作者:Pulkit Sharma;翻譯:申利彬;校對:付宇帥
本文約10300字,建議閱讀10分鐘。
本文介紹了各種推薦引擎演演算法以及使用Python構建它們的基本框架。
簡介
當今社會的每個人都面臨著各種各樣的選擇。例如,如果我漫無目的想找一本書讀,那麼關於我如何搜尋就會出現很多可能。這樣一來,我可能會浪費很多時間在網上瀏覽,並且在各種各樣的網站上搜尋,希望能找到有價值的書籍。這個時候我可能尋找別人的推薦。
如果有一家網站或者手機應用可以基於我以前閱讀的書籍向我推薦新的書籍,那對我肯定有很大的幫助。這時我會有如下愉快的體驗,登入網站,就可以看到符合我興趣的10本書籍,不用浪費時間在網站上搜尋。

這就是推薦引擎所做的事情,它們的力量現在正被大多數企業所使用。從亞馬遜到Netflix,谷歌到谷歌閱讀,推薦引擎是機器學習技術中最廣泛的應用之一。
在本文中,將介紹各種推薦引擎演演算法以及使用Python構建它們的基本框架。我們還將討論這些演演算法工作背後的數學原理,最後使用矩陣分解技術建立屬於我們自己的推薦引擎。
目錄
1 什麼是推薦引擎?
2 推薦引擎是如何工作的?
2.1 資料收集
2.2 資料儲存
2.3 資料過濾
2.31 基於內容過濾資料
2.32 協同過濾
3 基於MovieLens資料集的python實體學習
4 從0搭建協同過濾模型
5 使用Turicreate搭建簡單流行的協同過濾模型
6 矩陣分解簡介
7 使用矩陣分解構建一個推薦引擎
8 推薦引擎的評價指標
8.1 召回率
8.2 精確度
8.3 均方誤差(RMSE)
8.4 MRR(Mean Reciprocal Rank)
8.5 MAP at k(Mean Average Precision at cutoff k K位置截止的平均精度均值)
8.6 NDCG(Normalized Discounted Cumulative Gain歸一化累積折損增益)
9 還可以嘗試什麼?
尾註
1 什麼是推薦引擎?
一直到現在,人們也會傾向於買朋友或者信任的人推薦商品。當對某個商品有任何疑問時,人們往往會採用這種方式。但是隨著數字時代的到來,這個圈子已經擴充套件到包括使用某種推薦引擎的線上網站。
一個推薦引擎使用不同的演演算法過濾資料,並向用戶推薦最相關的物品。它首先儲存客戶過去的行為資料,然後基於這些資料向客戶推薦他們可能購買的物品。
如果一個全新的使用者訪問一個電子商務網站,網站沒有該使用者的任何歷史資料。那麼在這樣的場景中,網站是如何向用戶推薦產品呢?一種可能的方法是向客戶推薦賣的最好的商品,也就是該商品需求量很大。還有另外一種可能的方法是向用戶推薦可以給網站帶來最大利潤的商品。
如果我們可以根據使用者的需要和興趣向用戶推薦一些商品,這可以對使用者體驗產生積極的影響,最後可以達到多次訪問的效果。因此,現在的企業透過研究使用者過去的行為資料來構建聰明和智慧的推薦引擎。
目前我們對推薦引擎有了直觀的認識,現在讓我們來看看它們是如何工作的。
2 推薦引擎是如何工作的?
在深入探討這個主題之前,我們首先考慮一下如何向用戶推薦商品:
-
我們可以向一個使用者推薦最受歡迎的商品
-
可以根據使用者偏好(使用者特徵)把使用者分為多個細分類別,然後基於他們屬於的類別推薦商品。
上述兩種方法都有缺點。在第一種方法中,對於每一個使用者來說最受歡迎的商品都是相同的,所以使用者看到的推薦也是相同的。在第二種方法中,隨著使用者數量的增加,使用者特徵也隨著增加。因此將使用者劃分為多個類別將會是一件非常困難的任務。
這裡的主要問題是我們無法為使用者具體的興趣定製推薦。這就像亞馬遜建議你買一臺膝上型電腦,僅僅是因為它被大多數購物者購買。但幸運的是,亞馬遜(或其他大公司)並沒有使用上述方法來推薦商品。他們使用一些個性化的方法來幫助他們更準確地推薦產品。
我們現在來看看推薦引擎是如何透過以下步驟來工作的。
2.1 資料收集
收集資料是構建推薦引擎的第一步也是最關鍵的一步。可以透過兩種方式收集資料:顯式和隱式。顯示資料是使用者有意提供的資訊,比如電影排名,相反隱氏資料則不是使用者主動提供,而是從資料流中收集得到的資訊,例如搜尋歷史、點選率、歷史訂單等。

