資料科學專案可以讓你以一種有前途的方式開啟在這個領域的職業生涯。你不僅可以透過專案應用來學習資料科學,還可以在簡歷中展示該專案! 如今招聘人員透過候選人的工作來評估其潛力,並不是非常重視獲得的證書。 如果你只是告訴他們你知道多少,但你沒有什麼可以展示的話,那也沒關係,這是大多數人掙扎和錯過的地方。
你之前可能已經解決過一些問題,但是如果你不能使它們變得易於理解和解釋,怎麼能讓人知道你具有什麼能力? 這就是這些專案可以幫助你的地方。 想想你在這些專案上花費的時間,比如你的培訓課程。 練習的時間越多,越會出色!
我們確保為你提供來自不同領域的各種問題的體驗。 我們相信每個人都必須學會巧妙地處理大量資料,因此這裡包含了大量資料集。 我們確保所有資料集都是開放並可以自由訪問的。
為了幫助你決定從哪裡開始,我們把這個串列分為3個層次,即:
1、初級水平:該級別包括一些易於使用的資料集,不需要複雜的資料科學技術。你可以用基本的回歸或分類演演算法來解決它們。此外,這些資料集有足夠的開放教程幫你前進。在這個串列中,我們還提供了教程幫你入門。
2、中級水平:該級別包括本質上更具挑戰性的資料集,它由需要嚴格的樣式識別技能處理的中、大資料集組成。此外,特徵工程會在這裡發揮作用。可以無限制使用機器學習(ML)技術,而且一切公開技術都可以投入使用。
3、高階水平:這個級別適合理解如神經網路、深度學習、推薦系統等高階技術的人員。高維資料集是這個級別的特色。在這裡可以看到資料科學的創意,看看科學家們在工作和程式碼中的創造力。

這可能是樣式識別文獻中最通用、簡單和靈活多樣的資料集,沒有什麼比虹膜資料集更容易學習分類技術。如果你對資料科學完全陌生,這是你最好的起點。此資料只有150行4列。
任務:根據可用的屬性預測花的種類。
資料:https://archive.ics.uci.edu/ml/datasets/Iris
教程:https://www.slideshare.net/thoi_gian/iris-data-analysis-with-r

在所有行業中,保險領域是分析和資料科學方法使用最廣的行業之一。這個資料集為你提供了保險公司的資料工作體驗——那裡面臨什麼挑戰,使用什麼策略,哪些變數影響結果等。這是一個分類問題。資料有615行13列。
任務:預測貸款是否會得到批准。
資料:https://datahack.analyticsvidhya.com/contest/practice-problem-loan-prediction-iii/
教程:https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-learn-data-science-python-scratch-2/

零售業是另一個需要廣泛使用分析來最佳化業務流程的行業。諸如產品放置、庫存管理、定製報價、產品捆綁等任務都在使用資料科學技術進行智慧處理。此資料包括銷售商店的交易記錄,這是一個回歸問題,資料集有8523行12個變數。
任務:預測一家商店的銷售額。
資料:https://datahack.analyticsvidhya.com/ contest/practice-problem-big-mart-sales-iii/
教程:https://www.analyticsvidhya.com/blog/2016/02/bigmart-sales-solution-top-20/

這是在樣式識別文獻中另一個流行使用的資料集。此資料集是來自波士頓(美國)的房地產業。這是一個回歸問題,資料有506行14列,所以這是一個相當小的資料集,你可以嘗試任何技術,不用擔心膝上型電腦的記憶體過度使用。
任務:預測自住房屋的中位數值。
資料:https://www.cs.toronto.edu/~delve/ data/boston/bostonDetail.html
教程:https://www.analyticsvidhya.com/ blog/2015/11/started-machine-learning-ms-excel-xl-miner/

時間序列是資料科學中最常用的技術之一。它具有廣泛的應用——天氣預報、銷售預測、逐年趨勢分析等。這個資料集是針對時間序列的,這裡的挑戰是在運輸方式基礎上預測交通狀況。
任務:預測一種新的運輸方式的交通狀況。
資料:https://datahack.analyticsvidhya.com/ contest/practice-problem-time-series-2/
教程:https://trainings.analyticsvidhya.com/courses/course-v1:AnalyticsVidhya+TS_101+TS_term1/about

這是資料科學初學者中最流行的資料集之一。它被分為2個資料集。你可以在這個資料上執行回歸和分類任務。它將幫助你理解資料科學中的不同領域——離群點檢測、特徵選擇和不平衡資料。在這個資料集中有4898行12列。
任務:預測葡萄酒質量。
資料:https://archive.ics.uci.edu/ml/datasets/Wine+Quality
教程:暫無

