點選上方“芋道原始碼”,選擇“置頂公眾號”
技術文章第一時間送達!
原始碼精品專欄
Facebook起源的NewsFeed,以及Twitter起源的Timeline,核心問題都是如何處理巨大的訊息(活動,activity)分發。“推Push”和“拉Pull”或者“推拉結合”,是主要的處理方式。
以前各大網站陸續透露的檔案,以及這次QCon2012 London和深圳的架構師會議,較大程度的公開了各自的實現方式。本文從 訊息分發樣式;內部通訊工具、協議;儲存方式 3方面總結。
各大網站都大量使用的Nginx, memcached, MySQL等開源產品,都標配了,文中不再提。實現技術上,非同步訊息佇列的引入,來模組解耦和尖峰削平;Cache的精良設計等,也都是各家大量使用的技能,可看參看檔案,不再詳述。
1Facebook
參考《Facebook news-feed QCon12.pdf》。典型的Pull方式,讀時fanout,獲得所有好友的活動,再進行聚合,rank,排序等操作(這幾步後續動作,是feed和timeline的最大不同特點)。Facebook把這種樣式叫做“Multifeed – Multi-fetch and aggregate stories at read time”。  FB的眾多產品、模組,通訊協議自然用自家的Thrift,還用到SMC和其他的底層平臺。
FB的眾多產品、模組,通訊協議自然用自家的Thrift,還用到SMC和其他的底層平臺。
儲存模組,有自家的“排序”儲存檔案(feed要按時間倒排,還有rank影響排序…記憶體的B樹排序結構,可以預測性的合併到檔案。可能開源)。還大量使用了 Redis 和Google開發的開源持久化KV儲存: LevelDB。
Feeds相對於Timeline,最大特點是有rank影響排序,需要按型別合併,有推薦演演算法的插入,有更複雜的資料結構…這些都是影響架構設計的重要因素,但這些都沒有檔案詳細描述。拉樣式下,最重要的是高效穩定、分散式的Aggregator的設計,也沒有詳細檔案說明。
(Facebook可以說是技術檔案最不透明的網站了,特別是相較於他擁有最大的UGC而言。)
2Twitter
參考《TimelinesTwitter-QCon12.pdf》等眾多檔案。主要是推樣式。Twitter的Timeline這種應用,和FB的Feed最大的區別,就是要解決fan-out的效率和全文搜尋的效率。整體模組劃分圖: 
主要特點是對fanout的處理:佇列化(有自己用Scala語言實現的Kestrel佇列),併發處理推送等大消耗業務,各級快取(包括In-Proc)…
通訊協議上, Kestrel 復用了MemCached協議;而Timeline API模組使用了FB的Thrift。通訊框架是大量使用的自己開發的(已開源)RPC框架 Finagle (A fault tolerant, protocol-agnostic RPC system)。
搜尋引擎使用了Lucene。儲存也大量使用了Redis。
3人人網
參考《人人網Feed系統結構淺析.pdf》和《人人網網站架構–服務化的演進》。作為中國的大型SNS網站,設計上也有很多自己的特色。
從查詢的效率考慮, 人人網採用了推樣式(近似twitter樣式)。但是,人人網的Feeds,又比twitter類的timeline,有更複雜的結構和功能需求,所以在設計上,會有FB和Twitter雙方融合的特點。 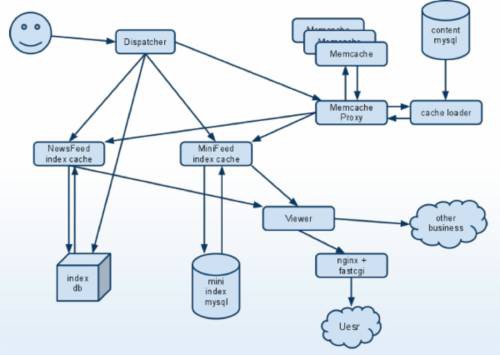
在Cache上,人人有自己實現的Server來支援。特別是在IndexCache上,基本資料結構和FB一樣,使用了C++ Boost multi-index container;序列化和壓縮採用Protobuf和QuickLZ。特別是有專門實現的解決feed索引持久化難題的Feed Index DB。
最後用模板渲染引擎(也是C++實現)來顯示覆雜的Feed。