在上面的圖片中,Netflix正在以使用者對不同電影的評分形式明確地收集資料。

上圖可以看到Amazon記錄的使用者歷史訂單,這是一個隱式資料收集樣式的例子。
2.2 資料儲存
資料量決定了模型的建議有多好,例如,在電影推薦系統中,使用者對電影的評價越多,推薦給其他使用者的效果就越好。資料型別對採用何種儲存型別有很重要的影響,這種型別的儲存可以包括一個標準的SQL資料庫、NoSQL資料庫或某種型別的物件儲存。
2.3 資料過濾
在收集和儲存資料之後,我們必須對其進行過濾,以便提取出最終推薦所需的相關資訊。

有各種各樣的演演算法可以幫助我們簡化過濾過程。在下一節中,我們將詳細介紹每種演演算法。
2.3.1 基於內容的過濾
這個演演算法推薦的產品類似於使用者過去喜歡的產品。

圖片來源:Medium
例如,如果一位使用者喜歡《盜夢空間》這部電影,那麼演演算法就會推薦屬於同一型別的電影。但是,演演算法是如何理解選擇和推薦電影的型別呢?
以Netflix為例:它們以向量形式儲存與每個使用者相關的所有資訊。這個向量包含使用者過去的行為,也就是使用者喜歡/不喜歡的電影和他們給出的評分,這個向量也被稱為輪廓向量(profile vector)。所有與電影相關的資訊都儲存在另一個叫做專案向量(item vector)中。專案向量包含每個電影的細節,如型別、演員、導演等。
基於內容的過濾演演算法找到了輪廓向量與專案向量夾角的餘弦,也就是餘弦相似度。假設A是輪廓向量,B是專案向量,那麼它們之間的相似性可以按如下公式計算:
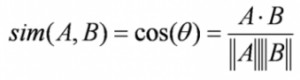
根據在-1到1之間的餘弦值,可以將電影按降序排列,並且採用下麵兩種方法中的一種用於推薦:
-
選擇前N部電影:推薦最相關的前N部電影(這裡N可以由公司決定)。
-
等級量表的方法:設定一個閾值,並推薦所有超過該閾值的電影。
其它可以用來計算相似性的方法有:
-
歐幾裡得距離:如果在N維空間中繪製,相似的物體將會彼此靠近。因此,我們可以計算物體之間的距離根據這個距離,向用戶推薦內容。下麵是歐幾裡得距離公式:

-
皮爾遜相關性:它告訴我們兩個物體的相關程度,越高的相關性,就越相似。皮爾遜的相關性可以用以下公式來計算:

這種演演算法有一個主要的缺點,也就是它僅限於推薦相同型別的物體。它永遠不會推薦使用者過去沒有購買或喜歡的產品。因此,如果使用者過去僅僅看或喜歡動作電影,系統也就只會推薦動作電影。很顯然,這種搭建推薦引擎的方法泛化效能很差。
我們要找到一種演演算法可以改進這種型別的推薦系統,它不僅可以根據內容進行推薦,還要可以利用使用者的行為資訊。
2.3.2 協同過濾
我們透過一個例子來理解這個方法。如果使用者A喜歡3部電影,比如《星際穿越》,《盜夢空間》和《前目的地》,而使用者B喜歡《盜夢空間》、《前目的地》和《致命魔術》,那麼他們就有差不多的興趣愛好。我們可以肯定地說,A應該喜歡《致命魔術》,B應該喜歡《星際穿越》。協同過濾演演算法使用“使用者行為”來推薦電影。這是工業中最常用的演演算法之一,因為它不依賴於任何額外的資訊。協同過濾技術有很多種不同的型別,我們將在下麵詳細討論這些問題。
使用者與使用者間的協同過濾
該演演算法首先發現使用者之間的相似性分數,基於這個相似性的分數,它會挑選出最相似的使用者,並推薦這些類似的使用者以前喜歡或購買的產品。

