作者:OwenZeng
出處:https://www.cnblogs.com/OwenZeng/
連結:https://www.cnblogs.com/OwenZeng/p/8276892.html
前言
微軟工程師的一個工程師曾經對效能調優有一個非常形象的比喻:剝洋蔥 。我也非常認可,讓我們來一層一層撥開外面它神秘的面紗。

六大因素
下麵祭出的是我們在給客戶分析資料庫效能問題最常用的圖。
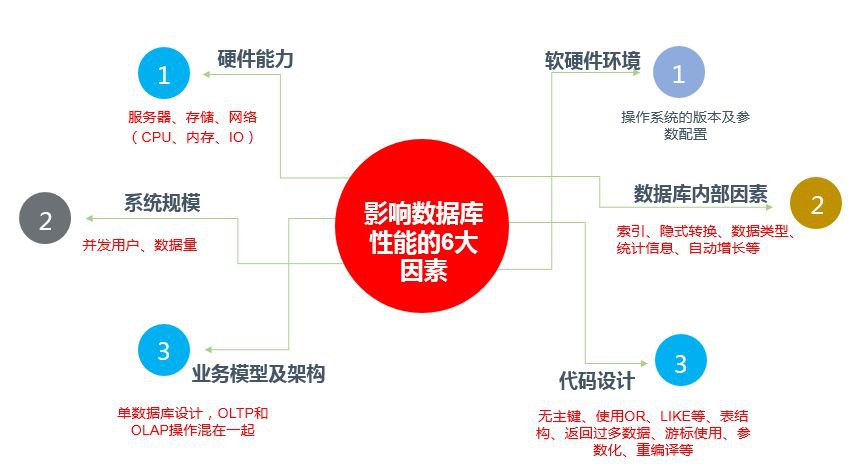
看完這個圖,你是不是對效能調優有了個基本的概念了.通常來講我們會依照下麵的順序來進行分析:
-
硬體能力
-
系統規模
-
資料庫內部因素
-
軟體環境
這4個的順序可以有所調整或者交換,但是對於系統的效能最佳化一定要從全域性出發。切勿一來就深入到某一個SQL陳述句的最佳化,因為可能你花費大量的時間吧。
一個SQL從20s 最佳化到1s,但是整個系統的卡慢仍然存在。
最後才是:
-
業務模型及架構
-
程式碼設計
實戰案例
不廢話了,開整開整,直接上乾貨。
時間:2018年1月某天
事件:某醫院客戶 下午4點 突然出現大面積的卡慢。整個系統出現嚴重問題,資訊中心電話打爆,醫院工程師手足無措。
萬幸的是我們給資料庫裝了‘攝像頭’,下麵就從監控錄影來看看發送了什麼。然後加以解決
硬體能力
CPU
在問題發生時間段內CPU使用率在20%以下,正常。

