英文:ben stopford
譯者:伯樂線上-喬永琪
網址:http://blog.jobbole.com/88453/
點選“閱讀原文”可檢視本文網頁版
譯註:本文是作者今年在 Progscon & JAX Finance 大會上的同名主題演講《Elements of Scale: Composing and Scaling Data Platforms》。
@何_登成 的推薦語:此文很長,但長而不臭,而且配圖非常Q。作者以簡潔易懂的文字,將資料庫設計中應該考慮的儲存、並行、架構等問題做了詳細的闡述。
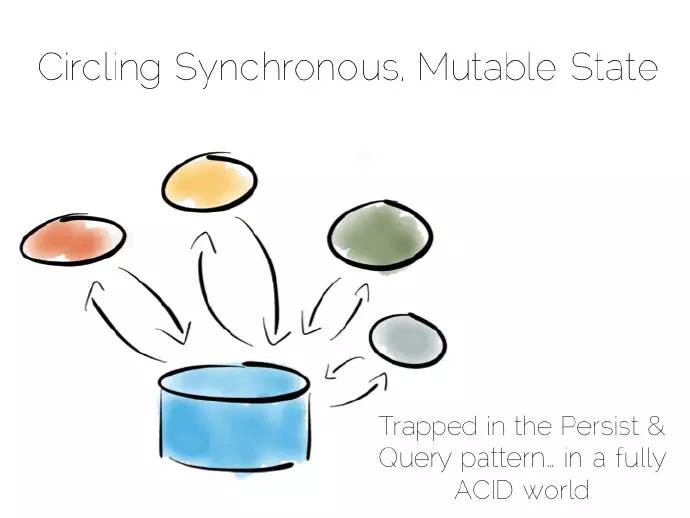
作為軟體工程師,不可避免地受到周圍計算機工具的影響,語言、框架、甚至執行過程都會影響我們構建的軟體。
資料庫亦如此,基於一種特殊的方式,不可避免地影響到我們對應用程式中易變和共享狀態的處理。
過去的十多年,我們採用不同的方式去探尋這個世界。採用不同理念的一小眾開源專案,它們不斷成長,你中有我,我中有你。平臺集成了這些工具,每個控制元件通常都能提高某些基礎硬體或者系統效能。結果是平臺無法透過任何單一的工具解決某些問題,不是太過笨重,就是侷限於某一特定部分。
因此當今資料平臺多種多樣,從簡單的快取層、多語言持久化層到整個整合資料管道,針對多種特定需求的多種解決方案。在某些方面,確實有不錯的表現。
因此本對話的目的就是解釋一些流行的方式方法如何發揮作用,為什麼會有如此表現。我們先來考慮組成它們的基本元素,這樣便於在後續的討論中對這些認識通盤地考慮。
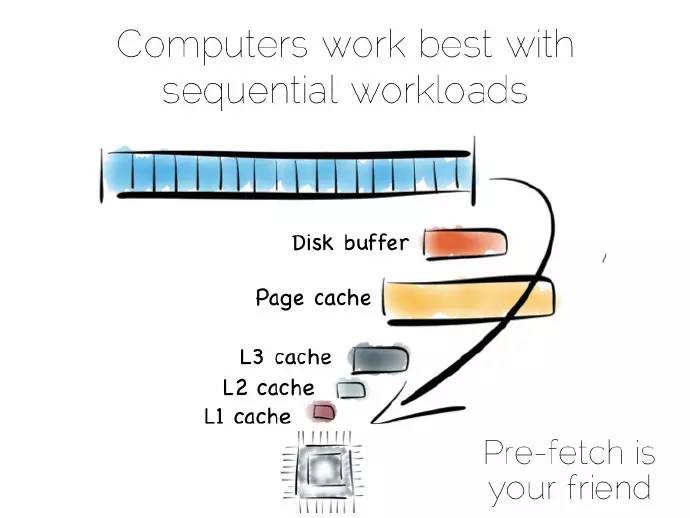
從某種抽象的角度看,當我們處理資料時,實際上就是對其進行區域性性(locality)處理,區域性性到CPU、區域性性到我們需要的其它資料。有序地獲取資料是其中很重要的部分,計算機很擅長序列化的操作,這些操作是可以預測的。
(譯者註:區域性性是計算機中一種預測行為,透過快取、記憶體中預取指令、處理器管道分支預測等技術來提高效能;更多參見《作業系統精髓與設計原理》。)
若是有序地從硬碟中獲取資料,資料會預獲取存入硬碟快取、頁快取、以及不同層級的CPU快取中,這可以極大地提升效能。但這對隨機資料定址意義不大,這些資料存於主記憶體、硬碟或者網路中。實際上,預獲取反倒會拉低隨機負載能力:不論是各種快取或是前端匯流排,充滿了不太會被用到的資料。

硬碟通常被認為效能稍低,而主記憶體稍快些。這種認識不見得一直是對的,隨機和有序主記憶體負載之間相差一兩個數量級。用某種語言管理記憶體,事情往往會變得更加糟糕。
從硬碟有序獲取的資料流效能確實好過隨機定址主記憶體,或許硬碟並不像我們想的那樣跟烏龜似的,至少在有序獲取的情況不會很慢。固態盤(SSD),特別是採用PCIe介面,正如它們顯示不同的權衡,將事情複雜化。但採用這兩種獲取樣式帶來的快取收益是不變的。
譯者註:資料流就是大量連續到達的、潛在無限的有序資料序列,這些資料按順序存取並被讀取一次或有限次。
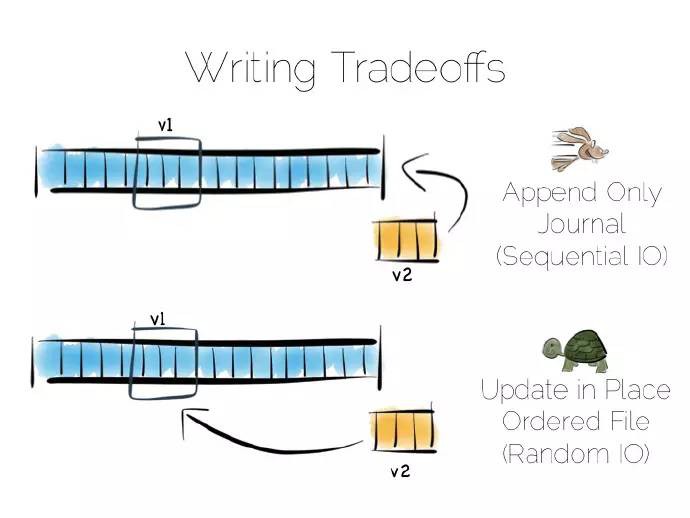
假設我們要建立一個簡單的資料庫,首先從基礎部分檔案開始。

保持有序讀和寫,檔案在硬體上會表現地很好。我們可以將寫入的資料放入檔案的末尾,可以透過掃面整個檔案進行資料讀取。任何我們希望的處理過程可以隨著資料流穿過CPU而成真,比如過濾,聚合、甚至做一些更複雜的操作,總之非常完美。
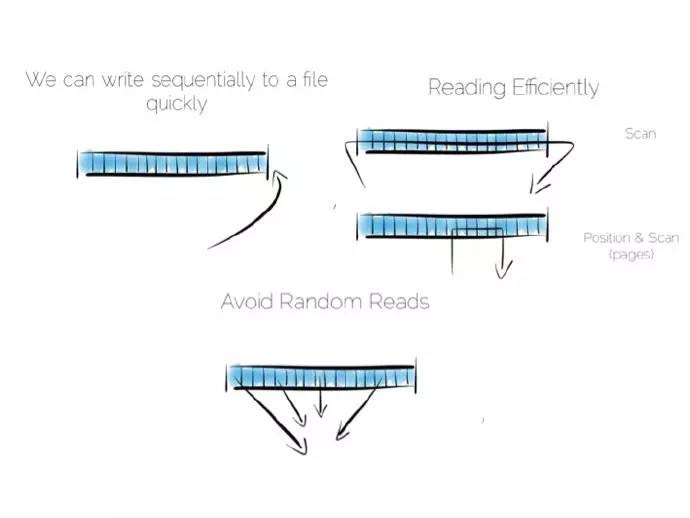
倘如資料發生諸如更新這樣的變化會怎樣?