圖片來源:Medium
就我們之前的電影例子而言,這個演演算法根據他們之前給不同電影的評分來發現每個使用者之間的相似性。使用者u的一個物體的預測是透過計算其它使用者對一個物體i的使用者評分的加權總和來計算的。Pu,i透過下式計算得到:

公式符號含義如下:
-
Pu,I 是一個物體的預測
-
Rv,I 是使用者v對電影i的評分
-
Su,v 使使用者之間的相似性分數
現在,我們在輪廓向量中對使用者進行了評分,並且基於這個向量,我們要預測其他使用者的評分。接下來的步驟如下:
-
對於預測,我們需要使用者u和v之間的相似性。這時可以利用皮爾遜相關性。
-
首先,我們發現被使用者打分的商品,根據評分,計算使用者之間的相關性。
-
可以用相似值來計算預測。這個演演算法首先計算每個使用者之間的相似性,然後根據每個相似度計算預測值。具有高相關性的使用者,一般都相似。
-
基於這些預測值給出推薦。我們透過一個例子來理解它:
使用者-電影評分矩陣:

我們可以看到一個使用者-電影評分矩陣,為了更深入地理解這個公式,讓我們在上表中找到使用者(A, C)和(B, C)之間的相似性。A與C共同評分的電影是x2和x4,B與C共同評分的電影是x2,x4和x5。

使用者A和C之間的相關性大於B和C之間的相關性。因此使用者A和C有更多的相似性,使用者A喜歡的電影會推薦給使用者C,反之亦然。
這個演演算法非常耗時,因為它涉及到計算每個使用者的相似度,然後計算每個相似度得分的預測。解決這個問題的一種方法是隻選擇幾個使用者(鄰居)而不是對所有的值進行預測,也就是說,我們只選擇幾個相似值而不是對所有相似值進行預測:
-
選擇一個相似度閾值並選擇該值以上的所有使用者
-
隨機選擇使用者
-
按照相似度值的降序排列相鄰使用者,然後選擇前n個使用者
-
使用聚類演演算法選擇相鄰使用者
當使用者數量較少時,這個演演算法可以很好的發揮作用。當有大量的使用者時,它並不有效,因為計算所有使用者對之間的相似性需要花費大量的時間。這就產生了商品-商品的協同過濾,當使用者數量遠遠超過推薦商品的數量時,這種演演算法是非常有效的。
商品-商品協同過濾
在這個演演算法中,我們計算每一對商品之間的相似度。

圖片來源:Medium
所以在我們的案例中,我們會發現每個電影對之間的相似性,在此基礎上,我們可以推薦使用者過去喜歡的相似的電影。這個演演算法的工作原理類似於使用者-使用者協同過濾,僅僅做了一點小小的改變——不是對“相鄰使用者”的評分進行加權求和,而是對“相鄰商品”的評分進行加權求和。預測公式如下:

我們計算商品之間的相似性:

現在我們我們有每一對電影的相似性,評分和預測都已經有了,而且基於這些預測,我們可以進行相似電影的推薦。我們透過一個例子來理解:

這裡的電影評分均值是所有個某一特定電影評分的平均值(將它與我們在使用者-使用者過濾中看到的表進行比較)。並且我們不是像前面看到的那樣找到使用者-使用者相似度,而是找到商品-商品相似度。
要做到這一點,首先我們需要找到對這些商品進行評分的使用者,並根據評分計算商品之間的相似性。我們來找出電影(x1, x4)和(x1, x5)之間的相似性。從上表可以看出,給電影x1, x4都有打分的使用者是A與B,給電影x1, x5都有打分的使用者也是A與B。
電影x1和x4的相似度大於電影x1和x5的相似度,基於這些相似度值,如果有任何使用者搜尋電影 x1,那麼將會為他們推薦電影x4,反之也一樣。在進一步運用這些概念之前,有一個問題我們必須要知道答案——如果在資料集中添加了新使用者或新電影,將會發生什麼?這被稱為冷啟動,它有兩種型別:
-
使用者冷啟動
-
產品冷啟動
使用者冷啟動意味著資料庫中新增加了一位新使用者,由於沒有該使用者的歷史記錄,系統也就不知道該使用者的偏好,所以向這位使用者推薦商品就會很困難。所以我們將如何解決這個問題呢?一種基本的方法是採用基於流行度的策略,即推薦最受歡迎的產品。這些可以由最近的流行趨勢來決定,以後一旦我們知道了使用者的喜好,推薦商品就會變的很容易。
另一方面,產品冷啟動意味著新產品投放市場或新增到系統中。使用者的行為對決定任何產品價值來說都是很重要的。產品接受的互動越多,我們的模型就越容易向正確的使用者推薦該產品。我們可以利用基於內容的過濾來解決這個問題。系統首先使用新產品的內容進行推薦,不過最終使用使用者對該產品的互動進行推薦。
現在讓我們使用Python中的一個案例學習來鞏固我們對這些概念的理解。這個例子非常有趣,快開啟你的電腦準備開始吧。
3 基於MovieLens資料集的python實體學習
我們將使用這個MovieLens資料集建立一個模型並向終端使用者推薦電影。明尼蘇達大學(University of Minnesota)的GroupLens研究專案已經收集了這些資料。資料集可以從這裡下載:
https://grouplens.org/datasets/movielens/100k/
這個資料集包含有:
-
1682部電影中有943位觀眾觀看了10萬次(1-5次)
-
使用者的人口統計資訊(年齡、性別、職業等)
首先,我們將匯入標準庫並將資料讀入python中:
import pandas as pd
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
# pass in column names for each CSV as the column name is not given in the file and read them using pandas.
# You can check the column names from the readme file
#Reading users file:
u_cols = [‘user_id’, ‘age’, ‘sex’, ‘occupation’, ‘zip_code’]
users = pd.read_csv(‘ml-100k/u.user’, sep=’|’, names=u_cols,encoding=’latin-1′)
#Reading ratings file:
r_cols = [‘user_id’, ‘movie_id’, ‘rating’, ‘unix_timestamp’]
ratings = pd.read_csv(‘ml-100k/u.data’, sep=’\t’, names=r_cols,encoding=’latin-1′)
#Reading items file:
i_cols = [‘movie id’, ‘movie title’ ,’release date’,’video release date’, ‘IMDb URL’, ‘unknown’, ‘Action’, ‘Adventure’,
‘Animation’, ‘Children\’s’, ‘Comedy’, ‘Crime’, ‘Documentary’, ‘Drama’, ‘Fantasy’,
‘Film-Noir’, ‘Horror’, ‘Musical’, ‘Mystery’, ‘Romance’, ‘Sci-Fi’, ‘Thriller’, ‘War’, ‘Western’]
items = pd.read_csv(‘ml-100k/u.item’, sep=’|’, names=i_cols,
encoding=’latin-1′)
載入資料集之後,我們應該檢視每個檔案的內容(使用者、評分、電影):
-
使用者
print(users.shape)
users.head()

因此,我們可以看到資料集中有943個使用者,每個使用者有5個特性,即使用者ID、年齡、性別、職業和郵政編碼。現在我們來看看評分檔案。
-
評分
print(ratings.shape)
ratings.head()

對於不同的使用者和電影組合,我們有100k個電影評分。現在最後檢查電影檔案。
-
電影
print(items.shape)
items.head()

