關註獲得更多內容
精彩預告:第八屆資料技術嘉年華大會將於2018年11月16日~17日在北京市朝陽區東三環中路61號富力萬麗酒店盛大開啟。本次大會邀請網際網路領先企業的資料庫專家,國產資料庫的領軍人物,雲技術等領域的知名人士,圍繞資料、智慧、連結組織前沿議題,倡導以智慧智慧演演算法應用,發掘資料價值,以技術將企業連結到未來的戰略制高點!
社群專屬福利(99.9%的人不知道):一分錢全場通票等你搶
點選“原文連結”檢視大會詳情。
京東大資料平臺部一直致力於最佳化基礎架構,為使用者提供穩定、高可靠、高效能、高利用率的超大規模Hadoop叢集。本文與大家分享大規模分散式儲存叢集的基石——本地儲存系統最佳化的點點滴滴。
在介紹主要內容前,先熟悉一下高可用Hadoop分散式檔案系統HDFS的核心架構,如下圖:

HDFS將大檔案切分為多個資料塊(Block)儲存到多個DataNode(以下簡稱DN)。
NameNode(以下簡稱NN)主要用於儲存分散式檔案系統的元資料,元資料包括檔案系統目錄樹、檔案與資料塊的對應關係、資料塊與DN 的對應關係。NN除了儲存元資料外,還需要管理大量的DN,同時要對外提供元資料的服務介面。
DN 是用於儲存資料塊的節點,HDFS上的所有檔案的資料都儲存在DN上。
HDFS上檔案的訪問檔案資料的流程,簡單來說,是Client先從NN獲取到檔案資料所在DN位置,然後與DN通訊訪問實際的資料。
為了保證NN的高可用,衍生出Active NN和Standby NN,依託ZooKeeper(以下簡稱ZK)實現NN的狀態切換。ActiveNN對外提供服務,Standby NN在Active NN發生故障時切換為Active NN繼續對外服務。
Active NN響應Client的修改元資料請求,需要記錄元資料的操作日誌(以下稱為EditLog),為了提升EditLog的一致性和可靠性,HDFS設計了JournalNode(以下簡稱JN)叢集,每一次元資料的修改都要同步儲存到JN中。Standby NN是Active NN的後備,他從JN持續拉取EditLog,並將其合併到本地的元資料結構中,隨時待命準備接收Active NN的工作。
本地儲存系統最佳化是在分析HDFS的不同核心元件和元件之間的I/O模型的前提下,為達到高吞吐或高ops的需求,而提出針對性的最佳化方案。共分為四個部分:
-
DN本地檔案系統元資料與資料的快取分離,為大家介紹一種更適合單機海量儲存的檔案系統快取方案
-
本地儲存最佳化案例分析,囊括了我們在實踐中遇到的幾個經典案例
-
本地儲存系統效能實時監控,工欲善其事必先利其器,只有iostat是不夠的
-
磁碟故障監控與自動化運維
>>>> DN本地檔案系統元資料與資料的快取分離
>>>> 本地儲存架構
在介紹快取分離的方案之前,以傳統機械硬碟為例,大致介紹本地儲存系統的架構,如下圖:

Java應用程式,透過檔案相關介面呼叫Java Native Interface(圖中簡稱JNI),再呼叫C Library暴露的系統呼叫介面,觸發軟中斷嵌入到Kernel Space,由Kernel代替應用程式行程執行VFS相應的系統呼叫處理函式;VFS是虛擬檔案系統,是不同型別檔案系統的抽象,我們常用的檔案系統如Ext4、xfs等。為了加速檔案系統的效能,Linux提供了Page Cache機制,這也是本部分的主角了。
再之下是block層,我們看到的磁碟比如/dev/sda,就是block層呈現的;大家耳熟能詳的電梯排程演演算法,就是各類I/O Scheduler的鼻祖。我們聽說過的硬碟介面比如SATA、SAS等都受SCSI框架的統一管理,不同的廠商向Kernel社群貢獻了自有的磁碟驅動。Hardware只需瞭解一些特性。
言歸正傳,本節的主角是Page Cache。
>>>> PageCache
相信很多人會有這樣的經歷,在定位緊急問題時開啟一個很大的日誌檔案往往是一個漫長的過程,很是讓人著急;但是在第二次開啟時基本是秒開。這要歸功於Linux kernel提供的Page Cache機制。
Page Cache一般又分為兩部分:Buffer快取檔案元資料,Cache快取檔案資料。此處的元資料是一個統稱,包括了檔案系統的元資料、檔案的索引節點inode、目錄項Dentry等。inode儲存了檔案長度、屬主、建立日期等關鍵資訊,但不包括檔案名。目錄是一種特殊的檔案,其內容即為Dentry,用來儲存目錄內的子目錄和檔案inode與檔案名稱對應關係。訪問一個檔案是一個很耗時的過程,涉及到多次從磁碟讀取元資料和資料。
從下圖中我們可以看出,Buffer和Cache總共佔用約50G記憶體,正符合Linux的一個設計原則:你用或者不用,它都在那裡,不用白不用。在應用需要這部分記憶體空間時,Page Cache會根據精心設計的記憶體回收演演算法釋放記憶體頁。

>>>> 技術痛點
在超大規模叢集中,單個DN多則承擔千萬個Block,在這樣的極端場景下,Buffer和Cache的加速效果越來越差。主要原因是記憶體太小,磁碟嫌少。從容量比來看,記憶體幾十GB/元資料總量幾十GB/資料總量幾十TB,記憶體大小和資料總量對比約為1:1000,在多租戶隨機讀寫情況下,資料熱度極度分散,Page Cache的命中率比較低。
再加上DataNode的掃盤/錯誤檢查/du等操作需要訪問千萬級檔案和目錄的元資料,元資料多數為小塊I/O,常見的是4KiB,大部分元資料因無法命中Buffer而需要從磁碟讀取,搶佔磁碟IOPS,嚴重影響DN對外服務。再加上檔案系統元資料和資料一般非連續儲存,因此元資料讀寫加劇了磁頭的抖動,破壞了資料讀寫的連續性,最終導致磁碟吞吐遠低於預期。從下圖中,可以看出磁碟繁忙度持續在100%,本來有100+MB/s頻寬的硬碟實際上只發揮出不足4MB/S。

那如何來緩解這樣的問題呢,我們最初想到將元資料和資料從物理上分離開,即把元資料放到更快更強的非易失快閃記憶體,但是業界還沒有足夠成熟穩定的開源檔案系統,因為檔案系統是資料的根基,要十分謹慎小心。後來我們註意到記憶體容量和元資料總量旗鼓相當,那麼我們能不能用Page Cache盡可能多的快取元資料,這樣我們不會觸及檔案系統的任何修改,應用也無感知。
Linux Kernel並不提供機制讓系統管理員來控制Buffer和Cache的比例,而且前面的示例中也體現出Buffer和Cache的差距,那麼想要達到盡可能多的快取元資料的目的,只能從Page Cache的原理入手,修改Buffer和Cache的機制。
Cache與Buffer實際上共用File LRU連結串列,使用相同的記憶體回收策略。這也是為什麼Buffer總是比Cache小很多的原因,因為搶不過嘛。
>>>> 最佳化方案
要單獨控制Buffer,需要將Buffer從File LRU連結串列中獨立,新建Buffer LRU連結串列及回收策略:
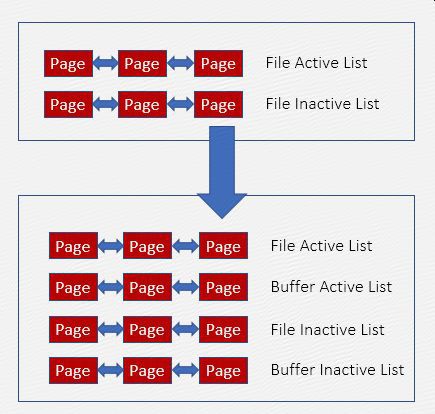
1、優先回收Cache
2、按比例回收Cache和Buffer
如果Cache不滿足回收條件,則按比例同時強制回收Buffer和Cache,可以配置100%回收Cache,不回收Buffer。
3、限制Buffer的記憶體佔比
不回收Buffer易造成其記憶體佔用量的持續增加,影響記憶體分配效率,因此需限制Buffer佔總記憶體的比例,需要合理規劃應用程式和Buffer的佔比,防止OOM。如果Buffer超出閾值,則強制回收一部分。
>>>> 最佳化效果
最佳化前,Cache平均佔用32G,Buffer平均佔用8G,總佔用約41G;