我們有多個選擇,在某個位置更新這個值。我們需要利用固定長度的欄位,在我們淺顯的思想實驗中這是沒有問題的。不過在某個位置更新資料意味著隨機輸入輸出流(IO),這會影響效能。
替代的辦法是將更新值放置在檔案的末尾,在讀取值時對過期的資料進行處理。
我們第一次做出權衡,將“日記”或者“日誌”放在檔案末尾,就能保證有序獲取進而提高效能。另外倘若某處需要更新資料,可以實現每秒300次左右的讀取,前提是更新資料刷入底層介質中。
實際上完整的讀取檔案是很慢的,獲取十億位元組(GB)資料,最好的硬碟也需要花費數秒,這是一個資料庫全表掃描所花費的時間。
我們時常只需要一些特定的資料,比如名為“bob”的客戶,這時掃描整個檔案就不妥當,我們需要一個索引。
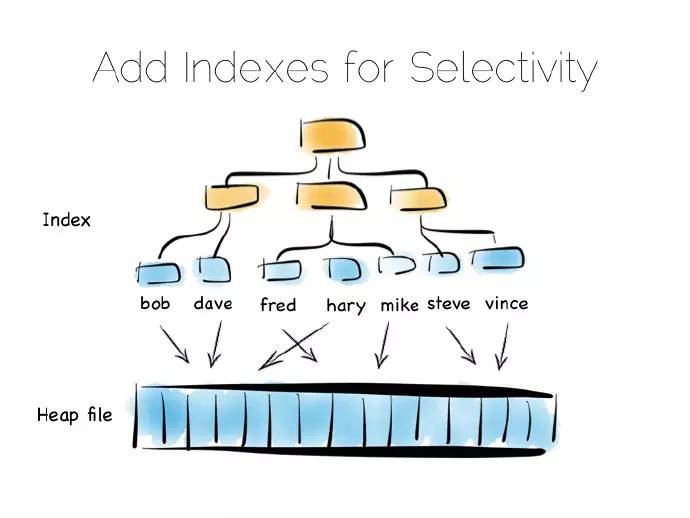
我們可用許多不同型別的索引,最簡單的一種是固定長度的有序陣列,比如本例中的客戶名,和對應的偏移量一起存放在一個堆檔案中。有序陣列可以進行二進位制搜尋查詢。同樣,我們可以用樹結構、點陣圖索引、雜湊索引、字典索引等。這裡是一個樹的結構圖。
索引就像是在資料中添加了一個總覽結構,值是有序排放的,這樣我們就能快速獲取我們想要讀取的資料。但總覽結構有個問題,資料進來時需要隨機寫。因此理想的、寫最佳化僅僅追加檔案;考慮到寫會打散檔案系統,這會使一切變慢。
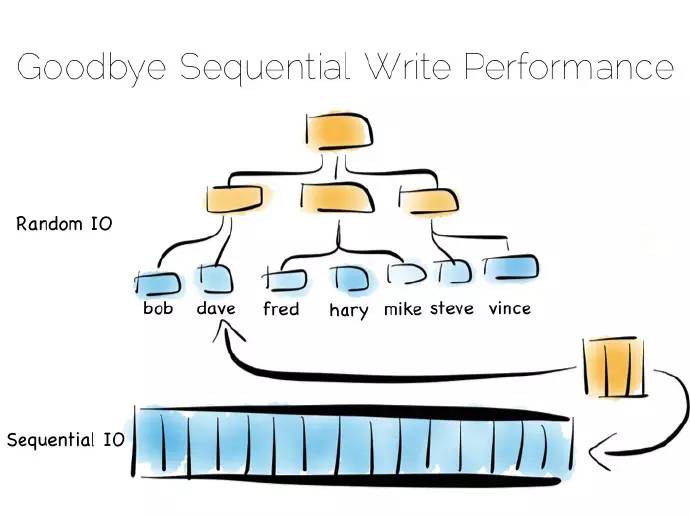
如果你將許多索引放入一個資料庫表中,那你一定熟悉這個問題。假定我們使用的機械盤,用這種方式維護某個索引的硬碟完整性,速度大約慢1000倍。
幸運的是,這裡有幾種解決方案。這裡我們討論三種,它們都是一些極端地例子。在現實世界中,遠沒有這麼複雜,但在考慮海量儲存時這些概念會特別有用。
譯者加:
- 第一種記憶體對映檔案
- 第二種較小的索引集合,採用元索引或者布隆過濾演演算法(Bloom Filter)做一些最佳化
- 第三種簡單匹配演演算法(brute force)又叫面向列(Column Oriented)
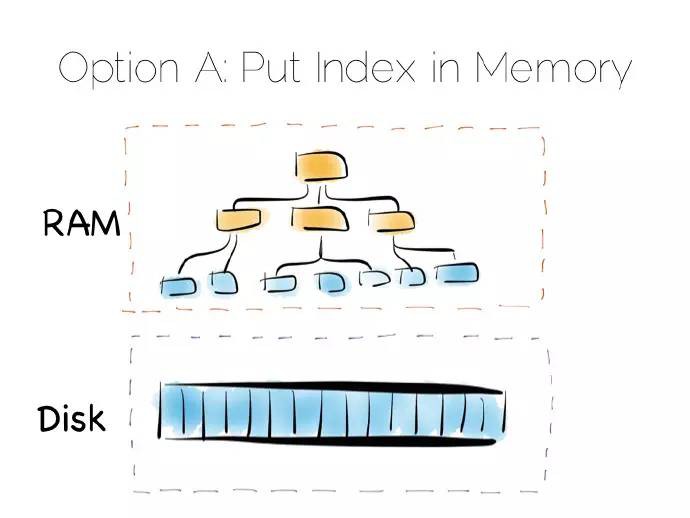
第一種方案是將索引放入主記憶體,隨機寫問題分隔到隨機儲儲存存器(RAM),堆檔案依舊在硬碟中。
這是一種簡單但行之有效的方案,可以解決我們隨機寫的問題。這種方式在許多資料庫中已得到應用,比如MongoDB、Cassandra、Riak、以及其他採用此最佳化型別的資料庫,它們常常用到記憶體對映檔案。
譯者註:記憶體對映檔案是虛擬記憶體單個分段,可以與檔案或者類檔案資源的某部分建立直接位元組對位元組的關聯,即檔案中的資料存放位置在記憶體中有對應的地址空間,這時對檔案的讀寫可以直接用指標來做,而不需要read/write函式,處理大檔案時可以顯著提高輸入輸出流(IO)效能。
倘若資料量遠超主記憶體,這種策略就失效了。特別是存在大量小的物件時,問題特別顯眼;索引增長很大,最後儲存越過了可用主記憶體的容量。多數情況下,這樣做是沒有問題的,但如果存在海量資料,這樣做就會成為一種負擔。
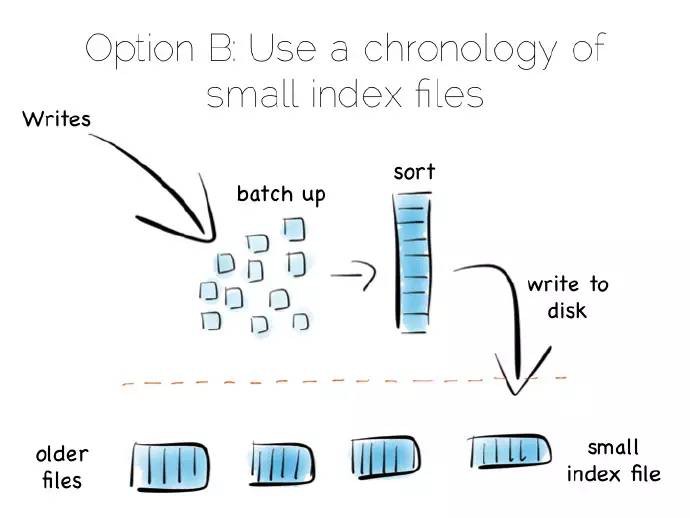
一種流行的方式拋開單個的“總覽”索引,轉而採用相對較小的索引集合。
這是一個簡單的理念:資料進來,我們批次地將其寫入主記憶體。一旦記憶體資料足夠多,比如達到MB,我們就對它們進行排序,而後將它們作為單個小的索引寫入硬碟中。最後得到的是一個小的、由不變索引檔案組成的年表。
那麼這樣做的好處是?這些不變的檔案集合被有序地流化處理,這樣就能快速地寫,最重要的是無需將整個索引載入入記憶體中。真棒!
