
Python 現在越來越火,連小學生都在學習 Python了 ^ ^,為了跟上時代,趕個時髦,秉承活到老學到老的精神,慢慢也開始學習 Python;理論是實踐的基礎,把 Python 相關語法看了,就迫不及待,大筆一揮來個 Hello world 壓壓驚,理論終歸是理論,實踐還是要要的嘛,動手了之後,才能更好的掌(chui)握(niu)基(bi)礎;發車了……….
'''
作者:tsmyk0715
源自:https://my.oschina.net/mengyuankan/blog/1934171
人生苦短,我用Python
'''
首先瀏覽器輸入 https://www.oschina.net/ 進入開源中國官網,點選頂部導航欄的 “部落格” 選項進入部落格串列頁面,之後點選左側 “服務端開發與管理” 選項,我們要爬取的是服務端相關的文章,如下圖所示:

接下來分析文章串列的佈局方式,按 F12 開啟除錯頁面,如下所示:

可以看到,一篇文章的相關資訊就是一個 div, class 屬性為 item blog-item,開啟該 div,如下:
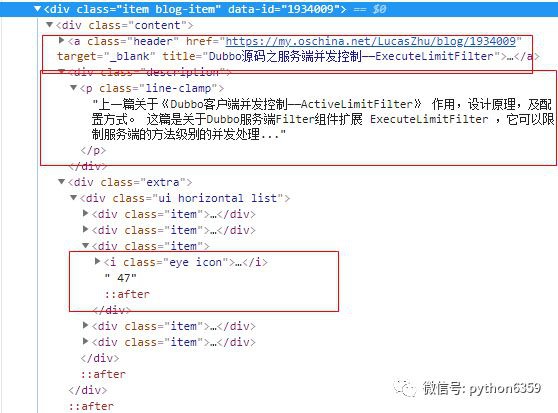
我們要抓取的是文章的標題,描述,URL,和閱讀數,標題和URL可以透過 a 標簽來獲取,描述透過
透過以下程式碼就可以獲取到以上到相關資訊:
# 獲取每個文章相關的 DIV
articles_div = beautiful_soup.find_all("div", class_="item blog-item")
# 處理每個 DIV
for article_div in articles_div:
content_div = article_div.find("div", class_="content")
essay-header_div = content_div.find("a", class_="essay-header")
# 文章URL
url = essay-header_div["href"]
# 文章標題
title = essay-header_div["title"]
# 文章描述
description_str = content_div.find("div", class_="description").find("p", class_="line-clamp")
if description_str is None:
continue
description = description_str.text
# 文章閱讀數
read_count_div = content_div.find("div", class_="extra").find("div", class_="ui horizontal list").find("div", class_="item")
# find_next_sibling 獲取兄弟節點
read_count_i = read_count_div.find_next_sibling("div", class_="item").find_next_sibling("div", class_="item")
read_count = read_count_i.getText()
上述程式碼就是主要的獲取相關資訊的邏輯,因為閱讀數沒有唯一id,或者 class ,所有可以透過 find_next_sibling 來獲取兄弟節點;
接下來就對獲取到到文章進行處理,如按照閱讀數大於等於1000過濾文章,並按照閱讀數從高到低低排序,並且寫到檔案中:
首先要定義一個文章類,用來表示文章的相關資訊,如下:
"""
文章物體類
@authon:tsmyk0715
"""
class Article:
def __init__(self, title, url, content="", read_cnt=0):
"""
文章類構造方法
:param title:文章標題
:param url: 文章 URL
:param content: 文章內容
:param read_cnt: 文章閱讀數
"""
self.title = title
self.url = url
self.content = content
self.read_cnt = read_cnt
def __str__(self):
return u"文章:標題《{0}》,閱讀數:{1},連結:{2}".format(self.title, self.read_cnt, self.url)
之後,定義文章的處理類 OschinaArticle ,相關處理邏輯在該類中實現:
import requests
# 使用 BeautifulSoup 庫來解析 HTML 頁面
from bs4 import BeautifulSoup
import logging
import time
# 匯入定義的文章物體類
from Article import Article
class OschinaArticle:
def __init__(self):
# 日誌
self.log = logging
# 設定日誌級別為 INFO
self.log.basicConfig(level=logging.INFO)
# 把文章寫到檔案的行號
self.file_line_num = 1
接下來獲取 BeautifulSoup 物件:
def getSoup(self, url):
"""
根據 url 獲取 BeautifulSoup 物件
"""
# 請求頭
essay-headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Host": "www.oschina.net"}
# 請求的時候,需要加上頭部資訊,表示是人在操作,而不是機器,不加頭部資訊會報錯
response = requests.get(url, essay-headers=essay-headers)
return BeautifulSoup(response.text, "html.parser")
之後,透過 BeautifulSoup 來解析 HTML 頁面,獲取文章相關資訊,之後,根據相關資訊建立文章物件,放到集合中進行傳回:
def get_articles(self, url):
# 存放文章的集合,進行傳回
article_list = []
beautiful_soup = self.getSoup(url)
self.log.info(u"開始解析 HTML 頁面...")