最佳化後,Cache平均佔用13G,Buffer平均佔用29G,總佔用約42G;

對比最佳化前後,說明在不擠壓應用程式可用記憶體的情況下,Page Cache總體實現了我們的最佳化標的–更多的快取元資料。
下圖橫坐標代表讀請求的大小,單位為KB,縱坐標為讀次數。在1分鐘統計時間內,4KB小塊讀的次數下降了27倍。

最佳化後,在DataNode的掃盤/錯誤檢查/du等操作期間,磁碟繁忙度未出現突出變化,磁碟讀吞吐保持平穩,在磁碟不繁忙的情況下,保持在10MB/s。
>>>> 本地儲存最佳化案例分析
>>>> 最佳化Edit log同步
如有必要,請先回顧文章開始對HDFS架構的描述,此處不再贅述。
1、問題描述
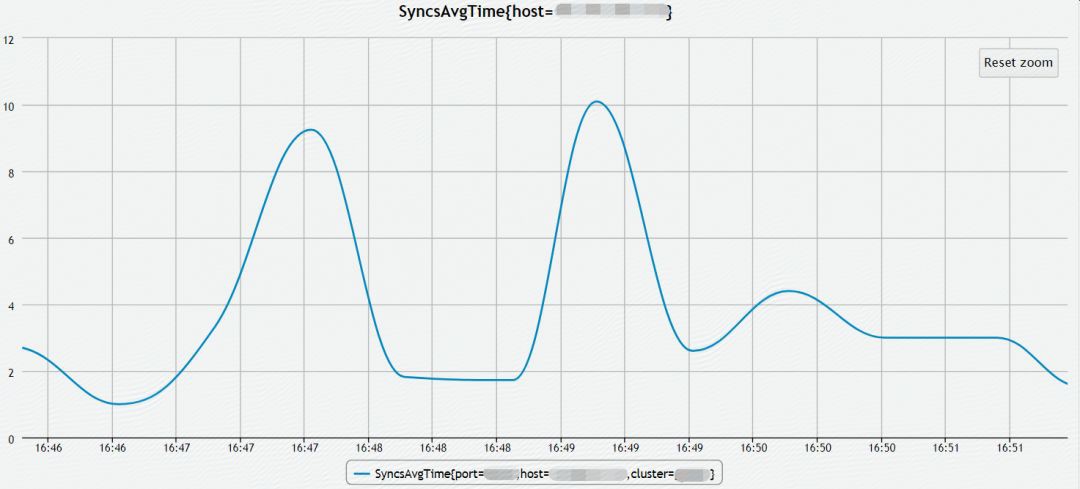
NameNode在響應Client修改檔案元資料的請求時,為保證元資料的原子性,需同步地向JournalNodes傳輸Editlog(小檔案),JournalNode在接收到Editlog後同步地寫入本地檔案系統,同時NameNode也需要將Editlog寫入本地檔案系統。為了保證每一條Editlog寫入磁碟,NameNode和JournalNode在寫入Editlog時呼叫flushAndSync(),如下圖所示,此過程消耗了大部分時間。雖然EditLog可以批次傳輸、批次寫入檔案系統,但是如果這個過程耗時過長,還是會嚴重影響NameNode的OPS。

NameNode有相應的指標來衡量同步EditLog的平均延遲時間,下圖是最佳化前的記錄,Syncs時間普遍大於20ms,而且波動很大,對QoS會產生嚴重的影響。

2、問題分析
從時延預估角度來看,在不考慮網路延遲的情況下,檔案系統一次寫請求的延遲時間大於20ms,是不符合預期的。從Java到kernel一步步來追蹤問題的根本原因,我們發現是fdatasync系統呼叫耗費了大部分時間。

