

俗話說得好,工欲善其事,必先利其器,有了好的工具肯定得知道如何用好這些工具,本篇將分為如下幾個方面介紹如何利用好快取:
-
你真的需要快取嗎
-
如何選擇合適的快取
-
多級快取
-
快取更新
-
快取挖坑三劍客
-
快取汙染
-
序列化
-
GC調優
-
快取的監控
-
一款好的框架
-
總結
你真的需要快取嗎
在使用快取之前,需要確認你的專案是否真的需要快取。使用快取會引入一定的技術複雜度,一般來說從兩個方面來判斷是否需要使用快取:
CPU 佔用
如果你有某些應用需要消耗大量的 CPU 去計算,比如正則運算式;如果你使用正則運算式比較頻繁,而它又佔用了很多 CPU 的話,那你就應該使用快取將正則運算式的結果給快取下來。
資料庫 IO 佔用
如果你發現你的資料庫連線池比較空閑,可以不用快取。但是如果資料庫連線池比較繁忙,甚至經常報出連線不夠的報警,那麼是時候應該考慮快取了。
筆者曾經有個服務被很多其他服務呼叫,其他時間都還好,但是在每天早上 10 點的時候總是會報出資料庫連線池連線不夠的報警。
經過排查,我發現有幾個服務選擇了在 10 點做定時任務,大量的請求打過來,DB 連線池不夠,從而產生連線池不夠的報警。
這個時候有幾個選擇,我們可以透過擴容機器來解決,也可以透過增加資料庫連線池來解決。
但是沒有必要增加這些成本,因為只有在 10 點的時候才會出現這個問題。後來引入了快取,不僅解決了這個問題,而且還增加了讀的效能。
如果並沒有上述兩個問題,那麼你不必為了增加快取而快取。
如何選擇合適的快取
快取分為行程內快取和分散式快取。包括筆者在內的很多人在開始選快取框架的時候都會感到困惑:網上的快取太多了,大家都吹噓自己很牛逼,我該怎麼選擇呢?
選擇合適的行程快取
首先看幾個比較常用快取的比較,具體原理可以參考《你應該知道的快取進化史》:
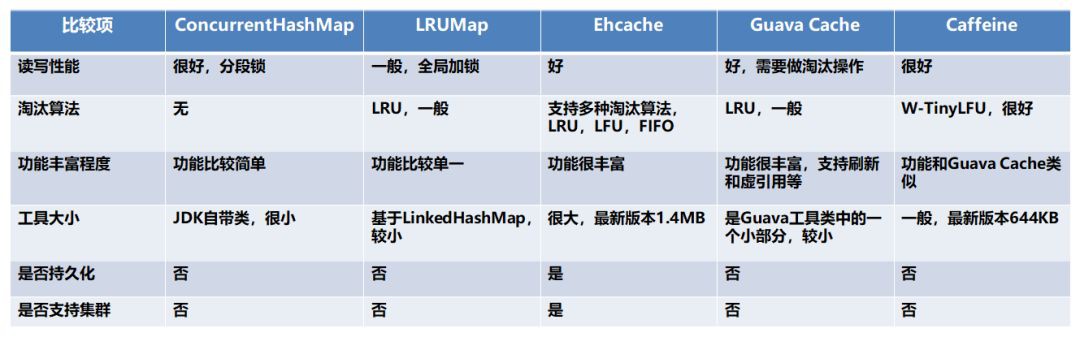
對於 ConcurrentHashMap 來說,比較適合快取比較固定不變的元素,且快取的數量較小的。
雖然從上面表格中比起來有點遜色,但是由於它是 JDK 自帶的類,在各種框架中依然有大量的使用。
比如我們可以用來快取反射的 Method,Field 等等;也可以快取一些連結,防止重覆建立。在 Caffeine 中也是使用的 ConcurrentHashMap 來儲存元素。
對於 LRUMap 來說,如果不想引入第三方包,又想使用淘汰演演算法淘汰資料,可以使用這個。