這個資料集包含了1682部電影的屬性,一共有24列,其中最後19列指定了具體電影的型別。這些是二進位制列,即,值1表示該電影屬於該型別,否則為0。
GroupLens已經將資料集劃分為train和test,每個使用者的測試資料有10個等級,總共9430行。我們接下來把這些檔案讀入到python環境中。
r_cols = [‘user_id’, ‘movie_id’, ‘rating’, ‘unix_timestamp’]
ratings_train = pd.read_csv(‘ml-100k/ua.base’, sep=’\t’, names=r_cols, encoding=’latin-1′)
ratings_test = pd.read_csv(‘ml-100k/ua.test’, sep=’\t’, names=r_cols, encoding=’latin-1′)
ratings_train.shape, ratings_test.shape
現在終於到了構建我們推薦引擎的時候了!
4 從0搭建協同過濾模型
我們將根據使用者-使用者相似度和電影-電影相似度推薦電影。為此,我們首先需要計算獨立使用者和電影的數量。
n_users = ratings.user_id.unique().shape[0]
n_items = ratings.movie_id.unique().shape[0]
現在,我們將建立一個使用者電影矩陣,該矩陣可用於計算使用者與電影之間的相似性。
data_matrix = np.zeros((n_users, n_items))
for line in ratings.itertuples():
data_matrix[line[1]-1, line[2]-1] = line[3]
現在,我們來計算相似度。我們可以使用sklearn的pairwise_distance函式來計算餘弦相似度。
from sklearn.metrics.pairwise import pairwise_distances
user_similarity = pairwise_distances(data_matrix, metric=’cosine’)
item_similarity = pairwise_distances(data_matrix.T, metric=’cosine’)
這就給出了陣列表單中的item-item和user-user相似度。下一步是根據這些相似數值做出預測,下麵我們定義一個函式來做這個預測。
def predict(ratings, similarity, type=’user’):
if type == ‘user’:
mean_user_rating = ratings.mean(axis=1)
#We use np.newaxis so that mean_user_rating has same format as ratings
ratings_diff = (ratings – mean_user_rating[:, np.newaxis])
pred = mean_user_rating[:, np.newaxis] + similarity.dot(ratings_diff) / np.array([np.abs(similarity).sum(axis=1)]).T
elif type == ‘item’:
pred = ratings.dot(similarity) / np.array([np.abs(similarity).sum(axis=1)])
return pred
最後,我們將基於使用者相似度和電影相似度進行預測。
user_prediction = predict(data_matrix, user_similarity, type=’user’)
item_prediction = predict(data_matrix, item_similarity, type=’item’)
事實證明,我們還有一個庫,可以自動生成所有這些推薦。現在讓我們學習如何在Python中使用turicreate建立推薦引擎。要熟悉turicreate並將它安裝到你的電腦上,請參考這裡:
https://github.com/apple/turicreate/blob/master/README.md
5 使用Turicreate搭建簡單流行的協同過濾模型
在安裝好turicreate庫之後,首先匯入它,然後在我們的環境中讀取訓練和測試資料集。
import turicreate
train_data = turicreate.SFrame(ratings_train)
test_data = turicreate.Sframe(ratings_test)
我們有使用者行為,也有使用者和電影的屬性,所以我們可以製作基於內容和協同過濾演演算法。我們將從一個簡單的流行模型開始,然後構建一個協同過濾模型。
首先,我們建立一個向用戶推薦最流行電影的模型,也就是所有使用者都會收到相同的推薦。我們可以使用Turicreate中的popularity_recommender推薦函式來實現。
popularity_model = turicreate.popularity_recommender.create(train_data, user_id=’user_id’, item_id=’movie_id’, target=’rating’)
我們使用的各種變數有:
-
train_data:SFrame包含了我們所需要的訓練資料
-
user_id:這一列包含了每個使用者的ID
-
item_id: 這一列包含了每一個要被推薦的電影(電影ID)
-
target:這一列包含了使用者給的評分或等級
預測的時間到了!我們將為我們資料集中的前5個使用者推薦排名前5的電影。
popularity_recomm = popularity_model.recommend(users=[1,2,3,4,5],k=5)
popularity_recomm.print_rows(num_rows=25)

