(點選上方公號,快速關註我們)
英文:Ioannis Kalfas,轉自:資料派(ID:datapi),翻譯:笪潔瓊
我們的大腦很奇特。它是一個神奇的器官,已經進化了數百萬年,不斷變化和調整來應對遇到的各種刺激和條件,它看起來就像一袋黏糊糊的物質,在我們的頭腦中以不同的方式組建起來。這個器官和組成它的數十億個神經元,是我們理解智力以及智力是如何產生的最佳研究物件。然而我們還有另一個選擇,那就是自己創造(人工)智慧,然後闡述我們自己的創造力。

圖一:我們的大腦幫助我們創造智慧
近年來,我們離創造智慧機器又近了一步。至少在(計算機)視覺方面,我們現在擁有能夠從數千個類別中精確地分類影象的系統。這要歸功於摺積神經網路(CNN)(以及用於訓練它們的圖形處理單元的效率)。如果每個類別都有足夠的影象來訓練,CNNs可以學會調整裡面的人造神經元的權重,這樣,經過訓練,CNNs就能對之前從未見過的影象進行分類。
有趣的是,CNNs的靈感來自於我們大腦的視覺系統,為了做到這一點(在這裡,這裡和這裡(連結)幸好CNNs與神經科學關係密切,我有機會從神經生理學的角度(在魯汶大學)來開展研究,發揮我對人工神經網路的熱情和好奇心去瞭解大腦構造。

圖二:一個典型的CNN的架構
在這篇部落格文章中,我們將透過摺積神經網路層的人工神經元來模擬大腦視覺區域的神經元。透過“建模”,我指的是函式的建立,它與生物神經元的輸入相同,並可以產生相似的輸出。
def model_neuron(image):
return realistic_response
在我們的舉例中,輸入是在空白背景下的剪影(黑色填充的形狀)的影象。

圖三:示例影象顯示為生物神經元(沒有綠色框架)
來自生物神經元的資料是透過電生理學實驗收集的。在這些實驗中,我們透過顯示器對一隻猴子顯示影象(輸入刺激),併在猴子大腦中插入一個電極,記錄神經元的活動或反應。
這裡說的活動或反應,通常指的是神經元每單位時間產生的動作電位(或峰值)的數量(如響應=30峰值/秒)。

