導語:F1是Google的分散式資料庫,問世以來一直受到大家的關註。其中分散式查詢引擎怎麼實現,也一直是資料庫界最關心的問題之一。F1團隊在VLDB2018上發表了論文詳細論述該話題。本文是對該問題的詳細剖析,十分值得架構師和資料庫從業人員學習。
F1 是起源於 Google AdWords 的分散式 SQL 查詢引擎,跟底下的 Spanner 分散式儲存搭配,開啟了分散式關係資料庫——所謂 NewSQL 的時代。我們今天說的是 F1 團隊在 VLDB2018 上發的文章 F1 Query: Declarative Querying at Scale [1],它和之前我們說的 F1 幾乎是兩個東西。
F1 Query 是一個分散式的 SQL 執行引擎,現在大資料領域流行的 Presto、Spark SQL、Hive 等等,都可以算在這個範疇裡。類似地,F1 Query 也支援對各種不同資料源的查詢,既可以是傳統的關係表、也可以是 Parquet 這樣的半結構化資料。
這樣一來,不同資料格式的壁壘也被打破了:你可以在一個系統裡完成對不同資料源的 Join,無論資料以什麼形式存放在哪裡。商業上管這個叫 Federated Query 或者 DataLake,幾家雲端計算巨頭都有類似的產品。
那 F1 Query 的貢獻在哪裡呢?
F1 Query 定義了三種不同型別的查詢執行樣式,根據查詢的資料量大小或執行時間,將使用者查詢劃分成:
-
單機執行(Centralized Execution)
-
分散式執行(Distributed Execution)
-
批處理執行(Batch Execution)
前兩個是互動式的,即客戶端會等待結果傳回。最後一個批處理更像是 ETL:客戶端輸入任務之後就不再管了,查詢結果會被寫到指定的地方。
單機執行
單機執行對應我們熟悉的 OLTP 查詢,例如單表點查、帶索引的 Join 等。這類查詢本身已經足夠簡單,只需幾毫秒就能做完,處理它們的最好方式就是在收到請求的機器上立即執行。
在 F1 Query 系統中有 F1 Server 和 F1 Worker 等角色。F1 Server 負責接收客戶端請求,如果它判斷這個查詢應當使用單機而不是分散式方式執行,它就親力親為、直接執行並傳回結果。
這樣的行為和絕大多數單機 OLTP 資料庫是一致的,例如 MySQL 採用的是 Thread Pool + Dispatcher 的處理模型,Thread Pool 的規模是一定的,Dispatcher 根據高低優先順序分派執行任務。最終一個請求只會被一個執行緒處理,換句話說,對某個查詢來說其執行過程是單執行緒的。

▲ MySQL 的執行緒池處理模型,一般存在多個 Thread Group,圖中描繪了一個 Thread Group
F1 Query 單機查詢的執行器同樣也是教科書式的 Valcano 模型,但也無可厚非——對 OLTP 來說這已經足夠好。如下圖所示,從頂層運算元開始遞迴地呼叫 GetNext(),每次取出一行資料,直到沒有更多資料為止。各個運算元只需要實現 GetNext() 介面即可,簡單清晰。