articles_div = beautiful_soup.find_all("div", class_="item blog-item")
for article_div in articles_div:
content_div = article_div.find("div", class_="content")
essay-header_div = content_div.find("a", class_="essay-header")
# 文章URL
url = essay-header_div["href"]
# 文章標題
title = essay-header_div["title"]
# 文章描述
description_str = content_div.find("div", class_="description").find("p", class_="line-clamp")
if description_str is None:
continue
description = description_str.text
# 文章閱讀數
read_count_div = content_div.find("div", class_="extra").find("div", class_="ui horizontal list").find("div", class_="item")
# find_next_sibling 獲取兄弟節點
read_count_i = read_count_div.find_next_sibling("div", class_="item").find_next_sibling("div", class_="item")
read_count = read_count_i.getText()
# 根據相關資訊建立文章物件,放到集合中,進行傳回
__article = Article(title, url, description, read_count)
article_list.append(__article)
self.log.info(u"文章:標題《{0}》,閱讀數:{1},連結:{2}".format(title, read_count, url))
return article_list
因為文章的閱讀數如果超過 1000 的話,就用 K 來表示,為了在後面篩選指定閱讀數的文章,所以需要進行處理,把 K 轉換為 1000,程式碼如下:
def handler_read_count(self, article_list):
"""
處理閱讀數:把 K 轉換為 1000
:param article_list:文章串列
"""
if article_list is None or len(article_list) == 0:
self.log.info(u"文章串列為空...")
return
for article in article_list:
read_count_str = article.read_cnt.strip()
read_count = 0
if isinstance(read_count_str, str):
if read_count_str.endswith("K"):
read_count_str = read_count_str[:-1] # 去掉K
read_count = int(float(read_count_str) * 1000)
else:
read_count = int(read_count_str)
article.read_cnt = read_count
接下來就是文章根據閱讀數進行篩選和排序了,篩選出閱讀數大於等於指定值並且按照閱讀數從高到低排序,程式碼如下:
def get_article_by_read_count_sort(self, article_list, min_read_cnt):
"""
獲取大於等於指定閱讀數的文章資訊, 並按照閱讀數從高到低排序
:param article_list: 文章串列
:param minx_read_cnt: 最小閱讀數
:return:
"""
if article_list is None or len(article_list) == 0:
self.log.info(u"文章串列為空...")
