

在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @hawksilent。本文是曼徹斯特大學發表於 ACL 2018 的工作,文章提出了一種新的基於圖的神經網路關係抽取模型。
文章在沒有使用任何外部工具的情況下,在 ACE 2005 資料集上對模型進行了測試,並將結果與 SPTree 系統進行了對比。實驗結果顯示,這篇文章提出的模型與當前最先進的 SPTree 系統相比,兩者的效能沒有明顯的統計學差異。
如果你對本文工作感興趣,點選底部閱讀原文即可檢視原論文。
關於作者:盧靖宇,西安電子科技大學碩士,研究方向為自然語言處理。
■ 論文 | A Walk-based Model on Entity Graphs for Relation Extraction
■ 連結 | https://www.paperweekly.site/papers/2289
■ 作者 | Fenia Christopoulou / Makoto Miwa / Sophia Ananiadou
引言
當一句話中存在多種關係時,不同關係之間往往會存在一定的聯絡,即標的物體對的關係可能會受到同一個句子中其他物體間關係的影響。例如,如下圖中虛線所示:“Toefting”既可以透過介詞“in”以直接的方式與 “capital”建立關係,也可以透過“teammates”以間接的方式與“capital”建立關係。

因此,在進行關係抽取(RE)時需要同時考慮這些關聯關係,藉此來對物體之間的依賴關係建模。然而,現有的大多數 RE 模型在抽取關係時往往會忽略不同關係間的這種關聯性。
針對這一情況,這篇文章提出了一種基於物體圖的神經關係抽取模型,該模型用圖的方式來表達一句話中多個物體間存在的多種關係。句子中的物體被表示為圖中的節點,物體間的關係則構成圖的定向邊,模型用一個物體及其背景關係來初始化一條邊,這樣,任意兩個物體之間就會形成由多個邊連線組成的、長度不等的多條路徑。模型透過迭代的方式,將兩個物體之間多條路徑逐漸聚合為一條直連路徑,該直連路徑即對應於物體關係的最終表示。
本文的創新點和貢獻主要有以下三個方面:
1. 提出一種基於路徑的神經圖模型,能夠處理一句話中存在多種物體及多個關係的關係抽取任務;
2. 提出一種迭代演演算法,可以將兩個物體之間多個不同長度的路徑融合為一條直連路徑;
3. 透過實驗證實,文章提出的模型在不使用任何外部句法工具的情況下,即可達到與當前最先進演演算法相近的效能。
模型
文章提出的模型由 5 層組成,如下圖所示:嵌入層(embedding layer),BLSTM 層(BLSTM Layer),邊表示層(edge representation layer),路徑融合層(walk aggregation layer),分類層(classification layer)。

模型的輸入為句子中單詞的詞嵌入,利用這些詞嵌入生成物體對的向量表達形式。物體對的表示向量包含以下資訊:標的物體對、標的物體對的背景關係單詞、背景關係單詞與物體對的相對位置以及物體對之間的路徑。在分類器中,這些表示向量將被用於預測物體對的關係型別。
