

本文由Ceph中國社群穆艷學翻譯、耿航校稿,英文原文出處: Red_Hat_Ceph_Storage-2-Architecture_Guide (掃文尾二維碼讀原文)
目錄
第1章 概覽
第2章 儲存叢集架構
2.1 儲存池
2.2 身份認證
2.3 PG(s)
2.4 CRUSH
2.5 I/O操作
2.5.1 副本I/O
2.5.2 糾刪碼I/O
2.6 自管理的內部操作
2.6.1 心跳
2.6.2 同步
2.6.3 資料再平衡與恢復
2.6.4 校驗(或擦除)
2.7 高可用
2.7.1 資料副本
2.7.2 Mon叢集
2.7.3 CephX
第3章 客戶端架構
3.1 本地協議與Librados
3.2 物件的監視與通知
3.3 獨佔鎖
3.4 物件對映索引
3.5 資料條帶化
第4章 加密
第1章 概覽
Red Hat Ceph是一個分散式的資料物件儲存,系統設計旨在效能、可靠性和可擴充套件性上能夠提供優秀的儲存服務。分散式物件儲存是儲存的未來,因為它們適應非結構化資料,並且客戶端可以同時使用現代及傳統的物件介面進行資料存取。例如:
-
本地語言系結介面(C/C++、Java、Python)
-
RESTful 介面(S3/Swift)
-
塊裝置介面
-
檔案系統介面
Red Hat Ceph所具備的強大功能可以改變您公司(或組織)的IT基礎架構和管理海量資料的能力,特別是對於像RHEL OSP這樣的雲端計算平臺。
Red Hat Ceph具有非常好的可擴充套件性——數以千計的客戶端可以訪問PB級到EB級甚至更多的資料。
譯者註: 資料的規模可以用KB、MB、GB、TB、PB、EB、YB等依次表示,比如1TB = 1024GB。
每一個Ceph部署的核心就是Ceph儲存叢集。 叢集主要是由2類後臺守護行程組成:
-
Ceph OSD守護行程:Ceph OSD為Ceph客戶端儲存資料提供支援。另外,Ceph OSD利用Ceph節點的CPU和記憶體來執行資料複製、資料再平衡、資料恢復、狀態監視以及狀態上報等功能。
-
Ceph 監視器:Ceph監視器使用儲存叢集的當前狀態維護Ceph儲存叢集對映關係的一份主副本。

Ceph客戶端介面與Ceph儲存叢集進行資料讀寫上的互動。客戶端要與Ceph儲存叢集通訊,則需要具備以下條件:
-
Ceph配置檔案,或者叢集名稱(通常名稱為ceph)與監視器地址
-
儲存池名稱
-
使用者名稱及金鑰所在路徑
Ceph客戶端維護物件ID和儲存物件的儲存池名稱,但它們既不需要維護物件到OSD的索引,也不需要與一個集中的物件索引進行通訊來查詢資料物件的位置。
為了能夠儲存並獲取資料,Ceph客戶端首先會訪問一臺Ceph mon並得到最新的儲存叢集對映關係,然後Ceph客戶端可以透過提供的物件名稱與儲存池名稱,使用叢集對映關係和CRUSH演演算法(可控的、可擴充套件的、分散式的副本資料放置演演算法)來計算出提供物件所在的PG和主Ceph OSD,最後,Ceph客戶端連線到可執行讀寫操作的主OSD上進而達到資料的儲存與獲取。客戶端和OSD之間沒有中間伺服器,中介軟體或匯流排。
當一個OSD需要儲存資料時(無論客戶端是Ceph Block裝置,Ceph物件閘道器或其他介面),從客戶端接收資料然後將資料儲存為物件。每一個物件相當於檔案系統中存放於如磁碟等儲存裝置上的一個檔案。

註: 一個物件的ID在整個叢集中是唯一的,(全域性唯一)而不僅僅是本地檔案系統中的唯一。
Ceph OSD將所有資料作為物件儲存在扁平結構的名稱空間中(例如,沒有目錄層次結構)。物件在叢集範圍內具有唯一的標識、二進位制資料、以及由一組名稱/值的鍵值對組成的元資料。而這些語意完全取決於Ceph的客戶端。例如,Ceph塊裝置將塊裝置映象對映到叢集中儲存的一系列物件上。