return
article_list_return = []
for article in article_list:
if article.read_cnt >= min_read_cnt:
article_list_return.append(article)
# 使用 Lambda 對集合中的物件按照 read_cnt 屬性進行排序
article_list_return.sort(key=lambda Article: Article.read_cnt, reverse=True)
return article_list_return
以上就可以獲取到我們想要的文章資訊了,此外,我們可以把資訊寫到檔案檔案中,程式碼如下:
def write_file(self, article_list, file_path):
# 建立 IO 物件
file = open(file_path + "/articles.txt", "a")
for article in article_list:
_article_str = str(article)
file.write("(" + str(self.file_line_num) + ")" + _article_str)
file.write("\n")
file.write("--------------------------------------------------------------------------------------------------------------------------------------------------------")
file.write("\n")
# 檔案行號
self.file_line_num += 1
time.sleep(0.2) # 休眠 200 毫秒
file.close()
之後,把上面的方法整合在一起,程式碼如下:
def run(self, url, min_read_count):
# 獲取所有文章
article_list = self.get_articles(url)
# 對閱讀數進行處理
self.handler_read_count(article_list)
# 篩選閱讀數大於等於指定值,並按閱讀數從高到低排序
_list = self.get_article_by_read_count_sort(article_list, min_read_count)
# 寫檔案
self.write_file(_list, "G:/python")
# 列印控制檯
for a in _list:
self.log.info(a)
main 方法測試一下,地址輸入:https://www.oschina.net/blog?classification=428640, 文章閱讀數要大於等於1000
if __name__ == '__main__':
article = OschinaArticle()
main_url = "https://www.oschina.net/blog?classification=428640"
min_read_count = 1000
article.run(main_url, min_read_count)
控制檯日誌列印如下:

寫入到檔案中的內容如下:

你以為到這裡就完了嗎,no, no, no………….,透過上述方式只能獲取到首頁的文章,如果想獲取更多的文章怎麼辦?開源中國的部落格文章串列沒有分頁,是透過滑動滑鼠滾輪來獲取更多的頁,可是人家的地址導航欄卻沒有絲毫沒有變動,但是可以透過 F12 來看呀,按 F12 後,透過 NetWork 來檢視相關的請求和響應情況:
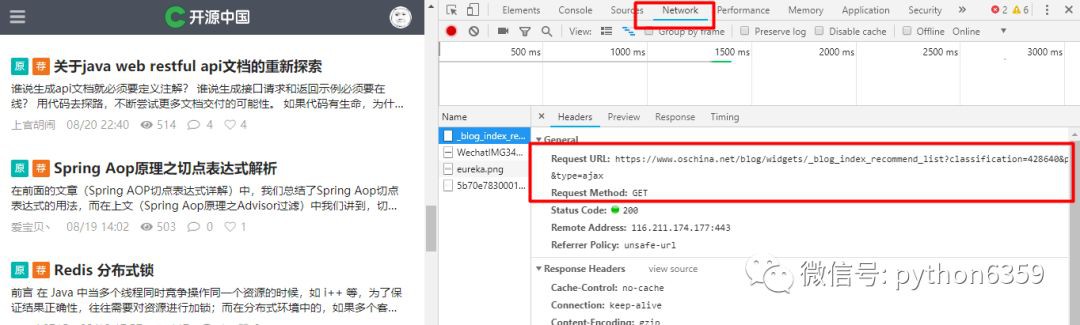
透過滾動幾下滑鼠滾輪之後,可以發現請求的 URL 還是有規律的:
https://www.oschina.net/blog/widgets/_blog_index_recommend_list?classification=428640&p;=2&type;=ajax
https://www.oschina.net/blog/widgets/_blog_index_recommend_list?classification=428640&p;=2&type;=ajax
https://www.oschina.net/blog/widgets/_blog_index_recommend_list?classification=428640&p;=3&type;=ajax
https://www.oschina.net/blog/widgets/_blog_index_recommend_list?classification=428640&p;=4&type;=ajax
https://www.oschina.net/blog/widgets/_blog_index_recommend_list?classification=428640&p;=5&type;=ajax
可以看到除了 p 的引數值不同的話,其他的都相同,p 就是分頁標識,p=2就表示第二頁,p=3就等於第三頁,以此類推,就可以獲取到更多的文章啦:
def main(self, min_read_count, page_size):
# 首頁 URL
self.log.info("首頁##########################")
main_url = "https://www.oschina.net/blog?classification=428640"
self.run(main_url, min_read_count)
# 第2頁到第page_size頁
for page in range(2, page_size):
self.log.info("第 {0} 頁##########################".format(str(page)))
page_url = "https://www.oschina.net/blog/widgets/_blog_index_recommend_list?classification=428640&p;=" + str(page) + "&type;=ajax"
self.run(page_url, min_read_count)
time.sleep(2)
測試:
if __name__ == '__main__':
article = OschinaArticle()
# 獲取到20頁的相關文章,並且閱讀數要大於等於1000
article.main(1000, 21)
日誌控制檯列印如下:

寫到檔案中如下:

可以看到,在 1-20 頁中,閱讀數大於等 1000 的文章有 114 篇,之後就可以 copy URL 到位址列進行閱讀啦………………..