該資料集基於不同課程的學生填寫的評價表。它含有不同的維度屬性,包括考勤,難度,每個評估的得分等等。這是一個無監督的學習問題。資料集有5820行33列。
任務:使用分類和聚類技術來處理資料。
資料:https://archive.ics.uci.edu/ml/datasets/ Turkiye+Student+Evaluation
教程:暫無
對於剛接觸資料科學的人來說,這是一個理想的簡單問題。它一個回歸問題。資料集有25000行3列(索引、高身高和體重)。
任務:預測一個人的身高或者體重。
資料:http://wiki.stat.ucla.edu/socr/i ndex.php/SOCR_Data_Dinov_020108_HeightsWeights
教程:https://www3.nd.edu/~steve/ computing_with_data/2_Motivation/motivate_ht_wt.html

該資料集包括從零售商店獲得的銷售交易資料。這是一個幫你探索和擴充套件你的特徵工程技術和逐漸瞭解多角度購物經驗的經典資料集。它是一個回歸問題。資料集有550069行12列。
任務:預測銷售額。
資料:https://datahack.analyticsvidhya.com/contest/black-friday/
教程:https://discuss.analyticsvidhya.com/ t/black-friday-data-hack-reveal-your-approach/5986

該資料集是嵌入慣性感測器啟用的智慧手機捕獲的30個人的活動記錄的集合。許多機器學習課程使用這些資料來教學。現在輪到你來處理這個多分類問題。資料集有10299行561列。
任務:預測一個人的活動類別。
資料:http://archive.ics.uci.edu/ml/ datasets/Human+Activity+Recognition +Using+Smartphones
教程:https://rstudio-pubs-static.s3.amazonaws.com/ 291850_859937539fb14c37b0a311 db344a6016.html

這個資料集來自於在2007年舉行的暹羅文字挖掘競賽。資料集包括描述在某些發生問題的航班的航空安全報告。它是一個多分類的高維問題。它有21519行30438列。
任務:按標簽分類檔案。
資料:https://www.csie.ntu.edu.tw/~cjlin/ libsvmtools/datasets/multilabel.html#siam-competition2007
教程:https://wtlab.um.ac.ir/images/ e-library/text_mining/Survey%20of% 20Text%20Mining%202%20.pdf

這個資料集來自於美國的共享單車。這個資料集需要你練習資料挖掘技術。它提供2010年第四季度以前季度資料,每個檔案有7列。這是一個分類問題。
任務:預測使用者分類。
資料:https://www.capitalbikeshare.com/system-data
教程:https://www.analyticsvidhya.com/blog/2015/06/solution-kaggle-competition-bike-sharing-demand/

你知道資料科學也可以用於娛樂行業嗎?現在自己動手試試吧。該資料集提出了回歸任務。它包括515345個觀測值和90個變數。然而,這僅僅是大約有一百萬首歌曲的歌曲資料庫的一小部分。
任務:預測歌曲的發行年。
資料:http://archive.ics.uci.edu/ml/datasets/YearPredictionMSD
教程:http://www-personal.umich.edu/~yjli/ content/projectreport.pdf

這是一個不平衡分類的經典機器學習問題。正如你所知,機器學習正被廣泛地被用於解決不平衡問題,如癌症檢測、欺詐檢測等。是時候輪到你去上手嘗試了。資料集有48842行14列。為了方便指導,你可以直接點選檢視這個不平衡資料專案。
任務:預測美國的收入等級。
資料:http://archive.ics.uci.edu/ml/ machine-learning-databases/census-income-mld/
教程:暫無

你建立過推薦系統嗎?這是你學習的好機會!該資料集是資料科學行業中最受歡迎及被取用最多的資料集之一。它有不同的數量級。在這裡我使用了一個相當小的集合,包含6000個使用者對4000部電影的100萬個評級。
任務:給使用者推薦新電影。
資料:https://grouplens.org/datasets/movielens/1m/
教程:https://www.analyticsvidhya.com/ blog/2016/06/quick-guide-build-recommendation-engine-python/

Twitter資料是情感類分析問題的一個組成部分。如果你想為自己在這個領域開闢一個新天地,你會很高興地迎接這個資料集所帶來的挑戰。這個資料集有3MB大,包含31962條推特。
任務:分辨正面推文和負面推文。
資料:https://datahack.analyticsvidhya.com /contest/practice-problem-twitter-sentiment-analysis/
教程:https://github.com/abdulfatir/twitter-sentiment-analysis

這個資料集讓你學習分析和識別影象中的元素。這就是你的相機如何識別你的臉的原理——使用影象識別技術!現在輪到你建立和測試這種技術了。這是一個數字識別問題。該資料集具有7000個28×28大小的影象,總計31MB。
任務:從影象中識別數字。
資料:https://datahack.analyticsvidhya.com/ contest/practice-problem-identify-the-digits/
教程:https://www.analyticsvidhya.com/blog/2016/10 /an-introduction-to-implementing-neural-networks-using-tensorflow/