註: 由唯一ID、資料、名稱/值構成鍵值對的元資料組成的物件可以表示結構化和非結構化資料,以及前沿新的資料儲存介面或者原始老舊的資料儲存介面。
第2章 儲存叢集架構
為了有效的實現無限可擴充套件性、高可用性以及服務效能,Ceph儲存叢集可以包含大量的Ceph節點。每個節點利用商業硬體以及智慧的Ceph守護行程實現彼此之間的通訊:
-
儲存和檢索資料
-
資料複製
-
監控並報告叢集執行狀況(心跳)
-
動態的重新分佈資料(回填)
-
確保資料完整性(清理及校驗)
-
失敗恢復
對於讀寫資料的Ceph客戶端介面來說,Ceph儲存叢集看起來就像一個儲存資料的簡單儲存池。然而,儲存叢集背後卻是對客戶端介面完全透明的方式並且會執行許多複雜的操作。Ceph客戶端和Ceph OSD都使用CRUSH演演算法(可控的、可擴充套件的、分散式的副本資料放置演演算法),後面的章節會詳細講解CRUSH演演算法。
2.1 儲存池
Ceph儲存叢集透過‘儲存池’這一邏輯劃分的概念對資料物件進行儲存。可以為特定型別的資料建立儲存池,比如塊裝置、物件閘道器,亦或僅僅是為了將一組使用者與另一組使用者分開。
從Ceph客戶端來看,儲存叢集非常簡單。當有Ceph客戶端想讀寫資料時(例如,會呼叫I/O背景關係),客戶端總是會連線到儲存叢集中的一個儲存池上。客戶端指定儲存池名稱、使用者以及金鑰,所以儲存池會充當邏輯劃分的角色,這一角色使得對資料物件訪問進行控制。
實際上,儲存池不只是儲存物件資料的邏輯劃分,它還扮演著Ceph儲存叢集是如何分佈及儲存資料的角色,當然了,這些複雜的操作對客戶端來說也是透明的。Ceph儲存池定義了:
-
儲存池型別:在以前的老版本中,一個儲存池只是簡單的維護物件的多個深複製。而現在,Ceph能夠維護一個物件的多個副本,或者能夠使用糾刪碼。正因為保證資料持久化的2種方法(副本方式與糾刪碼方式)存在差異,所以Ceph 支援儲存池型別。儲存池型別對於客戶端也是透明的。
-
PG:在EB規模的儲存叢集中,一個Ceph儲存池可能會儲存數百萬或更多的資料物件。因為Ceph必須處理資料持久化(副本或糾刪碼資料塊)、清理校驗、複製、重新再平衡以及資料恢復,因此在每個物件基礎上的管理就會出現擴充套件性和效能上的瓶頸。Ceph透過雜湊儲存池到PG的方式來解決這個瓶頸問題。CRUSH則分配每一個物件到指定的PG中,每個PG再到一組OSD中。
-
CRUSH規則集:Ceph中,高可用、持久化能力以及效能是非常重要的。CRUSH演演算法計算用於儲存物件的PG,同時也用於計算出PG的OSD Acting Set
譯者註:acting set即為活躍的osd集合,集合中第一個編號的osd即為主primary OSD。
-
CRUSH也扮演著其他重要角色:即CRUSH可以識別故障域和效能域(例如,儲存介質型別、nodes, racks, rows等等)。CRUSH使得客戶端可以跨故障域(rooms, racks, rows等等)完成資料的寫入以便當節點出現粒度比較大的問題時(例如,rack出問題)叢集仍然可以以降級的狀態提供服務直至叢集狀態恢復。CRUSH也可使客戶端能夠將資料寫入特定型別的硬體中(效能域),例如SSD或具有SSD日誌的硬碟驅動器,亦或具有與資料驅動相同驅動的日誌硬碟驅動器。對於儲存池來說,CRUSH規則集決定了故障域以及效能域。
-
資料持久化方式:在EB規模的儲存叢集中,硬體故障因為可預期所以一般並不算異常。當使用資料物件表示較大粒度的儲存介面時(例如塊裝置),對於這種大粒度儲存介面來說,物件的丟失(不管是1個還是多個)都可能破壞資料的完整性進而導致資料不可用。因此,資料丟失是不可容忍也是不能接受的。Ceph提供了2種持久化方式:第1種為副本儲存池方式,這種方式將多份相同內容的資料物件透過CRUSH進行故障域的隔離來儲存到不同的節點上(比如將物件分別儲存在硬體相互隔離的不同節點上),這樣即使硬體問題也不會對資料的持久化能力產生什麼大的影響;第2種為糾刪碼儲存池方式,這種方式將物件儲存到K+M 個塊中,其中K表示資料塊,M 表示編碼塊。K+M的和表示總的OSD數量,可以支援最多同時有M 個OSD出現問題,資料也不會丟失。
從客戶端角度來看,Ceph對外呈現顯得優雅而簡單。客戶端只需要讀取或寫入資料到儲存池。但是,儲存池在資料持久化,效能以及高可用方面發揮著重要的作用。
2.2 身份認證
為了識別使用者並防止中間人攻擊,Ceph提供了cephx認證系統來驗證使用者和守護行程。
註: Cephx協議並不處理傳輸中的資料加密(例如SSL/TLS)也不處理靜態資料加密。
Cephx使用共享的金鑰進行認證,這也意味著客戶端和mon都會有客戶端金鑰副本。認證協議也就是雙方都能夠向對方證明他們擁有金鑰的副本,而不會實際洩露金鑰。這種方式提供了相互認證的機制,意味著叢集確信使用者擁有金鑰以及使用者確信叢集擁有金鑰的副本。
2.3 PG(s)
Ceph將儲存池分片處理成在叢集中均勻且偽隨機分佈的PG。CRUSH演演算法將每個物件分配到一個指定的PG中,並且將每個PG分配到對應的Acting Set集合中—也就是在Ceph客戶端和儲存物件副本的OSD之間建立一個間接層。 如果Ceph客戶端直接就能知道物件存放到具體的哪個OSD中的話,那麼Ceph客戶端和Ceph OSD之間耦合性就太強了。
相反的,CRUSH演演算法會動態的將物件分配到PG中,然後再將PG分配到一組Ceph的OSD中。有了這個間接層之後,當新Ceph OSD加入或者Ceph OSD出現問題時,Ceph儲存叢集就可以動態的進行資料再平衡。透過在數百到數千個放置組的環境中管理數百萬個物件,Ceph儲存叢集可以高效地增長和收縮以及從故障中恢復。
下麵的圖描述了CRUSH是如何將物件分配到PG中,以及PG分配到OSD中的。
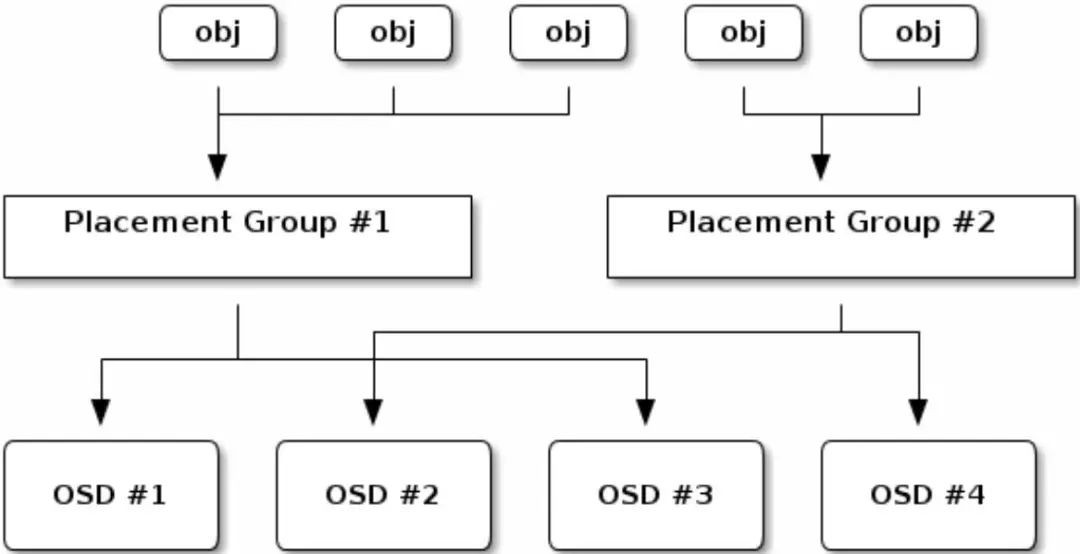
相對整體叢集規模來說,如果儲存池設定的PG較少,那麼在每個PG上Ceph將會儲存大量的資料;如果儲存池設定的PG過大,那麼Ceph OSD將會消耗更多的CPU與記憶體,不管哪一種情況都不會有較好的處理效能。 所以,為每個儲存池設定適當數量的PG,以及分配給叢集中每個OSD的PG數量的上限對Ceph效能至關重要。
譯者註: PG是物件的集合, 在同一個集合裡的物件放置規則都一樣(比如同一集合中的物件統一都儲存到osd.1、osd.5、osd.8這幾臺機器中);同時,一個物件只能屬於一個PG,而一個PG又對應於所放置的OSD串列;另外就是每個OSD上一般會分佈很多個PG。
2.4 CRUSH
Ceph會將CRUSH規則集分配給儲存池。當Ceph客戶端儲存或檢索儲存池中的資料時,Ceph會自動識別CRUSH規則集、以及儲存和檢索資料這一規則中的頂級bucket。當Ceph處理CRUSH規則時,它會識別出包含某個PG的主OSD,這樣就可以使客戶端直接與主OSD進行連線進行資料的讀寫。
為了將PG對映到OSD上,CRUSH 對映關係定義了bucket型別的層級串列(例如在CRUSH對映關係中的types以下部分)。建立bucket層級結構的目的是透過其故障域和(或)效能域(例如驅動器型別、hosts、chassis、racks、pdu、pods、rows、rooms、data centers)來隔離葉子節點。
除了代表OSD的葉子節點之外,層次結構的其餘部分可以是任意的,如果預設型別不符合你的要求,可以根據自己的需要來定義它。 CRUSH支援一個有向無環圖的拓撲結構,它可以用來模擬你的Ceph OSD節點在層級結構中的分佈情況。
因此,可以在單個CRUSH對映關係中支援具有多個Root節點的多個層級結構。例如,可以建立SSD的層級結構、使用SSD日誌的硬碟層級結構等等。
譯者註: CRUSH的目的很明確, 就是一個PG如何與OSD建立起對應的關係。
2.5 I/O操作
Ceph客戶端從Ceph mon獲取‘叢集對映關係Cluster map,然後對儲存池中的物件執行I/O操作。對於Ceph如何將資料存於標的中來說,儲存池的CRUSH規則集和PG數的設定起主要的作用。擁有最新的叢集對映關係,客戶端就會知道叢集中所有的mon和OSD的資訊。但是,客戶端並不知道物件具體的儲存位置(不知道物件具體存在哪個OSD上)。
對於客戶端來說,需要的輸入引數僅僅是物件ID和儲存池名稱。邏輯上也比較簡單:Ceph將資料儲存在指定名稱的儲存池中(例如儲存池名稱為livepool)。當客戶端想要儲存一個物件時(比如物件名叫 “john”、“paul”、”george”、 “ringo”等),客戶端則會以物件名、根據物件名資訊計算的hash碼、儲存池中的PG數、以及儲存池名稱這些資訊作為輸入引數,然後CRUSH(可控的、可擴充套件的、分散式的副本資料放置演演算法)就會計算出PG的ID(PG_ID)及PG對應的主OSD資訊。
譯者註:根據設定的副本數(比如3副本)則計算出的串列如(osd.1、osd.3、osd.8), 這裡的第一個osd.1就是主OSD。
Ceph客戶端經過以下步驟來計算出PG ID資訊。
-
客戶端輸入儲存池ID以及物件ID(例如,儲存池pool=”liverpool”, 物件ID=”john”)。
-
CRUSH獲取物件ID後對其進行HASH編碼。
-
CRUSH根據上一步的HASH編碼與PG總數求模後得到PG的ID。(譯者註:例如HASH編碼後為186,而PG總數為128,則求模得58,所以這個物件會儲存在PG_58中;另外這也可以看出PG數對儲存的影響,因為涉及到物件與PG的對映關係,所以輕易不要調整PG數)
-
CRUSH計算對應PG ID的主OSD。
-
客戶端根據儲存池名稱得到儲存池ID(例如”liverpool”=4)。
-
客戶端將PG ID與儲存池ID拼接(例如 4.58)
-
客戶端直接與Activtin Set集合中的主OSD通訊,來執行物件的IO操作(例如,寫入、讀取、刪除等)。
譯者註: Pool的名稱與ID(ID=4,儲存池名稱為default.rgw.log)。

