關註獲得更多內容
精彩預告:第八屆資料技術嘉年華大會將於2018年11月16日~17日在北京市富力萬麗酒店盛大開啟。本次大會圍繞資料、智慧、連結組織前沿議題,倡導以智慧智慧演演算法應用,發掘資料價值,以技術將企業連結到未來的戰略制高點!
福利:全場通票等你搶
點選“原文連結”檢視大會詳情。
作者:董明鑫,雪球網運維開發架構師,曾就職百度,2014 年加入雪球,目前主要負責保障雪球穩定性、提升資源利用率及提高開發效率等方面。關註容器生態圈的技術發展。
來自:51cto技術棧(ID:blog51cto)
雪球目前擁有一千多個容器,專案數量大概有一百多個,規模並不是很大。但是得益於容器技術,雪球部署的效率非常高,雪球的開發人員只有幾十個,但是每個月的釋出次數高達兩千多次。

2018 年 5 月 18-19 日,由 51CTO 主辦的全球軟體與運維技術峰會在北京召開。在“開源與容器技術”分會場,雪球 SRE 工程師董明鑫帶來了《容器技術在雪球的實踐》的主題分享。
本文主要分為如下三個方面跟大家分享雪球在業務中引入和使用容器技術的心路歷程:
-
為什麼要引入 Docker
-
Docker 在雪球的技術實踐
-
後續演進
雪球是一個投資者交流的社群,使用者可以在上面買賣股票,代銷基金等各種金融衍生業務,同時也可以透過雪盈證券來進行滬、深、港、美股的交易。
為什麼要引入 Docker

隨著業務的發展,不同的社群業務之間所受到影響的機率正在逐漸升高,因此我們希望各個業務之間既能夠不被打擾,又能在資源上、機器間、甚至網路上根據監管的要求予以不同層面的隔離。
早在 2014 年時,我們就發現容器技術具有本身映象小、靈活、啟動速度快等特點,而且在效能上比較適合於我們當時物理機不多的規模環境。
相比而言,傳統的虛擬化技術不但實現成本高,而且效能損耗也超過 10%。因此,基於對映象大小、啟動速度、效能損耗、和隔離需求的綜合考慮,我們選用了兩種容器引擎:LXC 和 Docker。
我們把 MySQL 之類有狀態的服務放在 LXC 裡;而將線上業務之類無狀態的服務放在 Docker 中。

容器使用方法
眾所周知,Docker 是以類似於單機的軟體形態問世的,最初它的宣傳口號是:Build/Ship/Run。
因此它早期的 Workflow(流程)是:
-
在一臺 Host 主機上先執行 Docker Build。
-
然後運用 Docker Pull,從映象倉庫裡把映象拉下來。
-
最後使用 Docker Run,就有了一個執行的 Container。
需要解決的問題
上述的流程方案伴隨著如下有待解決的問題:
-
網路連通性,由於是單機軟體,Docker 最初預設使用的是 Bridge 樣式,不同宿主機之間的網路並不相通。因此,早期大家交流最多的就是如何解決網路連通性的問題。
-
多節點的服務部署與更新,在上馬該容器方案之後,我們發現由於本身效能損耗比較小,其節點的數量會出現爆炸式增長。
因此,往往會出現一臺物理機上能夠執行幾十個節點的狀況。容器節點的絕對數量會比物理節點的數量大一個數量級,甚至更多。那麼這麼多節點的服務部署與更新,直接導致了工作量的倍數增加。
-
監控,同時,我們需要為這麼多節點的執行狀態採用合適的監控方案。
Docker 在雪球的技術實踐

網路樣式
首先給大家介紹一下我們早期的網路解決方案:在上圖的左邊,我們預設採用的是 Docker 的 Bridge 樣式。
大家知道,預設情況下 Docker 會在物理機上建立一個名為 docker0 的網橋。
每當一個新的 Container 被建立時,它就會相應地創建出一個 veth,然後將其連到容器的 eth0 上。
同時,每一個 veth 都會被分配到一個子網的 IP 地址,以保持與相同主機裡各個容器的互通。
由於在生產環境中不只一張網絡卡,因此我們對它進行了改造。我們產生了一個“網絡卡系結”,即生成了 bond0 網絡卡。我們透過建立一個 br0 網橋,來替換原來的 docker0 網橋。
在該 br0 網橋中,我們所配置的網段和物理機所處的網段是相同的。由於容器和物理機同處一個網段,因此核心上聯的交換機能夠看到該容器和不同宿主機的 MAC 地址。這就是一個網路二層互通的解決方案。