對於 Ehcache 來說,由於其 jar 包很大,較重量級。對於需要持久化和叢集的一些功能的,可以選擇 Ehcache。
筆者沒怎麼使用過這個快取,如果要選擇的話,可以選擇分散式快取來替代 Ehcache。
對於 Guava Cache 來說,Guava 這個 jar 包在很多 Java 應用程式中都有大量的引入。
所以很多時候直接用就好了,並且它本身是輕量級的而且功能較為豐富,在不瞭解 Caffeine 的情況下可以選擇 Guava Cache。
對於 Caffeine 來說,筆者是非常推薦的,它在命中率,讀寫效能上都比 Guava Cache 好很多。
並且它的 API 和 Guava Cache 基本一致,甚至會多一點。在真實環境中使用 Caffeine,取得過不錯的效果。
總結一下:如果不需要淘汰演演算法則選擇 ConcurrentHashMap;如果需要淘汰演演算法和一些豐富的 API,這裡推薦選擇 Caffeine。
選擇合適的分散式快取
這裡我選取三個比較出名的分散式快取來作為比較,MemCache(沒有實戰使用過),Redis(在美團又叫 Squirrel),Tair(在美團又叫 Cellar)。

不同的分散式快取功能特性和實現原理方面有很大的差異,因此它們所適應的場景也有所不同:
-
MemCache:這一塊接觸得比較少,不做過多的推薦。其吞吐量較大,但是支援的資料結構較少,並且不支援持久化。
-
Redis:支援豐富的資料結構,讀寫效能很高,但是資料全記憶體,必須要考慮資源成本,支援持久化。
-
Tair:支援豐富的資料結構,讀寫效能較高,部分型別比較慢,理論上容量可以無限擴充。
總結:如果服務對延遲比較敏感,Map/Set 資料也比較多的話,比較適合 Redis。
如果服務需要放入快取量的資料很大,對延遲又不是特別敏感的話,那就可以選擇 Tair。
在美團的很多應用中對 Tair 都有應用,在筆者的專案中使用其存放我們生成的支付 Token,支付碼,用來替代資料庫儲存。大部分的情況下兩者都可以選擇,互為替代。
多級快取
一說到快取,很多人腦子裡面馬上就會出現下麵的圖:
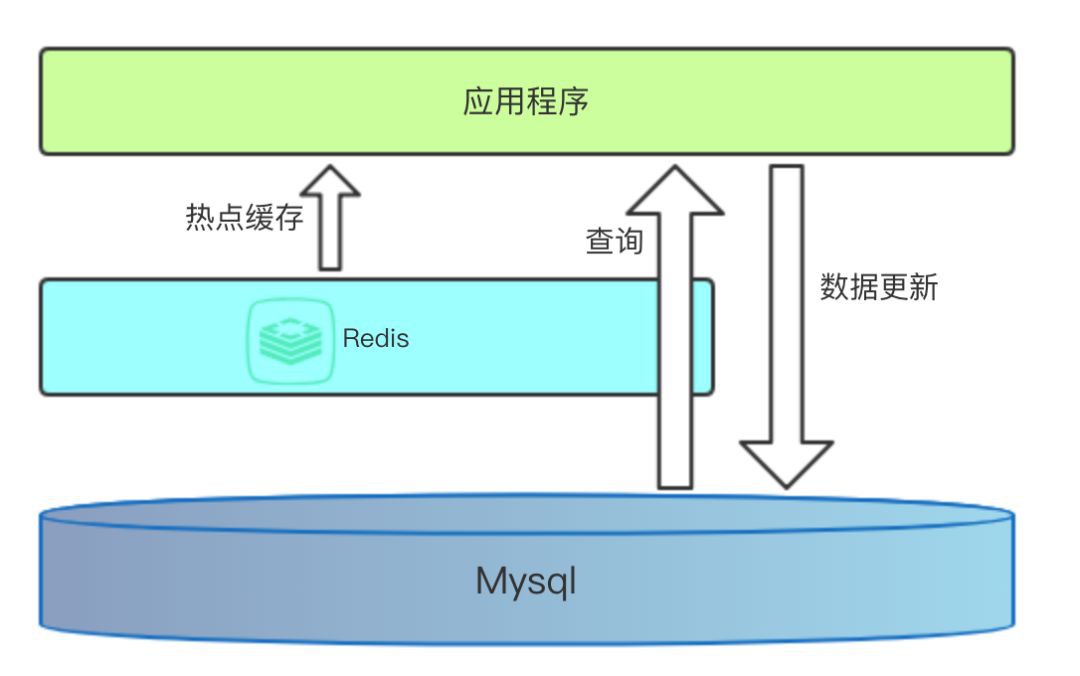
Redis 用來儲存熱點資料,Redis 中沒有的資料則直接去資料庫訪問。
在之前介紹本地快取的時候,很多人都問我,我已經有 Redis 了,我為什麼還需要瞭解 Guava,Caffeine 這些行程快取呢?