當然它也有一個缺點,當讀操作時需要詢問非常多的小索引。我們將隨機IO(RandomIO)寫問題變為讀問題。不過這確實一個很好的權衡策略,而且隨機讀比隨機寫更容易最佳化。
儲存一個小的元索引(meta-index)在記憶體中或者採用布隆過濾演演算法(Bloom Filter),提供一種低記憶體方式,評估單個索引檔案在讀操作中是否需要被詢問。即使保持快速地、有序化寫操作,這種方式的讀操作效能幾乎可以和單個總覽索引相媲美。
實際開發中,偶爾也需要清理孤子更新,但它有序讀和寫確實不錯。
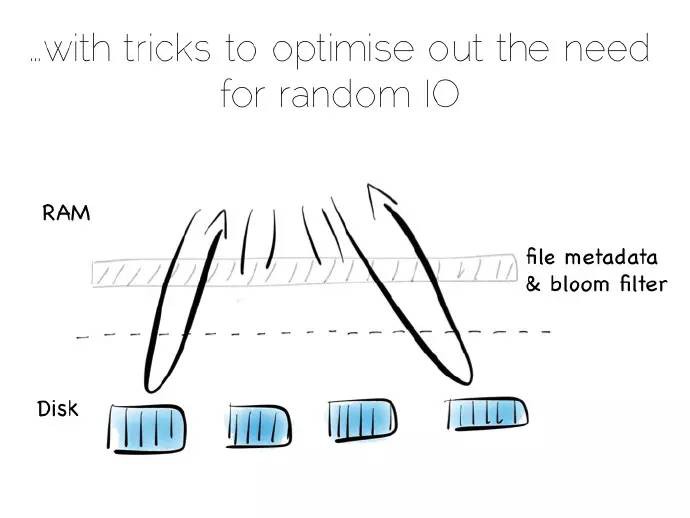
我們建立的這個結構稱作日誌結構合併樹(Log Structured Merge Tree),這種儲存方式在大資料工具中應用較大,如HBase、Cassandra、谷歌的BigTable等,它能用相對較小的記憶體開銷平衡寫、讀效能。

將索引儲存在記憶體中,或者利用諸如日誌結構合併樹(Log Structured Merge Tree)這樣的寫最佳化索引結構,繞開“隨機寫懲罰”(random-write penalty)。這是第三種方案為純粹的簡單匹配演演算法(Pure brute force)。
回到開始的檔案例子,完整地讀取它。如何處理檔案中的資料,可以有許多選擇。簡單匹配演演算法(brute force)透過列而非行來儲存資料,這種方法叫做面向列。
需要註意的是真實的列儲存及其遵循的大表樣式(Big Table pattern)之間存在一種不好的命名術語衝突。儘管它們有一些相似的地方,事實上它們是不同的,所以將它們視為不同的事情是一件明智的。
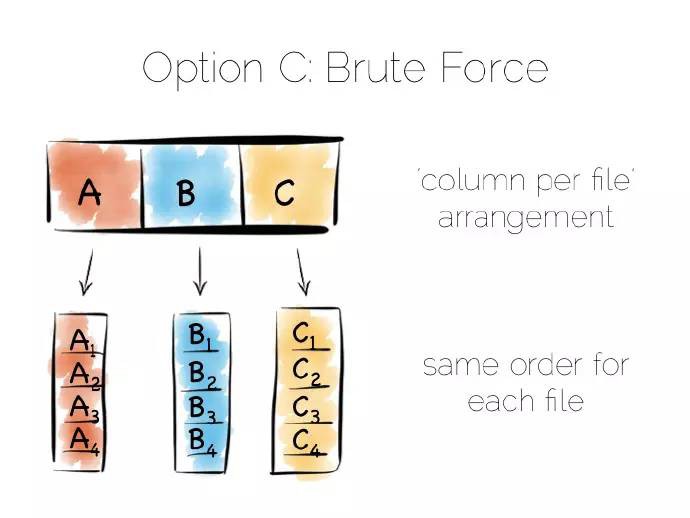
面向列是一種簡單的理念,和行儲存資料不同,透過列分割每一行,將資料追加到單個檔案末尾。接著在每個單獨的檔案中儲存每一列,一旦需要只需讀取需要的列。
這樣可以確保檔案的含有相同的序列,即每個列檔案的第N行含有相同的地址或者偏移量。這個很重要,在某一時刻讀取多列,來服務一個單一的查詢。意味著“連線(joining)”列速度飛快,倘若所有的列含有相同的序列,我們就能在一個緊湊的迴圈中這麼做,此迴圈有很好快取和CPU利用率。許多實現大量使用向量( vectorisation)進一步最佳化簡單連線和過濾操作吞吐量。
寫操作可以提高只在檔案末尾追加( being append-only)效能。不利的地方是很多檔案需要更新時,檔案的每個列需要單獨寫入資料庫。最常見的解決方案是採用類似日誌結構合併(LSM)方式,進行批次化的寫操作。許多列型別的資料庫透過給表新增一個完整的序列來提升讀的效能。
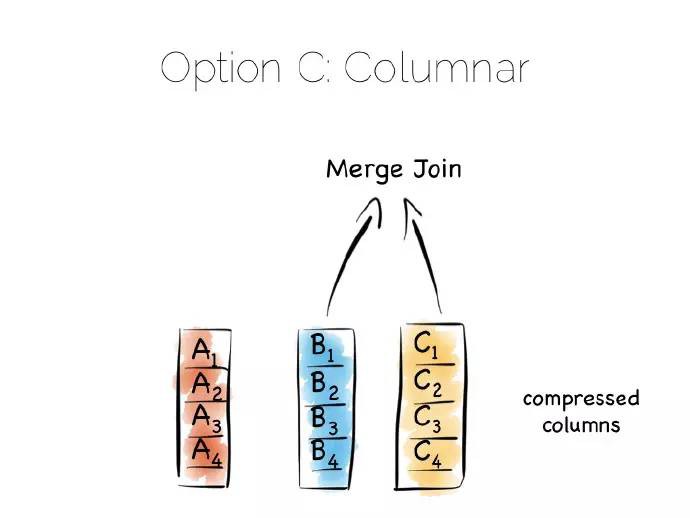
透過列分割資料可以極大地減少從硬碟中讀取的資料量,只要查詢操作在所有的列的子集中。
除此之外,單獨列中的資料通常可以很好的壓縮。可以利用列資料型別優勢去壓縮,特別是在我們熟悉列的資料型別時。這意味著我們能利用有效的、低成本的編碼方式,比如行程長度編碼、delta、位組合(bit-packed)等。對一些編碼來說,謂詞可以直接用來做壓縮流。
一種簡單匹配演演算法(brute force)特別適合大規模掃描操作,諸如平均值、最大值、最小值、分組等聚類函式就是這方面的典型。
這和先前提到的“堆檔案和索引(‘heap file & index)”方式不同,很好的理解這一點可以問自己,諸如此類的列方式和每一個欄位帶有索引的“堆和索引”方式有什麼不同?