完整程式碼如下:
OschinaArticle 處理邏輯類:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import logging
import time
from Article import Article
"""
爬取開源中國上的文章,且閱讀數大於等於1000
"""
class OschinaArticle:
def __init__(self):
self.log = logging
self.log.basicConfig(level=logging.INFO)
self.file_line_num = 1
def getSoup(self, url):
"""
根據 url 獲取 BeautifulSoup 物件
"""
essay-headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Host": "www.oschina.net"}
response = requests.get(url, essay-headers=essay-headers)
return BeautifulSoup(response.text, "html.parser")
def get_articles(self, url):
article_list = []
beautiful_soup = self.getSoup(url)
self.log.info(u"開始解析 HTML 頁面...")
articles_div = beautiful_soup.find_all("div", class_="item blog-item")
for article_div in articles_div:
content_div = article_div.find("div", class_="content")
essay-header_div = content_div.find("a", class_="essay-header")
# 文章URL
url = essay-header_div["href"]
# 文章標題
title = essay-header_div["title"]
# 文章描述
description_str = content_div.find("div", class_="description").find("p", class_="line-clamp")
if description_str is None:
continue
description = description_str.text
# 文章閱讀數
read_count_div = content_div.find("div", class_="extra").find("div", class_="ui horizontal list").find("div", class_="item")
# find_next_sibling 獲取兄弟節點
read_count_i = read_count_div.find_next_sibling("div", class_="item").find_next_sibling("div", class_="item")
read_count = read_count_i.getText()
__article = Article(title, url, description, read_count)
article_list.append(__article)
# self.log.info(u"文章:標題《{0}》,閱讀數:{1},連結:{2}".format(title, read_count, url))
return article_list
def handler_read_count(self, article_list):
"""
處理閱讀數:把 K 轉換為 1000
:param article_list:文章串列
"""
if article_list is None or len(article_list) == 0:
self.log.info(u"文章串列為空...")
return
for article in article_list:
read_count_str = article.read_cnt.strip()
read_count = 0
if isinstance(read_count_str, str):
if read_count_str.endswith("K"):
read_count_str = read_count_str[:-1] # 去掉K
read_count = int(float(read_count_str) * 1000)
else:
read_count = int(read_count_str)
article.read_cnt = read_count
def get_article_by_read_count_sort(self, article_list, min_read_cnt):
"""
獲取大於等於指定閱讀數的文章資訊, 並按照閱讀數從高到低排序
:param article_list: 文章串列
:param minx_read_cnt: 最小閱讀數
:return:
"""
if article_list is None or len(article_list) == 0:
self.log.info(u"文章串列為空...")
return
article_list_return = []
for article in article_list:
if article.read_cnt >= min_read_cnt:
article_list_return.append(article)
article_list_return.sort(key=lambda Article: Article.read_cnt, reverse=True)
return article_list_return
def write_file(self, article_list, file_path):
file = open(file_path + "/articles.txt", "a")
for article in article_list:
_article_str = str(article)
file.write("(" + str(self.file_line_num) + ")" + _article_str)
file.write("\n")
file.write("--------------------------------------------------------------------------------------------------------------------------------------------------------")
file.write("\n")
self.file_line_num += 1
time.sleep(0.2) # 休眠 200 毫秒
file.close()
def run(self, url, min_read_count):
# 獲取所有文章
article_list = self.get_articles(url)
# 對閱讀數進行處理
self.handler_read_count(article_list)
# 篩選閱讀數大於等於指定值,並按閱讀數從高到低排序
_list = self.get_article_by_read_count_sort(article_list, min_read_count)
# 寫檔案
self.write_file(_list, "G:/python")
# 列印控制檯
for a in _list:
self.log.info(a)
def main(self, min_read_count, page_size):
# 首頁 URL
self.log.info("首 頁##########################")
main_url = "https://www.oschina.net/blog?classification=428640"
self.run(main_url, min_read_count)
# 第2頁到第page_size頁
for page in range(2, page_size):
self.log.info("第 {0} 頁##########################".format(str(page)))
page_url = "https://www.oschina.net/blog/widgets/_blog_index_recommend_list?classification=428640&p;=" + str(page) + "&type;=ajax"
self.run(page_url, min_read_count)
time.sleep(2)
if __name__ == '__main__':
article = OschinaArticle()
# 獲取到20頁的相關文章,並且閱讀數要大於等於1000
article.main(1000, 21)