來自:開源中國,作者:樊騰飛
連結:
https://my.oschina.net/editorial-story/blog/2396106
HashMap 是 Java 中 Map 的一個實現類,它是一個雙列結構(資料+連結串列),這樣的結構使得它的查詢和插入效率都很高。HashMap 允許 null 鍵和值,它的鍵唯一,元素的儲存無序,並且它是執行緒不安全的。

由於 HashMap 的這些特性,它在 Java 中被廣泛地使用,下麵我們就基於 Java 8 分析一下 HashMap 的原始碼。
雙列結構:陣列+連結串列
首先 HashMap 是一個雙列結構,它是一個散串列,儲存方式是鍵值對。 它繼承了 AbstractMap,實現了 Map Cloneable Serializable 介面。
HashMap 的雙列結構是陣列 Node[]+連結串列,我們知道陣列的查詢很快,但是修改很慢,因為陣列定長,所以新增或者減少元素都會導致陣列擴容。而連結串列結構恰恰相反,它的查詢慢,因為沒有索引,需要遍歷連結串列查詢。但是它的修改很快,不需要擴容,只需要在首或者尾部新增即可。HashMap 正是應用了這兩種資料結構,以此來保證它的查詢和修改都有很高的效率。
HashMap 在呼叫 put() 方法儲存元素的時候,會根據 key 的 hash 值來計算它的索引,這個索引有什麼用呢?HashMap 使用這個索引來將這個鍵值對儲存到對應的陣列位置,比如如果計算出來的索引是 n,則它將儲存在 Node[n] 這個位置。
HashMap 在計算索引的時候儘量保證它的離散,但還是會有不同的 key 計算出來的索引是一樣的,那麼第二次 put 的時候,key 就會產生衝突。HashMap 用連結串列的結構解決這個問題,當 HashMap 發現當前的索引下已經有不為 null 的 Node 存在時,會在這個 Node 後面新增新元素,同一索引下的元素就組成了連結串列結構,Node 和 Node 之間如何聯絡可以看下麵 Node 類的原始碼分析。
先瞭解一下 HashMap 裡陣列的幾個引數:
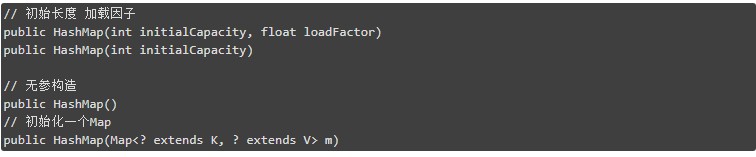
DEFAULT_INITIAL_CAPACITY,預設初始長度,16:

MAXIMUM_CAPACITY,最大長度,2^30:

DEFAULT_LOAD_FACTOR,預設載入因子,0.75:

threshold,閾值,擴容的臨界值(capacity * load factor)

再看看 HashMap 建構式
下邊是非常重要的一個內部類 Node ,它實現了 Map.Entry,Node 是 HashMap 中的基本元素,每個鍵值對都儲存在一個 Node 物件裡, Node 類有四個成員變數:hash key 的雜湊值、鍵值對 key 與 value,以及 next 指標。next 也是 Node 型別,這個 Node 指向的是連結串列下一個鍵值對,這也就是前文提到的 hash 衝突時 HashMap 的處理辦法。
Node 類內部實現了 Map.Entry 介面中的 getKey()、getValue() 等方法,所以在遍歷 Map 的時候我們可以用 Map.entrySet() 。

HashMap put() 流程
put() 方法
put() 主要是將 key 和 value 儲存到 Node 陣列中,HashMap 根據 key 的 hash 值來確定它的索引,原始碼裡 put 方法將呼叫內部的 putVal() 方法。

HashMap 在 put 鍵值對的時候會呼叫 hash() 方法計算 key 的 hash 值,hash() 方法會呼叫 Object 的 native 方法 hashCode() 並且將計算之後的 hash 值高低位做異或運算,以增加 hash 的複雜度。(Java 裡一個 int 型別佔 4 個位元組,一個位元組是 8 bit,所以下麵原始碼中的 h 與 h 右移 16 位就相當於高低位異或)