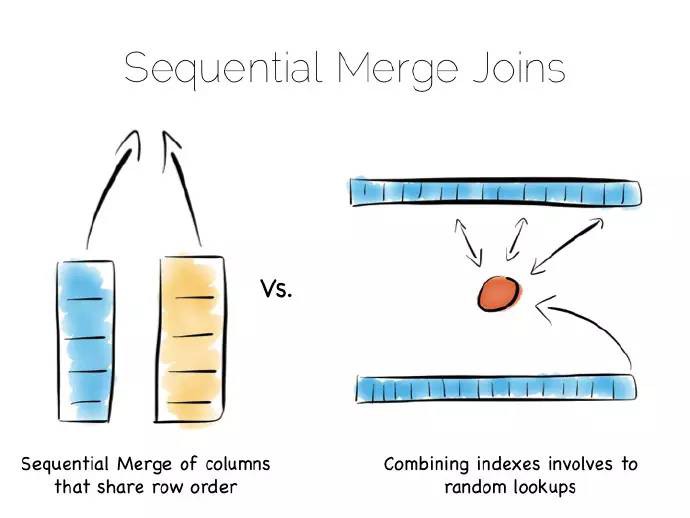
問題的關鍵是索引檔案序列:多路查詢樹(Btree)等會依據檢索的欄位排序,兩次檢索的資料連線一端涉及流操作,另一端第二個索引位置進行檢索隨機讀取。平衡樹總體上說效率低於包含兩個相同序列索引列連線,我們再一次提高了序列化訪問。
譯者註:結論是平衡樹連線效能不如兩個相同序列索引列連線

我們都想將最好的技術作為資料平臺控制元件,提升其中的某種核心功能,勝任一組特定的負載。
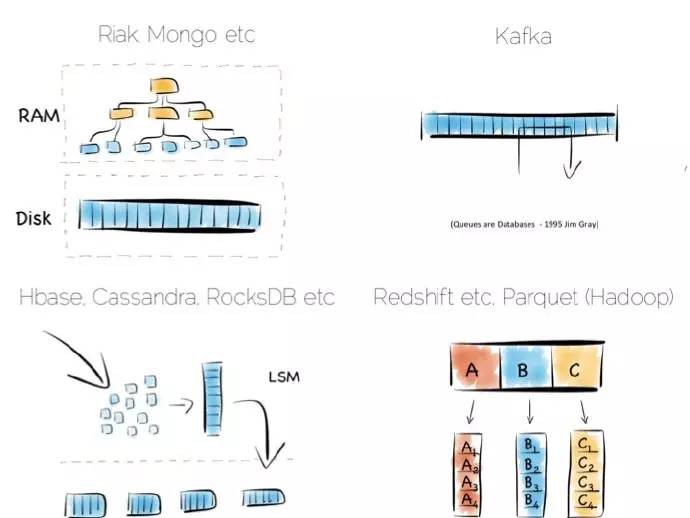
將索引存於記憶體而非堆檔案為叢多非關係型資料庫(NoSQL)所喜愛,比如Riak、Couchbase或者Mongodb,甚至一些關係型資料庫,這種簡單的模型效果不錯。
設計用來處理海量資料集的工具樂意採用LSM方式,這樣可以快速獲取資料,得到基於硬碟結構 讀一樣好的效能。HBase、 Cassandra、RocksDB、 LevelDB 甚至Mongo現在也支援這種方式。
每個檔案的列(Column-per-file)引擎常用於資料庫大規模並行處理(MPP),比如Redshift或者Vertica,以及Hadoop stack中的Parquet。這些資料引擎最大的問題是需要大的遍歷,聚合是這些工具最重要的特質。
諸如卡夫卡(Kafka)採用一個簡單的、基於硬體的高效訊息規範。訊息可以簡單地追加到檔案的末尾,或者從預定的偏移量處讀取。可以從某個偏移量讀取訊息,來來回回,你可以從上次結束的偏移量處讀取。看得出是很不錯的有序輸入輸出(IO)。
這和多數面向訊息的中介軟體不同,JMS(Java訊息服務)和AMQP(高階訊息佇列協議)說明檔案需要額外的索引,來管理選擇器和會話訊息。這意味著它們結束某個行為的方式更像資料庫,而非某個檔案。著名的論述是1995年Jim Gray發表的佇列就是資料庫(Queue’s are Databases).