我統一回覆下,有如下兩個原因:
-
Redis 如果掛了或者使用老版本的 Redis,會進行全量同步,此時 Redis 是不可用的,這個時候我們只能訪問資料庫,很容易造成雪崩。
-
訪問 Redis 會有一定的網路 I/O 以及序列化反序列化,雖然效能很高但是終究沒有本地方法快,可以將最熱的資料存放在本地,以便進一步加快訪問速度。
這個思路並不是我們做網際網路架構獨有的,在計算機系統中使用 L1,L2,L3 多級快取,用來減少對記憶體的直接訪問,從而加快訪問速度。

所以如果僅僅是使用 Redis,能滿足我們大部分需求,但是當需要追求更高效能以及更高可用性的時候,那就不得不瞭解多級快取。
使用行程快取
對於行程內快取,它本來受限於記憶體大小的限制,以及行程快取更新後其他快取無法得知,所以一般來說行程快取適用於:
資料量不是很大,資料更新頻率較低,之前我們有個查詢商家名字的服務,在傳送簡訊的時候需要呼叫,由於商家名字變更頻率較低,並且就算是變更了沒有及時變更快取,簡訊裡面帶有老的商家名字客戶也能接受。
利用 Caffeine 作為本地快取,Size 設定為 1 萬,過期時間設定為 1 個小時,基本能在高峰期解決問題。
如果資料量更新頻繁,也想使用行程快取的話,那麼可以將其過期時間設定為較短,或者設定其較短的自動掃清的時間。這些對於 Caffeine 或者 Guava Cache 來說都是現成的 API。
使用多級快取
俗話說得好,世界上沒有什麼是一個快取解決不了的事,如果有,那就兩個。
一般來說我們選擇一個行程快取和一個分散式快取來搭配做多級快取,一般來說引入兩個也足夠了。
如果使用三個,四個的話,技術維護成本會很高,反而有可能會得不償失,如下圖所示:
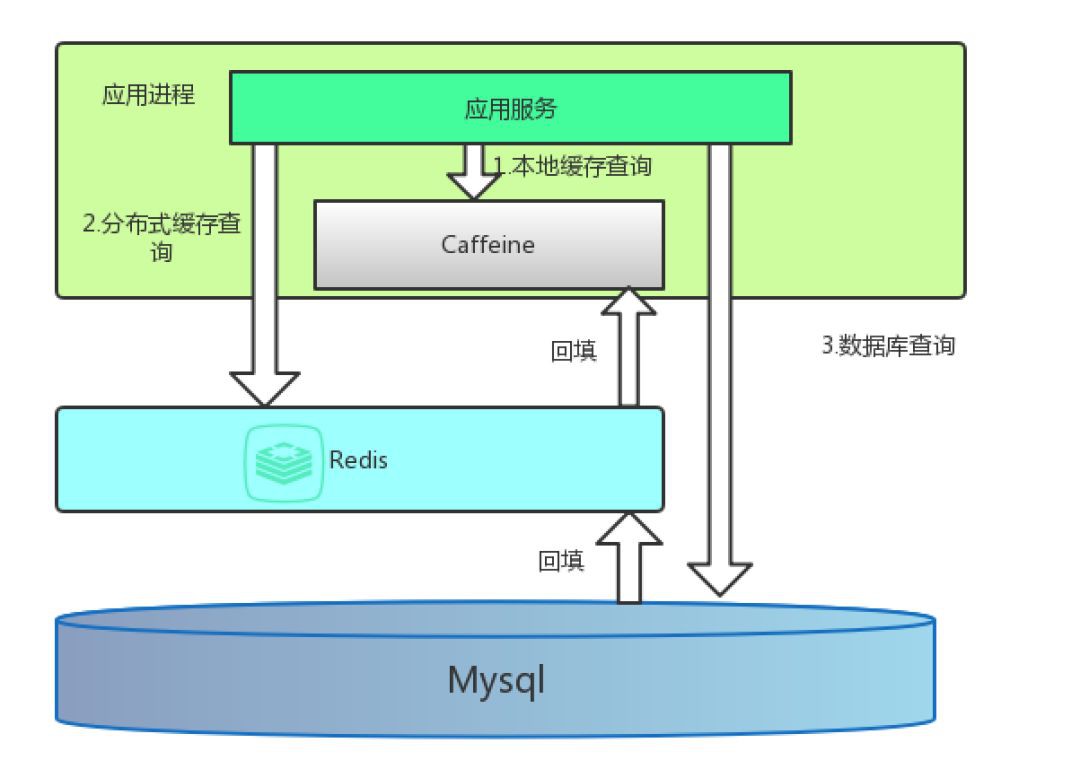
利用 Caffeine 做一級快取,Redis 作為二級快取,步驟如下:
-
首先去 Caffeine 中查詢資料,如果有直接傳回。如果沒有則進行第 2 步。
-
再去 Redis 中查詢,如果查詢到了傳回資料併在 Caffeine 中填充此資料。如果沒有查到則進行第 3 步。
-
最後去 MySQL 中查詢,如果查詢到了傳回資料併在 Redis,Caffeine 中依次填充此資料。
對於 Caffeine 的快取,如果有資料更新,只能刪除更新資料的那臺機器上的快取,其他機器只能透過超時來過期快取,超時設定可以有兩種策略:
-
設定成寫入後多少時間後過期。
-
設定成寫入後多少時間掃清。
對於 Redis 的快取更新,其他機器立刻可見,但是也必須要設定超時時間,其時間比 Caffeine 的過期長。
為瞭解決行程內快取的問題,設計進一步最佳化:

透過 Redis 的 Pub/Sub,可以通知其他行程快取對此快取進行刪除。如果 Redis 掛了或者訂閱機制不靠譜,依靠超時設定,依然可以做兜底處理。
快取更新