Ceph儲存叢集的拓撲和狀態在會話(I/O背景關係)期間相對比較穩定。與客戶端在每個讀/寫操作的會話上查詢儲存相比,Ceph客戶端計算物件儲存位置的速度要更快些。CRUSH演演算法不但能使客戶端可以計算出物件應當儲存的位置,同時也使得客戶端可以和Acting Set集合中的主OSD直接互動來實現物件的儲存與檢索。 由於EB規模的儲存叢集一般會有數千個OSD儲存節點,所以客戶端與Ceph OSD之間的網路互動並不是什麼大的問題。即使叢集狀態發生變化,客戶端也可以透過Ceph mon查詢到更新的叢集對映關係。
2.5.1 副本I/O
和Ceph客戶端一樣,Ceph OSD也是透過與Ceph mon互動來獲取到最新的叢集對映關係。Ceph OSD也使用CRUSH演演算法,但是用這個演演算法是用來計算物件的副本應該儲存在什麼位置(譯者註: 客戶端用CRUSH是用來找主OSD以及計算出Acting Set串列,而OSD用CRUSH則是主OSD定位對應的副本是誰)。
在典型的寫操作場景下,Ceph客戶端使用CRUSH演演算法計算物件所在的PG ID以及Acting Set串列中的主OSD,當客戶端將物件寫到主OSD時,主OSD會檢視這個物件應該儲存的副本個數(例如,osd_pool_default_size = n),然後主OSD根據物件ID、儲存池名稱、叢集對映關係這些資訊再根據CRUSH演演算法來計算出Acting Set串列中的從屬OSD(譯者註: 除串列中第一個OSD外,其它的都是從屬OSD)。
主OSD將物件寫入從屬OSD中,當主OSD收到從屬OSD回覆的ACK確認並且主OSD自身也完成了寫操作後,主OSD才會給Ceph客戶端回覆真正寫入成功的ACK確認。