可見所有的方式都需要這樣那樣的權衡,作為一種分散式手段,使事情變得簡單、硬體更加使用者友好。
我們分析了儲存引擎的一些核心方法,其實只是做了一些簡要說明,現實世界這些是要複雜的多,不過概念確實是很有用的。分散式資料平臺不僅僅是一個儲存引擎,還需要考慮並行。

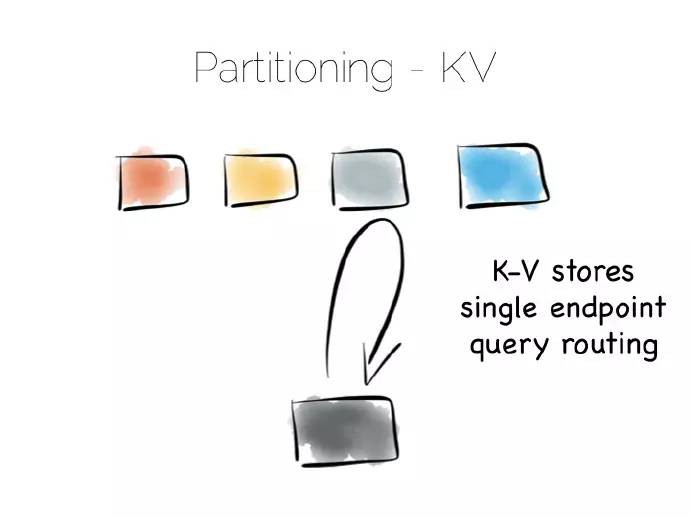
對於橫跨多臺計算機的分散式資料我們需要考慮兩個核心點,分割槽(partition)和複製(replication)。分割槽有時指的是分庫分表(sharding),在隨機讀取和簡單匹配工作負載(brute force workloads)表現不俗。
如果是基於雜湊的分割槽模型,藉助雜湊函式,資料就能均攤到一組機器上(譯者註:理想的結果是這樣的)。同雜湊表工作方式相似,每個桶(bucket)盛放某個機器節點。
這樣透過雜湊函式,直接訪問包含此資料的機器讀取來資料。這是一種很經典的分散式樣式,也是唯一一種隨著客戶端請求增加呈現線性分佈的樣式(譯者註:簡單點說就是均攤)。請求隔離到單臺計算機上,由叢集中的單臺計算機為其服務。
利用分割槽提供並行批次計算,比如聚合函式或者諸如聚眾或者機器學習的複雜演演算法。最大的不同是所有的計算機在同一時刻採用廣播的方式,在很短的時間採用分治的策略解決大規模計算問題。
批次處理系統很好地處理大規模問題,但在執行過程中少有併發,容易耗盡叢集資源。
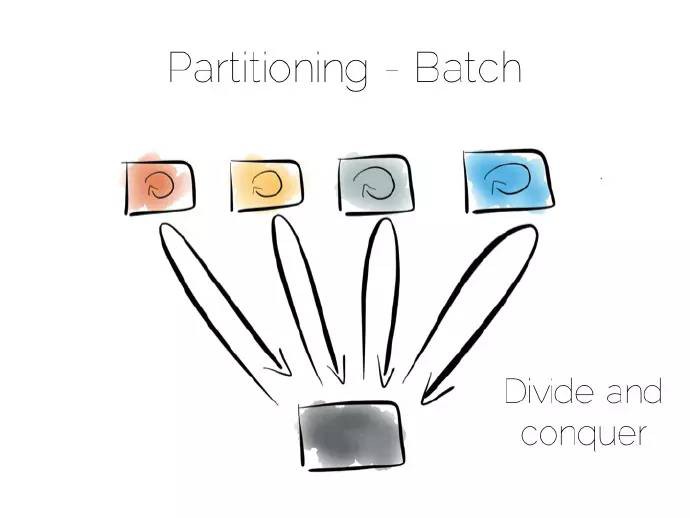
兩個極端且特別簡單的方式:一端直接訪問,另一端分治地進行廣播。需要註意的是終端之間的中間地帶,最好的例子就是非關係型資料庫(NoSQL)中跨越多臺計算機的二級索引。
二級索引有別於主鍵索引,這就意味著資料分割槽不再借助索引中的值。不再使用雜湊函式直接分發,而是廣播請求給所有的計算機。這會制約併發,任何一個節點與每一個請求都有關。
也是這個原因許多鍵值儲存不願採用二級索引,即使它的應用很廣泛,Hbase和Voldemort就是如此。不過諸如MongoDb、Cassandra、Riak等資料庫採用二級索引,不管咋說二級索引還是蠻有用的。但理解它們在整個系統併發的影響還是很重要的。
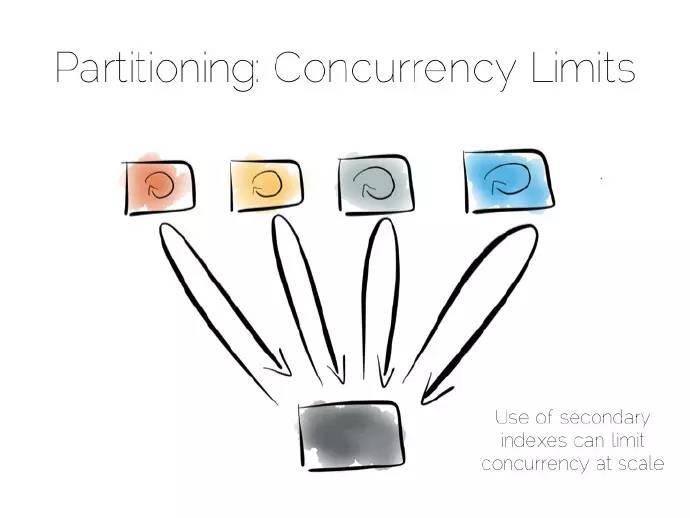
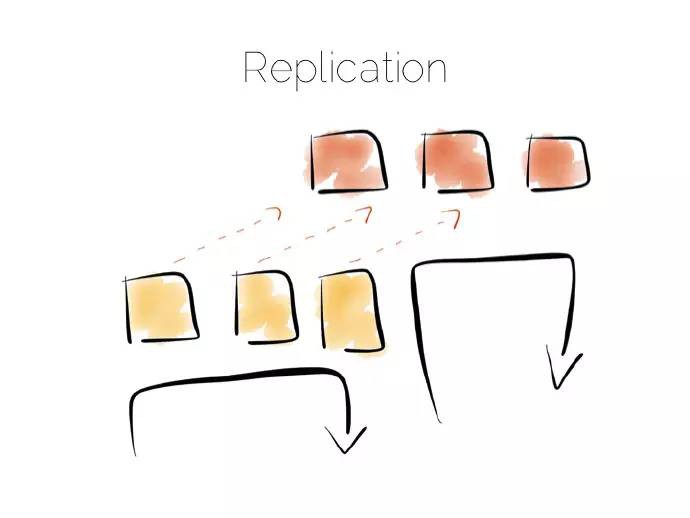
複製解決併發瓶頸,或許你熟悉備份,不論是非同步到從伺服器,還是複製到諸如Mongo或者Cassandra這樣的NoSQL儲存中。
實際上備份是不可見的(僅僅用於恢復)、只讀(增加併發量)、或者讀寫(增加網路分割槽下的可用性),選擇哪種方式需要從系統的一致性出發做出權衡。這是CAP(Consistency、Availability、Partition-Tolerance)理論的簡單應用,當然CAP理論遠非我們想象中的那麼簡單。
譯者註:網路分割槽( network partitions)指某個網路裝置出錯導致網路分離,比如某個資料庫掛掉。
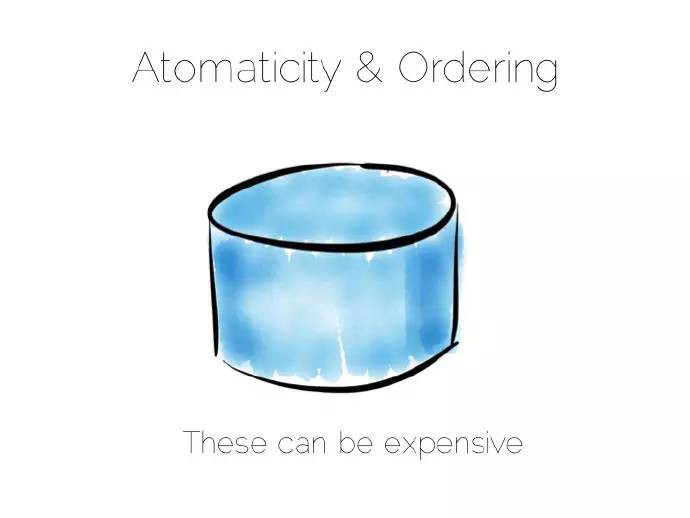
權衡一致性給我們帶來一個重要的問題,什麼時候需要保證資料的一致性?