一般來說快取的更新有兩種情況:
-
先刪除快取,再更新資料庫。
-
先更新資料庫,再刪除快取。
這兩種情況在業界,大家都有自己的看法。具體怎麼使用還得看各自的取捨。當然肯定有人會問為什麼要刪除快取呢?而不是更新快取呢?
當有多個併發的請求更新資料,你並不能保證更新資料庫的順序和更新快取的順序一致,那麼就會出現資料庫中和快取中資料不一致的情況。所以一般來說考慮刪除快取。
先刪除快取,再更新資料庫
對於一個更新操作簡單來說,就是先對各級快取進行刪除,然後更新資料庫。
這個操作有一個比較大的問題,在對快取刪除完之後,有一個讀請求,這個時候由於快取被刪除所以直接會讀庫,讀操作的資料是老的並且會被載入進入快取當中,後續讀請求全部訪問的老資料。

對快取的操作不論成功失敗都不能阻塞我們對資料庫的操作,那麼很多時候刪除快取可以用非同步的操作,但是先刪除快取不能很好的適用於這個場景。
先刪除快取也有一個好處是,如果對資料庫操作失敗了,那麼由於先刪除的快取,最多隻是造成 Cache Miss。
先更新資料庫,再刪除快取(推薦)
如果我們使用更新資料庫,再刪除快取就能避免上面的問題。但是同樣引入了新的問題。
試想一下有一個資料此時是沒有快取的,所以查詢請求會直接落庫,更新操作在查詢請求之後,但是更新操作刪除資料庫操作在查詢完之後回填快取之前,就會導致我們快取中和資料庫出現快取不一致。
為什麼我們這種情況有問題,很多公司包括 Facebook 還會選擇呢?因為要觸發這個條件比較苛刻:
-
首先需要資料不在快取中。
-
其次查詢操作需要在更新操作先到達資料庫。
-
最後查詢操作的回填比更新操作的刪除後觸發,這個條件基本很難出現,因為更新操作的本來在查詢操作之後,一般來說更新操作比查詢操作稍慢。但是更新操作的刪除卻在查詢操作之後,所以這個情況比較少出現。
對比上面先刪除快取,再更新資料庫的問題來說這種問題出現的機率很低,況且我們有超時機制保底所以基本能滿足我們的需求。
如果真的需要追求完美,可以使用二階段提交,但是成本和收益一般來說不成正比。
當然還有個問題是如果我們刪除失敗了,快取的資料就會和資料庫的資料不一致,那麼我們就只能靠過期超時來進行兜底。
對此我們可以進行最佳化,如果刪除失敗的話 我們不能影響主流程那麼我們可以將其放入佇列後續進行非同步刪除。
快取挖坑三劍客
大家一聽到快取有哪些註意事項,首先想到的肯定是快取穿透,快取擊穿,快取雪崩這三個挖坑的小能手,這裡簡單介紹一下他們具體是什麼以及應對的方法。
快取穿透
快取穿透是指查詢的資料在資料庫是沒有的,那麼在快取中自然也沒有,所以在快取中查不到就會去資料庫查詢,這樣的請求一多,我們資料庫的壓力自然會增大。
為了避免這個問題,可以採取下麵兩個手段:
約定:對於傳回為 NULL 的依然快取,對於丟擲異常的傳回不進行快取,註意不要把拋異常的也給快取了。
採用這種手段會增加我們快取的維護成本,需要在插入快取的時候刪除這個空快取,當然我們可以透過設定較短的超時時間來解決這個問題。

