

GPU英文名稱為Graphic Processing Unit,GPU中文全稱為計算機圖形處理器,1999年由NVIDIA公司提出。
一、GPU概述
GPU這一概念也是相對於計算機系統中的CPU而言的,由於人們對圖形的需求越來越大,尤其是在家用系統和遊戲發燒友,而傳統的CPU不能滿足現狀,因此需要提供一個專門處理圖形的核心處理器。
GPU作為硬體顯示卡的“心臟”,地位等同於CPU在計算機系統中的作用。同時GPU也可以用來作為區分2D硬體顯示卡和3D硬體顯示卡的重要依據。2D硬體顯示卡主要透過使用CPU 來處理特性和3D 影象,將其稱作“軟加速”。
3D 硬體顯示卡則是把特性和3D 影象的處理能力集中到硬體顯示卡中,也就是“硬體加速”。目前市場上流行的顯示卡多半是由NVIDIA及ATI這兩家公司生產的。
1.1、為什麼需要專門出現GPU來處理圖形工作,CPU為啥不可以?
GPU是並行程式設計模型,和CPU的序列程式設計模型完全不同,導致很多CPU上優秀的演演算法都無法直接對映到GPU上,並且GPU的結構相當於共享儲存式多處理結構,因此在GPU上設計的並行程式與CPU上的序列程式具有很大的差異。GPU主要採用立方環境的材質貼圖、硬體T&L;、頂點混合、凹凸的對映貼圖和紋理壓縮、雙重紋理四畫素256位的渲染引擎等重要技術。
由於圖形渲染任務具有高度的並行性,因此GPU可以僅僅透過增加並行處理單元和儲存器控制單元便可有效的提高處理能力和儲存器頻寬。
GPU設計目的和CPU截然不同,CPU是設計用來處理通用任務,因此具有複雜的控制單元,而GPU主要用來處理計算性強而邏輯性不強的計算任務,GPU中可利用的處理單元可以更多的作為執行單元。因此,相較於CPU,GPU在具備大量重覆資料集運算和頻繁記憶體訪問等特點的應用場景中具有無可比擬的優勢。
1.2、GPU如何使用?
使用GPU有兩種方式,一種是開發的應用程式透過通用的圖形庫介面呼叫GPU裝置,另一種是GPU自身提供API程式設計介面,應用程式透過GPU提供的API程式設計介面直接呼叫GPU裝置。
1.2.1、通用圖形庫
透過通用的圖形庫的方式使用GPU,都是透過 OpenGL 或Direct3D這一類現有的圖形函式庫,以編寫渲染語言(Shading Language)的方法控制 GPU 內部的渲染器(Shader)來完成需要的計算。
目前業界公認的圖形程式設計介面主要有OpenGL和DirectX這兩種介面。OpenGL是當前可用於開發可互動、可移植的2D與3D圖形應用程式的首選環境,也是當前圖形應用最廣泛的標準。OpenGL是SGI公司開發的計算機圖形處理系統,是圖形硬體的軟體介面,GL為圖形庫(Graphics Library),OpenGL應用程式不需要關註所在執行環境所處的作業系統與平臺。
只要在任何一個遵循OpenGL標準的環境下都會產生一樣的視覺化效果。與OpenGL類似,DirectX (Directe Xtension)也是一種圖形API。它是由Microsoft建立的多媒體程式設計介面,並已經成為微軟視窗的標準。為適應GPU應用的需求,DirectX則根據GPU新產品功能的擴充與進展及時地定義新的版本,它所提供的功能幾乎與GPU提供的功能同步。
1.2.2、GPU自身程式設計介面
GPU自身提供的程式設計介面主要由提供GPU裝置的兩家公司提供,分別是括NVIDIA的CUDA框架和AMD(ATI)公司於2006年提出了CTM(Close To Metal)框架(備註,最初是ATI公司生產GPU裝置,後被AMD收購)。AMD的CTM框架現在已不在使用,主要是AMD(ATI)於2007 年推出了ATI Stream SDK架構,2008 年AMD(ATI)完全轉向了公開的OpenCL標準,因此AMD(ATI)公司目前已沒有獨立的、私有的通用計算框架。
2007年NVIDIA公司釋出CUDA (Compute Unified Device Architecture)專用通用計算框架。使用CUDA 進行通用計算程式設計不再需要藉助圖形學API,而是使用與C 語言十分類似的方式進行開發。在CUDA 程式設計模型中,有一個被稱為主機(Host)的CPU 和若干個被稱作裝置(Device)或者協處理器(Co-Processor)的GPU。
在該模型中,CPU和GPU協同工作,各司其職。CPU負責進行邏輯性較強的事務處理和序列計算,而GPU 則專註於執行執行緒化的並行處理任務。CPU、GPU 各自擁有相互獨立的儲存器地址空間主機端的記憶體和裝置端的視訊記憶體。一般採用CUDA 框架自己進行程式設計的都一些大型的應用程式,比如石油勘測、流體力學模擬、分子動力學模擬、生物計算、音影片編解碼、天文計算等領域。
而我們一般企業級的應用程式由於開發成本以及相容性等原因,大多數都是採用通用的圖形庫來進行開發呼叫GPU裝置。
1.3、GPU如何工作?