一致性的代價是昂貴,在資料庫的世界裡,原子性由線性化(linearisabilty)做保障,這樣可以確保所有的操作有序排列.但代價也是昂貴的,實際上這完全是被禁止的,許多資料庫並不將此作為一個獨立(isolation)執行單元。鑒於此,很少將此設為預設值。
簡而言之,你想分散式寫的系統保持強一致性,系統會變慢。
註意一致性這個術語有兩個應用場景,在原子性和CAP中,當然其意思是不同的。我通常採用CAP中的定義,對所有的節點而言資料在某一時刻是相同的。
解決一致性問題的方法其實很簡單,就是避免它。如果無法避免,隔離它為其分配盡可能少的寫操作和計算機資源。
避免一致性問題一般不難,特別是資料為不變的事實流時,網路日誌集合就是一個很好的例子。無需關註一致性,因為這些日誌作為事實是不會改變的。
需要一致性的用例,比如轉賬、使用優惠碼這種非交換行為。
當然從傳統的眼光看一些事情需要一致性,但實際上卻也未必。比如一個行動從一個可變狀態變成一個新的相關事實集合,就可以避免這種變化狀態。通常是直接對新欄位進行更新,考慮到標記一個事務存在潛在的欺詐,我們可以簡單地利用某個事實流和原始的事務進行關聯。
譯者:好觀點
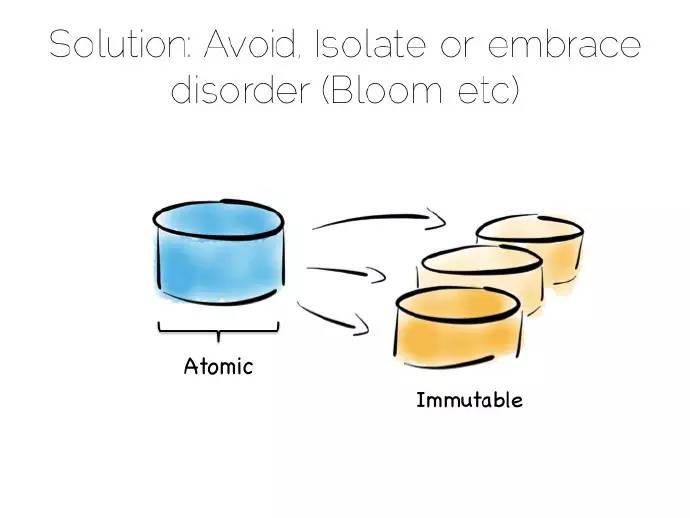
在資料平臺中移除所有一致性需求、或者隔離它都是很有用的。一種隔離方式是利用單個寫原則,涉及幾個方面,比如Datomic;另一種方式是拆分可變的和非可變的來隔離一致性需求。
諸如Bloom/CALM擴充套件了這些理念,支援預設狀態下的無序概念,除非需要才做排序。因此我們有必要做一些基本的權衡,那我們如何利用這些特性去建立一個資料平臺?

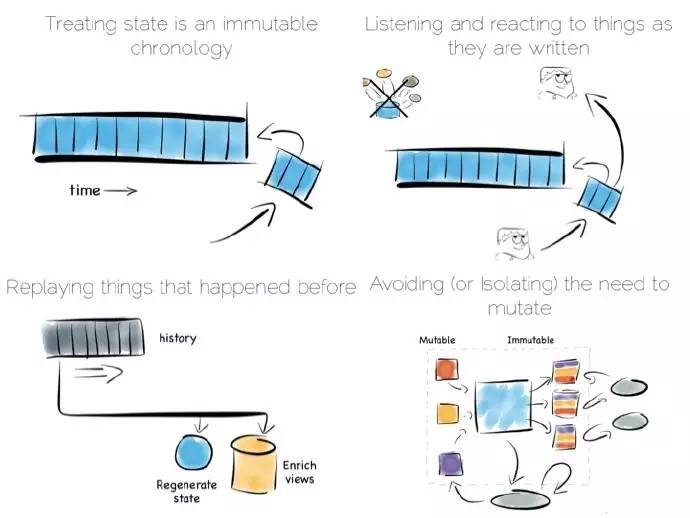
一個典型的應用架構或許應該是這樣的:有一組處理將資料寫入某個資料庫,然後將其讀出,對於許多簡單的工作負載這是沒有問題的,許多成功的應用都是基於此樣式。但隨著吞吐量的增加,此樣式越來越難以適用;在應用領域這個問題或許可以透過訊息傳遞、演員(actors)、負載均衡加以解決。
另外一個問題是這種方式將資料庫作為一個黑盒,資料庫是一個透明的軟體。它們提供了海量的特徵,但也提供了極少的原子拆分的機制。這樣做有很多好處,預設狀態下是安全的;但保護過度地扼殺我們的需求進而限制系統的分散式,這就很煩人。
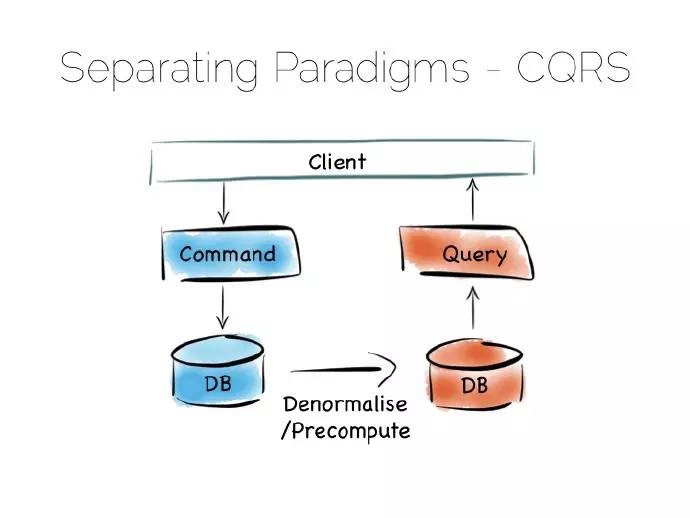
命令查詢職責分離(CQRS Command Query Responsibility Segregation)可以簡單地解決此問題。
譯註:
- 實現一Druid
- 實現二操作分析橋(Operational/Analytic Bridge)
- 實現三批次管道
- 實現四拉姆達框架(Lambda Architecture)
- 實現五卡帕(Kappa)框架又叫流資料平臺
想法其實很簡單,分離讀寫工作負載:最佳寫入狀態時寫入,最切貼的例子比如某個簡單日誌檔案;最佳讀取狀態時讀取。有多種實現方式,比如用於關係型資料庫的Goldengate工具、內部複製整合的諸如MongoDB的Replica Sets這樣的產品。