分散式執行
F1 Query 對更複雜的查詢,例如沒有索引的 Join 或聚合等,則採取分散式查詢的方式。大部分 OLAP 查詢、尤其是 Ad-hoc 的查詢都落在這一分類中。這種情況下,分散式導致的網路、排程等 Overhead 已經遠小於查詢本身的成本;而且隨著資料量的增加,單節點記憶體顯然不夠用了。
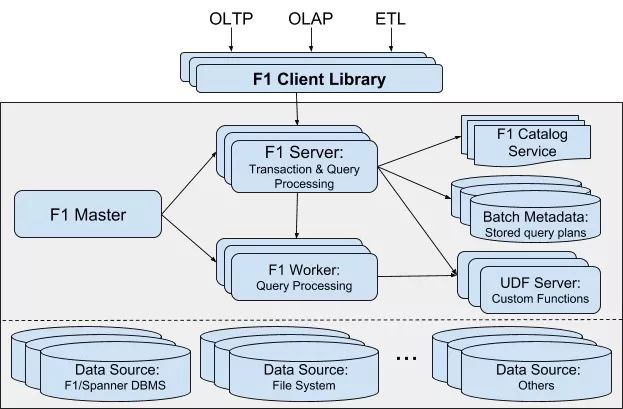
▲ *F1 Query 的系統架構,主要包含 F1 Master、F1 Server、F1 Worker 三個角色,其他 Catalog、UDF Server、Batch Metadata 用於儲存查詢相關的 Metadata 等*
這時,上圖中的 F1 Worker 就派上用場了。F1 Server 此時僅僅作為協調者存在,將任務分配給多個 Worker,直到 Worker 的任務全都完成,再把結果彙總發給客戶端。
這個樣式眼熟嗎?你可能會想到 Greenplum 這類的資料倉庫,已經很接近了。最相似的我認為是 Presto。Presto 是 Facebook 開發的一套分散式 SQL 引擎,如果單單隻看 F1 Query 的分散式查詢,和 Presto 大同小異。
與單機執行不同的是,分散式查詢中的運算元可以有多個實體(Instance)並行執行,每個實體負責其中一部分資料。在 F1 Query 裡這樣一個資料分片被稱為 Fragment,在 Spark SQL 裡叫 Partition,在 Presto 裡叫 Split。
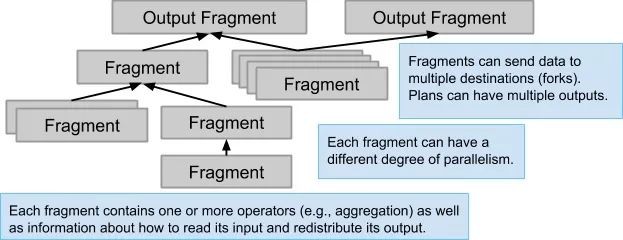
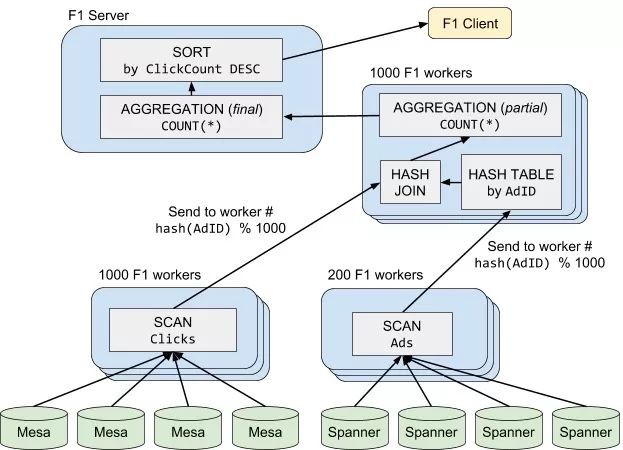
下麵的例子是一個 Join-Aggregation-Sort 的查詢,它分成了 4 個階段:
-
Scan(Clicks)被分配給 1000 個 F1 Worker 上並行拉取資料,並根據每一行資料的Hash(AdID)傳送給對應的HashJoin分片,即一般說的 shuffle 過程; -
Scan(Ads)被分配給 200 個 F1 Worker 上並行拉取資料,並且也以同樣的方式做 shuffle; -
HashJoin及PartialAggregation:根據 Join Key 分成了 1000 個並行任務,各自做 Join 計算,並做一次聚合; -
最後,F1 Server 把各個分片的聚合結果再彙總起來,傳回給客戶端。
Presto 具有的缺陷,F1 Query 分散式查詢同樣也有,比如:
-
純記憶體的計算方式,無法利用磁碟的儲存空間,某些查詢可能面臨記憶體不足;
-
沒有 Fault-tolerance,對於一個涉及上千臺 Worker 的查詢,任何一臺的重啟都會導致查詢失敗。
批處理執行
F1 Query 還有個獨特的批處理執行,這個樣式定位於更大的資料量、更久的查詢時間;另一方面,它的結果不再是傳回給客戶端,而是將查詢結果寫到指定的地方,例如 Colossus(第二代 GFS)上。
上一節我們提道,Presto 的樣式沒有 Fault-tolerance,這對於長時間執行的批處理任務是致命的,查詢失敗的機率會大大增加。批處理查詢首先要解決的就是 Fault-tolerance 問題:必須能以某種方式從 Worker 節點的失敗中恢復。
解決這個問題有兩條路可走:一是 MapReduce 的樣式,將計算分成若干個階段(Stage),而中間結果持久化到 HDFS 這樣的分散式檔案系統上;二是 Spark RDD 樣式,透過記錄祖先(Lineage)資訊,萬一發生節點失敗,就透過簡單的重算來恢復丟失的資料分片,這樣資料就可以放在記憶體裡不用落盤。
Spark 的做法顯然是更先進的,原因有很多,這裡只說最重要的 2 條。欲知詳情可以看我之前的部落格文章《一文讀懂 Apache Spark》[2]。
-
Spark 的計算基本在記憶體中,只有當記憶體不夠時才會上限溢位到磁碟,而 MR 的中間結果必須寫入外部檔案系統;
-
Spark 可以把執行計劃 DAG 中相互不依賴的 Stage 並行執行,而 MR 只能線性地一個接一個 Stage 執行。
但是出乎意料的是,F1 Query 採用的是前者,也就是 MR 樣式。這其中的原因我們不得而知,我猜想和 Google 自家的 FlumeJava 不夠給力有關係。
如下圖。左邊的 Physical Plan 和上一節的分散式查詢是一樣的,不同之處是在批處理樣式下,它被轉換成一系列的 MR 任務,之後交給排程器(Scheduler)去處理即可。
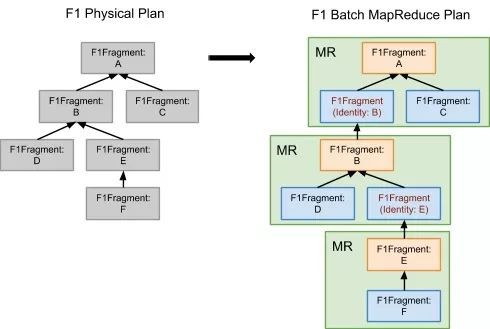
相比分散式執行,批處理樣式下各個步驟都會持久化到外部檔案系統(因為 MapReduce 的特性所致)。不僅如此,Pipeline 式的執行也沒法進行。以上一節提到的 HashJoin 為例,左邊 Clicks 的 Scan 和 HashJoin 原本是可以 Pipeline 執行的,但是在批處理樣式下,必須等到 Scan(Clicks) 這個階段完成才能進行下一步的 HashJoin 階段。
單機並行執行
除了上面聊的 F1 Query 所支援的 3 種查詢樣式之外,事實上還有一種處理模型位於單執行緒執行和分散式執行之間:單機的並行執行。初看這似乎與分散式執行很相似,但又有些不同:
-
不用考慮單個 Worker 的失敗恢復,因為它們都在同一個行程裡;
-
各個 Worker 執行緒的記憶體是共享的,它們之間交換資料無需考慮網路通訊代價。
這種樣式在傳統的關係型資料庫上很常見,尤其是 Postgres、SQL Server 這類以 OLAP 查詢見長的選手。以 Postgres 為例,在開啟並行查詢的情況下,查詢最佳化器會根據代價選擇是否生成並行執行計劃;如果生成了並行執行計劃,執行器會排程多個 Worker 一起完成工作。
下圖是一個 Postgres 上並行 Hash Join 的例子,從執行計劃上看和上一節幾乎一樣,但是這裡不再需要對資料做 Shuffle:Hash Join 所用的 Hash Table 本身是全域性共享的。

