
作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
前言:這篇文章是我們前幾天掛到 arXiv 上的論文的中文版。在這篇論文中,我們給出了結合流模型(如前面介紹的 Glow)和變分自編碼器的一種思路,稱之為 f-VAEs。理論可以證明 f-VAEs 是囊括流模型和變分自編碼器的更一般的框架,而實驗表明相比於原始的 Glow 模型,f-VAEs 收斂更快,並且能在更小的網路規模下達到同樣的生成效果。
■ 論文 | f-VAEs: Improve VAEs with Conditional Flows
■ 連結 | https://www.paperweekly.site/papers/2313
■ 作者 | Jianlin Su / Guang Wu
近來,生成模型得到了廣泛關註,其中變分自編碼器(VAEs)和流模型是不同於生成對抗網路(GANs)的兩種生成模型,它們亦得到了廣泛研究。然而它們各有自身的優勢和缺點,本文試圖將它們結合起來。

▲ 由f-VAEs實現的兩個真實樣本之間的線性插值
基礎
設給定資料集的證據分佈為![]() ,生成模型的基本思路是希望用如下的分佈形式來擬合給定資料集分佈:
,生成模型的基本思路是希望用如下的分佈形式來擬合給定資料集分佈:

其中 q(z) 一般取標準高斯分佈,而 q(x|z) 一般取高斯分佈(VAEs 中)或者狄拉克分佈(GANs 和流模型中)。理想情況下,最佳化方式是最大化似然函式 E[logq(x)],或者等價地,最小化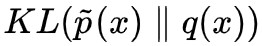 。
。
由於積分可能難以顯式計算,所以需要一些特殊的求解技巧,這導致了不同的生成模型。其中,VAE 引入後驗分佈 p(z|x),將最佳化標的改為更容易計算的上界 。眾所周知,VAE 有著收斂快、訓練穩定等優點,但一般情況下生成影象存在模糊等問題,其原因我們在後面會稍加探討。
。眾所周知,VAE 有著收斂快、訓練穩定等優點,但一般情況下生成影象存在模糊等問題,其原因我們在後面會稍加探討。
而在流模型中,q(x|z)=δ(x−G(z)),並精心設計 G(z)(透過流的組合)直接把這個積分算出來。流模型的主要元件是“耦合層”:首先將 x 分割槽為兩部分 x1,x2,然後進行如下運算:

這個變換是可逆的,逆變換為:

它的雅可比行列式是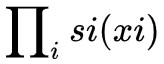 。這種變換我們通常稱之為“仿射耦合”(如果 s(x1)≡1,那麼通常稱為“加性耦合”),用 f 表示。透過很多耦合層的組合,我們可以得到複雜的非線性變換,即 G=f1∘f2∘⋯∘fn,這就是所謂的“(無條件)流”。
。這種變換我們通常稱之為“仿射耦合”(如果 s(x1)≡1,那麼通常稱為“加性耦合”),用 f 表示。透過很多耦合層的組合,我們可以得到複雜的非線性變換,即 G=f1∘f2∘⋯∘fn,這就是所謂的“(無條件)流”。
由於直接算出來積分,因此流模型可以直接完成最大似然最佳化。最近釋出的 Glow 模型顯示出強大的生成效果,引起了許多人的討論和關註。但是流模型通常相當龐大,訓練時間長(其中 256 x 256 的影象生成模型用 40 個 GPU 訓練了一週,參考這裡 [1] 和這裡 [2]),顯然還不夠友好。
分析
VAEs 生成影象模糊的解釋有很多,有人認為是 mse 誤差的問題,也有人認為是 KL 散度的固有性質。但留意到一點是:即使去掉隱變數的 KL 散度那一項,變成普通的自編碼器,重構出來的影象通常也是模糊的。這表明,VAEs 影象模糊可能是低維重構原始影象的固有問題。
如果將隱變數維度取輸入維度一樣大小呢?似乎還不夠,因為標準的 VAE 將後驗分佈也假設為高斯分佈,這限制了模型的表達能力,因為高斯分佈簇只是眾多可能的後驗分佈中極小的一部分,如果後驗分佈的性質與高斯分佈差很遠,那麼擬合效果就會很糟糕。
那 Glow 之類的流模型的問題是什麼呢?流模型透過設計一個可逆的(強非線性的)變換將輸入分佈轉化為高斯分佈。在這個過程中,不僅僅要保證變換的可逆性,還需要保證其雅可比行列式容易計算,這導致了“加性耦合層”或“仿射耦合層”的設計。然而這些耦合層只能帶來非常弱的非線效能力,所以需要足夠多的耦合層才能累積為強非線性變換,因此 Glow 模型通常比較龐大,訓練時間較長。
f-VAEs
我們的解決思路是將流模型引入到 VAEs 中,用流模型來擬合更一般的後驗分佈 p(z|x) ,而不是簡單地設為高斯分佈,我們稱之為 f-VAEs(Flow-based Variational Autoencoders,基於流的變分自編碼器)。
相比於標準的 VAEs,f-VAEs 跳出了關於後驗分佈為高斯分佈的侷限,最終導致 VAEs 也能生成清晰的影象;相比於原始的流模型(如 Glow),f-VAEs 的編碼器給模型帶來了更強的非線效能力,從而可以減少對耦合層的依賴,從而實現更小的模型規模來達到同樣的生成效果。
推導過程
我們從 VAEs 的原始標的出發,VAEs 的 loss 可以寫為:

其中 p(z|x),q(x|z) 都是帶引數的分佈,跟標準 VAEs 不同的是,p(z|x) 不再假設為高斯分佈,而是透過流模型構建:

這裡 q(u) 是標準高斯分佈,Fx(u) 是關於 x,u 的二元函式,但關於 u 是可逆的,可以理解為 Fx(u) 是關於 u 的流模型,但它的引數可能跟 x 有關,這裡我們稱為“條件流”。代入 (4) 計算得到:

這便是一般的 f-VAEs 的 loss,具體推導過程請參考下麵的註釋。
聯立 (4) 和 (5),我們有:
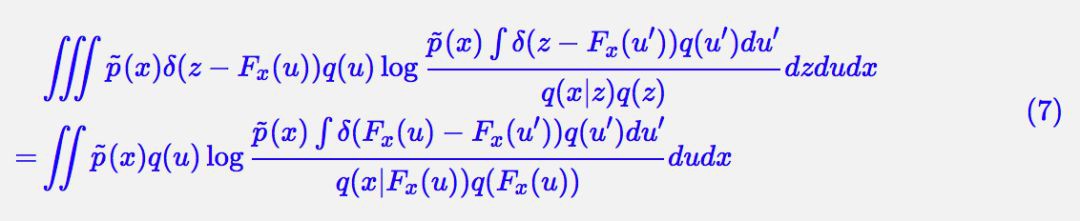
設 v=Fx(u′),u′=Hx(v),對於雅可比行列式,我們有關係:

從而 (7) 變成:

兩個特例
式 (6) 描述了一般化的框架,而不同的 Fx(u) 對應於不同的生成模型。如果我們設:

那麼就有:

以及:

這兩項組合起來,正好是後驗分佈和先驗分佈的 KL 散度;代入到 (6) 中正好是標準 VAE 的 loss。意外的是,這個結果自動包含了重引數的過程。
另一個可以考察的簡單例子是:
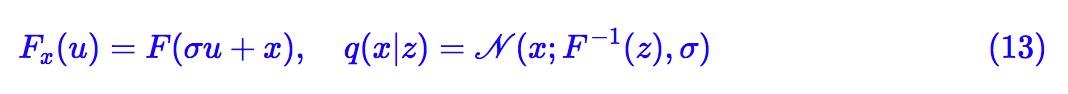
其中 σ 是一個小的常數,而F是任意的流模型,但引數與 x 無關(無條件流)。這樣一來:

所以它並沒有包含訓練引數。這樣一來,整個 loss 包含訓練引數的部分只有:
這等價於普通的流模型,其輸入加上了方差為![]() 的高斯噪聲。有趣的是,標準的 Glow 模型確實都會在訓練的時候給輸入影象加入一定量的噪聲。
的高斯噪聲。有趣的是,標準的 Glow 模型確實都會在訓練的時候給輸入影象加入一定量的噪聲。
我們的模型
上面兩個特例表明,式 (6) 原則上包含了 VAEs 和流模型。 Fx(u) 實際上描述了 u, x 的不同的混合方式,原則上我們可以選擇任意複雜的 Fx(u) ,來提升後驗分佈的表達能力,比如:
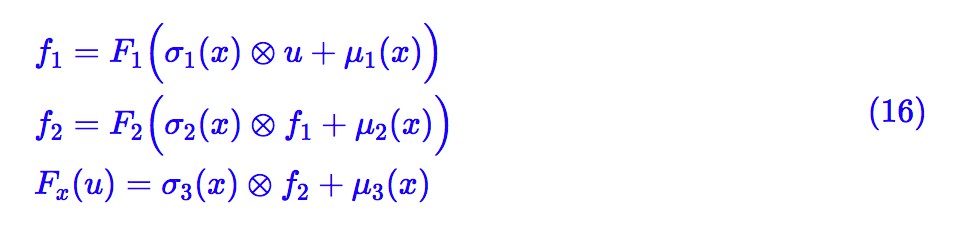
這裡的 F1,F2 是無條件流。
同時,到目前為止,我們並沒有明確約束隱變數 z 的維度大小(也就是 u 的維度大小),事實上它是一個可以隨意選擇的超引數,由此我們可以訓練更好的降維變分自編碼模型。但就影象生成這個任務而言,考慮到低維重構會導致模糊的固有問題,因此我們這裡選擇 z 的大小跟 x 的大小一致。
出於實用主義和簡潔主義,我們把式 (13) 和 (10) 結合起來,選擇:
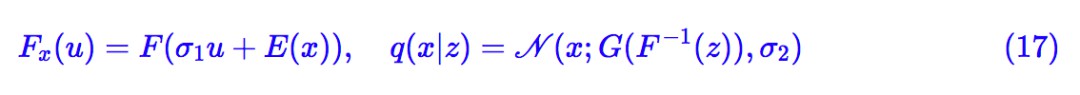
其中 σ1,σ2 都是待訓練引數(標量即可),E(⋅),G(⋅) 是待訓練的編碼器和解碼器(生成器),而F (⋅) 是引數與 x 無關的流模型。代入 (6),等效的 loss 為:

而生成取樣過程為:

相關
事實上,流模型是一大類模型的總稱。除了上述以耦合層為基礎的流模型(NICE、RealNVP、Glow)之外,我們還有“自回歸流(autoregressive flows)”,代表作有 PixelRNNs 和 PixelCNNs 等。自回歸流通常效果也不錯,但是它們是逐畫素地生成圖片,無法並行,所以生成速度比較慢。
諸如 RealNVP、Glow 的流模型我們通常稱為 Normalizing flows(常規流),則算是另外一種流模型。尤其是 Glow 出來後讓這類流模型再次火了一把。事實上,Glow 生成圖片的速度還是挺快的,就是訓練週期太長了,訓練成本也很大。
據我們瞭解,首次嘗試整合 VAEs 和模型的是 Variational Inference with Normalizing Flows [3],後面還有兩個改進工作 Improving Variational Inference with Inverse Autoregressive Flow [4] 和 Variational Lossy Autoencoder [5]。其實這類工作(包括本文)都是類似的。不過前面的工作都沒有匯出類似 (6) 式的一般框架,而且它們都沒有在圖片生成上實現較大的突破。
目測我們的工作是首次將 RealNVP 和 Glow 的流模型引入到 VAEs 中的結果。這些“流”基於耦合層,容易平行計算。所以它們通常比自回歸流要高效率,可以堆疊得很深。同時我們還保證隱變數維度跟輸入維度一樣,這個不降維的選擇也能避免影象模糊問題。
實驗
受 GPU 裝置所限,我們僅僅在 CelebA HQ 上做了 64×64 和 128×128 的實驗。我們先在 64×64 影象上對類似規模的 VAEs、Glow 和 f-VAEs 做了個對比,然後再詳細展示了 128×128 的生成效果。
實驗流程
首先,我們的編碼器 E(⋅) 是摺積和 Squeeze 運算元的堆疊。具體來說, E(⋅) 由幾個 block 組成,並且在每個 block 之前都進行一次 Squeeze。而每個 block 由若干步複合而成,每步的形式為 x+CNN(x) ,其中 CNN(x) 是 3×3 和 1×1 的摺積組成。具體細節可以參考程式碼。
至於解碼器(生成器)G (⋅) 則是摺積和 UnSqueeze 運算元的堆疊,結構上就是 E(⋅) 的逆。解碼器的最後可以加上 tanh(⋅) 啟用函式,但這也不是必須的。而無條件流 F(⋅) 的結果是照搬自 Glow 模型,只不過沒有那麼深,摺積核的數目也沒有那麼多。
原始碼(基於Keras 2.2 + Tensorflow 1.8 + Python 2.7):
https://github.com/bojone/flow/blob/master/f-VAEs.py