透過有代表性的Ceph客戶端(主OSD)執行資料複製的能力,Ceph OSD守護行程相對的減輕了Ceph客戶端的這一職責,同時確保了資料高可用以及安全性。
註: 比較典型的就是主OSD和從屬OSD在部署時會將故障域進行隔離(比如不同時配置到一個rack上或一個row上,亦或是同一個node上)。CRUSH計算從屬OSD的ID也會考慮故障域資訊。
2.5.2 糾刪碼I/O
糾刪碼實際上是一種前向錯誤糾正編碼,這種編碼會將K個資料塊透過補充N個編碼塊的方式,將原始資料擴充套件為更長的訊息編碼,以便當N個資料塊出現問題時資料依舊不會丟失。隨著時間的推移,開發了不同的糾刪編碼演演算法,其中最早和最常用的演演算法之一是Reed-Solomon演演算法。
可以透過等式 N = K + M 對這一演演算法進行理解,等式中 K 表示資料塊的個數,M 代表了編碼塊的個數,而 N 則是在 糾刪編碼 過程中建立的總的塊的個數。值 M 可以簡化為 N – K ,也就是說在計算原始的K個資料塊時 N – K 個冗餘塊也一併需要計算出來。這種方法保證只要N個塊中的K有效就可以訪問所有原始資料。換句話說,即使有 N – K 個塊出現了故障,對外提供服務的資料仍舊是沒有問題的。
例如配置(N=16,K=10)或者糾刪編碼 10/16,10個基本的塊(K)中會有額外補充的6個塊( M = K-N, 如16-10 = 6 ) 。這16個塊(N)可能對應16個OSD。即使有6個OSD出現問題,原始檔案也可以從這10個已經驗證的資料塊中重建恢復。這就意味著不會有任何的資料丟失,因此糾刪碼也具備比較高的容錯能力。
和副本儲存池類似,糾刪碼儲存池也是由up set串列中的主OSD來接收所有的寫操作。在副本儲存池中,Ceph對PG中的每個物件在從屬OSD上都會有一份一樣的資料物件;而對於糾刪碼儲存池來說,可能略有不同。每個糾刪碼儲存池都會以 K+M 個塊來儲存每一個物件。
物件(的資料內容)會被切分成 K 個資料塊以及 M個編碼塊。糾刪碼儲存池建立時也需要配置成 K+M 的大小(size)以便每個塊都可以儲存到Activtin Set串列中的每個OSD上。物件的屬性儲存這些塊的等級。主OSD負責資料劃分到 K+M 個塊的糾刪編碼以及將這些編碼資訊傳送到其它的OSD上。同時主OSD也會維護PG的權威日誌(譯者註: 權威日誌實際是一種進度控制機制,尤其當某些節點出現問題時,可以根據權威日誌進行資料的恢復)。
例如,使用5個OSD (K + M = 5) 建立糾刪碼儲存池,支援其中2個 (M = 2) 塊的資料丟失。
將物件寫入糾刪碼儲存池中的時候(比如物件名叫 NYAN,內容為 ABCDEFGHI )糾刪碼計算函式會將物件的內容按長度平分成3個塊(即,分成K個資料塊),第一個塊內容為 ABC , 第二個塊內容為DEF , 第三個塊內容為 GHI , 如果塊內長度不是 K 的倍數,那麼平分後最後的一塊所剩餘的空位就會進行填充以使其長度為K(比如內容串為ABCDEFGHIJ,則3個資料塊內容依次為ABCD、EFGH、IJ..,最後的IJ長度不夠就會填充);除了將內容按K切分外, 糾刪碼函式也要建立另外2個編碼塊,即第4個塊內容為 XYZ ,第5個塊內容為 GQC 。
這裡的每一個塊內容都對應Action Set串列中的一個OSD。 這些塊有相同的名稱都叫 NYAN , 但塊存在不同的OSD中。除了名稱之外,資料塊建立的對應序號需要儲存在物件的屬性中( shard_t ) 。 包括 ABC 內容的第一個塊儲存在 OSD5 上,而包括 YXY 內容的第4個塊則儲存在 OSD3 上。

譯者註: 註意上圖中,5個塊的名稱都叫NYAN,每個塊的內容為K個均分的內容, 同時被切分後的每個塊都有一個唯一序號shard, 每個塊都對應不同的OSD,即塊按HOST進行故障域隔離。
譯者註: 比如以下配置及圖例中,K=4, M=2 並且以rack作為故障域)