圖四:神經元很興奮地看著這個…
在我們的例子中,資料是從下顳葉皮層收集的,這是我們視覺系統的“後期”處理階段之一,更確切地說,是來自大腦的顳上溝(MSB)部分。
這些小區域中的神經元,正如你猜到的那樣,對身體形狀的影象的反應比其他類別的影象(如面孔)要敏感。當一個身體形狀出現在影象中時,它們會感到興奮,即使它們並沒有頭腦!
基本操作
讓我們繼續討論基本操作部分的技術細節,同時需要不能讓非技術讀者感到厭煩。
在這裡,我們將研究單個神經元的資料,稱為“C65b”(不要問我為什麼,它就叫這個名字)。
這個神經元被呈現出來(透過它的主人的眼睛,也就是一隻叫埃舍爾的獼猴),有605張影象,圖中有黑色形狀和白色背景。有些形狀是隨機的,有些形狀像動物或人類的身體,其他形狀就像其他類別的剪影(更多細節請閱讀我們論文的“材料和方法”)。
Materials and Methods:
http://www.eneuro.org/content/4/3/ENEURO.0113-17.2017
這些影象被調整以匹配我們選擇的CNN的輸入大小(例如224×224)。沒有對它們進行進一步的預處理。
對於每一個影象(刺激),在實驗室實驗中,我們會記錄單獨的發射速率(峰值/秒)。我們的標的是找出是否可以使用來自CNN層的人造神經元來預測神經元對每個影象的實際生物反應(即回歸問題)。我們該如何使用人工神經元?具體做法是,我們將給CNN提供同樣的影象,並從每一層提取它們的特徵。
-
(可選的)摺積神經網路的背景
讓我們來詳細解釋一下CNNs的工作原理,以及在案例中的“特徵”是什麼。
正如你可能已經知道的,CNN的層由成千上萬的人工神經元組成,它們被分成數百個特徵地圖(見圖二)。每一個神經元都被分配了一些數學運算來執行,這個操作涉及到神經元的輸入和它的權重,也就是神經元與它的輸入的連線有多強。
例如,第一個摺積層中的一個神經元,在它的權重和輸入影象的一個小視窗之間執行摺積運算(如圖二所示。基本上是兩個2D矩陣之間的元素乘法,然後是加上所有的)。這個想法是,如果神經元檢測到一個類似它的權重,透過訓練網路,我們實際上是在改變它們的權重,這樣它們看起來就像是輸入的樣式。
因此,您可以將神經元看作是一個樣式(或特徵)檢測器,檢查它所看到的區域,包含一些熟悉的東西的權重樣式,並輸出一個“分數”來表示這種熟悉程度。有趣的是神經元的對映功能將具有相同的權重,所以基本上每個特徵需要掃描整個輸入影象來尋找一個特定的樣式(這顯然有助於訓練權重時的計算和更新,因為你不需要更新每個神經元)。
在任何平均池層中,一個神經元接受上一層的一個小視窗的平均值。因此,一個最大池化層的神經元只是簡單獲取那個小視窗的最大值。這裡的想法是,即使你把輸入影象移到一邊,或者旋轉,或者縮放它,池中的神經元仍然會檢測到相似的樣式。這使得CNNs能夠允許這些影象轉換。
所以,透過“特徵”,我們指的是一堆數字,這些數字是我們神經元的輸出(或“樣式檢測器”)。
“啟用”一詞也可以與特徵互換使用。從神經科學的角度來看,這更容易理解,因為它指的是一個神經元在輸入刺激下被“啟用”的程度。我不會詳細講CNNs的工作方式,因為網上有很多很棒的資源可以很好地解釋這個問題(例如,卡洛西的課程,C. Olah的部落格,Adit Deshpande的部落格,hackernoon等等)。
Karpathy’s course:
http://cs231n.github.io/convolutional-networks/
C. Olah’s blog:
http://colah.github.io/posts/2014-07-Conv-Nets-Modular/
Adit Deshpande’s blog:
https://adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/
hackernoon article:
https://hackernoon.com/visualizing-parts-of-convolutional-neural-networks-using-keras-and-cats-5cc01b214e59
-
數學建模
我們將使用CNN層的VGG-16。像任何回歸問題一樣,我們需要一個預測矩陣X和一個標的矩陣y。在我們的舉例中,X將是一個2D矩陣,其中每一行對應一個輸入影象,每一列對應一個特定的CNN層神經元的啟用。我們可以考慮整個CNN的神經元,建立一個巨大的X矩陣,但那將是計算量密集型的,它不會讓我們知道層之間的差異。
因此,我們將為每個CNN層建立一個單獨的回歸設定,其中X將是nr。
輸入影象的nr,CNN圖層單元就會啟用。
因此,對於VGG16的最後一層(fc8由1000單元組成),我們的X矩陣將是605×1000。
Y矩陣將是長度為605的一維向量,它將包含生物細胞的響應(峰值)到我們的每一個輸入影象(刺激)。

