
導讀:郭敬明五年電影最動人之作《悲傷逆流成河》,可以說口碑票房都豐收的好劇。導演不是郭敬明,導演是落落,一個寫而優則導的好作家。
本篇推文將帶你爬取貓眼電影《悲傷逆流成河》短評,用資料告訴你,這部電影,你值得去看,值得你看兩遍。
作者:XksA
來源:極簡XksA(ID:xksnh888)
01 我的感受
知道《悲傷逆流成河》電影上映還是在QQ空間看見學弟發了說說,突然想起初中追小四的書,每天看到晚上10點多。
昨天看了電影,整個故事情節幾乎和小說一模一樣,當然縮減是避免不了的,最大的不一樣的是原著裡的易遙是跳樓自殺的,而電影里路遙是在眾人的”舌槍唇劍”、幸災樂禍的眼睛下,帶著不甘與怨恨跳河自殺的,最後竟然……我就不劇透了。
整部劇大概一個小時四十分鐘下來全程無尿點,看完讓我想寫這篇充滿技術+情感的文章。
02 技術搞事情:爬一爬
1. 貓眼電影短評介面
http://maoyan.com/films/1217236
我們直接訪問這個,在web端只能看到最熱的10條短評,那怎麼獲取到所有短評呢?
(1) 訪問上面的連結,按下F12,然後點選圖片上的圖示,把瀏覽樣式(響應式設計樣式,火狐快捷鍵Ctrl+Shift+M)改為手機樣式,掃清頁面。
▲第一步

▲掃清後
(2)換用谷歌瀏覽器,F12下進行上面操作,載入完畢後下拉短評,頁面繼續載入,找到含有offset和startTime的載入條,發現它的Response中包含我們想要的資料,為json格式。

▲獲取到真正的評論介面
2. 獲取短評
(1)簡單分析
透過上面分析
Request URL:
http://m.maoyan.com/mmdb/comments/movie/1217236.json?v=yes&offset;=0&startTime;=0%2021%3A09%3A31
Request Method: GET
下滑了幾次次,我發現了下麵規律:

▲測試表
分析上面資料變化,可以大致猜測出:offset表示該介面顯示評論開始位置,每個頁面15條,比如:15,則顯示15-30這中間的15條評論;startTime表示當前評論的時間,固定格式(2018-10-06)。
另外介面最後的%2021%3A09%3A31是不變的。
(2)程式碼獲取
'''
data : 2018.10.06
author : 極簡XksA
goal : 爬取貓眼《悲傷逆流成河》影評,詞雲視覺化
'''
# 貓眼電影介紹url
# http://maoyan.com/films/1217236
import requests
from fake_useragent import UserAgent
import json
essay-headers = {
"User-Agent": UserAgent(verify_ssl=False).random,
"Host":"m.maoyan.com",
"Referer":"http://m.maoyan.com/movie/1217236/comments?_v_=yes"
}
# 貓眼電影短評介面
offset = 0
# 電影是2018.9.21上映的
startTime = '2018-09-21'
comment_api = 'http://m.maoyan.com/mmdb/comments/movie/1217236.json?_v_=yes&offset;={0}&startTime;={1}%2021%3A09%3A31'.format(offset,startTime)
# 傳送get請求
response_comment = requests.get(comment_api,essay-headers = essay-headers)
json_comment = response_comment.text
json_comment = json.loads(json_comment)
print(json_comment)
傳回資料:

▲json資料
(3)資料簡單介紹
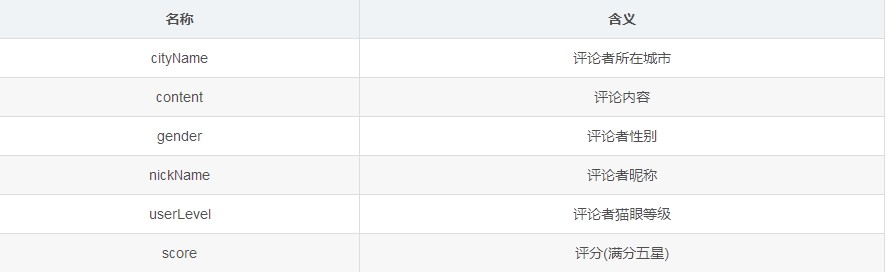
▲資料介紹表
(4)資料提取
# 獲取資料並儲存
def get_data(self,json_comment):
json_response = json_comment["cmts"] # 串列
list_info = []
for data in json_response:
cityName = data["cityName"]
content = data["content"]
if "gender" in data:
gender = data["gender"]
else:
gender = 0
nickName = data["nickName"]
userLevel = data["userLevel"]
score = data["score"]
list_one = [self.time,nickName,gender,cityName,userLevel,score,content]
list_info.append(list_one)
self.file_do(list_info)
3. 儲存資料
# 儲存檔案
def file_do(list_info):
# 獲取檔案大小
file_size = os.path.getsize(r'G:\maoyan\maoyan.csv')
if file_size == 0:
# 表頭
name = ['評論日期', '評論者暱稱', '性別', '所在城市','貓眼等級','評分','評論內容']
# 建立DataFrame物件
file_test = pd.DataFrame(columns=name, data=list_info)
# 資料寫入
file_test.to_csv(r'G:\maoyan\maoyan.csv', encoding='gbk', index=False)
else:
with open(r'G:\maoyan\maoyan.csv', 'a+', newline='') as file_test:
# 追加到檔案後面
writer = csv.writer(file_test)
# 寫入檔案
writer.writerows(list_info)
4. 封裝程式碼
複製貼上以下連結到瀏覽器,可獲取封裝好的爬取貓眼電影資料程式碼:
https://github.com/XksA-me/spider/tree/master/spider_maoyan
記得給個Star哦~
5. 執行結果顯示

▲獲取資料顯示
03 技術搞事情:資料分析視覺化
1. 提取資料
-
程式碼:
def read_csv():
content = ''
# 讀取檔案內容
with open(r'G:\maoyan\maoyan.csv', 'r', encoding='utf_8_sig', newline='') as file_test:
# 讀檔案
reader = csv.reader(file_test)
i = 0
for row in reader:
if i != 0:
time.append(row[0])
nickName.append(row[1])
gender.append(row[2])
cityName.append(row[3])
userLevel.append(row[4])
score.append(row[5])
content = content + row[6]
# print(row)
i = i + 1
print('一共有:' + str(i - 1) + '條資料')
return content-
執行結果:
一共有:15195條資料
2. 評論者性別分佈視覺化
-
程式碼:
# 評論者性別分佈視覺化
def sex_distribution(gender):
# print(gender)
from pyecharts import Pie
list_num = []
list_num.append(gender.count('0')) # 未知
list_num.append(gender.count('1')) # 男
list_num.append(gender.count('2')) # 女
attr = ["其他","男","女"]
pie = Pie("性別餅圖")
pie.add("", attr, list_num, is_label_show=True)
pie.render("H:\PyCoding\spider_maoyan\picture\sex_pie.html")-
執行結果:

▲性別分佈
從資料上看,大多數評論者在註冊貓時個人資訊欄沒有標註性別,而且男女中,評分者主要是女生,也好理解,這本來就是一部比較文藝、小眾的青春篇,女生可能更為喜愛,而男生可能更加喜歡動作大片。
3. 評論者所在城市分佈視覺化
-
程式碼:
# 評論者所在城市分佈視覺化
def city_distribution(cityName):
city_list = list(set(cityName))
city_dict = {city_list[i]:0 for i in range(len(city_list))}
for i in range(len(city_list)):
city_dict[city_list[i]] = cityName.count(city_list[i])
# 根據數量(字典的鍵值)排序
sort_dict = sorted(city_dict.items(), key=lambda d: d[1], reverse=True)
city_name = []
city_num = []
for i in range(len(sort_dict)):
city_name.append(sort_dict[i][0])
city_num.append(sort_dict[i][1])
import random
from pyecharts import Bar
bar = Bar("評論者城市分佈")
bar.add("", city_name, city_num, is_label_show=True, is_datazoom_show=True)
bar.render("H:\PyCoding\spider_maoyan\picture\city_bar.html")
# 地圖視覺化
def render_city(cities):
點選閱讀原文檢視該函式完整程式碼-
執行結果:
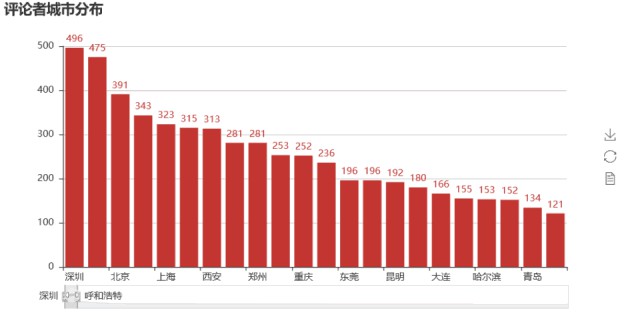
▲柱狀圖城市分佈

▲地理位置分佈
從中可以看出,大多數觀影評分者位於我國東南部分,城市分佈上,深圳、成都、北京、武漢、上海佔據前五,因為圖示裡還有很多地級市,所以資料不集中(最大的也只有幾百),還是可以看出,這些人大多分佈在一二線城市,有消費能力,也願意在節假日消費,有錢,就是好。
4. 每日評論總數視覺化分析
-
程式碼:
# 每日評論總數視覺化分析
def time_num_visualization(time):
from pyecharts import Line
time_list = list(set(time))
time_dict = {time_list[i]: 0 for i in range(len(time_list))}
time_num = []
for i in range(len(time_list)):
time_dict[time_list[i]] = time.count(time_list[i])
# 根據數量(字典的鍵值)排序
sort_dict = sorted(time_dict.items(), key=lambda d: d[0], reverse=False)
time_name = []
time_num = []
print(sort_dict)
for i in range(len(sort_dict)):
time_name.append(sort_dict[i][0])
time_num.append(sort_dict[i][1])
line = Line("評論數量日期折線圖")
line.add(
"日期-評論數",
time_name,
time_num,
is_fill=True,
area_color="#000",
area_opacity=0.3,
is_smooth=True,
)
line.render("H:\PyCoding\spider_maoyan\picture\c_num_line.html")-
執行結果:

▲每日評論數折線圖
由於資料顯示不完整,不能很好的看出評論數量變化,但基本可以看出每天的評論數都為1005,我估計是貓眼限制了每天評論數的顯示,或者我獲取的時候被限制了,從9.21開始到10.6的16天裡,每天新增評論數均達到最大值,可以說明其熱度不減。
5. 評論者貓眼等級、評分視覺化
-
程式碼:
# 評論者貓眼等級、評分視覺化
def level_score_visualization(userLevel,score):
from pyecharts import Pie
userLevel_list = list(set(userLevel))
userLevel_num = []
for i in range(len(userLevel_list)):
userLevel_num.append(userLevel.count(userLevel_list[i]))
score_list = list(set(score))
score_num = []
for i in range(len(score_list)):
score_num.append(score.count(score_list[i]))
pie01 = Pie("等級環狀餅圖", title_pos='center', width=900)
pie01.add(
"等級",
userLevel_list,
userLevel_num,
radius=[40, 75],
label_text_color=None,
is_label_show=True,
legend_orient="vertical",
legend_pos="left",
)
pie01.render("H:\PyCoding\spider_maoyan\picture\level_pie.html")
pie02 = Pie("評分玫瑰餅圖", title_pos='center', width=900)
pie02.add(
"評分",
score_list,
score_num,
center=[50, 50],
is_random=True,
radius=[30, 75],
rosetype="area",
is_legend_show=False,
is_label_show=True,
)
pie02.render("H:\PyCoding\spider_maoyan\picture\score_pie.html")-
執行結果:
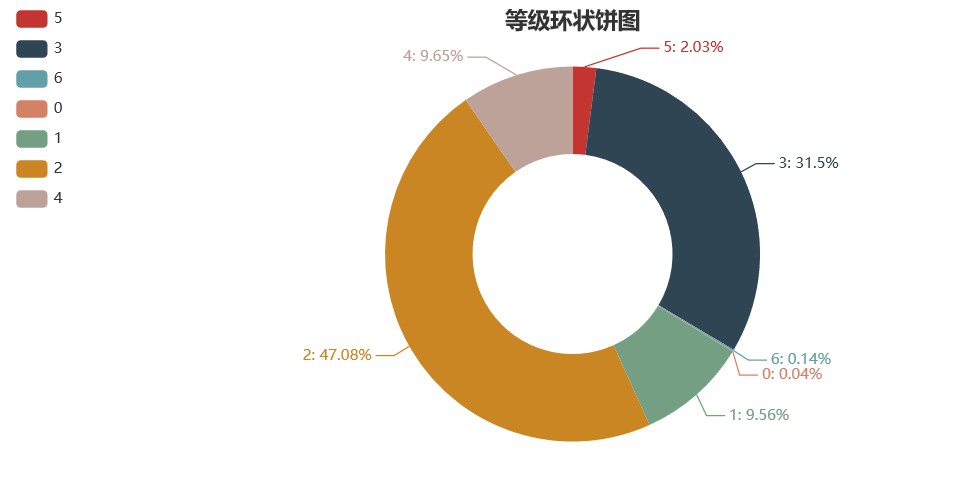
▲等級分佈
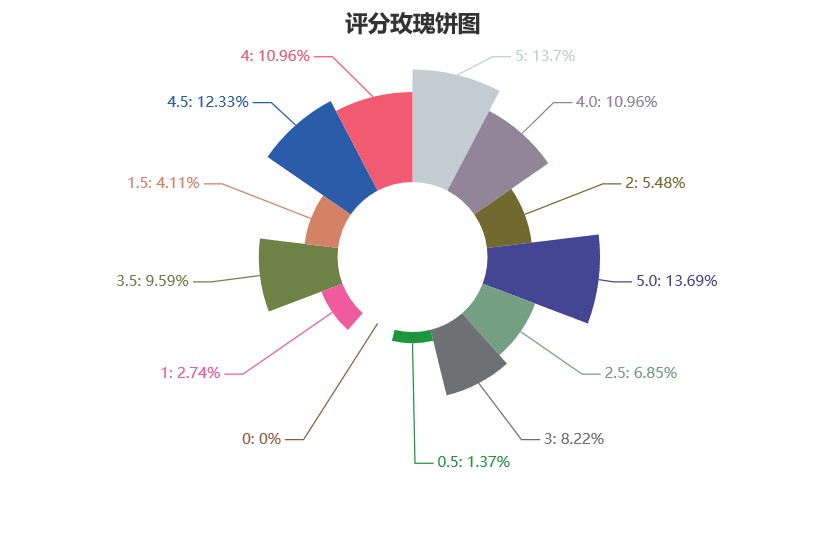
▲評分分佈
從資料視覺化結果可以看出,評論者中有47.08%為貓眼二級使用者,31.5%為貓眼三級使用者,四級及以上使用者佔11.82%,0級或1級(可以認定為新註冊使用者)佔9.6%,可以看出評分的人中水軍是很少的,基本都是貓眼老使用者,評分和評論都不會有任何客觀色彩。
從評分上看,五星的滿分,評分在3星及以上的佔93.8%,評分在4星及以上的佔87.7%,評分在5星的(滿分)佔62.82%,可以看出大家對該電影是一致好評。
6. 評論者評論內容視覺化分析
-
程式碼:
#定義個函式式用於分詞
def jiebaclearText(text):
點選閱讀原文檢視該函式完整程式碼
# 生成詞雲圖
def make_wordcloud(text1):
text1 = text1.replace("悲傷逆流成河", "")
bg = plt.imread(d + r"/static/znn1.jpg")
# 生成
wc = WordCloud(# FFFAE3
background_color="white", # 設定背景為白色,預設為黑色
width=890, # 設定圖片的寬度
height=600, # 設定圖片的高度
mask=bg,
# margin=10, # 設定圖片的邊緣
max_font_size=150, # 顯示的最大的字型大小
random_state=50, # 為每個單詞傳回一個PIL顏色
font_path=d+'/static/simkai.ttf' # 中文處理,用系統自帶的字型
).generate_from_text(text1)
# 為圖片設定字型
my_font = fm.FontProperties(fname=d+'/static/simkai.ttf')
# 圖片背景
bg_color = ImageColorGenerator(bg)
# 開始畫圖
plt.imshow(wc.recolor(color_func=bg_color))
# 為雲圖去掉坐標軸
plt.axis("off")
# 畫雲圖,顯示
# 儲存雲圖
wc.to_file(d+r"/picture/word_cloud.png")-
人物圖