Parallel Hash Join 並非只有這一種做法。SQL Server 就更接近分散式執行的方案:把 Hash Key 相同的資料 shuffle 到同一個分片上——但這個 shuffle 只是邏輯上的,不需要真的做 IO。
相比分散式查詢,單機並行的最大優勢在於響應速度更快,因為省去了大量的網路 IO 時間,而且排程一個 Worker 執行緒要比排程一個 Worker 機器快得多。
但別忘了,單機運算能力的 scale up 成本非常高,並且是存在上限的。對於 Google 之類的網際網路公司,絕大部分查詢都超出了單機的儲存或計算能力,我猜測這也是 F1 Query 並未考慮單機並行的理由。
對 F1 Query 的評價
從論文描述的情況來看,F1 Query 還不算個完善、成熟的系統,其定位更像是一個解決業務需求的膠水系統,而非 Spanner 這樣的“硬核”技術。它追求的是夠用就好。很多地方其實還有不小的改進空間,舉幾個例子:
-
對互動式查詢,選擇分散式還是單機計算目前還是基於啟髮式規則。
-
三種樣式的執行計劃是用一樣的最佳化器生成的。但是客觀的說,這其中的差別可是不小的。
-
最佳化器是基於規則的。之所以不做 CBO,論文給出的解釋是資料源眾多,不容易估算代價。
-
批處理樣式下用 Spark 取代 MR 的樣式是更好的選擇。
F1 Query 希望用一套系統解決所有 OLTP、OLAP、ETL 需求、用一套系統訪問資料中心裡各種格式的資料,這兩點才是 F1 Query 的核心競爭力。
SQL 執行樣式總結
從資料庫的視角看,理想的資料庫應當隱藏掉查詢執行的種種細節,只要使用者輸入一個宣告(例如 SQL),就能以最優的方式執行查詢給出答案。F1 Query 做了個勇敢的嘗試,它將多種執行模型揉合在一個系統中,共享同一套最佳化器和運算元,以較低的開發成本獲得其中最優的執行效能(在理想情況下)。
下麵的表格總結了 4 種執行樣式的優勢和不足。

總而言之,所謂 No Free Lunch[3] —— 沒有最優的方案,資料量是決定能選用哪個執行樣式的前提。實踐中,先確保資料量能夠承載的下,再談最佳化也就明白多了。
References
-
F1 Query: Declarative Querying at Scale
-
MySQL Thread Pool Implementation
-
Presto 實現原理和美團的使用實踐 – 美團技術團隊
文中連結:
[1] http://www.vldb.org/pvldb/vol11/p1835-samwel.pdf
[2] https://ericfu.me/apache-spark-in-nutshell/
[3] https://en.wikipedia.org/wiki/No_free_lunch_theorem

關註DRDS樂園公眾號,獲取更多分散式資料庫相關資訊。
活動預告:
11 月 23 ~ 24 日,GIAC 全球網際網路架構大會將於上海舉行。GIAC 是高可用架構技術社群推出的面向架構師、技術負責人及高階技術從業人員的技術架構大會。今年的 GIAC 已經有微軟,騰訊、阿裡巴巴、螞蟻金服,華為,科大訊飛、新浪微博、京東、七牛、美團點評、餓了麼,才雲,格靈深瞳,Databricks,等公司專家出席。
本期 GIAC 大會上,資料庫和大資料部分精彩的議題如下:

參加 GIAC,盤點2018最新技術。點選“閱讀原文”瞭解大會更多詳情。