該網路樣式具有優劣兩面性:
-
優點:由於在網路二層上實現了連線互通,而且僅用到了核心轉發,因此整體效能非常好,與物理機真實網絡卡的效率差距不大。
-
缺點:管理較為複雜,需要我們自己手動的去管理容器的 IP 和 MAC 地址。
由於整體處於網路大二層,一旦系統達到了一定規模,網路中的 ARP 包會產生網路廣播風暴,甚至會偶發出現 PPS(Package Per Second)過高,網路間歇性不通等奇怪的現象。
由於處於底層網路連線,在實現網路隔離時也較為複雜。
服務部署

對於服務的部署而言,我們最初沿用虛擬機器的做法,將容器啟動起來後就不再停下了,因此:
-
如果節點需要新增,我們就透過 Salt 來管理機器的配置。
-
如果節點需要更新,我們就透過 Capistrano 進行服務的分發,和多個節點的部署操作,變更容器中的業務程式。

其中,優勢為:
-
與原來的基礎設施相比,遷移的成本非常低。由於我們透過復用原來的基礎設施,直接將各種服務部署在原先的物理機上進行,因此我們很容易地遷移到了容器之中。
而對於開發人員來說,他們看不到容器這一層,也就如同在使用原來的物理機一樣,毫無“違和感”。
-
與虛擬機器相比,啟動比較快,執行時沒有虛擬化的損耗。
-
最重要的是一定程度上滿足了我們對於隔離的需求。
而劣勢則有:
-
遷移和擴容非常繁瑣。例如:當某個服務需要擴容時,我們就需要有人登入到該物理機上,生成並啟動一個空的容器,再把服務部署進去。此舉較為低效。
-
缺乏統一的平臺進行各種歷史版本的管理與維護。我們需要透過檔案來記錄整個機房的容器數量,和各個容器的 IP/MAC 地址,因此出錯的可能性極高。
-
缺少流程和許可權的控制。我們基本上採用的是原始的管控方式。
自研容器管理平臺
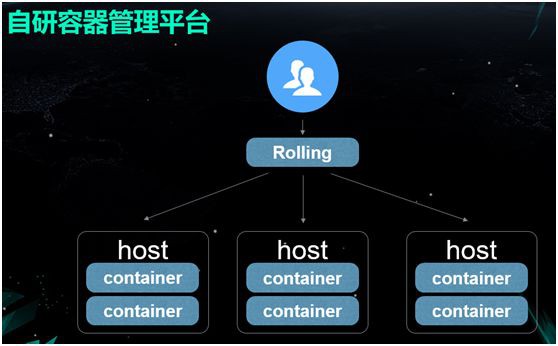
面對上述缺點,我們需要自行研發一個容器管理平臺,去管理各種物理機、容器、IP 與 MAC 地址、以及進行流程控制。

因此我們變更的整套釋出流程為:
-
由開發人員將程式碼提交到程式碼倉庫(如 Github)之中。
-
觸發一個 Hook 去構建映象,在構建的同時做一些 CI(持續整合),包括靜態程式碼掃描和單測等。
-
將報告附加到映象的資訊裡,並存入映象倉庫中。
-
部署測試環境。
-
小流量上線,上線之後,做一些自動化的 API Diff 測試,以判斷是否可用。
-
繼續全量上線。
映象構建

