(點選上方公眾號,可快速關註)
來源:裴彬
my.oschina.net/editorial-story/blog/2120649
Redis 中有 5 種資料結構,分別是字串(String)、雜湊(Hash)、串列(List)、集合(Set)和有序集合(Sorted Set),因為使用 Redis 場景的開發中肯定是無法避開這些基礎結構的,所以熟練掌握它們也就成了一項必不可少的能力。本文章精要地介紹了 Redis 的這幾種資料結構,主要改寫了它們各自的定義、基本用法與相關要點。
字串型別
字串是 Redis 中的最基礎的資料結構,我們儲存到 Redis 中的 key,也就是鍵,就是字串結構的。除此之外,Redis 中其它資料結構也是在字串的基礎上設計的,可見字串結構對於 Redis 是多麼重要。
Redis 中的字串結構可以儲存多種資料型別,如:簡單的字串、JSON、XML、二進位制等,但有一點要特別註意:在 Redis 中字串型別的值最大隻能儲存 512 MB。

命令
下麵透過命令瞭解一下對字串型別的操作:
1.設定值
set key value [EX seconds] [PX milliseconds] [NX|XX]

set 命令有幾個非必須的選項,下麵我們看一下它們的具體說明:
-
EX seconds:為鍵設定秒級過期時間
-
PX milliseconds:為鍵設定毫秒級過期時間
-
NX:鍵必須不存在,才可以設定成功,用於新增
-
XX:鍵必須存在,才可以設定成功,用於更新
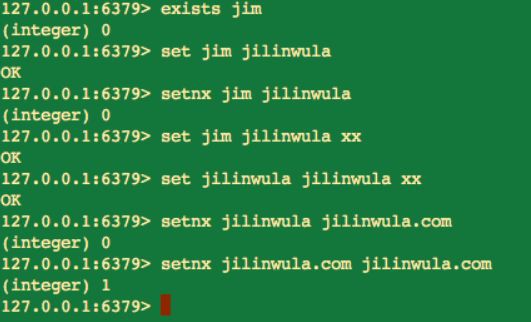
set 命令帶上可選引數 NX 和 XX 在實際開發中的作用與 setnx 和 setxx 命令相同。我們知道 setnx 命令只有當 key 不存在的時候才能設定成功,換句話說,也就是同一個 key 在執行 setnx 命令時,只能成功一次,並且由於 Redis 的單執行緒命令處理機制,即使多個客戶端同時執行 setnx 命令,也只有一個客戶端執行成功。所以,基於 setnx 這種特性,setnx 命令可以作為分散式鎖的一種解決方案。
而 setxx 命令則可以在安全性比較高的場景中使用,因為 set 命令執行時,會執行改寫的操作,而 setxx 在更新 key 時可以確保該 key 已經存在了,所以為了保證 key 中資料型別的正確性,可以使用 setxx 命令。
2.獲取值
get key

3.批次設定值
mset key value
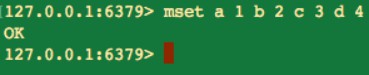
4.批次獲取值
mget key

如果有些鍵不存在,那麼它的值將為 nil,也就是空,並且傳回結果的順序與傳入時相同。

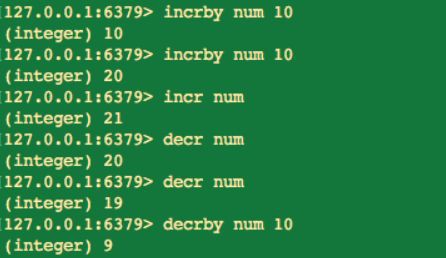
5.計數
incr key
incr 命令用於對值做自增操作,傳回的結果分為 3 種情況:
-
如果值不是整數,那麼傳回的一定是錯誤
-
如果值是整數,那麼傳回自增後的結果
-
如果鍵不存在,那麼就會建立此鍵,然後按照值為 0 自增, 就是傳回 1

除了有 incr 自增命令外,Redis 中還提供了其它對數字處理的命令。例如:
decr key 自減
incrby kek increment 自增指定數字
decrby key decrement 自減指定數字
incrbyfloat key increment 自增浮點數
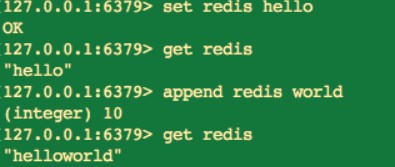
6.追加值
append key value
append 命令可以向字串尾部追加值。
7.字串長度
strlen key
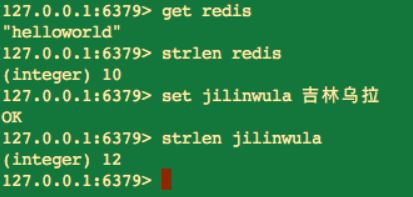
由於每個中文佔用 3 個位元組,所以 jilinwula 這個鍵,傳回是字串長度為 12,而不是 4。
8.設定並傳回原值
getset key value

