
最近學習了一點網路爬蟲,並實現了使用Python來爬取知乎的一些功能,這裡做一個小的總結。網路爬蟲是指透過一定的規則自動的從網上抓取一些資訊的程式或指令碼。我們知道機器學習和資料挖掘等都是從大量的資料出發,找到一些有價值有規律的東西,而爬蟲則可以幫助我們解決獲取資料難的問題,因此網路爬蟲是我們應該掌握的一個技巧。
Python有很多開源工具包供我們使用,我這裡使用了requests、BeautifulSoup4、json等包。requests模組幫助我們實現http請求,bs4模組和json模組幫助我們從獲取到的資料中提取一些想要的資訊,幾個模組的具體功能這裡不具體展開。下麵我分功能來介紹如何爬取知乎。

要想實現對知乎的爬取,首先我們要實現模擬登入,因為不登入的話好多資訊我們都無法訪問。下麵是登入函式,這裡我直接使用了知乎使用者fireling的登入函式,具體如下。其中你要在函式中的data裡填上你的登入賬號和密碼,然後在爬蟲之前先執行這個函式,不出意外的話你就登入成功了,這時你就可以繼續抓取想要 的資料。註意,在首次使用該函式時,程式會要求你手動輸入captcha碼,輸入之後當前檔案夾會多出cookiefile檔案和zhihucaptcha.gif,前者保留了cookie資訊,後者則儲存了驗證碼,之後再去模擬登入時,程式會自動幫我們填上驗證碼。

需要註意的是,在login函式中有一個全域性變數s=reequests.session(),我們用這個全域性變數來訪問知乎,整個爬取過程中,該物件都會保持我們的持續模擬登入。
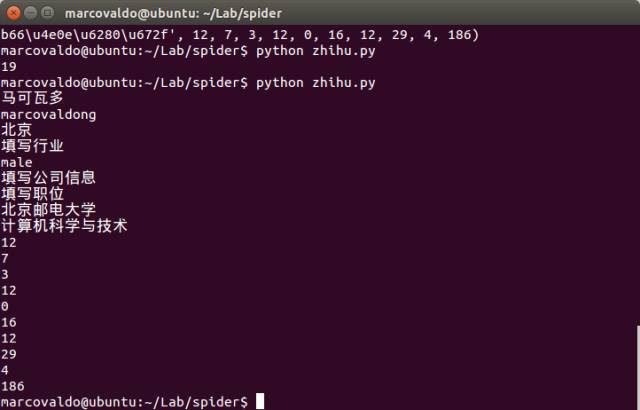
知乎上每個使用者都有一個唯一ID,例如我的ID是marcovaldong,那麼我們就可以透過訪問地址 https://www.zhihu.com/people/marcovaldong 來訪問我的主頁。個人主頁中包含了居住地、所在行業、性別、教育情況、獲得的贊數、感謝數、關註了哪些人、被哪些人關註等資訊。因此,我首先介紹如何透過爬蟲來獲取某一個知乎使用者的一些資訊。下麵的函式get_userInfo(userID)實現了爬取一個知乎使用者的個人資訊,我們傳遞給該使用者一個使用者ID,該函式就會傳回一個 list,其中包含暱稱、ID、居住地、所在行業、性別、所在公司、職位、畢業學校、專業、贊同數、感謝數、提問數、回答數、文章數、收藏數、公共編輯數量、關註的人數、被關註的人數、主頁被多少個人瀏覽過等19個資料。

下圖是我的主頁的部分截圖,從上面可以看到這19個資料,下麵第二張圖是終端上顯示的我的這19個資料,我們可以作個對照,看看是否全部抓取到了。這個函式我用了很長時間來除錯,因為不同人的主頁的資訊完整程度是不同的,如果你在使用過程中發現了錯誤,歡迎告訴我。