嵌入層
負責生成維度分別為 nw、nt、np 向量,分別對應於單詞、物體的語意型別、標的物體對的相對位置。單詞和語意型別分別對映為實值向量 w 和 t。標的物體對的相對位置由句子中單詞的位置來決定。以第 1 節中的例子為例,“teammates”與“capital”的相對位置為 -3,“teammates”與“Toefting”的相對位置為 +16。文章利用實值向量 p 表示這些相對位置。
BLSTM層
每個句子的詞嵌入將輸入倒一個雙向長短期記憶網路(BLSTM)中,BLSTM 輸出一個新的詞嵌入 h,該詞嵌入考慮了單詞的序列資訊。對於句子中的每一個單詞 t,其在 BLSTM 中前向網路和反向網路的輸出將被連線成一個 ne 維向量,即 。
。
邊表示層
BLSTM 輸出的詞嵌入在這一層將被進一步分為兩個部分:標的物體對的表示向量以及標的物體對特定背景關係的表示向量。
標的物體對的背景關係可以用句子中除已知物體外的其餘全部單詞來表示。物體對的具體表示方法如下:
一個標的物體對包含兩個物體 ei 和 ej。如果一個物體由 I 個單片語成,則求這 I 個單詞的 BLSTM 向量的平均值,用該平均值作為物體的 BLSTM 向量,即 ,其中 I 表示組成物體 e 的單詞的數量。
,其中 I 表示組成物體 e 的單詞的數量。
首先,為每對物體建立一個表示向量,然後構造每個物體對的背景關係的表示向量。物體 ei 的表示向量由以下幾部分連線而成:物體的 BLSTM 向量 ei,物體型別的表示向量 ti,以及物體 ei 與 ej 相對位置的表示向量 pij。類似的,對於物體 ej 用 pji 表示其與物體 ei 的相對位置。最終,物體對可以表示為: 和
和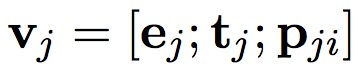 。
。
然後,構建上述物體對背景關係的表示向量。對於標的物體對 (ei,ej) 背景關係的每一個單詞 ωz,其表示向量由以下幾部分連線而成:單詞 ωz 的 BLSTM 向量 ez,單詞 ωz 的語意型別的表示向量 tz,單詞 ωz 與物體 ei、ej 的相對位置的表示向量(ωz 與 ei 的相對位置表示 pzi,ωz 與 ej 的相對位置表示 pzj)。
綜上,標的物體對的背景關係單詞的最終表示為: 。對於每一個句子,其所有物體對的背景關係表示向量可以用一個 3 維矩陣 C 表示,矩陣的行和列分別對應物體,矩陣的深度對應背景關係單詞。
。對於每一個句子,其所有物體對的背景關係表示向量可以用一個 3 維矩陣 C 表示,矩陣的行和列分別對應物體,矩陣的深度對應背景關係單詞。
之後,透過註意力機制將每對標的物體的背景關係表示向量聚合為一個向量。根據 Zhou et al. 2016 提出的方法,計算標的物體對背景關係單詞的權重,然後計算它們的加權平均值:
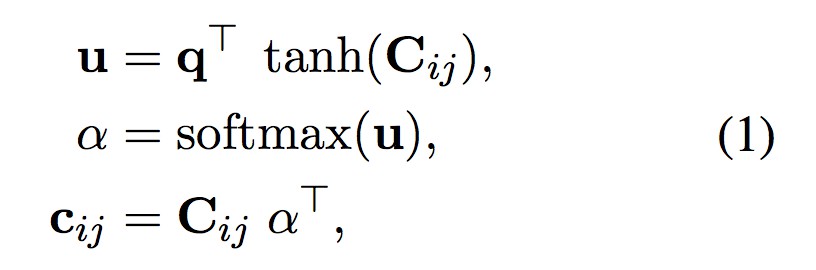
其中, 表示可訓練的註意力向量,α 表示加權向量,