# strace -f -p-T -e trace=fdatasync
[pid 18493] fdatasync(267) = 0 <0.043851>
[pid 18495] fdatasync(267) = 0 <0.036754>
[pid 18496] fdatasync(267) = 0 <0.043374>
3、檔案系統效能測試
為了驗證檔案系統的IOPS,透過fio測試檔案系統4k sync write的效能,IOPS=25,換算為平均延遲時間約為40ms。
file1: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W)4096B-4096B, (T) 4096B-4096B, ioengine=sync, iodepth=1
fio-3.1
Jobs: 1 (f=1): [w(1)][9.3%][r=0KiB/s,w=100KiB/s][r=0,w=25IOPS][eta 01h:07m:36s]
4、分析IO流程
透過blktrace分析I/O具體流程,某次flush請求執行時間約42ms,與fdatasync的時延吻合。
8,160 29 531 1.052751598 1156 AFWFS 5859838192 + 8 8,161) 5859836144
8,161 29 532 1.052751978 1156 QFWFS 5859838192 + 8 [jbd2/sdk1-8]
8,161 29 533 1.052752704 1156 GFWFS 5859838192 + 8 [jbd2/sdk1-8]
8,161 29 534 1.052753334 1156 IFWFS 5859838192 + 8 [jbd2/sdk1-8]
8,161 29 535 1.052754684 1156 DFWFS 5859838192 + 8 [jbd2/sdk1-8]
8,161 28 422 1.094201746 1156 CFWFS 5859838192 + 8 [0]
FWFS型別的I/O操作一般由Flush引發,Flush一般由檔案系統的barrier功能觸發,檢查檔案系統掛載引數,未指定關閉barrier,也就是說barrier預設是開啟的。
/dev/sdk1 on /data10 type ext4(rw,relatime,data=ordered
5、barrier為何物
檔案系統為了在核心崩潰、異常斷電等異常情況下保證完整性,必須保證寫資料時將資料、元資料、日誌寫入磁碟介質。然而一般情況下,即使是同步寫,資料也不會立即寫入到磁碟中,而是先寫入到磁碟自身的快取中。barrier是保護檔案系統完整性的安全特性。
barrier會觸發flush操作,將磁碟快取內的臟資料刷回磁碟介質。在flush操作完成前,磁碟無法處理後來的I/O請求;同時現代磁碟快取越來越大,導致flush變成一個漫長的過程。總之,barrier以犧牲檔案系統效能為代價,換取檔案系統完整性。
6、barrier可以關閉嗎?
若RAID卡或磁碟本身支援掉電保護,則可關閉barrier功能;
若RAID卡和磁碟不支援或關閉寫快取,也可關閉barrier功能
7、最佳化方案
檔案系統禁用barrier,掛載引數新增nobarrier
/dev/sdl1 on /data11 type ext4 (rw,relatime,nobarrier,data=ordered)
關閉磁碟寫快取
hdparm -W 0 /dev/sdX
關閉RAID卡寫快取
透過RAID卡管理工具關閉寫快取
8、最佳化效果
透過fio測試檔案系統4k sync write的效能, IOPS提升至180左右
file1: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W)4096B-4096B, (T) 4096B-4096B, ioengine=sync, iodepth=1
fio-3.1
bs: 1 (f=1): [w(1)][11.2%][r=0KiB/s,w=748KiB/s][r=0,w=187IOPS][eta 02m:39s]
NameNode的Syncs指標下降到10ms以下。
>>>> DataNode目錄結構最佳化
1、龐大的目錄規模
HDFS Block儲存在DataNode,由Block id計算出最終block儲存在哪個子目錄。