有了容器管理平臺,就會涉及到映象的自動構建。和業界其他公司的做法類似,我們也使用的是基於通用作業系統的映象。
然後向映象中新增那些我們公司內部會特別用到的包,得到一個通用的 base 映象,再透過分別加入不同語言的依賴,得到不同的映象。
每次業務版本釋出,將程式碼放入相應語言的映象即可得到一個業務的映象。構建映象的時候需要註意儘量避免無用的層級和內容,這有助於提升儲存和傳輸效率。
系統依賴
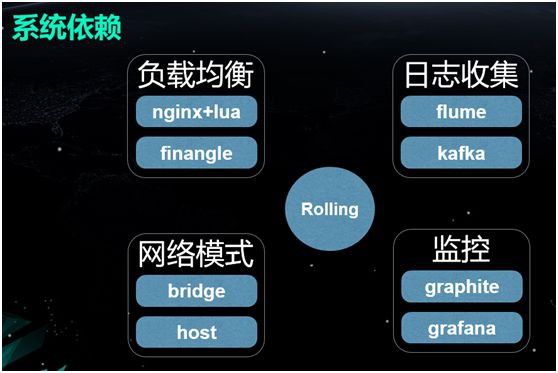
我們的這一整套解決方案涉及到瞭如下週邊的開源專案與技術:
負載均衡
由於會頻繁發生節點的增減,我們該如何透過流量的排程和服務的發現,來實現自動加入負載均衡呢?對於那些非 Http 協議的 RPC,又該如何自動安全地摘掉某個節點呢?
我們在此使用了 Nginx+Lua(即 OpenResty),去實現邏輯並動態更改 Upstream。
當有節點啟動時,我們就能夠將它自動註冊與加入;而當有節點被銷毀時,也能及時將其摘掉。
同時,我們在內部使用了 Finagle 作為 RPC 的框架,並透過 ZooKeeper 實現了服務的發現。
日誌收集
由於節點眾多,我們需要進行各種日誌的收集。在此,我們大致分為兩類收集方式:
-
一類是 Nginx 這種不易侵入程式碼的,我們並沒有設法去改變日誌的流向,而是讓它直接“打”到物理機的硬碟上,然後使用 Flume 進行收集,傳輸到 Kafka 中。
-
另一類是我們自己的業務。我們實現了一個 Log4 Appender,把日誌直接寫到 Kafka,再從 Kafka 轉寫到 ElasticSearch 裡面。
網路樣式
在該場景下,我們採用的是上述提到的改進後的 Bridge+Host 樣式。
監控系統

監控系統由上圖所示的幾個元件所構成。它將收集(Collector)到的不同監控指標資料,傳輸到 Graphite 上,而 Grafana 可讀取 Graphite 的資訊,並用圖形予以展示。
同時,我們也根據內部業務的適配需要,對報警元件 Cabot 進行了改造和定製。

此時我們的平臺已經與虛擬機器的用法有了較大的區別。如上圖所示,主要的不同之處體現在編譯、環境、分發、節點變更,流程控制、以及許可權控制之上。我們的用法更具自動化。

由於是自行研發的容器管理平臺,這給我們帶來的直接好處包括:
-
流程與許可權的控制。
-
程式碼版本與環境的固化,多個版本的釋出,映象的管理。
-
部署與擴容效率的大幅提升。
但是其自身也有著一定的缺點,包括:
-
在流程控制邏輯,機器與網路管理,以及本身的耦合程度上都存在著缺陷。因此它並不算是一個非常好的架構,也沒能真正實現“高內聚低耦合”。
-
由於是自研的產品,其功能上並不完善,沒能實現自愈,無法根據新增節點去自動選擇物理機、並自動分配與管理 IP 地址。
引入 Swarm

2015 年,我們開始著手改造該容器管理平臺。由於該平臺之前都是基於 DockerAPI 構建的。
而 Swarm 恰好能對 Docker 的原生 API 提供非常好的支援,因此我們覺得如果引入 Swarm 的話,對於以前程式碼的改造成本將會降到最低。

那麼我們該如何對原先的網路二層方案進行改造呢?如前所述,我們一直實現的是讓容器的 IP 地址與物理機的 IP 地址相對等。
因此並不存在網路不通的情況。同時,我們的 Redis 是直接部署在物理機上的。
所以依據上圖中各個串列的對比,我們覺得 Calico 方案更適合我們的業務場景。
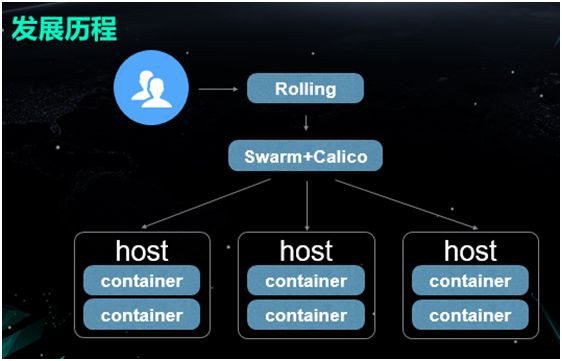
因此,我們在上層使用 Rolling 來進行各種流程的操作,中下層則用 Swarm+Calico 來予以容器和網路的管理。