GPU 對於通用計算和圖形處理的內部元件主要有兩部分: 頂點處理器(Vertex Processor)和子素處理器(Fragment Processor)。這種處理器具備流處理機的樣式,即不具有大容量的快存/儲存器可以讀寫,只是直接在晶片上利用臨時暫存器進行流資料的操作。
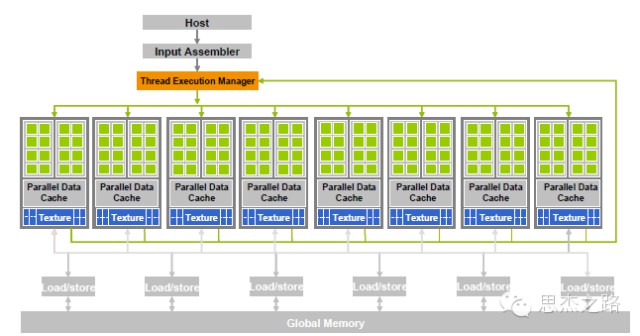
當GPU 用於圖形處理時,此時GPU 內部的頂點渲染、畫素渲染以及幾何渲染操作都可以透過流處理器完成。從圖中可以看出,此時GPU 內部的所有流處理器相當於一個多核的處理器,資料可以很方便的在不同的流處理器之間的輸入和輸出之間移動,同時GPU分派器和控制邏輯可以動態的指派流處理器進行相應的頂點,畫素,幾何等操作,因為流處理器都是通用的。
二、GPU虛擬化
開始我們的正題,目前虛擬機器系統中的圖形處理方式有三種:一種是採用虛擬顯示卡的方式,另一種是直接採用物理顯示卡,最後是採用GPU虛擬化。
2.1、虛擬顯示卡
第一種採用虛擬顯示卡是現在主流的虛擬化系統的選擇,因為專業的顯示卡硬體價格不菲。目前採用虛擬顯示卡的這些技術包括:
-
虛擬網路計算機VNC (Virtual Network Computing)
-
Xen 虛擬幀快取
-
VMware虛擬圖形顯示處理器GPU (Graphics Processing Unit)
-
獨立於虛擬機器管理器的圖形加速系統VMGL (VMM-Independent Graphics Acceleration)。
VNC(Virtual Network Computing)基本上是屬於一種顯示系統,也就是說它能將完整的視窗介面透過網路,傳輸到另一臺計算機的螢幕上。Windows 伺服器中包含的”Terminal Server“即是屬於這種原理的設計。VNC 是由AT&T; 實驗室所開發的,其採用GPL(General Public License)授權條款,任何人都可免費取得該軟體。VNC軟體要由兩個部分組成:VNC server和VNC viewer。使用者需先將VNC server安裝在被遠端操控的計算機上後,才能在主控端執行VNC viewer 進行遠端操控。
XEN虛擬幀快取是指XEN提供的一個虛擬的顯示裝置。該虛擬顯示裝置採用特權域的VNC伺服器,因此該虛擬顯示裝置具有相似的VNC介面。客戶機在XEN虛擬幀快取中寫入資料,然後透過VNC 協議來傳輸已修改的圖片,最後通知前端進行相應區域的更新。這個虛擬幀快取裝置的原始碼是來自開源的Qemu。我們在XenServer上看見虛擬機器的作業系統桌面介面,即是這種技術的顯示。
虛擬網路計算機VNC 和XEN 虛擬幀快取這兩種樣式至今在虛擬機器中仍未提供一定的硬體圖形加速能力。由於目前仍沒有一個機制能使虛擬機器進行訪問圖形硬體的能力,因此這些虛擬的顯示裝置都是透過使用CPU以及記憶體的方式對圖形資料進行相應處理。並沒有採用物理顯示裝置的功能。
然而VMGL這種樣式已經實現了這種機制,這個機制通常被稱為前端-後端虛擬化機制(Front-end virtualization)。VMGL這種樣式採用這個機制將需要圖形處理的資料傳送到一個擁有硬體圖形加速功能的虛擬監控機上進行相應的圖形資料處理。目前存在的比較主流可用於GPU應用程式開發的圖形處理介面有兩類:OpenGL和Direct3D。
在這兩類圖形處理介面中,OpenGL是唯一一類能夠在主流作業系統中跨平臺操作的圖形API介面。在虛擬機器平臺中,VMGL是首個針對OpenGL API進行虛擬化的專案。VMGL的工作原理是,它在客戶端作業系統中部署了一個偽庫(Fake Library)用來取代標準的OpenGL 庫,偽庫(Fake Library)擁有與標準的OpenGL庫相同的介面,在客戶端作業系統中的偽庫也實現了指向遠端伺服器的宿主機作業系統的遠端呼叫。