▲真的超級喜歡電影裡拿手機那一笑,初戀的感覺
-
執行結果:

▲詞雲圖
整體來看,是一部良心劇,好看,挺好看的,非常好看,超級好看,看哭了,感人,值得一看…幾乎100%的好評,主題鮮明,校園暴力,險惡嘴臉,事不關己高高掛起的腐爛心態的顯露,展示,很好的凸顯了現在浮躁的社會,浮躁的氣氛。
04 我想說的話
《悲傷逆流成河》這部劇除了反應校園暴力,當代中、高、大學生,乃至成年人心浮氣躁外,還有意無意的反應著那個時代友誼的可貴。
在電影中,路遙去找那個 小診所的男醫生,那個男醫生說的“一次100,10次下來你的這個痛苦就就可以徹底解脫了”,我依然記得路遙迷茫的眼神,還有路遙的媽媽,做的也不是骯髒的生意,就是普通的給那些”腐朽”的人按按摩而已。
還有很多情節,路遙媽媽說的“我每次做生意的時候都刻意的把你的內衣收著就是怕那些垃圾知道你”,路遙急著找錢時發現媽媽給她存的報名費,從一元的到一百的,那麼厚厚一沓,路遙媽媽知道路遙染上那個病是因為自己後,打自己的那個耳光,齊銘媽媽看見路遙媽媽拉著路遙的驚訝眼神……
太多了,最後路遙說出那句“殺死顧森湘的兇手,我不知道是誰,但殺死我的兇手,你們知道是誰”,轉身往大海奔去。我不知道是解脫還是傻,只怪我們都膽小怕事,別人做什麼我們就跟著做什麼。
世間向來不缺乏溫暖,只是大家都太過於,真的,太過於想要得到溫暖,搞小團體,“送禮”……我覺得不只是小孩在鬧著玩玩,很多大人也在鬧著“玩”。
無論你是小孩,初中生,高中生,大學生,成年人,工作的,當官的…還是什麼,請多多關愛身邊的弱勢群體,請記得給你的後輩做好榜樣,請記得不要“因為需要所以掠奪”,我相信,世間的邪惡雖不能完全消除,但是,我們可以儘量多的發現善良和美。
關於作者:XksA,大三在讀的師範技術生,主要研究Python資料分析、視覺化方面,爬蟲教程正在更新中,個人公眾號 極簡XksA 長期分享學習筆記,學習資料,歡迎交流學習。

據統計,99%的大咖都完成了這個神操作
▼
更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單
Python | 機器學習 | 深度學習 | 神經網路
區塊鏈 | 揭秘 | 乾貨 | 數學
猜你想看
Q: 你最近都看了哪些電影?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視
