來源:haolujun
https://www.cnblogs.com/haolujun/p/9527776.html
前言
我最近一直在公司做檢索效能最佳化。當我看到這個演演算法之前,我也不認為我負責的檢索系統效能還有改進的餘地。但是這個演演算法確實太牛掰了,足足讓服務效能提高50%,我不得不和大家分享一下。其實前一段時間的部落格中也寫到過這個演演算法,只是沒有細講,今天我準備把它單獨拎出來,說道說道。說實話,本人數學功底一般,演演算法證明不是我強項,所以文中的證明只是我在論文作者的基礎上加入了自己的思考方法,並且還沒有完全證明出來,請大家見諒 ! 歡迎愛思考的小夥伴進行補充。我只要達到拋磚引玉的作用,就知足了。
回歸正題,我們的檢索服務中用到了最小編輯距離演演算法,這個演演算法本身是平方量級的時間複雜度,並且很少人在帖子中提到小於這個複雜度的演演算法。但是我無意中發現了另外一個更牛的演演算法:列劃分演演算法,使得這個本就很牛的演演算法效能直接提高一倍。接下來進入正題。
列劃分演演算法
這個演演算法比較難理解,出自如下論文:《Theoretical and empirical comparisons of approximate string matching algorithms》。In Proceedings of the 3rd Annual Symposium on Combinatorial Pattern Matching, number 664 in Lecture Notes in Computer Science, pages 175~184. Springer-Verlag, 1992。Author:WI Chang ,J Lampe。所以有必要先給大家普及一些共識。
編輯矩陣 最小編輯距離在計算過程中使用動態規劃演演算法計算的那個矩陣,瞭解這個演演算法的都懂,我不贅述。但是我們的編輯矩陣有個特點:第一行都是0,這麼做的好處是:只要文字串T中的任意一個子序列與樣式串P的編輯距離小於某個固定的數值,就會被髮現。
給大夥一個樣例,文字串T=annealing,樣式串P=annual:

註意,第一行都是0,這是與傳統最小編輯距離的最大區別,其餘的動歸方程完全相同。
對角線法則 編輯矩陣沿著右下方對角線方向數值非遞減,並且至多相差1。
行列法則 每行每列相鄰兩個數至多相差1。
觀察編輯距離矩陣,我們發現如下事實:每一列是由若干段連續數字組成。所以我們把編輯矩陣的每一列劃分成若干連續序列,如下圖所示:

紅色框中就是一個一個的序列,序列內部連續。
序列-δ 定義 對於編輯矩陣的每一個元素D[j][i] (j是行,i是列),若 j – D[j][i] = δ,我們就說D[j][i]屬於i列上的 序列-δ,我們還觀察到隨著j增大,j – D[j][i]是非遞減的。如下圖所示:

序列-δ終止位置 每個序列都會有起始和終止位置。序列-δ的終止位置為j,如果j是序列-δ的最小橫坐標,並且滿足D[j+1][i]屬於序列-ε,並且ε>δ(即j+1-D[j+1][i]>δ)。
長度為0的序列 我們發現如果按照如上定義,每一列上δ的值並不一定連續,總是或有或無的缺少一個數值。所以我們定義長度為0的序列:當D[j+1][i] < D[j][i]時,我們就在序列-δ和序列-(δ+2)之間人為插入一個長度為0的序列-(δ+1)。如下圖所示:

所以,我們按照這個定義,就可以對編輯矩陣的每列進行一個劃分,劃分的每一段都是一串連續數字。
說了這麼多,這個定義有什麼用呢?假若,我們每次都能根據前一列的列劃分情況直接推匯出後一列的列劃分情況,那麼就可以省去好多計算,畢竟每一個劃分中的每一段的數字都是連續的,這就暗示我們可以直接用一個常數時間的加法直接得到某一個編輯矩陣的元素值,而不用使用最小編輯距離的動態規劃演演算法去計算。
接下來的重點來了,我們介紹這個推導公式,請打起十二分精神!我們按照序列-δ長度是否為0來介紹這個推論。由於其中一個推論文字描述太繁瑣,不容易理解,所以我畫了個圖: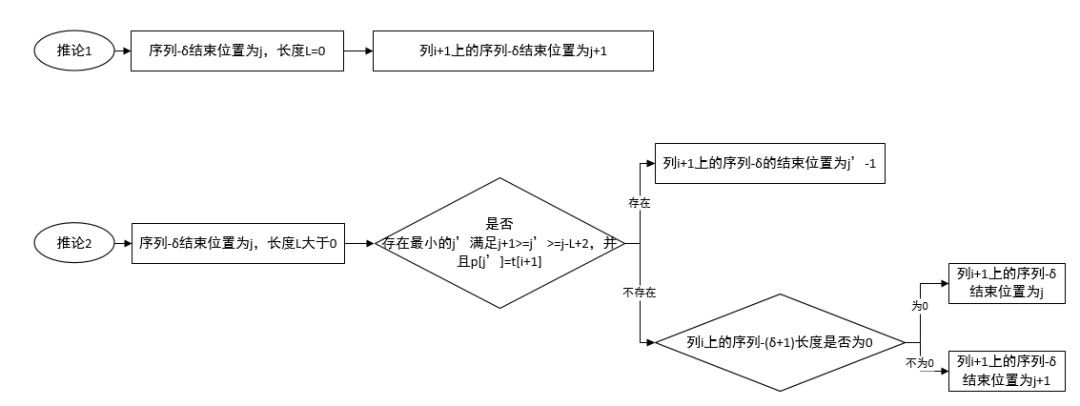
接下來燒腦開始。
推論1:如果列i上長度為0的 序列-δ 的結束位置為j,則列i+1上的 序列-δ 的結束位置為 j+1。
證明 :由推論前提我們知道 δ = j – D[j][i] + 1 (想想前面說的δ值不連續,我們就人為插入一個中間值,只不過長度為0)。
我們觀察編輯矩陣就會發現如下兩個事實:
-
事實1:D[j+1][i+1] = D[j][i] ( 別問為什麼, 自己觀察, 看看是不是都這樣, 其實可以用反證法,我們就不證明瞭)。
-
事實2:D[j+2][i+1] <= D[j][i]。
透過事實1,我們知道D[j+1][i+1]確實屬於 序列-δ,因為 j + 1 – D[j+1][i+1] = j + 1 – D[j][i] = δ。
透過事實2,我們知道列i+1上的序列δ,終止位置為j+1。
所以推論1證明結束。
推論2: 文字描述略,請看圖
證明 :
-
設這個序列長度為L,除了每列的第一個序列外,其餘序列的其餘位置均是當前的編輯距離小於等於該列上一個位置的編輯距離:即D[j-L+1][i]<=D[j-L][i],所以,我們可以推出:D[j-L+1][i] <= D[j-L][i];
-
再根據編輯矩陣對角線非遞減我們知道,D[j-L+1][i+1] >= D[j-L][i];
綜上兩點我們得到如下大小關係:D[j-L+1][i+1] >= D[j-L+1][i]。
此外我們知道我們當前列的序列-δ截止位置為j,也意味著D[j+1][i] <= D[j][i],同樣根據對角線法則,我們得出D[j+2][i+1] <= D[j+1][i] + 1 <= D[j][i] + 1。
接下來到了最精彩的一步,我們知道列i當前序列-δ內的值是連續的,如果起始編輯距離為A,那麼終止編輯距離為A+L-1。
而由我們的推導可以發現:D[j-L+1][i+1] >= A,D[j+2][i+1] <= (A+L-1) + 1 = A+L,而之間跨越的長度為 (j+2)-(j-L+1)+1= L+2。 我們可以推出列i+1上從行j-L+1到行j+2之間的序列一定不連續,否則D[j+2][i+1] >= A+L+2-1= A+L+1,與我們先前的推導矛盾。所以,在j-L+1和j+2之間一定有一個列終止,這樣才能消去一個序號。
此外我們還有一個疑問,列i+1上的序列-δ結束位置一定在j-L+1和j+1之間麼?我們要證明這個事。
證明 :
因為δ=j-D[j][i]=j-L+1-D[j-L+1][i]>=j-L+1-D[j-L+1][i+1],即列i+1上的 序列-δ的結束位置一定在j-L+1或者之後;
由於j+1-D[j+1][i]>δ,根據對角線法則D[j+2][i+1] <= D[j+1][i]+1,有j+2-D[j+2][i+1]>=j+2-(D[j+1][i]+1)=j+1-D[j+1][i] > δ, 固列i+1上的序列-δ的終止位置一定在j+2之前,即j-L+1到j+1之間。
後面推論2的分情況討論,我一個也沒證明出來,作者在論文中輕飄飄的一句話“後面很好證明,他就不去證明瞭”,但是卻消耗了我所有腦細胞。所以,如果哪位小夥伴把推論2剩下的內容證明出來了,歡迎給我留言,我也學習學習。
這個演演算法的時間複雜度是多少呢?作者用啟髮式的方法證明瞭演演算法的複雜度約為$ O(mn/sqrt[2]{b}) $,其中b是字符集大小。
程式碼實現
接下來說一下程式碼實現,給出我總結出來的步驟,否則很容易踩坑。
-
編輯矩陣第一列,肯定只有一個序列。
-
每次遍歷前一列的所有序列,根據推論1和推論2計算後一列的劃分情況。
-
如果前一列遍歷完畢,但是下一列還有剩餘的元素沒有劃分。沒關係,下一列剩下的元素都歸為一個新的序列。
-