圖五:我們的回歸問題中X和Y矩陣
請註意,這些影象是黑-白(二進位制的),但是為了將它們輸入到CNN,我們複製它們兩次以得到一個3D捲(bnw影象3次)。要瞭解它們是如何與輸入互動的,請從Karpathy的CS231n課程中瞭解這個令人難以置信的視覺化(同時也要閱讀其他的部落格以獲得更多的細節)。
Karpathy CS231n:
https://cs231n.github.io/assets/conv-demo/index.html
直觀地說,到目前為止我們所做的是把一隻猴子的生物神經元更換成出現在CNN層中的人工神經元。我們建立了一個人工的方式來表示相同的函式作為神經元C65b,我們需要找到一種有效的數學方法得到Y給X。接下來,我們將討論建模選項以及為什麼它不是一個簡單的線性多重回歸可以解決的問題。
基本歷史:CNNs和神經科學的前身
在前文中,我提到CNNs是受神經科學的啟發。為了讓你知道為什麼會這樣,我將提供在CNNs出現之前的一個舊模型例子,它被用於視覺神經科學。
CNNs的神經科學靈感來自於它們處理和表示資訊的方式。
特別是,摺積神經和最大池化的操作,並不是視覺計算的外來概念。
它們也被用於更古老的、受生物學啟發的HMAX模型,它試圖將大腦皮層的視覺處理解釋為“越來越複雜的現象的層次”。
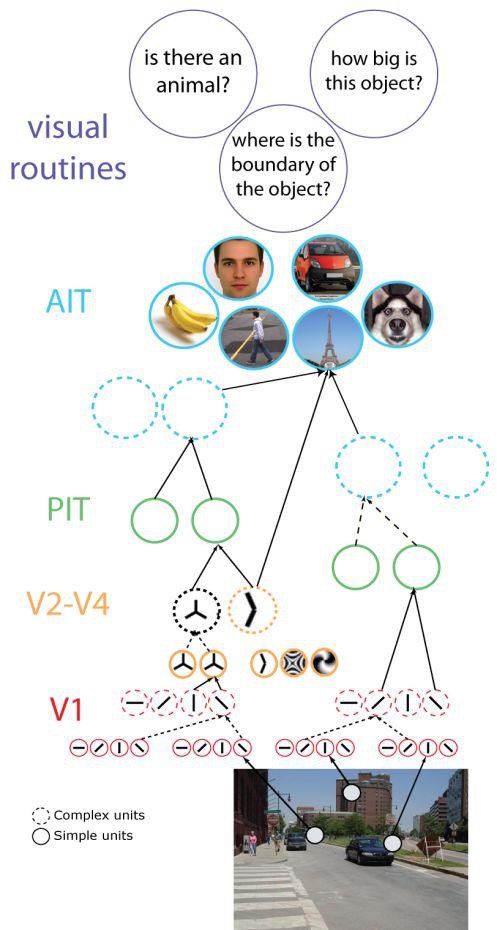
圖六:資訊透過我們的眼睛進入大腦,再透過大腦區域的神經元傳遞
在日益複雜的過程中被消化,從簡單的視覺表現如邊緣、線條、曲線等開始,逐漸進行更複雜的表示,例如,面部或全身。這將使我們瞭解更多關於觀察物件的資訊。
在HMAX中,摺積運算是用預先定義的權重集(Gabor濾波器)來表示的,它們代表了基本的4個方向。因此,第一個HMAX層(S1)的神經元(或“樣式檢測器”),在4個方向上尋找類似於邊緣的特徵。這發生在10個不同的影象大小中。然後,在下一個HMAX層,稱為C1,這些操作的結果被合用(與CNNs的最大池化操作相同)。
接下來是對集合響應(S2層)和另一個池操作(C2層)的取樣,它給出了HMAX模型的最終輸出向量(見下麵的圖七)。

圖七:HMAX模型架構
想要更完整地瞭解視覺皮層模型的歷史,請閱讀這篇非常有結構的學術百科全書:
http://www.scholarpedia.org/article/Models_of_visual_cortex#Riesenhuber1999
後記
免責宣告:這裡提供了所有資料(儘管我懷疑我提交的任何“資料”都屬於魯汶大學)關於這個主題的更多細節你可以參考eNeuro的出版物:
http://www.eneuro.org/content/4/3/ENEURO.0113-17.2017
【關於投稿】
如果大家有原創好文投稿,請直接給公號傳送留言。
① 留言格式:
【投稿】+《 文章標題》+ 文章連結
② 示例:
【投稿】《不要自稱是程式員,我十多年的 IT 職場總結》:http://blog.jobbole.com/94148/
③ 最後請附上您的個人簡介哈~
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能