9.設定指定位置的字元
setrange key offeset value

10.獲取部分字串
getrange key start end

時間複雜度
在 Redis 中執行任何命令時,都有相應的時間複雜度,複雜度越高也就越費時間,所以在執行 Redis 中的命令時,如果要執行的命令複雜度越高,就越要慎重。下麵是字串命令時間複雜度型別表:

內部編碼
在 Redis 中字串型別的內部編碼有 3 種:
-
int:8 個位元組的長整型
-
embstr:小於等於 39 個位元組的字串
-
raw:大於 39 個位元組的字串

雜湊型別
大部分語言基本都提供了雜湊型別,如 Java 語言中的 Map 型別及 Python 語言中的字典型別等等。雖然語言不同,但它們基本使用都是一樣的,也就是都是鍵值對結構的。例如:
value={{field1, value1}
透過下圖可以直觀感受一下字串型別和雜湊型別的區別:

Redis 中雜湊型別都是鍵值對結構的,所以要特別註意這裡的 value 並不是指 Redis 中 key 的 value,而是雜湊型別中的 field 所對應的 value。
命令
下麵我們還是和介紹字串型別一樣,瞭解一下 Redis 中雜湊型別的相關命令。
1.設定值
hset key field value

我們看上圖執行的命令知道,hset 命令也是有傳回值的。如果 hset 命令設定成功,則傳回 1,否則傳回 0。除此之外 Redis 也為雜湊型別提供了 hsetnx 命令。在前文對字串的介紹中,我們知道 nx 命令只有當 key 不存在的時候,才能設定成功,同樣的,hsetnx 命令在 field 不存在的時候,才能設定成功。
2.獲取值
hget key field

我們看 hget 命令和 get 有很大的不同,get 命令在獲取的時候,只要寫一個名字就可以了,而 hget 命令則要寫兩個名字,第一個名字是 key,第二個名字是 field。當然 key 或者 field 不存在時,傳回的結果都是 nil。
3.刪除 field
hdel key field [field …]
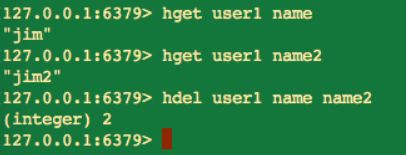
hdel 命令刪除的時候,也會有傳回值,並且這個傳回就是成功刪除 field 的個數。當 field 不存在時,並不會報錯,而是直接傳回 0。
4.計算 field 個數
hlen key

hlen 命令傳回的就是當前 key 中 field 的個數,如果 key 不存在,則傳回 0。
5.批次設定或獲取 field-value
hmget key field [field …]
hmset key field value [field value …]

hmset 命令和 hmget 命令分別是批次設定和獲取值的,hmset 命令沒有什麼要註意的,但 hmget 命令要特別註意,當我們獲取一個不存在的 key 或者不存在的 field 時,Redis 並不會報錯,而是傳回 nil。並且有幾個 field 不存在,則 Redis 傳回幾個 nil。
6.判斷 field 是否存在
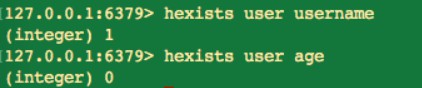
hexists key field

當執行 hexists 命令時,如果當前 key 包括 field,則傳回 1,否則傳回 0。
7.獲取所有 field
hkeys key
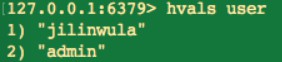
8.獲取所有 value
hvals key
9.獲取所有的 field-value
hgetall key
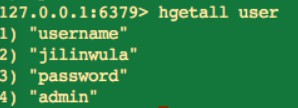
hgetall 命令會傳回當前 key 中的所有 field-value,並按照順序依次傳回。
10.計數
hincrby key field increment
hincrbyfloat key field increment

