
導讀:本文為你詳細分析資料科學家最需要掌握的普通技能以及特定語言和工具的特殊技能。
作者:Jeff Hale
翻譯:陳之炎
來源:資料派THU(ID:DatapiTHU)
資料科學家需要涉獵的知識面很廣,包括:機器學習、電腦科學、統計學、數學、資料視覺化、溝通和深度學習,那麼資料科學家應如何制定他們的學習預算,才能最大限度地滿足僱主的需要?
我瀏覽了一些求職網站,想找出哪些技能是資料科學家最需要掌握的技能,並對普通資料科學技能以及特定的語言和工具的特殊技能分別做了一些研究。
2018年10月10日,我在LinkedIn,Indeed,SimplyHired,Monster上搜索了求職名單,下麵這個圖表,顯示了每個網站列出的資料科學家職位的數目。
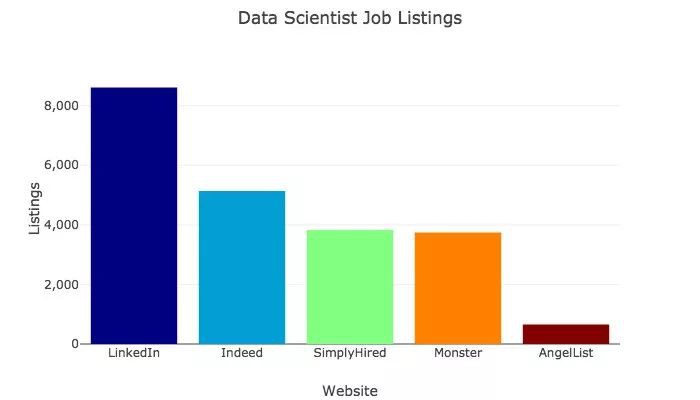
透過閱讀這些職位清單,經過一番調查研究,我找出了資料科學家最常用的技能。像“管理”這樣的術語沒有進行比較,因為它們在職位清單中被太多的背景關係所取用。
所有搜尋都是用“資料科學家”這個關鍵字在美國本土進行的,採用精確匹配搜尋的話,會使得搜尋結果的數量大為減少。精確匹配搜尋確保了搜尋結果均與資料科學家的職位相關,並受到類似搜尋條件的影響。
AngelList列出了需要資料科學家的上市公司的數量,而不是列出了資料科學家職位數量。我將AngelList從這兩種分析中排除,因為它的搜尋演演算法似乎是一種OR(或)型別的邏輯搜尋,沒有將其轉換為AND(與)邏輯。
如果你搜索的關鍵字是 “資料科學家”“ TensorFlow”,那麼只會列出需要資料科學家的公司,AngelList的搜尋效果不錯。但是如果你的關鍵詞是“資料科學家” “react.js”,它會傳回許多需要非資料科學家公司的串列。
Glassdoor 也被排除在我的分析之外。該網站聲稱,它在美國有26263個“資料科學家”職位,但能讓我看到的職位不超過900個。此外,資料科學家的職位數量不可能超過其他主要平臺的三倍以上。最後的分析中包括了在LinkedIn上列出400多個普通技能和200多個特殊技能,當然這其中會有一些交叉。
結果記錄在下麵連結的Google Sheet表格中。我下載了.csv檔案並將它們匯入JupyterLab中。然後,計算出了百分比,併在職位串列網站上對它們進行了平均計算。
Google Sheet表格連結:
https://docs.google.com/spreadsheets/d/1df7QTgdAOItQJadLoMHlIZH3AsQ2j2_yoyvHOpsy9qU/edit?usp=sharing
我還將軟體的計算結果與JupyterLab針對2017年上半年資料科學家職位串列進行了比較。結合KDNuggets’ usage survey的資訊,似乎有些技能變得越來越重要,而另一些則變得越來越不重要。我們一會兒再談。
KDNuggets’ usage survey
https://www.kdnuggets.com/2018/05/poll-tools-analytics-data-science-machine-learning-results.html/2
請參閱我的Kaggle Kernel以獲得互動式圖表和其他的分析。我用Plotly對資料進行視覺化。在編寫這篇文章時,對使用JupyterLab的Ploly出現了一些爭論-指令在我的Kaggle Kernel的結尾的Plotly’s docs之中。
Plotly’s docs
https://github.com/plotly/plotly.py
01 普通技能
以下是僱主最常搜尋的資料科學家技能圖表。
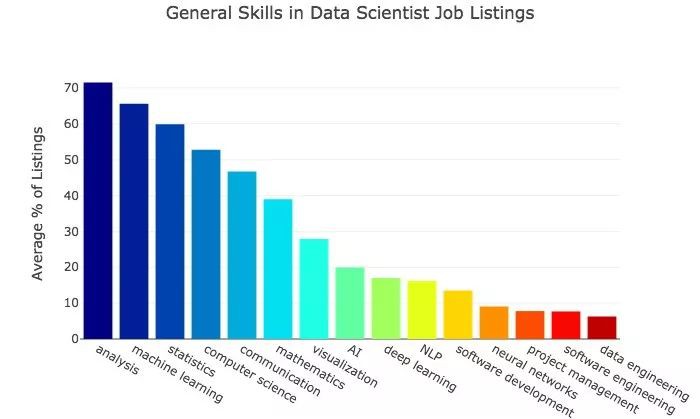
結果表明,分析和機器學習是資料科學家工作的核心。從資料中收集有用資訊是資料科學的主要功能。機器學習的全部內容是建立系統來預測效能,這個需求非常大。
資料科學需要統計學和電腦科學技能——這一點也不奇怪。統計學、電腦科學和數學也都是大學的專業,可能有助於加大它們出現的頻度。
有趣的是,在近一半的職位串列中提到了溝通,資料科學家需要能夠交流見解並與他人密切合作。
人工智慧和深度學習不像其他術語那樣頻繁出現。然而,它們是機器學習的子集。深度學習正被越來越多的機器學習任務所使用,而這些任務以前是由其他演演算法完成的。
例如,對於大多數自然語言處理問題,最好的機器學習演演算法都是當前的深度學習演演算法。我預計,在未來,人們將更加明確地尋求深度學習技能,而機器學習將成為深度學習的代名詞。
僱主們都在尋找掌握哪些特定的軟體工具的資料科學家?接下來我們來解決這個問題。
02 技術技能
僱主們正在尋找的具備以下技能的資料科學家,其中名列前20位的特定語言、庫和技術工具如下。
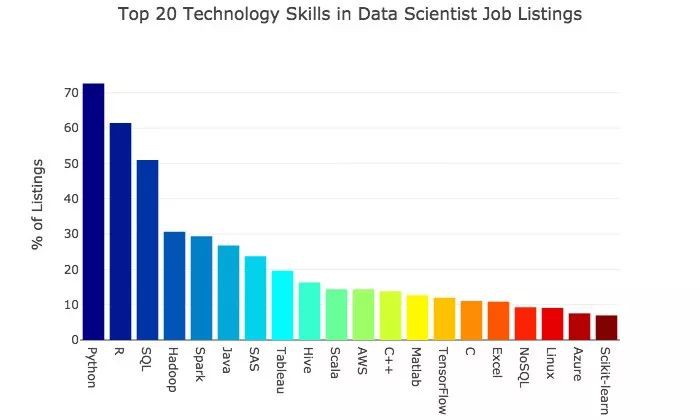
我們來簡要地看看最常見的技術技能。
1. Python