Renren在網路通訊上大量使用 ICE框架 ,協議上多用Protobuf,實現快取等中間層、新鮮事兒等系統。大量自己開發的server叢集,透過他們高效通訊。
在高效能運算上,Renren網傾向用C/C++編寫定製性Server,保證資料中心儲存,大規模資料儘量在行程內訪問。像IndexCache Server(海量的Feed資料裝載在單一Server內,實現“資料盡可能靠近CPU”的原則),實現高速排序等計算需求;此外還有檔案裡提及的渲染Server…都是用C寫的專用Server。好處自然是本地記憶體的納秒級訪問速度,遠遠高於網路IO,可實現極高的效能。
現在,人人網的架構也在向Service化方向發展,並封裝成了XOA,基礎匯流排使用了Thrift,訊息佇列用了ZeroMQ …
4新浪微博
參考TimYang的《 構建可擴充套件的微博架構 》和《新浪微博cache設計談.pdf》
雖然來源於Twitter,但不得不說,就資料量、複雜性而言,已經不弱於Twitter;穩定性更是高出了Twitter很多。新浪微博基礎是拉樣式,但是增加了“線上推”,對於線上使用者有“Inbox Cache”加速對timeline的獲取,減少aggregator的效能和時間消耗。結構如下圖: 
首頁timeline獲取步驟是:1.檢查inbox cache是否可用; 2.獲取關註串列; 3.聚合內容, 從 following 關係; 4.根據id list傳回最終feed聚合內容。Sina的這種結合樣式,符合中國的特點:明星海量粉絲(純推送代價巨大),個人使用者關註多(純拉取代價大),且線上使用者能得到極快的響應。
儲存大量使用了Redis。並且有專門的講演,詳細介紹了Sina在Redis的大規模應該場景。《 Redis介紹》 《 新浪微博開放平臺Redis實踐 》
但是基於拉樣式的aggragator沒有對外介紹。此外,sina微博的訊息機制、RPC框架,也未介紹。
5騰訊微博
參考《 張松國-騰訊微博架構介紹 08.pdf》。騰訊作為最有技術底子的公司,其架構有很多獨特之處,參考和直接利用國外的網站的樣式最少。騰訊微博採用“拉”樣式,聚合計算aggregator採用了多級樣式: 
同大多的timeline系統一樣,使用佇列來非同步化和解耦,不過qq的解耦包括了系統解耦和業務解耦(和Renren網的“中轉單向RPC呼叫的訊息佇列”類似),不但解耦模組,還使得各模組開發得以並行,提升開發效率。其主要架構圖: 
騰訊的積累,使得騰訊微博在平臺化做的扎實。整個產品的“介面-服務”感覺清晰。在容災容錯方面更是比其它家(至少從檔案上)高出了很多。叢集建設,系統維護都沿襲了騰訊的積累,光海量日誌的查詢就用了Sphinx全文搜尋。資料挖掘和分析(比如關係鏈分析、圈子挖掘、使用者價值評估)也一直是騰訊的重點能力。
如果你對 Dubbo 感興趣,歡迎加入我的知識星球一起交流。

目前在知識星球(https://t.zsxq.com/2VbiaEu)更新瞭如下 Dubbo 原始碼解析如下:
01. 除錯環境搭建
02. 專案結構一覽
03. 配置 Configuration
04. 核心流程一覽
05. 拓展機制 SPI
06. 執行緒池
07. 服務暴露 Export
08. 服務取用 Refer
09. 註冊中心 Registry
10. 動態編譯 Compile
11. 動態代理 Proxy
12. 服務呼叫 Invoke
13. 呼叫特性
14. 過濾器 Filter
15. NIO 伺服器
16. P2P 伺服器
17. HTTP 伺服器
18. 序列化 Serialization
19. 叢集容錯 Cluster
20. 優雅停機
21. 日誌適配
22. 狀態檢查
23. 監控中心 Monitor
24. 管理中心 Admin
25. 運維命令 QOS
26. 鏈路追蹤 Tracing
…
一共 60 篇++
原始碼不易↓↓↓↓↓
點贊支援老艿艿↓↓