這樣一來,所有的本地OPENGL呼叫都將被解釋為對遠端伺服器的一次服務請求,遠端伺服器的宿主機作業系統擁有真正的OPENGL庫、顯示卡驅動和物理硬體GPU,它負責完成OPENGL請求並將執行結果顯示到螢幕上。由於VMGL在整個過程操作中都是完全透明的,因此呼叫OPENGL的應用程式不需要修改原始碼也不需要進行二進位制改寫,無需為虛擬機器平臺作任何改動。
2.2、顯示卡直通
顯示卡直通也叫做顯示卡穿透(Pass-Through),是指繞過虛擬機器管理系統,將GPU 單獨分配給某一虛擬機器,只有該虛擬機器擁有使用GPU的許可權,這種獨佔裝置的方法分配方式儲存了GPU的完整性和獨立性,在效能方面與非虛擬化條件下接近,且可以用來進行通用計算。但是顯示卡直通需要利用顯示卡的一些特殊細節,同時相容性差,僅在部分GPU 中裝置可以使用。
Xen 4.0增加了VGA Passthrough技術,因此XenServer也擁有了該技術,XenServer的Passthrough 就是利用英特爾裝置虛擬化(Intel VT-d)技術將顯示裝置暴露給某一個客戶虛擬機器,不僅其它客戶虛擬機器不能訪問,就連宿主虛擬機器也失去了使用該GPU的能力。它在客戶虛擬機器中實現了顯示卡的一些特殊細節,如VGA BIOS、文字樣式、IO 埠、記憶體對映、VESA樣式等,以支援直接訪問。使用Xen Server的 VGA Pass-Through 技術的GPU執行效率高,功能全,但只能被單一系統獨佔使用,失去了裝置復用的功能。VMware ESXi 中包括一個VM Direct Path I/O框架,使用該技術也可以將我們的顯示卡裝置直通給某一虛擬機器進行使用。
XenServer和VMware使用的是不同的技術但是實現的效果都是一樣的,即將物理顯示卡裝置直通給其中的某一虛擬機器使用,以達到虛擬機器進行3D顯示和渲染的效果。
由於顯示卡直通實際上是由客戶作業系統使用原生驅動和硬體,缺少必要的中間層來跟蹤和維護GPU 狀態,它不支援實時遷移等虛擬機器高階特性。如XenServer Passthrough禁止執行Save/Restore/Migration 等操作。VMware的虛擬機器中,一旦開啟VMDirectPath I/O功能,其對應的虛擬機器將失去執行掛起/恢復、實時遷移的能力。
2.3、顯示卡虛擬化(GPU虛擬化)
顯示卡虛擬化就是將顯示卡進行切片,並將這些顯示卡時間片分配給虛擬機器使用的過程。由於支援顯示卡虛擬化的顯示卡一般可以根據需要切分成不同的規格的時間片,因此可以分配給多臺虛擬機器使用。其實現原理其實就是利用應用層介面虛擬化(API remoting),API重定向是指在應用層進行攔截與GPU相關的應用程式程式設計介面(API),透過重定向(仍然使用GPU)的方式完成相應功能,再將執行結果傳回應用程式。
我們現在使用Citrix的3D桌面虛擬化解決方案中,大部分是使用NVIDIA公司提供的顯示卡虛擬化技術,即是vCUDA(virtual CUDA)技術,前面我們說過了CUDA框架,再此不在說明。vCUDA採用在使用者層攔截和重定向CUDA API的方法,在虛擬機器中建立物理GPU的邏輯映像——虛擬GPU,實現GPU資源的細粒度劃分、重組和再利用,支援多機併發、掛起恢復等虛擬機器高階特性。
其vCUDA的實現原理大概包括三個模組:CUDA客戶端、CUDA服務端和CUDA管理端。以XenServer為例,在物理硬體資源上執行著一個VMM用於向上提供硬體映像,在VMM上執行著若干個虛擬機器。其中一個虛擬機器為特權虛擬機器(Host VM),即為XenServer中的Domain 0,在虛擬機器中執行的作業系統稱為Host OS。