Python是最受歡迎的語言。這種開源語言的受歡迎程度已廣為所知。初學者容易接受,而且有很多支援資源。絕大多數新的資料科學工具都與它相容。Python是資料科學家的主要語言。
2. R

R不遜於 Python,它曾經是資料科學的主要語言。我驚訝地看到它目前仍然很受歡迎。這種開源語言的根源在於統計學,它目前仍然很受統計學家的歡迎。Python或R對於幾乎每一個資料科學家職位來說都是必須的。
3. SQL

SQL也很受歡迎。SQL是結構化查詢語言,是與關係型資料庫互動的主要方式。在資料科學領域,SQL有時會被忽視,但是如果您打算進入就業市場,這是一項值得展示的技能。
4. Hadoop和Spark


接下來是Hadoop和Spark,它們都是Apache提供的用於大資料的開源工具。Apache Hadoop是一個開源的軟體平臺,用於分散式儲存和分散式處理由商業硬體構建的計算機叢集上的大型資料集。
Apache Spark是一個快速、記憶體資料處理引擎,它具有優雅的、有表現力的開發API,使資料工作者能夠高效地執行需要快速迭代訪問資料集的流、機器學習或SQL工作負載。
與許多其他工具相比,這些工具在媒體和教程中,關於它們的文章要少得多。我預計具備這些技能的求職者比具備Python、R和SQL技能的求職者要少得多。如果你有或可以獲得Hadoop和Spark的經驗,會為你的競爭優勢助一臂之力。
5. Java和SAS