預處理一個表,表中記錄T中的每個字元在P中的位置。可以直接用雜湊演演算法(最好直接ascii碼)進行定位,如果位置不唯一,可以拉鏈。進行列劃分計算時,從前往後遍歷那一鏈上的位置,直到找到第一個符合條件的,速度出奇的快。盡可能少使用或者不要使用map進行定位,測試發現相當慢。
接下來做最不願意做的事:貼一個程式碼,很醜。
inline int loc(int find[][200], int *len, int ch, int pos) {
for(int i = 0; i if(find[ch][i] >= pos) return find[ch][i];
}
return -1;
}
int new_column_partition(char *p, char *t) {
int len_p = strlen(p);
int len_t = strlen(t);
int find[26][200];
int len[26] = {0};
int part[200]; //記錄每一個序列的結束位置
//生成loc表,用來快速查詢
for(int i = 0; i find[p[i] - 'a'][len[p[i] - 'a']++] = i + 1;
}
int pre_cn = 0, next_cn = 1, min_v = len_p;
part[0] = len_p;
for(int i = 0; i //前一列partition數
pre_cn = next_cn;
next_cn = 0;
int l = part[0] + 1;
int b = 1;
int e = l;
int tmp;
int tmp_value = 0;
int pre_v = part[0];
//前一列第0個partition長度肯定>=1
if(len[t[i] - 'a'] >0 && (tmp = loc(find, len, t[i] - 'a', b)) != -1 && tmp <= e) {
part[next_cn++] = tmp - 1;
} else if(pre_cn >= 2 && part[1] - part[0] != 0){
part[next_cn++] = part[0] + 1;
} else {
part[next_cn++] = part[0];
}
//每列第一個partition尾值
tmp_value = part[0];
//遍歷前一列剩下的partition
for(int j = 1; j part[next_cn - 1] int x = part[j], y = pre_v;
pre_v = part[j];
l = x - y;
if(l == 0) {
part[next_cn++] = x + 1;
} else {
b = x - l + 2;
e = x + 1;
if(b <= len_p && len[t[i] - 'a'] > 0 && (tmp = loc(find, len, t[i] - 'a', b)) != -1 && tmp <= e) {
part[next_cn++] = tmp - 1;
} else if(j + 1 part[j + 1] - x != 0) {
part[next_cn++] = x + 1;
} else {
part[next_cn++] = x;
}
}
l = part[j] - part[j - 1];
if(l == 0) {
//新得到的partition長度為0,那麼下一個partition的起始值比上一個partition尾值少1
tmp_value -= 1;
} else {
tmp_value += l - 1;
}
}
if(part[next_cn - 1] != len_p) {
part[next_cn++] = len_p;
tmp_value += len_p - part[next_cn - 2] - 1;
if(tmp_value min_v = tmp_value;
}
} else {
min_v = min_v }
}
return min_v;
}結語
這個演演算法應用到線上之後,效果非常明顯,如下對比。
-
最佳化前CPU:

-
最佳化後CPU:

能力有限,證明不充分,有興趣的小夥伴可以直接去看原版論文,歡迎交流,共同進步。
●編號597,輸入編號直達本文
●輸入m獲取文章目錄

演演算法與資料結構
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