實驗結果
對比 VAEs 和 f-VAEs 的結果,我們可以認為 f-VAEs 已經基本解決了 VAEs 的模糊問題。對於同樣規模下的 Glow 和 f-VAEs,我們發現 f-VAEs 在同樣的 epoch 下表現得更好。當然,我們不懷疑 Glow 在更深的時候也表現得很好甚至更好,但很明顯,在同樣的複雜度和同樣的訓練時間下,f-VAEs 有著更好的表現。

f-VAEs 在 64×64 上面的結果,只需要用 GTX1060 訓練約 120-150 個 epoch,大概需要 7-8 小時。
準確來說,f-VAEs 的完整的編碼器應該是 F(E(⋅)),即 F 和 E 的複合函式。如果在標準的流模型中,我們需要計算 E 的雅可比行列式,但是在 f-VAEs 中則不需要。所以 E 可以是一個普通的摺積網路,它可以實現大部分的非線性,從而簡化對流模型 F 的依賴。
下麵是 128×128 的結果(退火引數 T 指的是先驗分佈的方差)。128×128 的模型大概在 GTX1060 上訓練了 1.5 天(約 150 個 epoch)。
隨機取樣結果

隱變數線性插值
▲ 兩個真實樣本之間的線性插值

退火引數影響

總結
文章綜述
事實上,我們這個工作的原始標的是解決針對 Glow 提出的兩個問題:
-
如何降低 Glow 的計算量?
-
如何得到一個“降維”版本的 Glow?
我們的結果表明,一個不降維的 f-VAEs 基本相當於一個迷你版本的 Glow,但是能達到較好的效果。而式 (6) 確實也允許我們訓練一個降維版本的流模型。我們也從理論上證明瞭普通的 VAEs 和流模型自然地包含在我們的框架中。因此,我們的原始標的已經基本完成,得到了一個更一般的生成和推斷框架。
未來工作
當然,我們可以看到隨機生成的圖片依然有一種油畫的感覺。可能的原因是模型還不夠複雜,但我們猜測還有一個重要原因是 3×3 摺積的“濫用”,導致了感知野的無限放大,使得模型無法聚焦細節。
因此,一個挑戰性的任務是如何設計更好的、更合理的編碼器和解碼器。看起來 Network in Network 那一套會有一定的價值,還有 PGGAN 的結構也值得一試,但是這些都還沒有驗證過。
參考文獻
[1]. https://github.com/openai/glow/issues/14#issuecomment-406650950
[2]. https://github.com/openai/glow/issues/37#issuecomment-410019221
[3]. Rezende, Danilo Jimenez, and Shakir Mohamed. Variational inference with normalizing flows. arXiv preprint arXiv:1505.05770, 2015.
[4]. D.P. Kingma, T. Salimans, R. Jozefowicz, I. Sutskever, M. Welling. Improving Variational Autoencoders with Inverse Autoregressive Flow. Advances in Neural Information Processing Systems 29 (NIPS), Barcelona, 2016
[5]. X. Chen, D.P. Kingma, T. Salimans, Y. Duan, P. Dhariwal, J. Schulman, I. Sutskever, P. Abbeel. Variational Lossy Autoencoder. The International Conference on Learning Representations (ICLR), Toulon, 2017

點選以下標題檢視作者其他文章:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視作者部落格