表示可訓練的註意力向量,α 表示加權向量,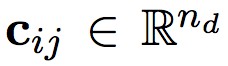 為物體對背景關係表示向量加權平均後的結果。
為物體對背景關係表示向量加權平均後的結果。
最後,將標的物體對的表示向量與其背景關係的表示向量 連線起來。透過使用一個全連線線性層
連線起來。透過使用一個全連線線性層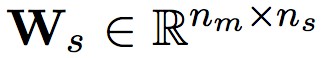 ,其中 ns
,其中 ns
路徑融合層
模型的主要目的是透過使用物體之間的間接關係來判斷物體之間的直接關係。因此,本層的標的是:將物體對之間的多個不同長度的路徑融合成一條路徑。為了達成這一標的,模型將一個句子表示成一個有向圖,其中圖的節點表示句子中的物體,圖中的邊表示兩個節點(物體)之間的關係。
標的物體之間的單位長度路徑表示為![]() ,以此作為一個基本的構建模組,可進一步用於建立和聚合兩個物體之間長度為 l(l≥1) 的路徑。
,以此作為一個基本的構建模組,可進一步用於建立和聚合兩個物體之間長度為 l(l≥1) 的路徑。
基於路徑的演演算法可以看成兩步處理過程:路徑構建和路徑融合。在第一步處理過程中,透過一種改進的非線性變換將圖中兩個連續邊聯合起來:

其中, 表示物體 ei 和 ej 之間長度為 λ 的路徑,⨀ 表示元素乘法,σ 表示 sigmoid 非線性函式,
表示物體 ei 和 ej 之間長度為 λ 的路徑,⨀ 表示元素乘法,σ 表示 sigmoid 非線性函式,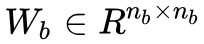 為一個可訓練的權值矩陣。等式 (2) 得到一個長度為 2λ 的路徑。
為一個可訓練的權值矩陣。等式 (2) 得到一個長度為 2λ 的路徑。
在路徑融合步驟中,模型將初始路徑(長度為 λ)和擴充套件路徑(長度 2λ)線性地結合起來:
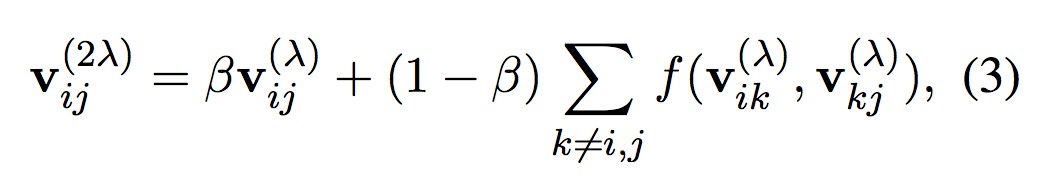
其中,β 為權重,用於表示路徑的重要程度。
綜上,當 λ=1 時,利用等式 (3) 可建立一個長度為 2 的路徑。之後,取 λ=2,再次使用等式 (3) 建立一個長度為 4 的路徑。不斷重覆上述過程直到達到預期的最大路徑長度,即 2λ=l。
分類層
在整個網路的最後一層,將上一層的輸出輸入到一個使用 softmax 函式的全連線層:
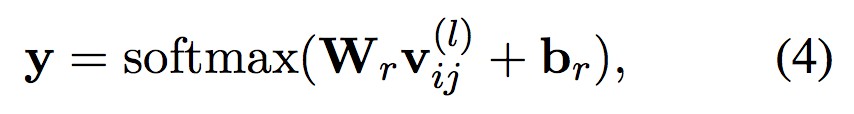
其中, 是權值矩陣,nr 表示關係型別的總數目,br 表示偏置向量。
是權值矩陣,nr 表示關係型別的總數目,br 表示偏置向量。
實驗
文章在 ACE 2005 的關係抽取任務資料集上對提出的模型進行了測試。
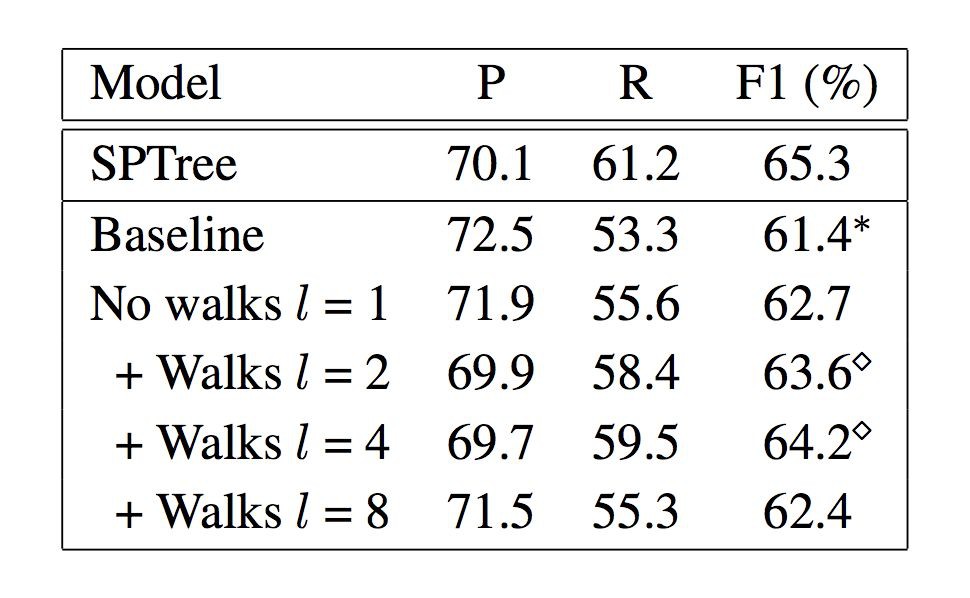
上表所示為模型與 SPTree 系統在 ACE2005 資料集上效能的比較,第一行為 SPTree 系統得分,第二行為基線模型得分,第三行為使用了註意力機制的基線模型得分,餘下三行為文章提出的模型使用不同長度路徑時的得分。表中顯示了準確率 P、召回率 R 和 F1 得分三項指標。