Memory
從下麵的影象顯示,記憶體使用正常。頁生命週期
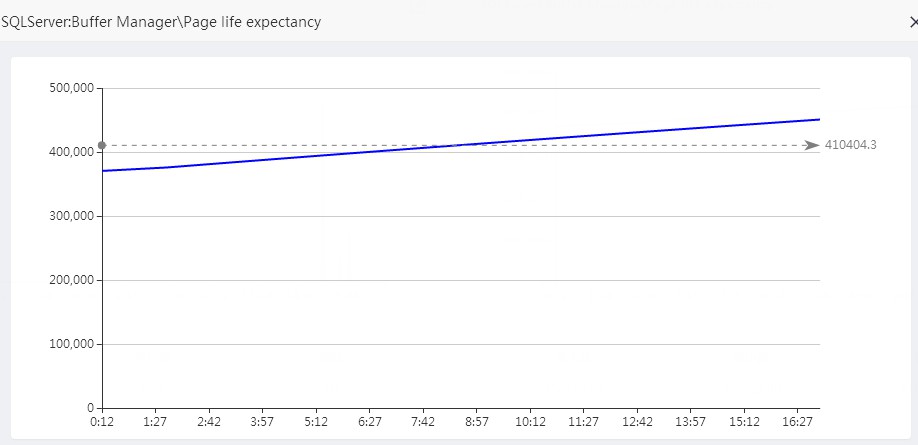
可用記憶體

IO
IO佇列平均值很低,15.48 左右有個瞬時的高點,可留意這段時間有沒有批次的寫入。

總的來看,硬體資源是足夠的。
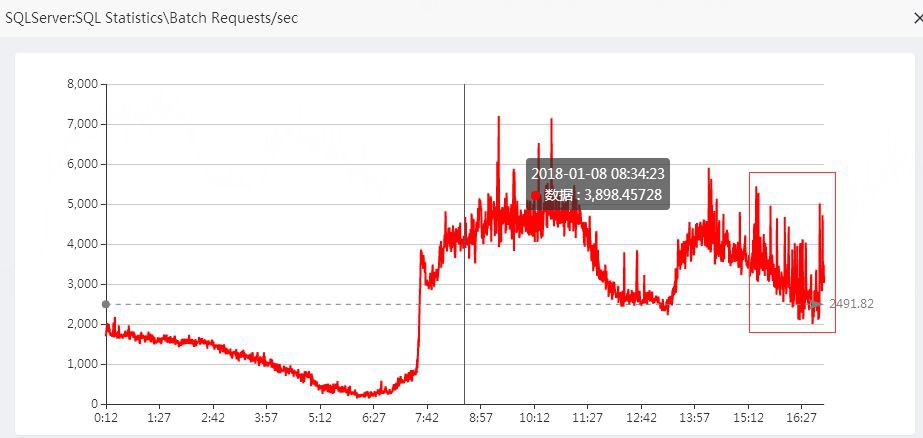
系統規模
問題發生時,每秒的批請求書並不是一個上升趨勢,反而有所下降。這是因為系統的擁堵,等待 ,影響了系統的吞吐量。
資料庫內部因素
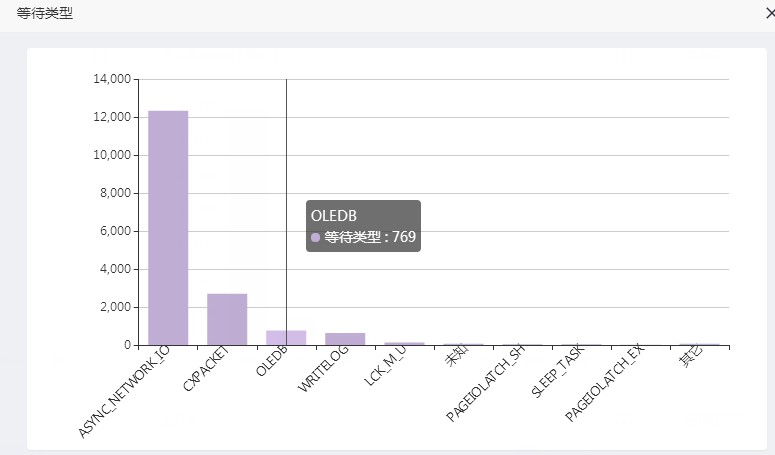
等待

慢陳述句

從會話和慢陳述句的趨勢圖可以看到,問題發生的時間和客戶描述完全吻合,我們可以斷定本身事故的確是慢在資料庫。
什麼導致的慢
檢查者個時間段執行中的陳述句,可以發現下午15.58左右,資料庫中開始出現越來越多的CMEMTHREAD等待。

一直到1900頁16.08分的時候,出現了最高達100個併發同時出現CMEMTHREAD等待

什麼是CMEMTHREAD等待
微軟官方的描述:
在任務正在等待執行緒安全的記憶體物件時發生。 當多個任務嘗試從同一個記憶體物件分配記憶體導致爭用時,等待時間可能會增加。
這個描述很晦澀,感覺還是完全不知道等待型別是怎麼回事,應該怎麼處理這類問題。
實際上,從官方描述來看是記憶體爭用的問題,但是實際上這個問題的關鍵在於多個任務的爭用,實際上是併發的執行的問題。
場景
-
出現在資料庫編譯或重編譯時,將即席執行計劃ad hoc plans 插入到計劃快取中的時候
-
NUMA架構下,記憶體物件是按照節點來分割槽的
記憶體物件有三種型別的(Global,Per Numa Node,Per CPU)。 SQL Server將允許對記憶體物件進行分段,以便只有同一節點或cpu上的執行緒具有相同的底層CMemObj,從而減少來自其他節點或cpu的執行緒互動,從而提高效能和可伸縮性。減少記憶體的併發爭用
SELECT
type, pages_in_bytes,
CASE
WHEN (0x20 = creation_options & 0x20) THEN 'Global PMO. Cannot be partitioned by CPU/NUMA Node. TF 8048 not applicable.'
WHEN (0x40 = creation_options & 0x40) THEN 'Partitioned by CPU.TF 8048 not applicable.'
WHEN (0x80 = creation_options & 0x80) THEN 'Partitioned by Node. Use TF 8048 to further partition by CPU'
ELSE 'UNKNOWN'
END
from sys.dm_os_memory_objects
order by pages_in_bytes desc
如果你發現,Partitioned by Node 的記憶體開銷是排在前面的,可以使用TRACE FLAG 8048來減少CMEMTHREAD等待.
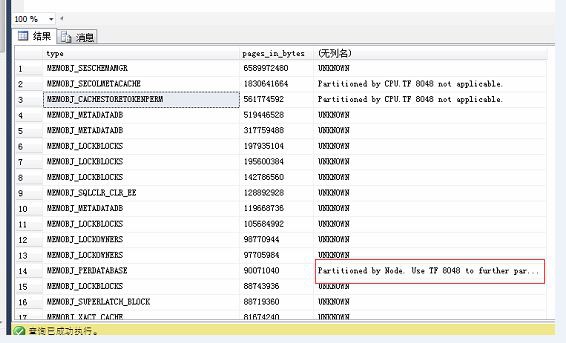
從圖中可以看到,客戶的 Partitioned by Node 是比較靠後的,排在14位。
-
補丁
這類場景是最常見的。如果在系統中發現出現大量的CMEMTHREAD等待,優先考慮資料庫是不是已經安裝最新的補丁
https://support.microsoft.com/en-us/help/2492381
https://support.microsoft.com/zh-cn/help/3074425/fix-cmemthread-waits-occur-when-you-execute-many-ad-hoc-queries-in-sql
軟硬體環境