制定一些規則過濾一些不可能存在的資料,小資料用 BitMap,大資料可以用布隆過濾器。
比如你的訂單 ID 明顯是在一個範圍 1-1000,如果不是 1-1000 之內的資料那其實可以直接給過濾掉。

快取擊穿
對於某些 Key 設定了過期時間,但是它是熱點資料,如果某個 Key 失效,可能大量的請求打過來,快取未命中,然後去資料庫訪問,此時資料庫訪問量會急劇增加。
為了避免這個問題,我們可以採取下麵的兩個手段:
-
加分散式鎖:載入資料的時候可以利用分散式鎖鎖住這個資料的 Key,在 Redis 中直接使用 SetNX 操作即可。
對於獲取到這個鎖的執行緒,查詢資料庫更新快取,其他執行緒採取重試策略,這樣資料庫不會同時受到很多執行緒訪問同一條資料。
-
非同步載入:由於快取擊穿是熱點資料才會出現的問題,可以對這部分熱點資料採取到期自動掃清的策略,而不是到期自動淘汰。淘汰也是為了資料的時效性,所以採用自動掃清也可以。
快取雪崩
快取雪崩是指快取不可用或者大量快取由於超時時間相同在同一時間段失效,大量請求直接訪問資料庫,資料庫壓力過大導致系統雪崩。
為了避免這個問題,我們採取下麵的手段:
-
增加快取系統可用性,透過監控關註快取的健康程度,根據業務量適當的擴容快取。
-
採用多級快取,不同級別快取設定的超時時間不同,即使某個級別快取都過期,也有其他級別快取兜底。
-
快取的 Key 值可以取個隨機值,比如以前是設定 10 分鐘的超時時間,那每個 Key 都可以隨機 8-13 分鐘過期,儘量讓不同 Key 的過期時間不同。
快取汙染
快取汙染一般出現在我們使用本地快取中。可以想象,在本地快取中如果你獲得了快取,但是你接下來修改了這個資料,這個資料卻並沒有更新在資料庫,這樣就造成了快取汙染:

上面的程式碼就造成了快取汙染,透過 ID 獲取 Customer,但是需求需要修改 Customer 的名字。
所以開發人員直接在取出來的物件中直接修改,這個 Customer 物件就會被汙染,其他執行緒取出這個資料就是錯誤的資料。
要想避免這個問題需要開發人員從編碼上註意,並且程式碼必須經過嚴格的 Review,以及全方位的回歸測試,才能從一定程度上解決這個問題。
序列化
序列化是很多人都不註意的一個問題,很多人忽略了序列化的問題,上線之後馬上報出一下奇怪的錯誤異常,造成了不必要的損失,最後一排查都是序列化的問題。
列舉幾個序列化常見的問題:
Key-Value 物件過於複雜導致序列化不支援:筆者之前出過一個問題,在美團的 Tair 內部預設是使用 protostuff 進行序列化。
而美團使用的通訊框架是 thfift,thrift 的 TO 是自動生成的,這個 TO 裡面有很多複雜的資料結構,但是將它存放到了 Tair 中。
