(點選上方公眾號,可快速關註)
編譯:資料派THU – 季洋,倪驍然,英文:Kislay Keshari
資料框是現代行業的流行詞。人們往往會在一些流行的資料分析語言中用到它,如Python、Scala、以及R。 那麼,為什麼每個人都經常用到它呢?讓我們透過PySpark資料框教程來看看原因。在本文中,我將討論以下話題:
-
什麼是資料框?
-
為什麼我們需要資料框?
-
資料框的特點
-
PySpark資料框的資料源
-
建立資料框
-
PySpark資料框實體:國際足聯世界盃、超級英雄
什麼是資料框?
資料框廣義上是一種資料結構,本質上是一種表格。它是多行結構,每一行又包含了多個觀察項。同一行可以包含多種型別的資料格式(異質性),而同一列只能是同種型別的資料(同質性)。資料框通常除了資料本身還包含定義資料的元資料;比如,列和行的名字。

我們可以說資料框不是別的,就只是一種類似於SQL表或電子錶格的二維資料結構。接下來讓我們繼續理解到底為什麼需要PySpark資料框。
為什麼我們需要資料框?
1. 處理結構化和半結構化資料

資料框被設計出來就是用來處理大批次的結構化或半結構化的資料。各觀察項在Spark資料框中被安排在各命名列下,這樣的設計幫助Apache Spark瞭解資料框的結構,同時也幫助Spark最佳化資料框的查詢演演算法。它還可以處理PB量級的資料。
2. 大卸八塊

資料框的應用程式設計介面(API)支援對資料“大卸八塊”的方法,包括透過名字或位置“查詢”行、列和單元格,過濾行,等等。統計資料通常都是很凌亂複雜同時又有很多缺失或錯誤的值和超出常規範圍的資料。因此資料框的一個極其重要的特點就是直觀地管理缺失資料。
3. 資料源

資料框支援各種各樣地資料格式和資料源,這一點我們將在PySpark資料框教程的後繼內容中做深入的研究。它們可以從不同類的資料源中匯入資料。
4. 多語言支援

它為不同的程式語言提供了API支援,如Python、R、Scala、Java,如此一來,它將很容易地被不同程式設計背景的人們使用。
資料框的特點

-
資料框實際上是分散式的,這使得它成為一種具有容錯能力和高可用性的資料結構。
-
惰性求值是一種計算策略,只有在使用值的時候才對運算式進行計算,避免了重覆計算。Spark的惰性求值意味著其執行只能被某種行為被觸發。在Spark中,惰性求值在資料轉換髮生時。
-
資料框實際上是不可變的。由於不可變,意味著它作為物件一旦被建立其狀態就不能被改變。但是我們可以應用某些轉換方法來轉換它的值,如對RDD(Resilient Distributed Dataset)的轉換。
資料框的資料源
在PySpark中有多種方法可以建立資料框:

可以從任一CSV、JSON、XML,或Parquet檔案中載入資料。還可以透過已有的RDD或任何其它資料庫建立資料,如Hive或Cassandra。它還可以從HDFS或本地檔案系統中載入資料。
建立資料框
讓我們繼續這個PySpark資料框教程去瞭解怎樣建立資料框。
我們將建立 Employee 和 Department 實體:
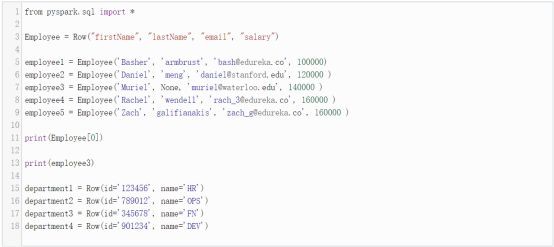
接下來,讓我們透過Employee和Departments建立一個DepartmentWithEmployees實體。

讓我們用這些行來建立資料框物件:

PySpark資料框實體1:國際足聯世界盃資料集
這裡我們採用了國際足聯世界盃參賽者的資料集。我們將會以CSV檔案格式載入這個資料源到一個資料框物件中,然後我們將學習可以使用在這個資料框上的不同的資料轉換方法。

1. 從CSV檔案中讀取資料
讓我們從一個CSV檔案中載入資料。這裡我們會用到spark.read.csv方法來將資料載入到一個DataFrame物件(fifa_df)中。程式碼如下:
spark.read.format[csv/json]

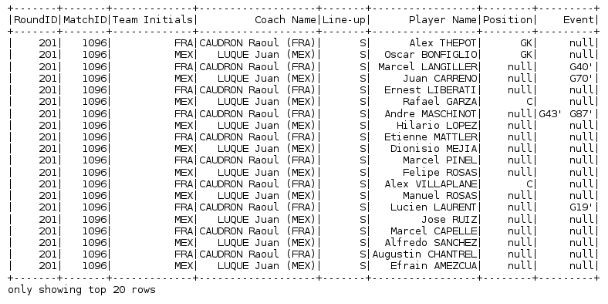
2. 資料框結構
來看一下結構,亦即這個資料框物件的資料結構,我們將用到printSchema方法。這個方法將傳回給我們這個資料框物件中的不同的列資訊,包括每列的資料型別和其可為空值的限制條件。


3. 列名和個數(行和列)
當我們想看一下這個資料框物件的各列名、行數或列數時,我們用以下方法:



4. 描述指定列
如果我們要看一下資料框中某指定列的概要資訊,我們會用describe方法。這個方法會提供我們指定列的統計概要資訊,如果沒有指定列名,它會提供這個資料框物件的統計資訊。

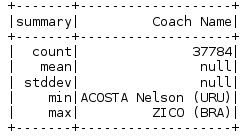
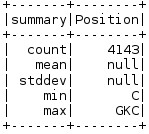
5. 查詢多列
如果我們要從資料框中查詢多個指定列,我們可以用select方法。


6. 查詢不重覆的多列組合


7. 過濾資料
為了過濾資料,根據指定的條件,我們使用filter命令。 這裡我們的條件是Match ID等於1096,同時我們還要計算有多少記錄或行被篩選出來。


8. 過濾資料(多引數)
我們可以基於多個條件(AND或OR語法)篩選我們的資料:


9. 資料排序 (OrderBy)
我們使用OrderBy方法排序資料。Spark預設升序排列,但是我們也可以改變它成降序排列。

PySpark資料框實體2:超級英雄資料集

1. 載入資料
這裡我們將用與上一個例子同樣的方法載入資料:


2. 篩選資料

3. 分組資料
GroupBy 被用於基於指定列的資料框的分組。這裡,我們將要基於Race列對資料框進行分組,然後計算各分組的行數(使用count方法),如此我們可以找出某個特定種族的記錄數。


4. 執行SQL查詢
我們還可以直接將SQL查詢陳述句傳遞給資料框,為此我們需要透過使用registerTempTable方法從資料框上建立一張表,然後再使用sqlContext.sql()來傳遞SQL查詢陳述句。







到這裡,我們的PySpark資料框教程就結束了。
我希望在這個PySpark資料框教程中,你們對PySpark資料框是什麼已經有了大概的瞭解,並知道了為什麼它會在行業中被使用以及它的特點。恭喜,你不再是資料框的新手啦!
原文標題:PySpark DataFrame Tutorial: Introduction to DataFrames
原文連結:https://dzone.com/articles/pyspark-dataframe-tutorial-introduction-to-datafra
【關於投稿】
如果大家有原創好文投稿,請直接給公號傳送留言。
① 留言格式:
【投稿】+《 文章標題》+ 文章連結
② 示例:
【投稿】《不要自稱是程式員,我十多年的 IT 職場總結》:http://blog.jobbole.com/94148/
③ 最後請附上您的個人簡介哈~
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能