如果從糾刪碼儲存池中讀取物件 NYAN, 解碼函式需要讀取3個塊: 包括ABC 的第一個塊, 包括GHI 的第3個塊以及包括YXY 的第4個塊;然後重構出物件的內容ABCDEFGHI 。解碼函式來通知第2個塊和第5個塊缺失(一般稱為糾刪或擦寫)。
可在這2個缺失的塊中,第5個塊缺失可能因為OSD4 狀態是OUT而讀不到,只要讀到3個塊可讀的話,解碼函式就可以被呼叫:因為OSD2對應的是最慢的塊,所以讀取時排除掉不在考慮之內。
將資料拆分成不同的塊是獨立於物件放置規則的。CRUSH規則集和糾刪碼儲存池配置決定了塊在OSD上的放置。例如,在配置中如果使用lrc(區域性可修複編碼)外掛來建立額外塊的話,那麼恢復資料的話則需要更少的OSD。
例如lrc配置資訊: K=4、M=2、L=3 中,使用jerasure外掛庫來建立6個塊(K+M),但區域性值(L=3 )則要求需要再建立2個區域性塊。額外建立的區域性塊個數可以透過(K+M)/L 來計算得出。如果0號塊的OSD出現問題,那麼這個塊的資料可以透過塊1,塊2以及第一個區域性塊進行恢復。在這個例子中,恢復也只需要3個塊而不是5個塊。關於CRUSH、糾刪碼配置、以及外掛的內容,可以參考儲存策略指南。
註: 糾刪碼儲存池的物件對映是失效的,不能設定為有效狀態。關於物件對映的更多內容,可以參考物件對映章節。
註: 糾刪碼儲存池目前公支援RADOS閘道器(RGW),對於RADOS的塊裝置(RBD)目前還不支援。
2.6 自管理的內部操作
Ceph叢集也會自動的執行一些自身狀態相關的監控與管理工作。例如,Ceph的OSD可以檢查叢集的健康狀態並將結果上報給後端的Ceph mon;再比如,透過CRUSH演演算法將物件對映到PG上,再將PG對映到具體的OSD上;同時,Ceph OSD也透過CRUSH演演算法對OSD的故障等問題進行自動的資料再平衡以及資料恢復。 以下部分我們將介紹Ceph執行的一些操作。
2.6.1 心跳
Ceph OSD加入到叢集中並且將其狀態上報到Ceph mon。在底層實現上,Ceph OSD的狀態就是up或為down ,這一狀態反映的就是OSD是否執行併為Ceph客戶端的請求提供服務。如果Ceph OSD在叢集中的狀態是donw且為in ,那麼表明此OSD是有問題不能提供服務的;如果Ceph OSD並沒有執行(比如服務crash掉了),那麼這個Ceph OSD也不能上報給Ceph mon其自身狀態為Down 。
Ceph mon會定期的ping 這些OSD以此來確信這些OSD是否仍在執行。當然了,Ceph也提供了更多的機制,比如使Ceph OSD可以評判與之關聯的OSD是否狀態為down(譯者註:比如在副本OSD間相互ping狀態的關係,沒有副本關係的話,OSD之間不會建立連線亦即更不會ping彼此),以及更新Ceph的叢集對映關係並上報給Ceph mon。由於OSD分擔了部分工作,所以對於Ceph mon來說,工作內容相對要輕量很多。
2.6.2 同步
Ceph OSD守護行程執行同步,這裡的同步指的是將儲存放置組(PG)的所有OSD中物件狀態(包括元資料資訊)達到一致的過程。同步問題通常都會自行解決無需人為的幹預。
註: 即使Ceph mon對於OSD儲存PG的狀態達成一致,這也並不意味著PG擁有最新的內容。
當Ceph儲存PG到OSD的acting set串列中的時候,會將它們分別標記為主,從等等。慣例上,Acting set串列中的第一個是主OSD,主OSD也負責協調組內的PG進行同步操作,這裡的主OSD也是唯一 接收客戶端的寫入物件到給定PG請求的OSD。
當一系列的OSD負責一個放置組PG,則這一系列的OSD,我們稱它們為一個Acting Set。Acting Set可能指的是當前負責放置組的Ceph OSD守護行程或者某個有效期內,負責特定放置組的OSD守護行程。
Acting Set中的部分Ceph OSD可能不會一直是up 狀態。當Acting Set中的OSD狀態是up 狀態時,那麼這個OSD也是Up Set中的成員。相對Acting Set來說,Up Set是非常重要的,因為當OSD失敗時,Ceph可以將PG重新對映到其他Ceph OSD上。
註: 對於PG包括osd.25、osd.32、osd.61的Acting Set串列,串列中第一個OSD即osd.25 是主OSD。哪果主OSD失敗,那麼從屬OSD 即osd.32 就會成為新的主OSD,同時原主osd.25 也會從Up Set串列中刪除。
2.6.3 資料再平衡與恢復
當我們向Ceph儲存叢集中新增加Ceph OSD的時候,叢集對映關係隨著新增加的OSD同時也會更新。因此,由於這一變化改變了計算CRUSH時提供的輸入引數,所以也就間接的改變了物件的放置位置。CRUSH演演算法是偽隨機的,但會均勻的放置資料。所以叢集中新增加一臺OSD時,也只會有一小部分的資料發生遷移。一般遷移的資料量是叢集總資料量與OSD數量的比值(例如,在有50個OSD的叢集中,當新增加一臺OSD時也只有1/50 或者2%的資料受到遷移影響)。
下麵的圖示描述了部分的PG(非全部PG)從已有的OSD 1,OSD 2上遷移到新OSD 3上達到資料再平衡的過程(因為對大型叢集的影響要小得多,所以過程相對粗略一些)。 即使在再平衡過程中,CRUSH也是穩定的。大部分的PG仍然保留著原始的配置,由於新增加了OSD,所以每個OSD都會增加一些(可用的)容量,因此在重新平衡完成後,新的OSD上也不會出現負載峰值的情況。