查詢的時候反序列化也沒有報錯,單測也透過,但是到 QA 測試的時候發現這一塊功能有問題,有個欄位是 boolean 型別預設是 False,把它改成 true 之後,序列化到 Tair 中再反序列化還是 False。
定位到是 protostuff 對於複雜結構的物件(比如陣列,List 等等)支援不是很好,會造成一定的問題。
後來對這個 TO 進行了轉換,用普通的 Java 物件就能進行正確的序列化反序列化。
添加了欄位或者刪除了欄位,導致上線之後老的快取獲取的時候反序列化報錯,或者出現一些資料移位。
不同的 JVM 的序列化不同,如果你的快取有不同的服務都在共同使用(不提倡),那麼需要註意不同 JVM 可能會對 Class 內部的 Field 排序不同,而影響序列化。
比如(舉例,實際情況不一定如此)下麵的程式碼,在 JDK7 和 JDK8 中物件 A 的排列順序不同,最終會導致反序列化結果出現問題:
//jdk 7
class A{
int a;
int b;
}
//jdk 8
class A{
int b;
int a;
}
序列化的問題必須得到重視,解決的辦法有如下幾點:
測試:對於序列化需要進行全面的測試,如果有不同的服務並且他們的 JVM 不同,那麼你也需要做這一塊的測試。
在上面的問題中筆者的單測透過的原因是用的預設資料 False,所以根本沒有測試 true 的情況,還好 QA 給力,將它給測試出來了。
對於不同的序列化框架都有自己不同的原理,對於新增欄位之後如果當前序列化框架不能相容老的,那麼可以換個序列化框架。
對於 protostuff 來說它是按照 Field 的順序來進行反序列化的,對於新增欄位我們需要放到末尾,也就是不能插在中間,否則會出現錯誤。
對於刪除欄位來說,用 @Deprecated 註解進行標註棄用,如果貿然刪除,除非是最後一個欄位,否則肯定會出現序列化異常。
可以使用雙寫來避免,對於每個快取的 Key 值可以加上版本號,每次上線版本號都加 1。
比如現線上上的快取用的是 Key_1,即將要上線的是 Key_2,上線之後對快取的新增是會寫新老兩個不同的版本(Key_1,Key_2)的 Key-Value,讀取資料還是讀取老版本 Key_1 的資料。
假設之前的快取的過期時間是半個小時,那麼上線半個小時之後,之前的老快取存量的資料都會被淘汰,此時線上老快取和新快取的資料基本是一樣的,切換讀操作到新快取,然後停止雙寫。
採用這種方法基本能平滑過渡新老 Model 交替,但是不好的就是需要短暫的維護兩套新老 Model,下次上線的時候需要刪除掉老 Model,這樣增加了維護成本。
GC 調優
對於大量使用本地快取的應用,由於涉及到快取淘汰,那麼 GC 問題必定是常事。如果出現 GC 較多,STW 時間較長,那麼必定會影響服務可用性。
這一塊給出下麵幾點建議:
-
經常檢視 GC 監控,如何發現不正常,需要想辦法對其進行最佳化。
-