putVal() 方法
這部分是主要 put 的邏輯
- 計算容量:根據 map 的 size 計算陣列容量大小,如果元素數量也就是 size 大於陣列容量 ×0.75,則對陣列進行擴容,擴容到原來的 2 倍。
- 查詢資料索引:根據 key 的 hash 值和陣列長度找到 Node 陣列索引。
- 儲存:這裡有以下幾種情況(假設計算出的 hash 為 i,陣列為 tab,變數以程式碼為例)
- 當前索引為 null,直接 new 一個 Node 並存到陣列裡,tab[i]=newNode(hash, key, value, null)
- 陣列不為空,這時兩個元素的 hash 是一樣的,再呼叫 equals 方法判斷 key 是否一致,相同,則改寫當前的 value,否則繼續向下判斷
- 上面兩個條件都不滿足,說明 hash 發生衝突,Java 8 裡實現了紅黑樹,紅黑樹在進行插入和刪除操作時透過特定演演算法保持二叉查詢樹的平衡,從而可以獲得較高的查詢效能。本篇也是基於 Java 8 的原始碼進行分析,在這裡 HashMap 會判斷當前陣列上的元素 tab[i] 是否是紅黑樹,如果是,呼叫紅黑樹的 putTreeVal 的 put 方法,它會將新元素以紅黑樹的資料結構儲存到陣列中。
如果以上條件都不成立,表明 tab[i] 上有其它 key 元素存在,並且沒有轉成紅黑樹結構,這時只需呼叫 tab[i].next 來遍歷此連結串列,找到連結串列的尾然後將元素存到當前連結串列的尾部。


HashMap 的 get()
get() 方法會呼叫 getNode() 方法,這是 get() 的核心,getNode() 方法的兩個引數分別是 hash 值和 key。

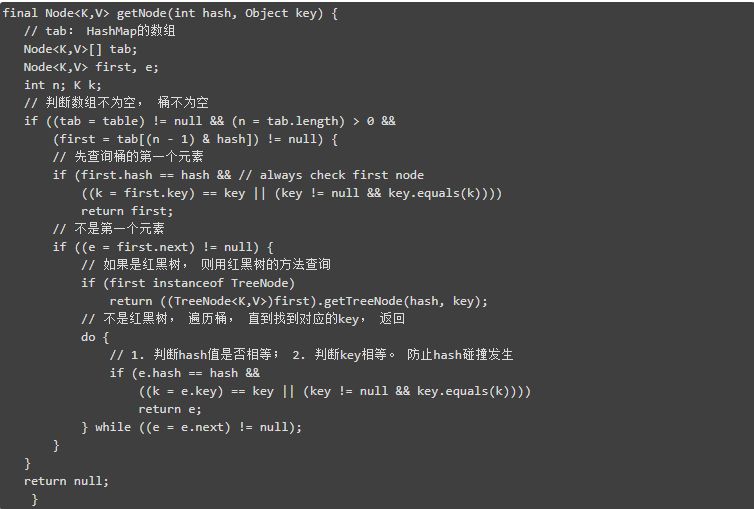
這裡重點來看 getNode() 方法,前面講到過,HashMap 是透過 key 生成的 hash 值來儲存到陣列的對應索引上,HashMap 在 get 的時候也是用這種方式來查詢元素的。
- 根據 hash 值和陣列長度找到 key 對應的陣列索引。
- 拿到當前的陣列元素,也就是這個連結串列的第一個元素 first,先用 hash 和 equals() 判斷是不是第一個元素,是的話直接傳回,不是的話繼續下麵的邏輯。
- 不是連結串列的第一個元素,判斷這個元素 first 是不是紅黑樹,如果是呼叫紅黑樹的 getTreeNode 方法來查詢。
- 如果不是紅黑樹結構,從 first 元素開始遍歷當前連結串列,直到找到要查詢的元素,如果沒有則傳回 null。
陣列擴容時再雜湊(re-hash)的理解
前面提到,當 HashMap 在 put 元素的時候,HashMap 會呼叫 resize() 方法來重新計算陣列容量,陣列擴容之後,陣列長度發生變化。我們知道 HashMap 是根據 key 的 hash 和陣列長度計算元素位置的,那當陣列長度發生變化時,如果不重新計算元素的位置,當我們 get 元素的時候就找不到正確的元素了,所以 HashMap 在擴容的同時也重新對陣列元素進行了計算。
這時還有一個問題,re-hash 的時候同一個桶(bucket)上的連結串列會重新排列還是連結串列仍然在同一桶上。先考慮一下當它擴容的時候同一個桶上的元素再與新陣列長度做與運算 & 時,可能計算出來的陣列索引不同。假如陣列長度是 16,擴容後的陣列長度將是 32。
下邊用二進位制說明這個問題:

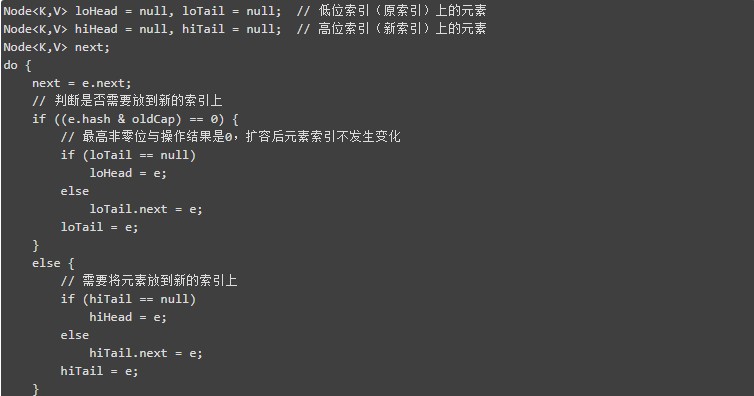
最終的結果是 0000 1111,和用 oldLen 計算的結果一樣,其實看上式可以發現真正能改變索引值的是 hash 第 5 位(從右向左)上的值,也就是 length 的最高非零位,所以,同一個連結串列上的元素在擴容後,它們的索引只有兩種可能,一種就是保持原位(最高非零位是 0),另一種就是 length+ 原索引 i (第五位是 1,結果就相等於 25+原索引 i,也就是 length+i)。

下邊所示的 HashMap 原始碼中就是用這個思路來 re-hash 一個桶上的連結串列,e.hash & oldCap == 0 判斷 hash 對應 length 的最高非 0 位是否是 1,是 1 則把元素存在原索引,否則將元素存在 length+原索引的位置。HashMap 定義了四個 Node 物件,lo 開頭的是低位的連結串列(原索引),hi 開頭的是高位的連結串列(length+原索引,所以相當於是新 length 的高位)。

HashMap 與 HashTable
另外對比一下 HashMap 與 HashTable:
- HashMap 是執行緒不安全的,HashTable 執行緒安全,因為它在 get、put 方法上加了 synchronized 關鍵字。
- HashMap 和 HashTable 的 hash 值是不一樣的,所在的桶的計算方式也不一樣。HashMap 的桶是透過 & 運運算元來實現 (tab.length – 1) & hash,而 HashTable 是透過取餘計算,速度更慢(hash & 0x7FFFFFFF) % tab.length (當 tab.length = 2^n 時,因為 HashMap 的陣列長度正好都是 2^n,所以兩者是等價的)
- HashTable 的 synchronized 是方法級別的,也就是它是在 put() 方法上加的,這也就是說任何一個 put 操作都會使用同一個鎖,而實際上不同索引上的元素之間彼此操作不會受到影響;ConcurrentHashMap 相當於是 HashTable 的升級,它也是執行緒安全的,而且只有在同一個桶上加鎖,也就是說只有在多個執行緒操作同一個陣列索引的時候才加鎖,極大提高了效率。
總結
- HashMap 底層是陣列+連結串列結構,陣列長度預設是 16,當元素的個數大於陣列長度×0.75 時,陣列會擴容。
- HashMap 是散串列,它根據 key 的 hash 值來找到對應的陣列索引來儲存, 發生 hash 碰撞的時候(計算出來的 hash 值相等) HashMap 將採用拉鏈式來儲存元素,也就是我們所說的單向連結串列結構。
- 在 Java7 中,如果 hash 碰撞,導致拉鏈過長,查詢的效能會下降, 所以在 Java8 中新增紅黑樹結構,當一個桶的長度超過 8 時,將其轉為紅黑樹連結串列,如果小於 6,又重新轉換為普通連結串列。
- re-hash 再雜湊問題:HashMap 擴容的時候會重新計算每一個元素的索引,重新計算之後的索引只有兩種可能,要麼等於原索引要麼等於原索引加上原陣列長度。
- 由上一條可知,每次擴容,整個 hash table 都需要重新計算索引,非常耗時,所以在日常使用中一定要註意這個問題。
參考檔案
- Why is the bucket size 16 by default in HashMap?
- 集合原始碼解析之 HashMap(基於 Java8)
- Java HashMap 工作原理
- HashMap 原始碼詳細分析(JDK1.8)
作者介紹
樊騰飛,有開源精神,樂於分享,希望透過寫部落格認識更多志同道合的人。個人部落格:rollsbean.com
●編號823,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。