然後是Java和SAS。看到這兩種語言位列如此之高,我感到十分驚訝。這兩種語言的背後都有大公司支援,至少有一些免費產品。Java和SAS通常在資料科學社群中很少受到關註。
6. Tableau
接下來是Tableau。這個分析平臺和視覺化工具功能強大,易於使用,並且越來越受歡迎。它有一個免費的公開版本,但如果想要保持資料私密性,則需要付費。
如果你不熟悉Tableau,那麼肯定值得在Udemy上一門快速課程,比如Tableau 10A-Z。我參加了這門課,發現它物超所值。
下圖顯示了這些語言、框架和其他資料科學軟體工具的串列。
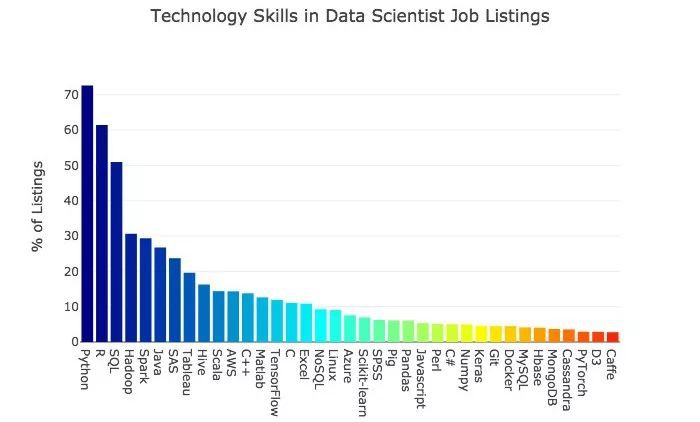
03 歷史比對
GlassDoor分析了2017年1月至2017年7月期間在其網站上的資料科學家最常見的10種軟體技能。以下是與2018年10月LinkedIn, Indeed, SimplyHired, 和Monster平均水平相比,它們在網站上出現頻率的比較。
結果非常相似。我的分析和GlassDoor’s都發現Python、R和SQL是最受歡迎的。我們還發現了同樣的前九位技術技能,只是順序略有不同。
結果表明,與2017年上半年相比,目前對R、Hadoop、Java、SAS和MATLAB需求較少,Tableau需求則更大。這就是我所期望的,對 KDnuggets developer survey等來源的結果的補充。在那裡,R、Hadoop、Java和SAS都顯示出明顯的多年下降趨勢,Tableau顯示出明顯的上升趨勢。
04 建議
根據以上分析結果,為當前和有抱負的資料科學家,提出一些一般性的建議,以使自己在職場上更受歡迎:
1. 證明你可以進行資料分析
並專註於成為真正擅長機器學習的人。
2. 投資於自己的溝通技巧
我建議閱讀《Made to Stick》這本書,它對你的想法會有更大的影響。還可以檢視名稱為 Hemmingway Editor的APP(應用程式),以提高寫作的清晰度。
《Made to Stick》:
https://www.amazon.com/Made-Stick-Ideas-Survive-Others/dp/1400064287
Hemmingway Editor:
http://www.hemingwayapp.com/
3. 掌握一個深度學習的框架
對深度學習框架的熟練程度是精通機器學習的重要組成部分。有關深度學習框架在用法、興趣和流行程度方面的比較,請參閱下方連結中的文章:
https://towardsdatascience.com/deep-learning-framework-power-scores-2018-23607ddf297a
4. 如果在學習Python和R之間進行選擇,請選擇Python
如果對Python不感冒,考慮學習R。如果你會使用Python的同時也知道R,你肯定會更有市場。
當僱主正在尋找一位具備Python技能的資料科學家時,他們也期望應聘者能瞭解常見的Python資料科學庫,如:numpy、pandas、scikit-learn和matplotlib。如果想學習這組工具,我建議提供以下資源:
1. DataCamp和 DataQuest:它們都是定價合理的線上SaaS資料科學教育產品,在這些產品中,您可以一邊編寫程式碼一邊學習,二者都教授一些技術工具。
DataCamp
https://www.datacamp.com/
DataQuest
https://www.dataquest.io/
2. Data School擁有多種資源,包括一套很好的影片,解釋資料科學的概念。
Data School
https://www.dataschool.io/start/
影片資源:
https://www.youtube.com/dataschool
3. 麥金尼(McKinney)的Python for Data Analysis(《利用Python進行資料分析(原書第2版)》)。這本書由pandas庫的主要作者撰寫,重點關註pandas,還討論了基本的python,numpy和scikit-learn等資料科學的知識。
Python for Data Analysis
https://www.amazon.com/Python-Data-Analysis-Wrangling-IPython/dp/1491957662
中文版:《利用Python進行資料分析(原書第2版)》
連結見下方:
4. Müller&Guido;的《用Python進行機器學習簡介》。米勒是scikit-learn的主要維護者。這是一本用於學習機器學習scikit-learn的很好的書。
Introduction to Machine Leaning with Python
https://www.amazon.com/Introduction-Machine-Learning-Python-Scientists-ebook/dp/B01M0LNE8C
如果你想探究深度學習,我建議在進入TensorFlow或PyTorch之前先從Keras或FastAI開始。Chollet的《用Python進行的深度學習》一書是學習Keras的很好的資源。除了這些建議之外,我建議你瞭解自己感興趣的內容,儘管在決定如何分配學習時間時有很多因素需要考慮。
如果你想透過網路門戶尋找一份資料科學家的工作,我建議你從LinkedIn開始——它的結果總是最多的。
如果你在網上求職或者在求職網站上釋出職位,關鍵詞非常重要。“資料科學”傳回的結果是“資料科學家”傳回結果數的近3倍。但是,如果你在嚴格地尋找資料科學家的工作,你最好還是輸入 “資料科學家”這個關鍵字。
無論你在哪個網站找工作,我建議你建立一個線上組合串列,列出你對所需求技能領域的熟練程度。我還建議用LinkedIn個人資料展示你的技能。
作為這個專案的一部分,我收集了其他資料,可能也會寫成文章。跟我來,不要錯過哦。
如果您希望看到互動式圖表和它們背後的程式碼,請檢視我的Kaggle Kernel:
Kaggle Kernel:
https://www.kaggle.com/discdiver/the-most-in-demand-skills-for-data-scientists/
關於作者:Jeff Hale是一位經驗豐富的企業家,曾為多家公司管理過技術、運營和財務。專註於機器學習領域的資料科學家,子商務公司的共同創始人和營運長。目前,傑夫正將他對資料驅動決策的熱情轉化為以資料科學家為職業期盼。他對機器學習、交流和資料分析很感興趣。
關於譯者:陳之炎,北京交通大學通訊與控制工程專業畢業,獲得工學碩士學位,現任北京吾譯超群科技有限公司技術支援。目前從事智慧化翻譯教學系統的運營和維護,在人工智慧深度學習和自然語言處理(NLP)方面積累有一定的經驗。
原文標題:
The Most in Demand Skills for Data Scientists
原文連結:
https://www.kdnuggets.com/2018/11/most-demand-skills-data-scientists.html

我們正在繪製一份大資料粉絲畫像——
2019大資料粉絲有獎調查問捲上線了
歡迎長按二維碼或點選閱讀原文填寫

我們每週一將從參與者中
隨機抽取3名幸運小夥伴
每位將獲贈近期出版的技術類圖書1本