目前資料庫的版本是 11.0.5556.0 而前面提到的補丁,安裝後的版本是:11.0.5623.0
程式碼設計
是什麼陳述句產生了等待?
都是類似下麵的陳述句,最高時,併發超過100.
SELECT
* INTO #Tmp from TB where 1=2
特點如下:
-
陳述句簡單 開銷都小於5不會產生並行
-
都採用了select into #temptable的形式
就像上面分析的一樣,CMEMTHREAD等待是一個併發問題,而不是一個記憶體問題。在其他方案行不通的時候,我們可以透過調整此類陳述句的寫法,減少CMEMTHREAD等待.
業務模型及架構
目前系統是單機執行的狀態,這其實是很少見的。存在少量OLAP 和OLTP業務混合的情況。後續我們會給客戶規劃 讀寫分離 或者負載均衡的解決方案。在
解決方案
安裝最新的補丁
至少需要安裝前面發的解決等待問題的FIX。建議是直接安裝到目前為止最新的2012 SP4補丁。
修改引數
optimize for ad hoc workloads 從0修改為1 。針對將即席執行計劃ad hoc plans 插入到計劃快取中的時候 場景,減少ad hoc 查詢佔用的記憶體。
增加TEMPDB資料檔案的個數
select * into #temptable 會產生大量的閂鎖爭用,防止在CMEMTHREAD 等待消除後,出現大量的pagelatch 閂鎖爭用。我經歷過很多案例,解決了前面的一個擁堵之後,
後面有產生了新的等待,導致效能更差了。請記住,最佳化是一個長期的,循序漸進的過程。
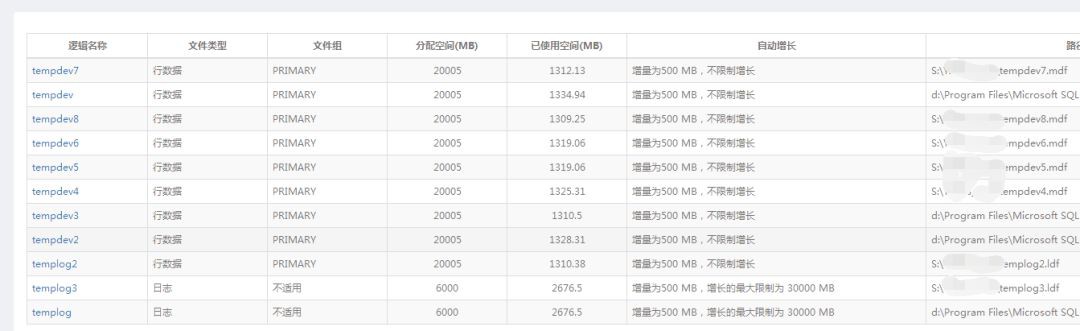
遷移TEMPDB資料檔案的位置
目前部分tempdb檔案放在S,一般分放在D盤。建議都遷移到S盤(儲存上面),增加tempdb的響應速度。如果可能的話,使用SSD來最大化tempdb的效能,將會是不錯的選擇。
最佳化程式的程式碼
修改程式碼通常都是放在最後面的,因為要牽涉的情況比較多。前面的手段80%的情況下,都可以解決問題。剩下的20%,我們需要,檢查程式中的邏輯,看看這些的陳述句都是什麼業務產生的。什麼條件會觸發這類業務.對應下麵類似的陳述句都使用儲存過程,或者引數化後的方式,減少編譯和重編譯的次數。另外此類陳述句都會併發建立臨時表,可能透過調整tempdb的設定,加快此類陳述句的執行速度,減少同一時間此類陳述句的併發數量。
最佳化效果
經過前面的幾個最佳化手段,第二天開始,沒有再出現過一次CMEMTHREAD的等待。
等待
慢陳述句
總結
透過這篇檔案你應該已經完全學會了資料庫效能調優的思想。他告訴了我們出現問題時,怎麼動手一步一步的排查問題,就像剝洋蔥一樣一層一層的剝開。
參考
https://blogs.msdn.microsoft.com/psssql/2012/12/20/how-it-works-cmemthread-and-debugging-them/
●編號421,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