hincrby 命令和 incrby 命令的使用功能基本一樣,都是對值進行增量操作的,唯一不同的就是 incrby 命令的作用域是 key,而 hincrby 命令的作用域則是 field。
11.計算 value 的字串長度
hstrlen key field
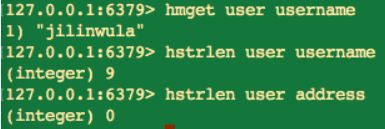
hstrlen 命令傳回的是當前 key 中 field 中字串的長度,如果當前 key 中沒有 field 則傳回 0。
時間複雜度
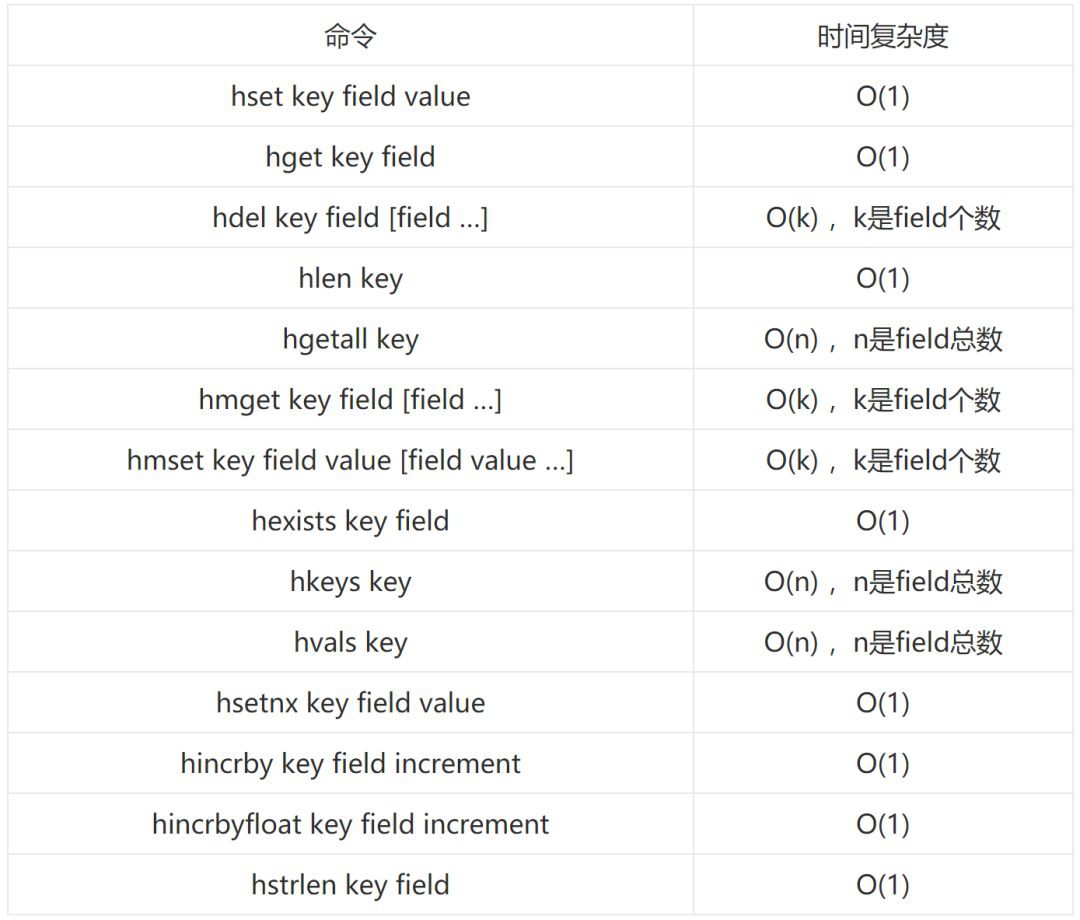
內部編碼
Redis 雜湊型別的內部編碼有兩種,它們分別是:
-
ziplist(壓縮串列):當雜湊型別中元素個數小於 hash-max-ziplist-entries 配置(預設 512 個),同時所有值都小於 hash-max-ziplist-value 配置(預設 64 位元組)時,Redis 會使用 ziplist 作為雜湊的內部實現。
-
hashtable(雜湊表):當上述條件不滿足時,Redis 則會採用 hashtable 作為雜湊的內部實現。
下麵我們透過以下命令來演示一下 ziplist 和 hashtable 這兩種內部編碼。
當 field 個數比較少並且 value 也不是很大時候 Redis 雜湊型別的內部編碼為 ziplist:

當 value 中的位元組數大於 64 位元組時(可以透過 hash-max-ziplist-value 設定),內部編碼會由 ziplist 變成 hashtable。
![]()
當 field 個數超過 512(可以透過 hash-max-ziplist-entries 引數設定),內部編碼也會由 ziplist 變成 hashtable。
由於直接手動建立 512 個 field 不方便,為了更好的驗證該功能,我將用程式的方式,動態建立 512 個 field 來驗證此功能,下麵為具體的程式碼:

串列型別
Redis 中串列型別可以簡單地理解為儲存多個有序字串的一種新型別,這種型別除了字串型別中已有的功能外,還提供了其它功能,如可以對串列的兩端插入和彈出元素(在串列中的字串都可以稱之為元素),除此之外還可以獲取指定的元素串列,並且還可以透過索引下標獲取指定元素等等。下麵我們透過下圖來看一下 Redis 中串列型別的插入和彈出操作:
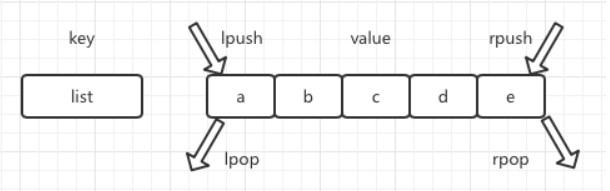
下麵我們看一下 Redis 中串列型別的獲取與刪除操作:
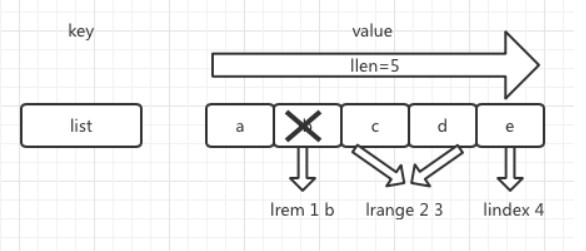
Redis 串列型別的特點如下:
-
串列中所有的元素都是有序的,所以它們是可以透過索引獲取的,也就是上圖中的 lindex 命令。並且在 Redis 中串列型別的索引是從 0 開始的。
-
串列中的元素是可以重覆的,也就是說在 Redis 串列型別中,可以儲存同名元素,如下圖所示:

命令
下麵我們還是和學習其它資料型別一樣,我們還是先學習一下 Redis 串列型別的命令。
1.新增操作
-
從右邊插入元素
rpush key value [value …]
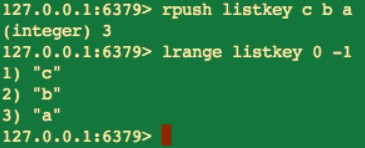
我們看 rpush 命令在插入時,是有傳回值的,傳回值的數量就是當前串列中所有元素的個數。
我們也可以用下麵的命令從左到右獲取當前串列中的所有的元素,也就是如上圖所示中那樣。
lrange 0 -1
-
從左邊插入元素
lpush key value [value …]

lpush 命令的傳回值及用法和 rpush 命令一樣。透過上面的事例證明瞭我們前面說的,rpush 命令和 lpush 命令的傳回值並不是當前插入元素的個數,而是當前 key 中全部元素的個數,因為當前 key 中已經有了 3 個元素,所以我們在執行插入命令時,傳回的就是 6 而不是 3,。
-
向某個元素前或者後插入元素
linsert key BEFORE|AFTER pivot value
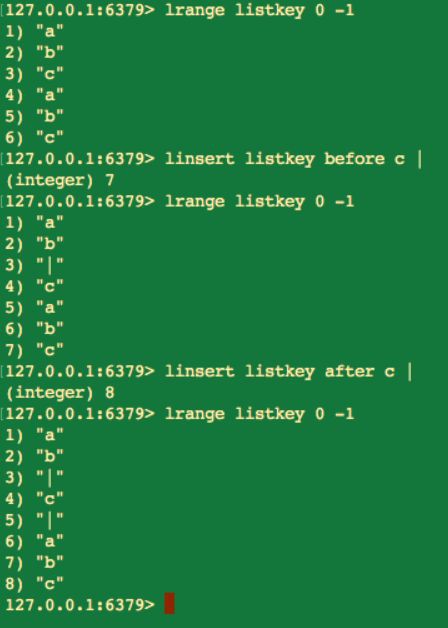
linsert 命令在執行的時候首先會從當前串列中查詢到 pivot 元素,其次再將這個新元素插入到 pivot 元素的前面或者後面。並且我們透過上圖可以知道 linsert 命令在執行成功後也是會有傳回值的,傳回的結果就是當前串列中元素的個數。
2.查詢
-
獲取指定範圍內的元素串列
lrange key start stop
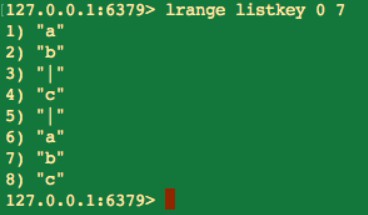
lrange 命令會獲取串列中指定索引範圍的所有元素。
透過索引獲取串列主要有兩個特點:
-
索引下標從左到右分別是 0 到 N-1,從右到左是 -1 到 -N。
-
lrange 命令中的 stop 引數在執行時會包括當前元素,並不是所有的語言都是這樣的。我們要獲取串列中前兩個元素則可以如下圖所示:
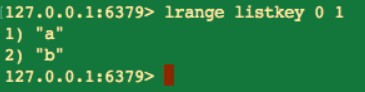
-
獲取串列中指定索引下標的元素
lindex key index

-
獲取串列長度
llen key

3.刪除
-
從串列左側彈出元素
lpop key

lpop 命令執行成功後會傳回當前被刪除的元素名稱。
-
從串列右側彈出元素
rpop key

rpop 命令和 lpop 命令的使用方式一樣。
-
刪除指定元素
lrem key count value
lrem 命令會將串列中等於 value 的元素刪除掉,並且會根據 count 引數來決定刪除 value 的元素個數。
下麵我們看一下 count 引數的使用說明:
count > 0:表示從左到右,最多刪除 count 個元素。也就是如下圖所示:
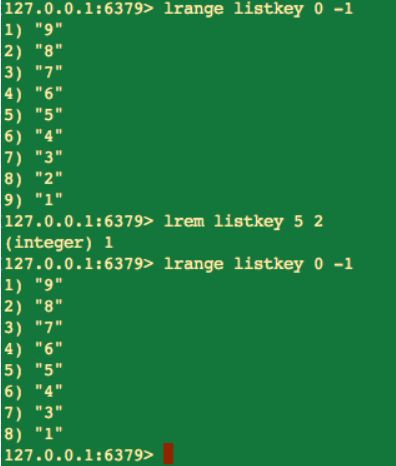
我們看上圖中的命令中,雖然我們將 count 引數指定的是 5,將 value 引數指定的是 2,但由於當前串列中只有一個 2,所以,當前 lrem 命令最多隻能刪除 1 個元素,並且 lrem 命令也是有傳回值的,也就是當前成功刪除元素的個數。
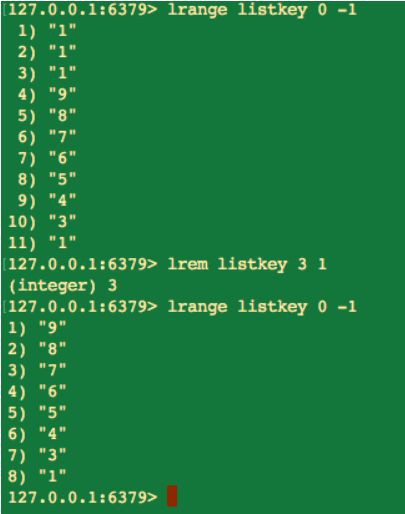
count < 0:從右到左,最多刪除 count 個元素。