對於 CMS 垃圾收集演演算法,如果發現 Remark 過長,如果是大量本地快取應用的話這個過長應該很正常,因為在併發階段很容易有很多新物件進入快取,從而 Remark 階段掃描很耗時,Remark 又會暫停。
可以開啟 XX:CMSScavengeBeforeRemark,在 Remark 階段前進行一次 YGC,從而減少 Remark 階段掃描 GC Root 的開銷。
-
可以使用 G1 垃圾收集演演算法,透過 XX:MaxGCPauseMillis 設定最大停頓時間,提高服務可用性。
快取的監控
很多人對於快取的監控也比較忽略,基本上線之後如果不報錯,然後就預設它就生效了。
但是存在這個問題,很多人由於經驗不足,有可能設定了不恰當的過期時間,或者不恰當的快取大小導致快取命中率不高,讓快取成為了程式碼中的一個裝飾品。
所以對於快取各種指標的監控,也比較重要,透過不同的指標資料,我們可以對快取的引數進行最佳化,從而讓快取達到最最佳化:

上面的程式碼中用來記錄 Get 操作的,透過 Cat 記錄了獲取快取成功,快取不存在,快取過期,快取失敗(獲取快取時如果丟擲異常,則叫失敗)。
透過這些指標,我們就能統計出命中率,我們調整過期時間和大小的時候就可以參考這些指標進行最佳化。
一款好的框架
一個好的劍客沒有一把好劍怎麼行呢?如果要使用好快取,一個好的框架也必不可少。
在最開始使用的時候,大家使用快取都用一些 util,把快取的邏輯寫在業務邏輯中:
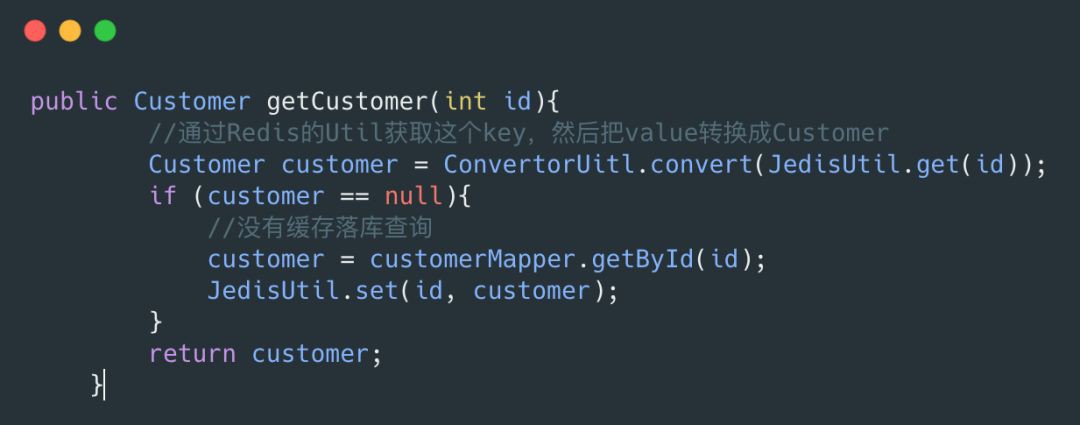
上面的程式碼把快取的邏輯耦合在業務邏輯當中,如果我們要增加成多級快取那就需要修改我們的業務邏輯,不符合開閉原則,所以引入一個好的框架是不錯的選擇。
推薦大家使用 JetCache 這款開源框架,它實現了 Java 快取規範 JSR107 並且支援自動掃清等高階功能。
筆者參考 JetCache 結合 Spring Cache,監控框架 Cat 以及美團的熔斷限流框架 Rhino 實現了一套自有的快取框架,讓操作快取,打點監控,熔斷降級,業務人員無需關心。
上面的程式碼可以最佳化成:

對於一些監控資料也能輕鬆從大盤上看到:
總結
想要真正的使用好一個快取,必須要掌握很多的知識,並不是看幾個 Redis 原理分析,就能把 Redis 快取用得爐火純青。
對於不同場景,快取有各自不同的用法,同樣的不同的快取也有自己的調優策略,行程內快取你需要關註的是它的淘汰演演算法和 GC 調優,以及要避免快取汙染等。
分散式快取你需要關註的是它的高可用,如果它不可用了,如何進行降級,以及一些序列化的問題。
一個好的框架也是必不可少的,對它如果使用得當再加上上面介紹的經驗,相信能讓你很好的駕馭住這頭野馬——快取。
推薦閱讀:
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取電子書詳情。

求知若渴, 虛心若愚

