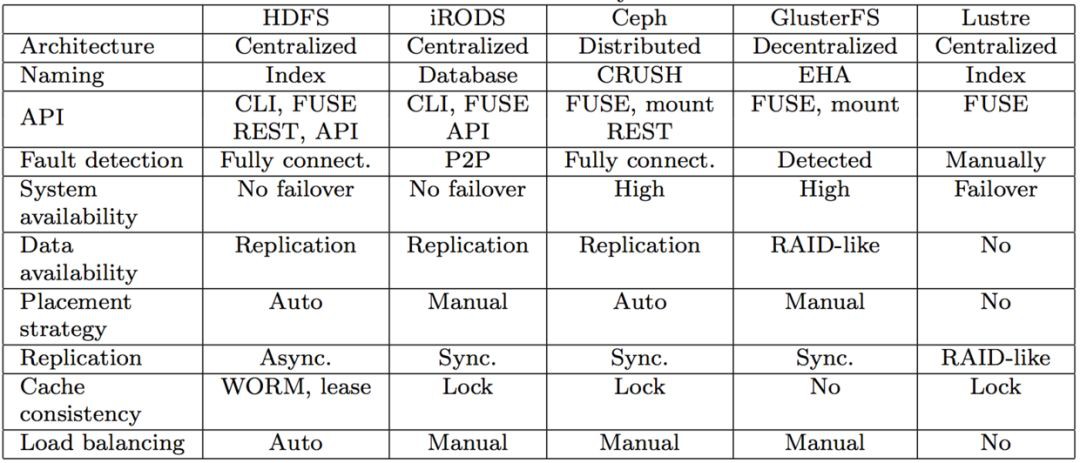
從這裡也可以看到,選擇其實很多,並不是 GFS 論文中的方式就是最好的。在不同的業務場景中,也可以有更多的選擇策略。
作者介紹
張軻,目前任職於杭州大樹網路技術有限公司,擔任首席架構師,負責系統整體業務架構以及基礎架構,轉載請聯絡作者。
文章推薦:
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取電子書詳情。

求知若渴, 虛心若愚