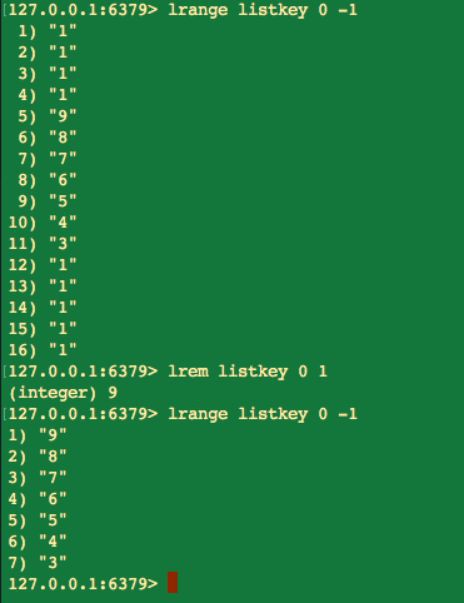
count = 0:刪除所有元素。
-
按照索引範圍修剪串列
ltrim key start stop
ltrim 命令會直接保留 start 索引到 stop 索引的之間的元素,並包括當前元素,而之外的元素則都會刪除掉,所以該命令也叫修剪串列。

並且有一點要註意,ltrim 命令不會傳回當前的串列中元素的個數,而是傳回改命令是否成功的狀態。
4.修改
-
修改指定索引下標的元素
lset key index value

5.阻塞操作
blpop key [key …] timeout
brpop key [key …] timeout
blpop 和 brpop 命令是 lpop 和 rpop 命令的阻塞版本,它們除了彈出方向不同以外,使用方法基本相同。
-
key [key …]:可以指定多個串列的鍵。
-
timeout:阻塞時間(單位:秒)
下麵我們看一下該命令的詳細使用。
串列為空:如果 timeout=3,則表示客戶端等待 3 秒後才能傳回結果,如果 timeout=0,則表示客戶端會一直等待,也就是會阻塞。

由於我期間向串列中插入了元素,否則上述命令將一直阻塞下去。
串列不為空:如果 timeout=0,並且串列不為空時,則 blpop 和 brpop 命令會立即傳回結果,不會阻塞。
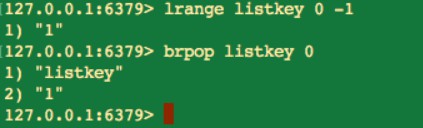
下麵我們看一下 blpop 和 brpop 命令的註意事項。
如果使用 blpop 和 brpop 命令指定多個鍵時,blpop 和 brpop 命令會從左到右遍歷鍵,並且一旦有一個鍵能傳回元素,則客戶端會立即傳回。

當串列為空時,上述命令會阻塞,如果向上述中的任何一個鍵中插入元素,則上述命令會直接傳回該鍵的元素。
如果多個客戶端都對同一個鍵執行 blpop 或者 brpop 命令,則最先執行該命令的客戶端會獲取到該鍵的元素。

我同時啟動了 3 個客戶端,因為當前串列為空,所以上述命令執行後會阻塞。如果此時我向該串列中插入元素,則只有第一個客戶端會有傳回結果,因為第一個客戶端是第一個執行上述命令的。


時間複雜度
下麵我們看一下串列中命令的相關時間複雜度。

內部編碼
串列中的內部編碼有兩種,它們分別是:
-
ziplist(壓縮串列):當串列中元素個數小於 512(預設)個,並且串列中每個元素的值都小於 64(預設)個位元組時,Redis 會選擇用 ziplist 來作為串列的內部實現以減少記憶體的使用。當然上述預設值也可以透過相關引數修改:list-max-ziplist-entried(元素個數)、list-max-ziplist-value(元素值)。
-
linkedlist(連結串列):當串列型別無法滿足 ziplist 條件時,Redis 會選擇用 linkedlist 作為串列的內部實現。
集合型別
Redis 中的集合型別,也就是 set。在 Redis 中 set 也是可以儲存多個字串的,經常有人會分不清 list 與 set,下麵我們重點介紹一下它們之間的不同:
-
set 中的元素是不可以重覆的,而 list 是可以儲存重覆元素的。
-
set 中的元素是無序的,而 list 中的元素是有序的。
-
set 中的元素不能透過索引下標獲取元素,而 list 中的元素則可以透過索引下標獲取元素。
-
除此之外 set 還支援更高階的功能,例如多個 set 取交集、並集、差集等。
命令
下麵我們介紹一下 set 中的相關命令。
1.集合內操作
-
新增元素
sadd key member [member …]