準確率指標P:雖然準確率並沒有隨著基於路徑的圖模型的使用以及路徑長度的增加而線性提高,甚至還要低於基線模型,但模型在不同路徑長度下的準確率 P 均與 SPTree 系統十分接近,證明基於路徑的圖模型在關係抽取任務中的有效性,只是效能還有待提升。
召回率指標R:模型召回率隨著路徑的增加而逐漸提高,直到路徑增加到 l=8 時發生回落。說明增加路徑長度是提升真正例識別數量的一種有效手段,也從側面驗證了透過物體的間接關係來識別標的物體對直接關係的可行性和有效性。
F1得分:圖中,基線模型的 F1 得分為 61.4%,在所有模型中為最低。透過使用註意力機制可以將其 F1 得分提升 1.3 個百分點至 62.7%。在此基礎之上,使用基於路徑的模型,模型 F1 得分隨著路徑長度的增加而增加,l=4 時模型 F1 得分最高為 64.2%,當路徑長度增加至 8 時 F1 得分出現回落。若僅從 F1 得分指標看,文章模型在關係提取任務中的效能已與當前比較先進的演演算法十分接近。
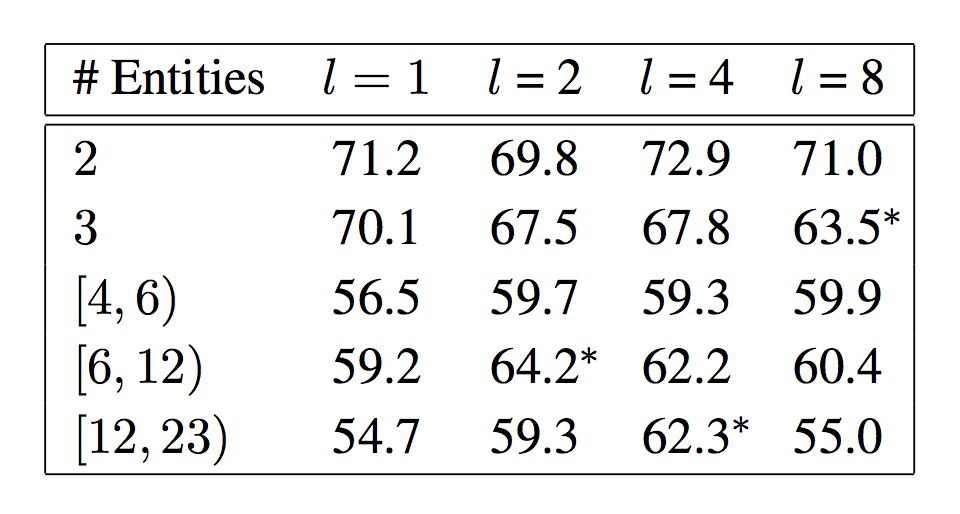
下表所示為,在擁有不同物體數量的句子中,使用不同長度路徑時模型的 F1 得分。其中,第一行表示路徑長度,第一串列示句子中物體的數量。觀察可知,當句子中物體數量較少時,基於路徑的圖模型與普通模型相比優勢並不明顯,甚至還略顯不如。但當句子中的物體數量較多時,基於路徑的圖模型與普通模型相比效能提升明顯,說明基於路徑的圖模型適用於處理句子中物體數量較多的情況。
除了上述實驗之外,文章還將模型與 Nguyen and Grishman 2015 提出的 CNN 模型進行了對比。實驗中,將路徑長度設定為 l=4,得到的 P/R/F1(%) 分別為 65.8/58.4/61.9,而 CNN 模型相應的得分分別為 71.5/53.9/61.3。對比發現,文章模型的 F1 得分高於 CNN 模型 0.6 個百分點。
總結
當前,在關係抽取任務中使用最多的是 RNNs 及其各種改進演演算法,但這些方法都沒有考慮句子中關係之間的依賴性,在處理句子中存在多個物體對的情況時沒有充分利用物體間的間接關係。與這些方法不同,這裡介紹的文章,採用基於路徑的物體圖模型,在識別標的物體對的關係時充分使用物體間的間接關係。
雖然,也有一些其他的演演算法,也是針對句子中存在多種關係的情況(Gupta et al., 2016; Miwa and Sasaki, 201421; Li and Ji, 2014)。但是,這些演演算法無法對已知物體路徑建模。
本文透過實驗,證明瞭基於路徑的圖模型在關係抽取任務中的可行性和有效性。雖然從實驗結果看,其效能與當前最先進的演演算法相比還存在一定差距,但是將基於路徑的圖模型引入關係抽取任務是一種新的思路,對此類模型的研究目前尚未大規模展開,因而模型效能暫時不佳也實屬正常,這就為我們下一步開展後續工作提供了研究思路和提升空間。
整體而言,這篇文章的啟發性意義大於其模型的實用意義。期待下一步在此思路的基礎上進一步提升模型效能。
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 下載論文