2.6.4 校驗(或擦除)
作為Ceph中維護資料一致性以及整潔性的部分,Ceph OSD 守護行程也可以完成PG內的物件清理工作,意思就是Ceph OSD守護行程比較副本間PG內的物件元資料資訊。校驗/擦除(通常是天級別的排程策略)捕獲異常或檔案系統的一些錯誤。同時,Ceph OSD守護行程也可以進行更深層次的比較(物件資料本身的按位比較),而這種深層次的比較(可以發現驅動盤上壞的扇區)一般是周級別的排程策略。
2.7 高可用
除了透過CRUSH演演算法實現高可擴充套件性外,Ceph也需要支援高可用性。這就意味著即使叢集處於降級狀態或某個Ceph mon出現問題情況下(譯者註:這裡出問題的mon個數不能超過mon總數的一半,否則叢集會阻塞所有操作),客戶端仍舊可以進行資料的讀寫。
2.7.1 資料副本
在副本儲存池中,Ceph需要物件的多個副本在降級狀態下執行。理想情況下,即使Acting Set中的一個OSD出現問題,Ceph儲存叢集也可以支援客戶端讀寫操作。基於此,Ceph預設也是一個物件保持3副本的設定,寫操作則要求至少2個副本為clean狀態(譯者註: 具體設定多少個副本為clena才支援寫操作,這要依賴於設定儲存池時的配置,例如,在ceph osd dump | grep pool輸出中的replicated size 3 min_size 2,這裡的2就是至少有多少個副本為clean,在這個儲存池上的寫操作才被支援,而這個值是可以再更新的)。
如果有2個OSD出現問題,Ceph仍然可以保留資料不會丟失,但是就不能進行寫操作了。
在糾刪碼儲存池中,Ceph需要多個OSD來儲存物件分割後的塊以便在降級狀態仍然可以操作。與副本儲存池類似,理想情況下,在降級狀態下糾刪碼儲存池也支援Ceph客戶端進行讀寫操作。基於此,我們則建議設定K+M=5 透過5個OSD來儲存塊資訊,同時設定M=2 以保證即使2個OSD出現問題也可以根據剩餘的OSD進行資料的恢復重建。
2.7.2 Mon叢集
在客戶端進行資料讀寫之前,客戶端必須從Ceph mon端獲取最新的叢集對映關係。一個Ceph儲存叢集可以與一臺mon進行通訊發起操作,然而這就存在單點問題(例如這個單點的mon出現問題,Ceph客戶端則不能進行資料的讀寫)。
為了提供服務的可靠性以及容錯性,Ceph支援mon組成叢集方式提供服務。在mon叢集中,延遲和其他的故障可能導致一個或多個mon落後於叢集當前的狀態。基於此,Ceph必須在叢集狀態的各種mon實體之間達成一致。對於叢集當前的狀態,Ceph也總是使用大多數的mon(例如: 1、2:3、3:5、4:6等等)或者Paxos演演算法進行一致性確認。同時,mon叢集內機器間也需要NTP時間服務防止時鐘漂移。
2.7.3 CephX
Cephx 認證協議的操作方式與Kerberos類似。使用者、角色呼叫Ceph客戶端來與mon互動,不像Kerberos,每一個monitor都可以對使用者進行認證並分發金鑰,所以使用cephx 不存在單點問題或瓶頸。mon傳回類似於Kerberos的包含會話金鑰資訊的結構以便呼叫方可以根據金鑰對接Ceph的所提供的服務。這裡的會話金鑰本身使用了使用者的永久金鑰進行加密,因此只有使用者自已才可以從Ceph mon請求服務。
客戶端使用會話金鑰從monitor處獲取想要的服務,mon則透過認證使得客戶端有許可權對接OSD來完成資料互動。Ceph mon和OSD共享一個秘鑰,因此客戶端可以使用mon提供的憑證與群集中的任何OSD或元資料伺服器進行互動。和Kerberos類似,cephx 憑證也有超時時間,所以並不能使用一個超時的憑證偷偷的對叢集進行攻擊。只要使用者的金鑰在到期前不洩露的話,這種身份認證的形式可以防止攻擊者以其他使用者的身份建立偽造訊息或更改其他使用者的合法訊息訪問通訊介質。
如果使用Cephx 認證,管理員必須先設定使用者。在下麵的圖示中,client.admin 使用者透過命令列執行ceph auth get-or-create-key 命令,建立使用者以及金鑰。Ceph的auth 子系統生成使用者名稱以及金鑰,並將其存於mon中以及將使用者名稱與金鑰傳回給呼叫命令的client.admin 使用者。 這也就意味著客戶端與mon共享同一個金鑰。
註: client.admin 使用者必須以安全的方式向用戶提供使用者ID和金鑰。

第3章 客戶端架構
Ceph客戶端在資料儲存的介面方面還是存在比較大的差異的。Ceph的塊裝置提供了可以像掛載本地物理驅動盤一樣的塊儲存,而Ceph物件閘道器則透過使用者的管理提供了相容S3與Swift的Restful物件儲存介面。而對於這些介面,都是使用的RADOS(可靠且自動分散式的物件儲存)協議與Ceph儲存叢集進行的互動;同時這些介面也都有一些相同的基本前提:
-
Ceph配置檔案,或叢集名稱(通常為ceph )與mon地址
-
儲存池名稱
-
使用者名稱以及金鑰的路徑
Ceph客戶傾向於遵循一些類似的樣式,例如物件的監視-通知以及條帶化。下麵大概介紹下Ceph客戶端裡使用的RADOS,librados以及常見的樣式。
3.1 本地協議與Librados
現代的應用需要有非同步通訊能力簡單的物件儲存介面,Ceph儲存叢集就有這個能力並提供簡單的介面。此介面提供了對叢集直接、並行的物件存取。
-
儲存池操作
-
快照
-
讀、寫物件
– 建立或刪除
– 整個物件或位元組範圍
– 追加或截斷 -
建立/設定/獲取/刪除 XATTRs
-
建立/設定/獲取/刪除 K/V對
-
複合操作和雙重ack語意
3.2 物件的監視與通知
Ceph客戶端可以為物件註冊持久的關註點,並保持與主OSD的會話開啟。客戶端可以向所有觀察者傳送通知訊息和資料,併在觀察者收到通知時接收通知。這使得客戶端可以使用任何物件作為同步/通訊的通道。