Calico 使用的是 DownwardDefault 樣式,該樣式透過運用 BGP 協議,來實現對於不同機器之間路由資訊的分發。
在預設情況下,Calico 是 Node 與 Node 之間的 Mesh 方式,即:任意兩個 Node 之間都有著 BGP 連線。
當我們在一臺物理機上啟動了某個容器之後,它就會新增一條包含著從容器 IP 地址到物理機的路由資訊。
由於多臺物理機同處一個 Mesh,那麼每一臺機器都會學習到該路由資訊。而隨著我們系統規模的逐漸增大,每一臺物理機上的路由表也會相應地增多,這就會影響到網路的整體效能。
因此我們需要採用這種 Downward Default 部署樣式,使得不必讓每臺物理機都擁有全量的路由表,而僅讓交換機持有便可。
眾所周知,BGP 會給每一臺物理機分配一個 AS(自治域是 BGP 中的一個概念)號,那麼我們就可以給各臺物理機都分配相同的 AS 號。
而給它們的上聯交換機分配另一個 AS 號,同時也給核心交換機再分配第三種 AS 號。
透過此法,每一臺物理機只會和自己上聯的交換機做路由分發,那麼當有一個新的節點啟動之後,我們便可以將這條路由資訊插入到該節點自己的路由表中,然後再告知與其相連的上聯交換機。
上聯交換機在學習到了這條路由之後,再進一步推給核心交換機。
總結起來,該樣式的特點是:
-
單個節點不必知道其他物理機的相關資訊,它只需將資料包發往閘道器便可。因此單臺物理機上的路由表也會大幅減少,其數量可保持在“單機上的容器數量 +一個常數(自行配置的路由)”的水平上。
-
每個上聯交換機只需掌握自己機架上所有物理機的路由表資訊。
-
核心交換機則需要持有所有的路由表。而這恰是其自身效能與功能的體現。
當然,該樣式也帶來了一些不便之處,即:對於每一個資料流量而言,即使標的 IP 在整個網路中並不存在,它們也需要一步一步地向上查詢直到核心交換機處,最後再判斷是否真的需要丟棄該資料包。
後續演進
在此之後,我們也將 DevOps 的思想和樣式逐步引入了當前的平臺。具體包括如下三個方面:
-
透過更加自助化的流程,來解放運維。讓開發人員自助式地建立、新增、監控他們自己的專案,我們只需瞭解各個專案在平臺中所佔用的資源情況便可,從而能夠使得自己的精力更加專註於平臺的開發與完善。
-
如今,由於 Kubernetes 基本上已成為了業界的標準,因此我們逐步替換了之前所用到的 Swarm,並透過 Kubernetes 來實現更好的排程方案。
-
支援多機房和多雲環境,以達到更高的容災等級,滿足業務的發展需求,並完善叢集的管理。

上圖展示了一種巢狀式的關係:在我們的每一個 Project 中,都可以有多個 IDC。
而每個 IDC 裡又有著不同的 Kubernetes 叢集。同時在每一個集群裡,我們為每一個專案都分配了一個 Namespace。
根據不同的環境,這些專案的 Namespace 會擁有不同的 Deployment。例如想要做到部署與釋出的分離,我們就相應地做了多個 Deployment,不同的 Deployment 標示不同的環境。
預設將流量引入第一個 Deployment,等到第二個 Deployment 被部署好以後,需要釋出的時候,我們再直接把流量“切”過去。
同時,鑒於我們的平臺上原來就已經具有了諸如日誌、負載均衡、監控之類的解決方案。
而 Kubernetes 本身又是一個較為全面的解決方案,因此我們以降低成本為原則,謹慎地向 Kubernetes 進行過渡,儘量保持平臺的相容性,不至讓開發人員產生“違和感”。
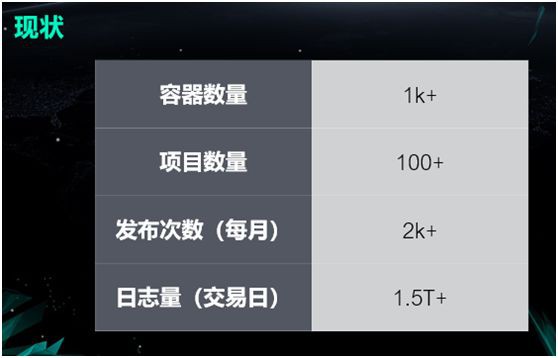
如今,我們的容器只有一千多個,專案數量大概有一百多個。但是我們在部署效率方面的提升還是非常顯著的,我們的幾十個開發人員每個月所釋出的次數就能達到兩千多次,每個交易日的日誌量大概有 1.5T。
Percona釋出XtraBackup for MySQL 8.0