sadd 命令也是有傳回值的,它的傳回值就是當前執行 sadd 命令成功新增元素的個數,因為 set 中不能儲存重覆元素,所以在執行 sadd setkey c d 命令時,傳回的是 1,而不是 2。因為元素 c 已經成功儲存到 set 中,不能再儲存了,只能將 d 儲存到 set 中。
-
刪除元素
srem key member [member …]

srem 命令和 sadd 命令一樣也是有傳回值的,傳回值就是當前刪除元素的個數。
-
計算元素個數
scard key
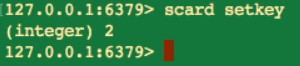
scard 命令的時間複雜度為O(1),scard 命令不會遍歷 set 中的所有元素,而是直接使用 Redis 中的內部變數。
-
判讀元素是否在集合中
sismember key member

sismember 命令也有傳回值,如果傳回值為1則表示當前元素在當前 set 中,如果傳回 0 則表示當前元素不在 set 中。
-
隨機從 set 中傳回指定個數元素
srandmember key [count]

srandmember 命令中有一個可選引數 count,count 引數指的是傳回元素的個數,如果當前 set 中的元素個數小於 count,則 srandmember 命令傳回當前 set 中的所有元素,如果 count 引數等於 0,則不傳回任何資料,如果 count 引數小於 0,則隨機傳回當前 count 個數的元素。
-
從集合中隨機彈出元素
spop key [count]

spop 命令也是隨機從 set 中彈出元素,並且也支援 count 可選引數,但有一點和 srandmember 命令不同。spop 命令在隨機彈出元素之後,會將彈出的元素從 set 中刪除。
-
獲取所有元素
smembers key

smembers 命令雖然能獲取當前 set 中所有的元素,但傳回元素的順序與 sadd 新增元素的順序不一定相同,這也就是前面提到過的儲存在 set 中的元素是無序的。
2.集合間操作
-
集合的交集
sinter key [key …]

-
集合的並集
sunion key [key …]
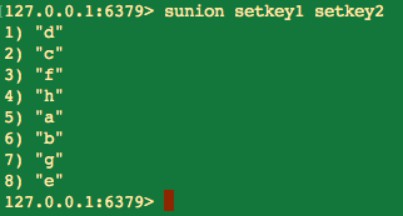
-
集合的差集
sdiff key [key …]

-
將集合的交集、並集、差集的結果儲存
sinterstore destination key [key …]
sunionstore destination key [key …]
sdiffstore destination key [key …]

為什麼 Redis 要提供 sinterstore、sunionstore、sdiffstore 命令來將集合的交集、並集、差集的結果儲存起來呢?這是因為 Redis 在進行上述比較時,會比較耗費時間,所以為了提高效能可以將交集、並集、差集的結果提前儲存起來,這樣在需要使用時,可以直接透過 smembers 命令獲取。
時間複雜度
下麵我們看一下 set 中相關命令的時間複雜度。
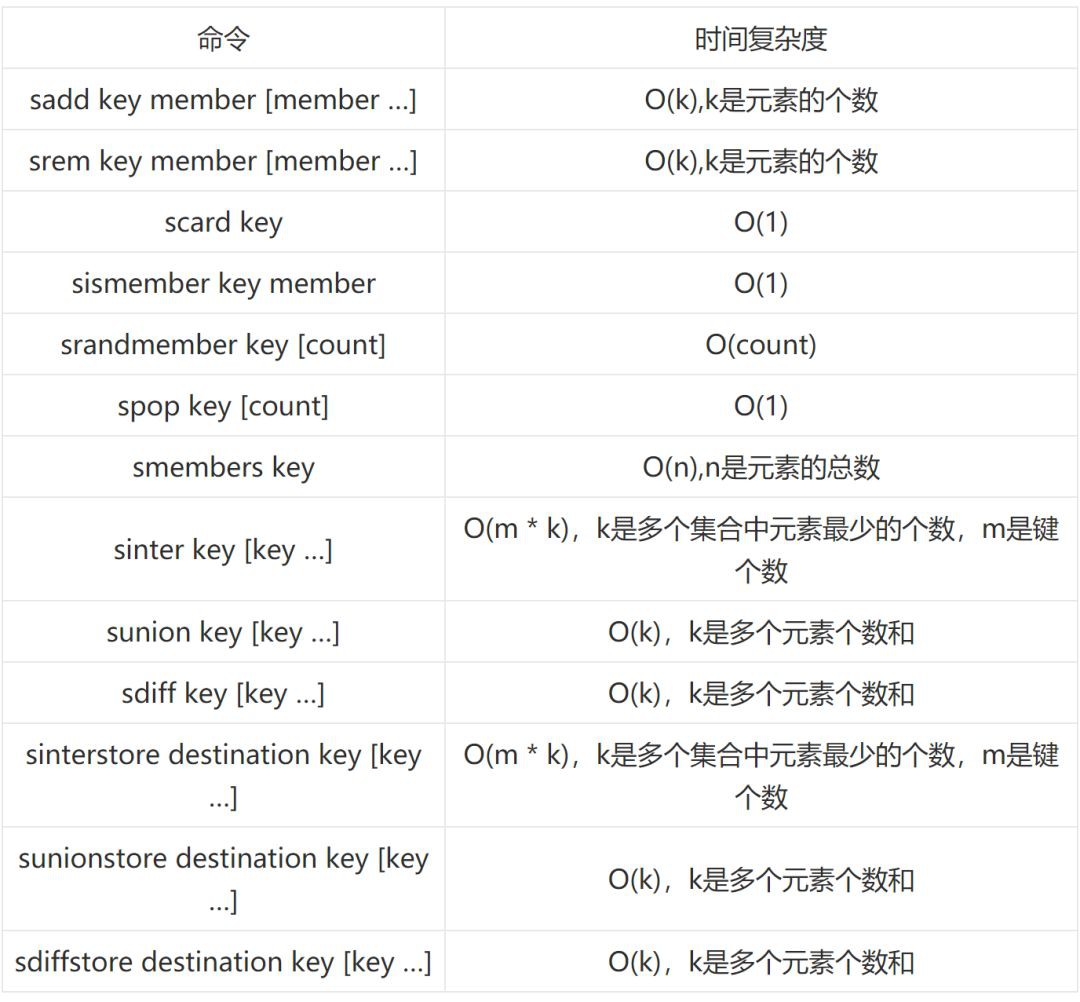
內部編碼
-
intset(整數集合):當集合中的元素都是整數,並且集合中的元素個數小於 512 個時,Redis 會選用 intset 作為底層內部實現。
-
hashtable(雜湊表):當上述條件不滿足時,Redis 會採用 hashtable 作為底層實現。
備註:我們可以透過 set-max-intset-entries 引數來設定上述中的預設引數。
下麵我們看一下具體的事例,來驗證我們上面提到的內部編碼。
當元素個數較少並且都是整數時,內部編碼為 intset。