單個DataNode的目錄數估算:256 x 256 x NS個數 x Disk個數
以10個Namespace,12個磁碟為例,目錄總個數約為:
256 x 256x 10 x 12 = 7864320 ≈786萬
2、易導致I/O瓶頸
DataNode的Block report、DU、DirectoryScanner等過程會掃描所有subdir目錄,因目錄數量龐大,作業系統的Buffer Cache不足以快取所有目錄項及索引節點,因此需要從磁碟讀取。因掃描過程持續時間較長,磁碟壓力過大,嚴重影響DataNode響應Client的IO請求。
3、最佳化方案
目錄結構從256 x 256升級為32 x 32
以10個Namespace,12個磁碟為例,目錄總個數約為:
32x 32 x 10 x 12 = 122880 ≈12萬
4、最佳化效果
以DataNode全量彙報Block時間為例,時間由接近1小時,下降為78秒。
|
NS*Disk |
10*12 |
10*12 |
|
目錄結構 |
256x256 |
32x32 |
|
總目錄數 |
7864320 |
122880 |
|
report耗時 |
0:57:54 |
0:01:18 |
>>>> 本地儲存系統效能實時監控
我們在遇到很多案例之後發現Linux kernel沒有很好地提供我們想要的工具或者介面來實時的監控儲存系統的效能,這使我們在分析I/O問題時感覺非常麻煩。
為了更方便、直觀、實時地監控儲存系統的I/O行為和效能表現,需要在kernel中開發相應的功能介面,暴露給使用者。
不同型別的I/O size實時統計:

不同型別的I/O Latency實時統計:
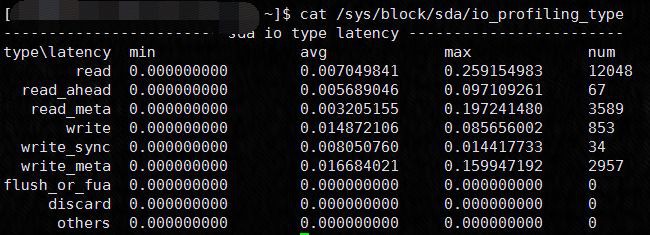
I/O Stage Latency實時統計:
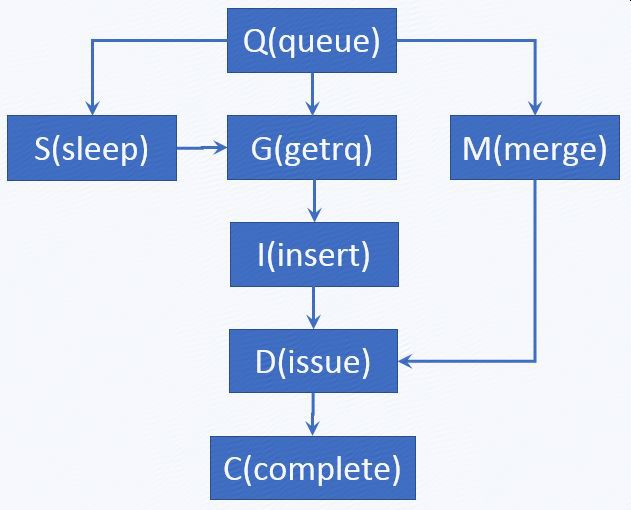
queue: I/O 到達block層
getrq:I/O分配到request
sleep:request不足,I/O需等待
merge:I/O合併到已分配的request
insert:request插入到request佇列
issue:request傳送到裝置驅動
complete:request完成

S2G:如果出現多次,說明請求佇列過小或併發度過高
Q2M:多次I/O合併為一次,有益於提升磁碟效能
D2C:裝置驅動及以下協議棧處理I/O的效率
Q2C:整個I/O協議棧的處理效率
>>>> 磁碟故障監控與自動化運維
在超大規模叢集中,磁碟和raid卡的硬體故障是很頻繁的,會嚴重的影響QoS,因此需要及時發現、及時報警、及時報修。Kernel層及驅動層是感知磁碟故障的第一線。
故障型別與自動化運維策略:
|
故障型別 |
自動踢盤 |
自動報警 |
自動報修 |
|
磁碟介質損壞 |
✔ |
✔ |
✔ |
|
磁碟連結錯誤 |
✔ |
✔ |
✔ |
|
磁碟IO響應慢 |
✘ |
✔ |
✘ |
|
磁碟reset超時 |
✔ |
✔ |
✘ |
|
raid卡IO響應慢 |
✘ |
✔ |
✘ |
|
raid卡頻繁reset |
✘ |
✔ |
✘ |
|
raid卡故障 |
✔ |
✔ |
✔ |
轉載自:京東技術。
投稿:有投稿意向技術人請在公眾號對話方塊留言。
轉載:意向文章下方留言。
更多精彩請關註 “資料和雲” 公眾號 。