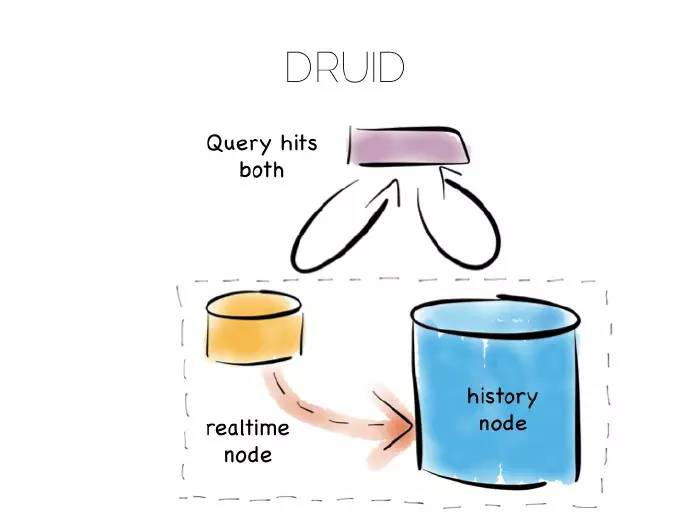
許多資料庫底層的行為就是這樣,Druid是一個不錯的例子,它是一個開源的、分散式、時序化、列式分析引擎。列式儲存表現不俗,特別是大規模資料錄入,資料必須分散到許多檔案中。為了得到更好的寫效能,Druid儲存近期的新資料到某個最佳寫入狀態中,然後逐漸轉移到最佳讀取儲存狀態。
一旦查詢Druid,請求就會同時派發到最佳寫和最佳讀控制元件中,對結果進行組合(移除冗餘),傳回給使用者。Druid藉助時間標記每條記錄來進行排序。
諸如此類的組合方式提供了單個抽象下的CQRS好處。
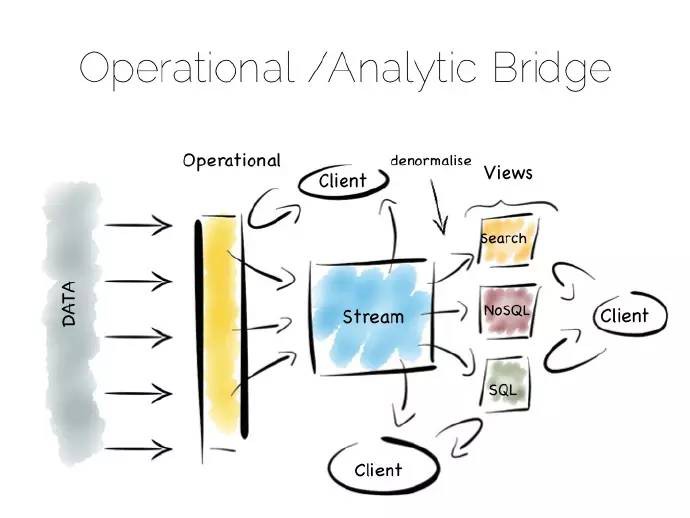
另一種相似的方式是操作分析橋(Operational/Analytic Bridge),利用單個事件流拆分最佳讀以及最佳寫檢視。流處在一種不斷變化的狀態,因此非同步檢視可以在隨後的日子裡被重寫和增強。
前端提供了同步讀和寫,這麼做即可以簡單快速地讀取已寫入的資料,又可以支援複雜的原子事務。
後端採用非同步、不變狀態的優勢來提高效能,比如藉助複製、反正規化化、甚至完全不同的儲存引擎擴充套件線下處理。前後端之間的訊息橋連方便應用透過平臺去監聽資料流。這種模型很適閤中等規模的部署,可變檢視至少存在一部分、不可避免的需求。
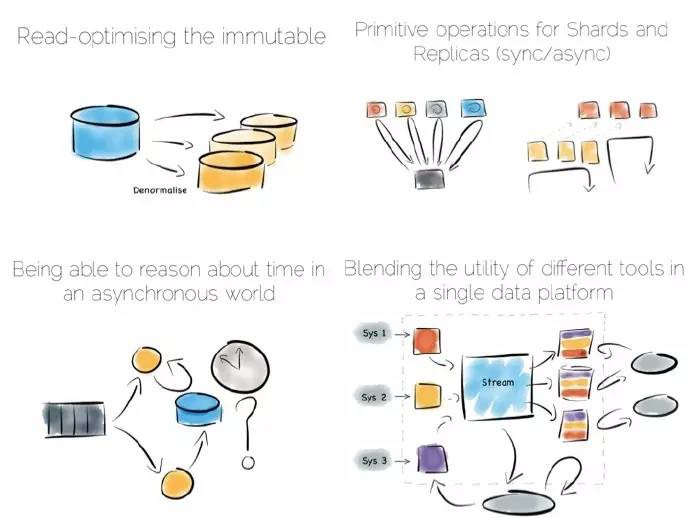
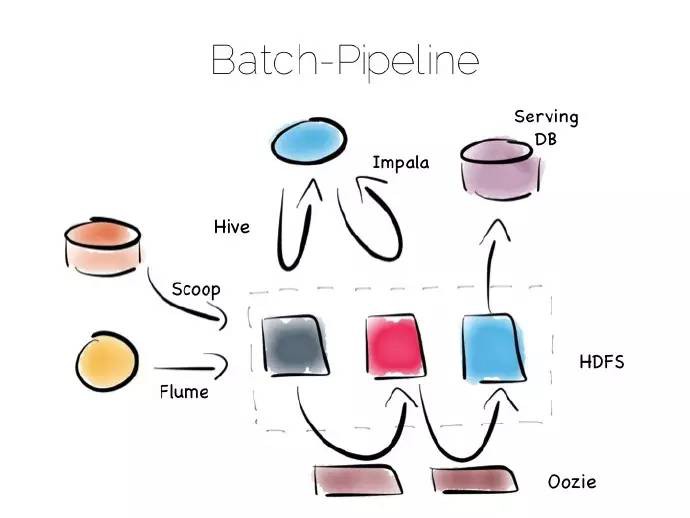
設計不變的狀態,以便容易地去支援大規模資料集和更加複雜的分析。Hadoop棧中獨一無二的實現——批次管道,就是一個典型的例子。
Hadoop棧最精彩的地方就是其叢多的工具,不管是快速讀寫訪問、還是廉價地儲存、抑或批次處理、高吞吐訊息、或者提取、處理、分析資料,hadoop生態體系應有盡有。
批次管道從多種資源中獲取資料,將其放入HDFS,接著對其進行處理,進而提供一個原始資料持續最佳化的版本。
資料可能得到富集、清理、反正規化化、聚集、移到一個諸如Parquet的最佳讀樣式,或者載入進伺服器層或者資料集市,處理之後的資料可以被檢索和處理。
此框架適用於不變資料、以及對資料進行大規模獲取和處理,比如100太位元組(TBs)。此框架處理過程很緩慢,以小時為單位。
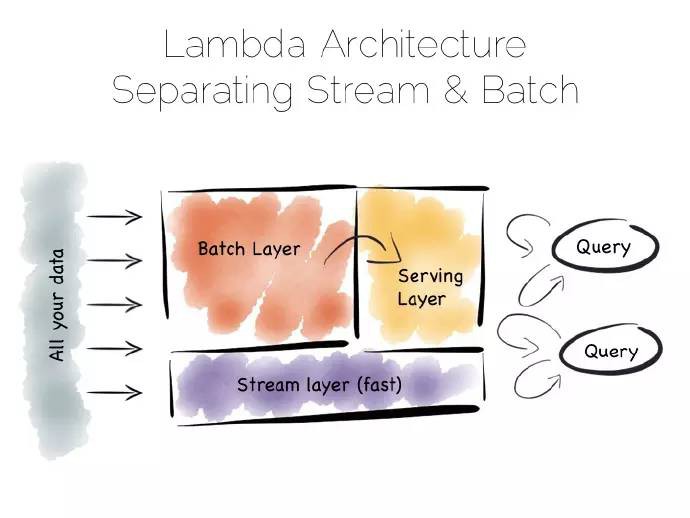
批次管道的問題是通常我們不想等幾個小時去獲取一個結果。常見的做法是新增一個流層,有時又叫拉姆達框架(Lambda Architecture)。
拉姆達框架保留了批次管線,不過增加了快速流層實現迂迴,就像在忙亂的小鎮架了一個支路,流層採用諸如Storm、Samza流處理工具。
拉姆達框架核心是我們最樂意快速粗略作答的,但我想在最後做一個精確的回答。
流層繞過了批次層,提供了最佳回答,它的核心就在流檢視中。這些會寫入一個伺服器層。稍好批次管道計算出精確的資料並改寫之前的值。