當元素不全是整數時,內部編碼為 hashtable。
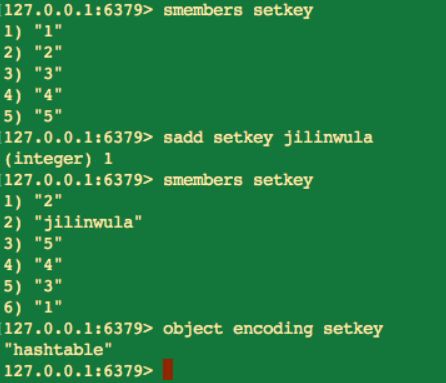
當元素個數超過 512 個時,內部編碼為 hashtable。

有序集合型別
看名字我們就知道,有序集合也是一種集合,並且這個集合還是有序的。串列也是有序的,那它和有序集合又有什麼不同呢?有序集合的有序和串列的有序是不同的。串列中的有序指的的是插入元素的順序和查詢元素的順序相同,而有序集合中的有序指的是它會為每個元素設定一個分數(score),而查詢時可以透過分數計算元素的排名,然後再傳回結果。因為有序集合也是集合型別,所以有序集合中也是不插入重覆元素的,但在有序集合中分數則是可以重覆,那如果在有序集合中有多個元素的分數是相同的,這些重覆元素的排名是怎麼計算的呢?後邊我們再做詳細說明。
下麵先看一下串列、集合、有序集合三種資料型別之間的區別:
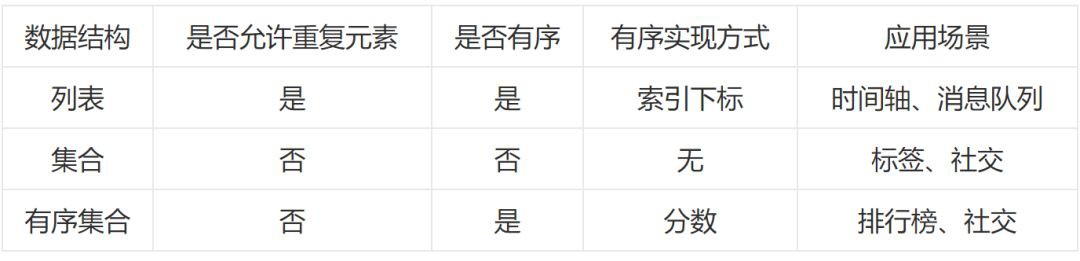
命令
1.集合內操作
-
新增元素
zadd key [NX|XX] [CH] [INCR] score member [score member …]

zadd 命令也是有傳回值的,傳回值就是當前 zadd 命令成功新增元素的個數。zadd 命令有很多選填引數:
-
nx: 元素必須不存在時,才可以設定成功。
-
xx: 元素必須存在時,才可以設定成功。
-
ch: 傳回此命令執行完成後,有序集合元素和分數發生變化的個數
-
incr: 對 score 做增加。
備註:由於有序集合相比集合提供了排序欄位,正是因為如此也付出了相應的代價,sadd 的時間複雜度為 O(1),而 zadd 的時間複雜度為O(log(n))。
-
計算成員個數
zcard key