3.3 獨佔鎖
獨佔鎖提供一種功能特性:任一客戶端可以對RBD中資源進行’排它的’鎖定(如果有多個終端對同一RBD資源進行操作時)。這有助於解決當有多個客戶端嘗試寫入同一物件時發生衝突的場景。此功能基於前一節中介紹的物件的監視與通知。因此,在寫入時,如果一個客戶端首先在物件上建立獨佔鎖,那麼其它的客戶端如果想寫入資料的話就需要在寫入前先檢查是否在物件上已經放置了獨佔鎖。
設定了這一特性的話,同一時刻只有一個客戶端能夠對RBD資源進行修改,尤其像快照建立與刪除這種改變RBD內部結構的時候。這一特性對於失敗的客戶端也起到了一些保護的作用,例如,虛擬機器沒有響應了,然後在其他地方使用同一塊磁碟啟動它的副本,那麼這個無響應的虛擬機器將在Ceph中被列入黑名單,並且無法破壞新的虛擬機器中資料。
強制的獨佔鎖功能特性預設是不開啟的,但是可以在建立鏡象時顯示的透過加入–image-features引數來開啟這一特性,例如:
rbd -p mypool create myimage –size 102400 –image-features 5
這裡的5是1與4的和值, 其中1使得分層特性生效,4使得獨佔鎖特性生效。所以執行上面這個命令後會建立100GB的RBD鏡象,同時既支援分層特性也支援獨佔鎖特性。
強制的獨佔鎖也是後面提到的物件索引對映使用的前提。如果沒有開啟強制的獨佔鎖,那麼物件索引對映也不會生效。
獨佔鎖也為mirror這塊內容做了不少的工作。
3.4 物件對映索引
物件對映索引也是一種功能特性,可以在客戶端寫入rbd映像時跟蹤RADOS物件是否已經存在了。當有寫入操作時,寫操作被轉義為RADOS物件中的偏移,如果物件對映索引功能開啟那麼對於存在的RADOS物件就會被跟蹤到。所以當物件已經存在時我們就可以提前知道。物件對映索引儲存在librbd客戶端機器記憶體中,所以對於不存在的物件就省去了再去查詢OSD的這一步開銷。物件對映索引對於一些操作還是比較有利的,即:
-
調整大小
-
匯出操作
-
複製操作
-
扁平化
-
刪除
-
讀取
縮小操作就像是對尾部物件的部分刪除。匯出操作知道哪些物件被RADOS請求。複製操作知道哪些物件存在並需要複製。它不需要遍歷潛在的數百或數千個可能的物件。扁平化操作將所有父物件複製到克隆中,以便可以將克隆與父項分離,即可以刪除從子克隆到父快照的取用。因此,不是對所有潛在的物件,僅是對存在的物件進行複製。
刪除操作僅刪除鏡象中存在的物件。讀取操作對於不存在的物件會直接跳過。因此,對於調整大小(僅縮小)、匯出操作、複製操作、扁平化和刪除等操作,這些操作需要針對所有可能受到影響的RADOS物件(無論它們是否存在)釋出操作。如果啟用物件對映索引特性的話,物件若不存在就不需要釋出操作了。
例如,我們有一個RBD鏡象,有1TB的資料且比較稀疏,可能擁有數百或數千個RADOS物件。如果不開啟物件對映索引的話,執行刪除操作則需要對每一個潛在的標的物件釋出刪除物件操作;但是如果開啟了這一特性,那麼只需要對真正存在的物件釋出一個刪除物件的操作就可以了。
物件對映索引對於克隆是比較有價值的(自身沒有實際物件但可以從父物件那獲取)。當有一個克隆的鏡象時,克隆初始並沒有什麼物件,所有對克隆物件的讀操作都會重定向到父物件中。開啟物件對映索引可以改善讀操作,首先對於克隆物件向OSD釋出讀操作,如果讀失敗了,那麼再向克隆物件的父物件釋出讀操作。讀操作會直接忽略掉根本不存在的物件。
物件對映索引預設是不開啟的,但是可以在建立鏡象時顯示的透過加入–image-features引數來開啟這一特性。同時獨佔鎖 也是物件對映索引功能特性的使用前提。如果不開啟獨佔鎖功能特性則物件對映索引也不會生效。建立鏡象時如果開啟物件對映索引,可以執行:
rbd -p mypool create myimage –size 102400 –image-features 13
這裡的13是1、4、8的和值, 其中1 使得分層特性生效,4 使得獨佔鎖特性生效,8 使得物件對映索引特性生效。所以執行上面這個命令後會建立100GB的RBD鏡象,同時既支援分層特性也支援獨佔鎖特性和物件對映索引特性。
3.5 資料條帶化
儲存裝置一般在吞吐量上都有限制,這就會影響到服務的效能和伸縮性。因此,儲存系統一般會提供條帶化方案來提高效能與吞吐能力(即,將有序的資訊分割成多個區段後儲存到多個裝置上)。關於條帶化最常見的就是RAID(譯者註: 磁碟陣列RAID,意為將多個磁碟組合成一個容量更大的磁碟組,利用單塊盤儲存的疊加效果來提升整個磁碟儲存冗餘能力。採用這種方案後,將儲存的資料切割成許多個區段資料,然後分別存放在各個硬碟上)。與Ceph中條帶化最相似的RAID型別就是RAID 0或’條帶化捲’。Ceph的條帶化提供了RAID 0級的吞吐能力以及n路RAID映象的可靠性和快速的資料恢復能力。
Ceph提供3種客戶端對接型別: Ceph塊裝置(CephRBD)、Ceph檔案系統(CephFS)、Ceph物件儲存(一般是Ceph RGW)。資料儲存方面,Ceph客戶端會將使用者提交的資料轉換為Ceph儲存叢集內部的格式儲存到叢集中,在提供給使用者的介面上也是按照這3種型別完成的:塊裝置映象、物件儲存的RESTful介面、以及CephFS系統目錄。
提示: 儲存在Ceph儲存叢集中的物件自身並沒有條帶化。 Ceph物件儲存,Ceph塊裝置和Ceph檔案系統將客戶端資料條帶化後儲存在Ceph叢集內的多個物件中。如果想充分發揮並行能力,使用librados庫直接將資料寫入到Ceph儲存叢集的Ceph客戶端必須執行條帶化(以及並行I/O)。
最簡單的Ceph條帶化格式即為條帶數量為1的單個物件。 Ceph客戶端將條帶單元塊寫入到Ceph儲存叢集物件中,直到物件達到其最大容量,然後再為額外的條帶化資料建立另一個物件。對於較小的塊裝置映象、S3或Swift物件來說,這種簡單的條帶化方式可能就完全能夠滿足需求,然而,這種簡單的形式並沒有最大限度的利用Ceph在整個放置組中分佈資料的能力,因此並不能有較大的效能提升。下麵圖示描述了這種最簡單的條帶化方式:

譯者註: 例如每一個物件儲存上限是4M,同時每一個單元塊佔1M,這時我們有一個8M大小的檔案想進行儲存,這樣前4M儲存在物件0中,後4M就建立另一個物件1來儲存。
如果可以預知儲存需求為較大的影象,或較大的S3物件或Swift物件(例如影片),若想有較大的讀寫效能提升,則可以透過將客戶端資料條帶化分割儲存到多個物件上。如果客戶端將條帶單元塊並行的寫入到對應物件中,由於物件對映到不同的PG上進而會對映到不同的OSD上,每個寫操作都以最大化速並行進行,那麼寫效能的提升是相當明顯的。
如果完全只對一塊磁碟寫入操作的話,受限就比較多: 磁頭的移動(例如每次6ms的定址時間開銷)、裝置的頻寬(例如每秒最大100MB)。透過擴充套件多個物件上的寫入(對映到不同的PG以及OSD上),Ceph不但可以降低每個驅動盤的定址時間,同時也可以合併多個驅動盤的吞吐能力以獲取更快的讀寫速度。
註: 條帶化獨立於物件的副本。由於CRUSH跨OSD複製物件,所以條帶化也會自動完成複製。
在下麵的圖示中,客戶端跨越物件集(物件集 1)來獲取條帶資料。物件集中由4個物件組成,第1個條帶單元塊是儲存在object 0中的stripe unit 0,第4個條帶單元塊是儲存在 object 3中的stripe unit 3。當寫完第4個單無塊時,客戶端會判斷物件集是否已滿,如果沒有滿的話,客戶端繼續將條帶單元塊寫入第1個物件中(下圖中的object 0)。如果物件集已滿,那麼客戶端就會建立一個新的物件集(下圖中的對像集 2),然後將第1個條帶單元塊(stripe unit 16)寫入到新物件集中的第1個物件中(下圖中的object 4)。

Ceph資料條帶化過程中,有3個比較重要的引數會對條帶化產生影響:
-
物件大小:Ceph儲存叢集中可以配置物件大小的上限值(比如2M、4M等),物件大小也應該足夠的大以便與條帶單元塊相適應,同時設定物件的大小也應該是單元塊大小的倍數。Red Hat則建議物件大小比較合理的值是16MB。
-
條頻寬度:條帶化中的單元塊大小也是可配置的(例如64kb)。Ceph客戶端將寫入物件的資料劃分為相同大小的條帶單元塊(因為寫入的資料不一定是單元塊的倍數,所以最後剩餘的一個單元塊可能大小與其它的不一樣)。條頻寬度應該是物件大小的一個分數(比如物件是4M,單元塊是1M,則一個物件能包含4個單元塊),以便物件可以包含更多條帶單元塊。(譯者註:條頻寬度也是指同時可以併發讀或寫的條帶數量。一般這個數量等於RAID中的物理硬碟數量)
-
條帶數量:根據條帶數量,Ceph客戶端將一批條帶單元塊寫入到一系列物件中。這裡的一系列物件也就是物件集。在Ceph客戶端寫入物件集中最後一個物件之後會傳回到物件集中的第1個物件。
重要提示: 在服務上線生產環境前,最好對條帶化進行效能上的測試,因為一旦資料寫入,就無法再更改條帶引數資訊了。
一旦Ceph客戶端將條帶化資料對映到條帶單元塊上,進而對映到物件上,在物件最終以檔案形式儲存在磁碟上之前,Ceph的CRUSH演演算法會將物件對映到PG中,然後再將PG對映到OSD守護行程中。
註: 由於客戶端寫入單個儲存池中,因此條帶化到物件中的所有資料都會對映到同一個儲存池的PG內。所以也會使用相同的CRUSH對映關係以及相同的訪問控制策略。
譯者註: 在Ceph儲存中,涉及條帶化的主要是Order、stripe_unit和stripe_count這3個引數。由這3個引數確定了資料的寫入與儲存編排方式。預設情況order是22,也即物件大小為4MB(2的22次方),strip_unit大小與物件大小一致(也是4M),strip_count為1(物件集中只有1個物件)。
第4章 加密相關
LUKS磁碟加密及帶來的好處: 在Linux系統中,可以使用LUKS方法對磁碟分割槽進行加密,由於LUKS是對整個塊裝置進行加密,所以對於行動式儲存能夠起到較好的資料保護作用。
可以使用Ceph-ansible工具建立加密的OSD儲存節點,這樣可以對OSD上儲存的資料進行保護。更詳細的內容可以參考
如何使用ceph-ansible建立加密的磁碟分割槽: 在OSD安裝過程中,ceph-ansible會呼叫ceph-disk工具來完成建立加密分割槽的工作。
除了資料和日誌分割槽外(Ceph data和ceph journal),ceph-disk 工具也會建立一個小的密碼箱分割槽以及名稱為cephx client.osd-lockbox 的使用者。ceph密碼箱分割槽包含一個金鑰檔案,client.osd-lockbox 使用者使用這個金鑰檔案獲取LUKS私鑰,從而對ceph data和ceph journal分割槽進行解密。
之後,Ceph-disk會再呼叫cryptsetup 工具為ceph data和ceph journal分割槽建立2個dm-crypt裝置。其中dm-crypt裝置使用ceph data和ceph journal的GUID作為標識。
Ceph-ansible如何處理LUKS金鑰: Ceph-ansible工具將LUKS私鑰儲存在Ceph monitor監視器的K/V儲存中。每個OSD都有自己的金鑰將儲存在dm-crypt裝置上加密的OSD資料和日誌進行解密。加密分割槽在服務啟動時就自動的進行瞭解密操作。
掃描二維碼閱讀原文

溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取電子書詳情。

求知若渴, 虛心若愚