知乎上有一個問題是如何寫個爬蟲程式扒下知乎某個回答所有點贊使用者名稱單?,我參考了段小草的這個答案如何入門Python爬蟲,然後有了下麵的這個函式。
這裡先來大概的分析一下整個流程。我們要知道,知乎上的每一個問題都有一個唯一ID,這個可以從地址中看出來,例如問題2015 年有哪些書你讀過以後覺得名不符實?的地址為 https://www.zhihu.com/question/38808048 ,其中38808048就是其ID。而每一個問題下的每一個答案也有一個唯一ID,例如該問題下的最高票答案2015 年有哪些書你讀過以後覺得名不符實? – 餘悅的回答 – 知乎的地址連結為https://www.zhihu.com/question/38808048/answer/81388411 ,末尾的81388411就是該答案在該問題下的唯一ID。不過我們這裡用到的不是這兩個ID,而是我們在抓取點贊者名單時的唯一ID,此ID的獲得方法是這樣:例如我們打算抓取如何評價《人間正道是滄桑》這部電視劇? – 老編輯的回答 – 知乎的點贊者名單,首先開啟firebug,點選“5321 人贊同”時,firebug會抓取到一個“GET voters_profile”的一個包,把游標放在上面,會看到一個連結 https://www.zhihu.com/answer/5430533/voters_profile ,其中的5430533才是我們在抓取點贊者名單時用到的一個唯一ID。註意此ID只有在答案被贊過後才有。(在這安利一下《人間正道是滄桑》這部電視劇,該劇以楊立青三兄妹的恩怨情仇為線索,從大革命時期到解放戰爭,比較全面客觀的展現了國共兩黨之間的主義之爭,每一次看都會新的認識和體會。)
在拿到唯一ID後,我們用requests模組去get到知乎傳回的資訊,其中有一個json陳述句,該json陳述句中包含點贊者的資訊。另外,我們在網頁上瀏覽點贊者名單時,一次只能看到20條,每次下拉到名單底部時又載入出20條資訊,再載入20條資訊時所用的請求地址也包含在前面的json陳述句中。因此我們需要從json陳述句中提取出點攢著資訊和下一個請求地址。在網頁上瀏覽點贊者名單時,我們可以看到點贊者的暱稱、頭像、獲得了多少贊同和感謝,以及提問和回答的問題數量,這裡我提取了每個點贊者的暱稱、主頁地址(也就是使用者ID)、贊同數、感謝數、提問數和回答數。關於頭像的提取,我會在下麵的函式中實現。
在提取到點贊者名單後,我將者資訊儲存了以唯一ID命名的txt檔案中。下麵是函式的具體實現。

註意,點贊者名單中會有匿名使用者,或者有使用者被登出,這時我們抓取不到此使用者的資訊,我這裡在txt檔案中添加了一句“有點贊者的資訊缺失”。
使用同樣的方法,我們就可以抓取到一個使用者的關註者名單和被關註者名單,下麵列出了這兩個函式。但是關註者名單抓取函式有一個問題,每次使用其抓取大V的關註者名單時,當抓取到第10020個follower的時候程式就會報錯,好像知乎有訪問限制一般。這個問題,我還沒有找到解決辦法,希望有solution的告知一下。因為沒有看到有使用者關註10020+個人,因此抓取被關註者名單函式暫時未發現報錯。
再往下就是抓取使用者頭像了,給出某個唯一ID,下麵的函式自動解析其主頁,從中解析出該使用者頭像地址,抓取到圖片並儲存到本地檔案,檔案以使用者唯一ID命名。
結合其他函式,我們就可以抓取到某個答案下所有點贊者的頭像,某個大V所有followers的頭像等。
給出某個唯一ID,下麵的函式幫助爬取到該問題下的所有答案。註意,答案內容只抓取文字部分,圖片省略,答案儲存在txt檔案中,txt檔案以答主ID命名。

在完成了上面的這些功能後,下一步要做的是將使用者資訊儲存在資料庫中,方便資料的讀取使用。我剛剛接觸了一下sqlite3,僅僅實現了將使用者資訊儲存在表格中。

等熟悉了sqlite3的使用,我的下一步工作是抓取大量使用者資訊和使用者之間的follow資訊,嘗試著將大V間的follow關係進行視覺化。再下麵的工作應該就是學習python的爬蟲框架scrapy和爬取微博了。
另外,在寫這篇部落格的時候我又重新測試了一下上面的這些函式,然後我再在火狐上訪問知乎時,系統提示“因為該賬戶過度頻繁訪問”而要求輸入驗證碼,看來知乎已經開始限制爬蟲了,這樣以來我們就需要使用一些反反爬蟲技巧了,比如控制訪問頻率等等,這個等以後有了系統的瞭解之後再作補充吧。
《Linux雲端計算及運維架構師高薪實戰班》2018年11月26日即將開課中,120天衝擊Linux運維年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