當你開始你的機器學習之旅時,會遇到簡單的機器學習問題,例如泰坦尼克號生存預測。 但是,當涉及到現實生活中的實際問題時,你仍然沒有得到足夠的練習。 因此,此練習題旨在向你介紹通常的分類場景中的音訊處理。 該資料集包含摘錄自10個等級的8,732個城市聲音。
任務:從音訊中分類聲音型別。
資料:https://datahack.analyticsvidhya.com/ contest/practice-problem-urban-sound-classification/
教程:https://www.analyticsvidhya.com/blog/ 2017/08/audio-voice-processing-deep-learning/
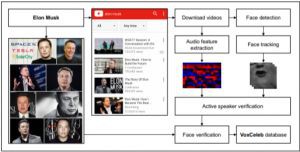
音訊處理正迅速成為深度學習的重要領域,這是另一個具有挑戰性的問題。 該資料集用於大規模說話人識別,資料集包含從YouTube影片中提取的名人所說的單詞。 這是一個有趣的語音分離和識別的例子。 這些資料包含了1,251位名人所說的100,000個話語。
任務:找出這個聲音屬於哪個名人。
資料:http://www.robots.ox.ac.uk/~vgg/data/voxceleb/
教程:https://www.robots.ox.ac.uk/~vgg/ publications/2017/Nagrani17/nagrani17.pdf

ImageNet提供了各種各樣的問題,包括物件檢測、定位、分類和螢幕解析。所有的影象都是免費提供的。你可以搜尋任何型別的影象並圍繞它構建專案。截至目前,該影象引擎有超過1500萬個多形狀影象,超過140GB。
任務:要解決的問題是你下載的影象型別。
資料:http://image-net.org/download-imageurls
教程:http://image-net.org/download-imageurls

如今每個資料科學家都希望能夠處理大型資料集。 當公司具有處理完整資料集的計算能力時,就不再喜歡處理樣本資料。 此資料集為你提供了在本地計算機上處理大型資料集所需的實踐經驗。 問題很簡單,但資料管理才是關鍵! 該資料集具有6M觀測值,這是一個多分類問題。
任務:預測犯罪型別。
資料:https://data.cityofchicago.org/Public-Safety/Crimes- 2001-to-present/ijzp-q8t2
教程:http://nathanwayneholt.com/mathematicalmodeling /ChicagoCrimesReport.pdf

對於所有深度學習愛好者來說,這都是一項極具挑戰性的挑戰。 該資料集包含數千張印度演員的影象,你的任務是確定他們的年齡。所有影象都是手動選擇並從影片幀中裁剪出來的,導致了人物比例,姿勢,表情,照明,年齡,解析度,遮擋和化妝等方面的高度變化性。 訓練集中有19,906個影象,測試集中有6,636個影象。
任務:預測演員的年齡。
資料:http://image-net.org/download-imageurls
教程:https://www.analyticsvidhya.com/blog/2017/06/hands-on-with-deep-learning-solution-for-age-detection-practice-problem/

這是一項高階推薦系統挑戰。在這個實踐問題中,你將得到程式員的資料、他們以前已經解決的問題以及他們解決那個特定問題所花費的時間。作為一名資料科學家,你所構建的模型將幫助線上評判人員決定向使用者推薦的下一級問題。
任務:根據使用者的當前狀態預測解決問題所花費的時間。
資料:https://datahack.analyticsvidhya.com/contest/practice-problem-recommendation-engine/
教程:暫無

VisualQA是一個包含有關影象的開放式問題的資料集,解決這些問題需要你瞭解計算機視覺和語言,問題均含有自動評估指標。 資料集有265,016個影象,每個影象3個問題,每個問題10個基礎的真實答案。
任務:使用深度學習技術回答關於影象的開放性問題。
資料:http://www.visualqa.org/
教程:https://arxiv.org/abs/1708.02711

在上面列出的24個資料集中,你應該首先找到與你技能相匹配的資料集。 比如,如果你是機器學習的初學者,請避免從一開始就使用高階資料集,不要貪多嚼不爛,也不要因為還有很多要做而感到不知所措。 相反,專註於逐步的進步。
完成2到3個專案後,在簡歷和GitHub配置檔案中展示它們(非常重要!)。 如今,很多招聘人員透過檢視候選人的GitHub專案來選擇。 你的動機不應該是完成所有專案,而是根據要解決的問題,域和資料集大小選擇所選專案。 如果你想檢視完整的專案解決方案,請檢視這裡。
原文標題:24 Ultimate Data Science Projects
To Boost Your Knowledge and Skills
原文URL:https://www.analyticsvidhya.com/blog/2018/05/24-ultimate-data-science-projects-to-boost-your-knowledge-and-skills/
翻譯、編輯、排版和校對:冀佳鈺、朝樂門
轉自:資料科學DataScience 公眾號;
END
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
80%的運營註定了打雜?因為你沒有搭建出一套有效的使用者運營體系
合作請加qq:365242293
更多相關知識請回覆:“ 月光寶盒 ”;
資料分析(ID : ecshujufenxi )網際網路科技與資料圈自己的微信,也是WeMedia自媒體聯盟成員之一,WeMedia聯盟改寫5000萬人群。