用響應來平衡精度是個不錯的做法,兩個分支在流和批次處理層都有編碼,這種樣式的一些實現是有問題的。解決辦法,一是將此邏輯簡單抽象到一個可復用的通用庫中,比如處理都寫入了諸如Python、R語言這樣的外源庫中。二是諸如Spark這樣的系統同時提供了流和批次處理功能,當然spark中的流只是少量的批處理。
因此這種樣式適合比如100TB的海量資料平臺,將流和已存、富集的、批次分析函式結合起來。
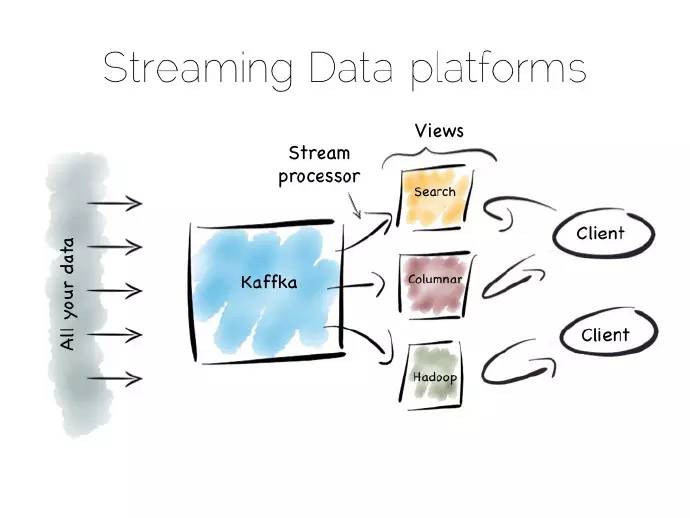
另外一種解決慢資料管道的方式,稱之為卡帕(Kappa)框架。起初我以為這個架構名稱不對,現在我不太確定。不管它是什麼,我叫它流資料平臺,其實這個已經有人這麼叫了。
流資料平臺相對批次樣式更有優勢:與將資料儲存在HDFS中劃分給新的批次任務不同,資料分散儲存在訊息系統或者諸如kafka日誌中。批處理就變成了記錄系統,資料流經過實時處理生成三層結構:檢視、索引、服務或者資料集市。
與拉姆達(lambda)框架的流層相似,不一樣的是沒有批處理層。顯然這就要求訊息層能夠儲存、供應海量資料,並且具有強大有效的流處理器來處理此過程。
天下沒有免費的午餐,問題很棘手,流資料平臺執行速度並沒有同等批次處理系統快多少。但將預設的方法“儲存和處理”切換為“流和處理”,可以極大地提高快速獲取結果的可能性。
流資料平臺方式還可以用來解決“應用整合”問題,應用整合這個棘手的問題困惑Informatica、Tibco和Oracle等大的供應商好多年了。對許多資料庫而言是有益的,但不是一種變革性方案。應用整合至今停留在找尋切實可行方案的話題上。
流資料平臺提供了一個潛在的解決方案:利用操作分析橋的叢多優勢—多種非同步儲存格式以及重新建立檢視的能力—但這會增加已有資源中一致性需求:
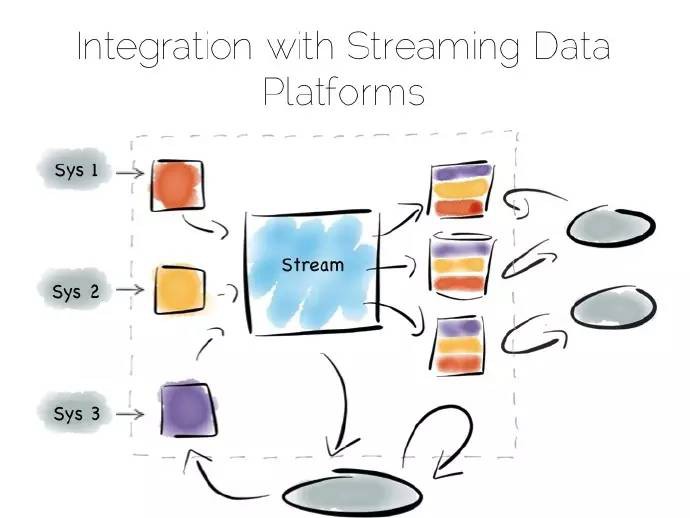
系統記錄變為日誌,易於增強資料的不變性。諸如Kafka等產品內部保留了足夠的資料量和吞吐量,將其作為歷史記錄來用。這就意味著回覆是一個重演、重新生成狀態的處理過程,而非常態化地檢驗。
相似的方式很在就有應用,早於最新出現的資料湖或者Goldengate等工具,後者將資料放入企業級資料倉庫。複製層缺乏吞吐量和管理複雜的schema變化使此方法大打折扣。看似最後第一個問題已經解決,但作為最後一個問題,還沒有定論。
回到區域性性,讀和寫按序定址,是控制元件內部最需要權衡的部分。我們觀看瞭如何拓展這些控制元件,提高了分庫分表和複製最基本的效能。重新審視一致性將其作為一個問題,在構建平臺時隔離它。
不過資料平臺本身需要用單一、全域性的方式來平衡這些控制元件達到最佳狀態。不斷重建,從最佳寫狀態遷移到最佳讀狀態,從一致性約束轉移到流、非同步、不變狀態的開放地帶。
需要記住幾件事,一是schema,二是時間、分散式、非同步系統風險。但這些問題都是可控的,前提是你認真對待。未來大資料領域可能會出現這樣一些新的工具、革新,逐漸摻入到平臺中,解決過去和現在更多的問題。
譯者註:schema 指資料庫完整性約束。