-
計算某個成員的分數
zscore key member

在使用 zscore 命令時,如果 key 不存在,或者元素不存在時,該命令傳回的都是(nil)。
-
計算成員的排名
zrank key member
zrevrank key member

zrank 命令是從分數低到高排名,而 zrevrank 命令則恰恰相反,從高到低排名。有一點要特別註意, zrank 和 zrevrank 命令與 zscore 是命令不同的,前者透過分數計算出最後的排名,而後者則是直接傳回當前元素的分數。
-
刪除元素
zrem key member [member …]
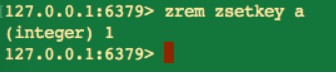
傳回的結果為成功刪除元素的個數,因為 zrem 命令是支援批次刪除的。
-
增加元素分數
zincrby key increment member

雖然 zincrby 命令是增加元素分數的,但我們也可以指定負數,這樣當前元素的分數,則會相減。
-
傳回指定排名範圍的元素
zrange key start stop [WITHSCORES]
zrevrange key start stop [WITHSCORES]

zrange 命令是透過分數從低到高傳回資料,而 zrevrange 命令是透過分數從高到低傳回資料。如果執行命令時添加了 WITHSCORES 可選引數,則傳回資料時會傳回當前元素的分數。
-
傳回指定分數範圍的元素
zrangebyscore key min max [WITHSCORES] [LIMIT offset count]
zrevrangebyscore key max min [WITHSCORES] [LIMIT offset count]

min 和 max 引數還支援開區間(小括號)和閉區間(中括號),同時我們還可以用 -inf 和 +inf 引數代表無限小和無限大。

-
傳回指定分數範圍元素個數
zcount key min max

-
刪除指定排名內的升序元素
zremrangebyrank key start stop
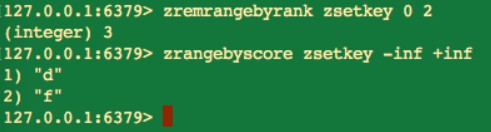
-
刪除指定分數範圍元素
zremrangebyscore key min max

2.集合間操作
-
交集
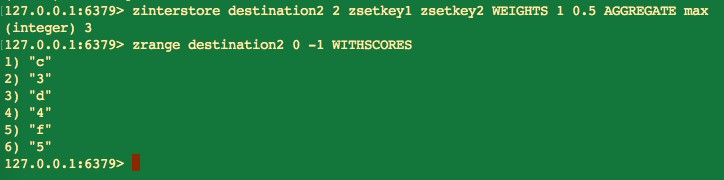
zinterstore destination numkeys key [key …] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
zinterstore 命令引數比較多:
-
destination:將交集的計算結果,儲存到這個鍵中。
-
numkeys:需要做交集計算鍵的個數。
-
key [key …]:需要做交集計算的鍵。
-
WEIGHTS weight:每個鍵的權重,在做交集計算時,每個鍵中的分數值都會乘以這個權重,預設每個鍵的權重為 1。
-
AGGREGATE SUM|MIN|MAX:計算成員交集後,分值可以按照 sum(和)、min(最小值)、max(最大值)做彙總,預設值為 sum。

下麵我們將權重設定為 0.5,這樣當計算交集後,有序集合中的元素分數將都會減半,並且使用 max 引數彙總。
-
並集
zunionstore destination numkeys key [key …] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]

zunionstore 命令的相關引數和 zinterstore 命令相同。
時間複雜度

內部編碼
有序集合型別的內部編碼有兩種,它們分別是:
-
ziplist(壓縮串列):當有序集合的元素個數小於 128 個(預設設定),同時每個元素的值都小於 64 位元組(預設設定),Redis 會採用 ziplist 作為有序集合的內部實現。
-
skiplist(跳躍表):當上述條件不滿足時,Redis 會採用 skiplist 作為內部編碼。
備註:上述中的預設值,也可以透過以下引數設定:zset-max-ziplist-entries 和 zset-max-ziplist-value。
下麵我們用以下示例來驗證上述結論。
當元素個數比較少,並且每個元素也比較小時,內部編碼為 ziplist:

當元素個數超過 128 時,內部編碼為 skiplist。下麵我們將採用 python 動態建立128個元素,下麵為原始碼:

當有序集合中有任何一個元素大於 64 個位元組時,內部編碼為 skiplist。


到這裡,本文就結束了,寫了這麼多,其實主要大部分是關於命令的簡單介紹,其中也介紹了一些關鍵要點,如有不正確的地方,歡迎留言。
作者介紹
裴彬,Java 工程師,喜歡程式設計,自己開發的部落格系統已上線:jilinwula.com
【關於投稿】
如果大家有原創好文投稿,請直接給公號傳送留言。
① 留言格式:
【投稿】+《 文章標題》+ 文章連結
② 示例:
【投稿】《不要自稱是程式員,我十多年的 IT 職場總結》:
http://blog.jobbole.com/94148/
③ 最後請附上您的個人簡介哈~
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能