Host OS能夠直接控制硬體,系統內安裝著原生的CUDA庫以及GPU驅動,使得Host OS可以直接訪問GPU和使用CUDA。其它的虛擬機器屬於非特權虛擬機器(Guest VM),其上執行的作業系統(Guest OS)不能直接操縱GPU。在這裡我們將CUDA客戶端稱之為客戶端驅動,CUDA服務端稱之為宿主機的驅動,CUDA管理端稱之為GPU管理器。
2.3.1、客戶端
客戶端驅動其實質就是我們安裝在虛擬機器比如Windows 7上的顯示卡驅動程式。主要的功能是在使用者層提供針對CUDA API的庫以及一個維護CUDA相關軟硬體狀態的虛擬GPU(vGPU)。客戶端驅動直接面向CUDA應用程式,其作用包括:
-
1)攔截應用程式中CUDA API呼叫;
-
2)選擇通訊策略,為虛擬化提供更高層語意的支援;
-
3)對呼叫的介面和引數進行封裝、編碼;
-
4)對服務端傳回的資料進行解碼,並傳回給應用。
此外,客戶端驅動在第一個API呼叫到來之前,首先到管理端索取GPU資源。每一個獨立的呼叫過程都必須到宿主管理端驅動申請資源,以實現對GPU資源和任務的實時排程。
此外,客戶端驅動同時設定了vGPU用來維護與顯示卡相關的軟硬體狀態。vGPU本身實質上僅僅是一個鍵值對的資料結構,在其中儲存了當前使用的地址空間、視訊記憶體物件、記憶體物件等,同時記錄了API的呼叫次序。當計算結果傳回時,客戶端驅動會根據結果更新vGPU。
2.3.2、伺服器端
服務端元件位於特權虛擬機器(XenServer術語:特權域)中的應用層。特權虛擬機器可以直接與硬體互動,因此服務端元件可以直接操縱物理GPU來完成通用計算任務。
服務端面向真實GPU,其作用包括:
-
1)接收客戶端的資料報,並解析出呼叫和引數;
-
2)對呼叫和引數進行審核;
-
3)利用CUDA和物理GPU計算審核透過的呼叫;
-
4)將結果編碼,並傳回給客戶端;
-
5)對計算系統中支援CUDA的GPU進行管理。
此外,服務端執行的第一個任務是將自身支援CUDA的GPU裝置的資訊註冊到管理端中。服務端應對客戶端的請求時,為每個應用分配獨立的服務執行緒。服務端統一管理本地GPU資源,按照一定的策略提供GPU資源,並將由於API呼叫修改的相關軟硬體狀態更新至vGPU。
2.3.3、管理端
管理端元件位於特權域,在實現CUDA程式設計介面虛擬化的基礎上,將GPU強大的計算能力和計算資源在更高的邏輯層次上進行隔離、劃分、排程。在CUDA服務端使用計算執行緒和工作執行緒在一定程度上使同在一個物理機上的GPU間負載均衡,設定CUDA管理端元件在更高的邏輯層次上進行負載均衡,使在同一個GPU虛擬叢集中的GPU負載均衡。
管理端元件排程的原則是儘量使在同一個物理機上的GPU需求自給,如果該物理機上具備滿足條件的GPU資源,在一般情況下,該物理機上的虛擬機器的GPU需求都重定向到該物理機的CUDA服務端。
管理端對GPU資源進行統一管理,採用集中、靈活的機制,實現:
-
1)動態排程:當使用者所佔資源空閑時間超過一定閾值或者任務結束時,管理端回收該資源,當該使用者再次釋出計算任務時,重新為其任務分配GPU資源;
-
2)負載平衡:當區域性計算壓力過大時,調整計算負載,透過動態排程時選擇合適的GPU資源來分散計算負載;
-
3)故障恢復:當出現故障時,將任務轉移到新的可用GPU資源上。
更多技術內容已經整理成電子書,雙十一期間優惠活動相詳細資訊如下:
(如滿足優惠條件,下單可聯絡助理修改價格)

溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多電子書詳解。

求知若渴, 虛心若愚