註意,所有使用者的推薦都是一樣的——1467、1201、1189、1122、814。它們的順序是一樣的!這證實了所有推薦電影的平均評分都是5分,即所有觀看電影的使用者都給予了最高的評分。因此我們基於流行的系統表現是符合我們預期的。
在構建了流行模型之後,我們現在將構建一個協同過濾模型。我們來訓練電影相似度模型,併為前5名使用者提供前5項推薦。
#Training the model
item_sim_model = turicreate.item_similarity_recommender.create(train_data, user_id=’user_id’, item_id=’movie_id’, target=’rating’, similarity_type=’cosine’)
#Making recommendations
item_sim_recomm = item_sim_model.recommend(users=[1,2,3,4,5],k=5)
item_sim_recomm.print_rows(num_rows=25)

在這裡我們可以看到每個使用者的推薦(movie id)是不同的。對於不同的使用者,我們有不同的推薦集,也就是說個性化是存在的。
在這個模型中,我們沒有每個使用者給出的每個電影的評分。我們必須找到一種方法來預測所有這些缺失的評分。為此,我們必須找到一組可以定義使用者如何評價電影的特徵。這些被稱為潛在特徵(latent features)。我們需要找到一種方法,從現有的特徵中提取出最重要的潛在特徵。下一節將介紹矩陣分解技術,它使用低維密集矩陣,幫助我們提取重要的潛在特徵。
6 矩陣分解簡介
我們透過一個例子來理解矩陣分解。考慮不同使用者對不同電影給出的使用者電影評分矩陣(1-5)。

這裡的使用者id是不同使用者的唯一id,每個電影也被分配一個唯一id。0.0表示使用者沒有對特定的電影進行評分(1是使用者能給出的最低評分)。我們希望預測這些缺失的評分,使用矩陣分解可以找到一些潛在的特徵,它們可以決定使用者如何評價一部電影。我們將原矩陣分解成不同的組成部分,使這些部分的乘積等於原始矩陣。

假設我們要找到k個潛在特徵。因此,我們可以將我們的評分矩陣R(MxN)劃分為P(MxK)和Q(NxK),使P x QT(這裡QT是Q矩陣的轉置)近似於R矩陣:
 :
:
-
M是使用者總數
-
N是電影的總數
-
K是總的潛在特徵
-
R是MxN使用者電影評分矩陣
-
P是MxK使用者特徵關聯矩陣,表示使用者與特徵之間的關聯
-
Q是NxK電影特徵關聯矩陣,表示電影與特徵之間的關聯
-
Σ是K*K個對角特徵權重矩陣,代表了特徵的重要權重
透過矩陣分解的方法來選擇潛在特徵並消除了資料中的噪聲。如何做到的呢?它是刪除了不能決定使用者如何評價電影的特徵。現在要得到使用者puk對一部電影qik的所有潛在特徵k的評分rui,我們可以計算這兩個向量的點積,並將它們相加,得到基於所有潛在特徵的評分。

這就是矩陣分解給我們預測電影的評分,而這些電影並沒有得到使用者的評分。但是,我們如何將新資料新增到我們的使用者電影評分矩陣中,也就是說,如果一個新使用者加入並對電影進行評分,我們將如何將這些資料新增到已有的矩陣中?
我透過矩陣分解的方法讓你更容易理解這個過程。如果有一個新使用者進入系統,對角權重矩陣和商品-特徵相關性矩陣是不會發生變化的,唯一的變化是發生在使用者特徵關聯矩陣P中。我們可以用一些矩陣乘法來實現這個。
我們有:
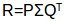
兩邊同時乘以矩陣Q:

現在我們有:

所以:

進一步化簡,得到P矩陣:
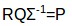
這是更新後的使用者特徵關聯矩陣。同樣地,如果向系統中添加了新電影,我們可以按照類似的步驟得到更新後的電影特徵關聯矩陣Q。
我們要有意識,雖然把R矩陣分解成P和Q,但是我們如何決定哪個P和Q矩陣更加近似於R矩陣呢?我們可以用梯度下降演演算法來做這個,標的是最小化實際評分與使用P和Q進行評估的評分之間的平方誤差。平方誤差公式如下所示:

-
eui 表示誤差
-
rui 表示使用者u對電影i的實際評分
-
řui 表示預測使用者u對電影i的評分
我們的標的是確定p和q值,使誤差最小化,因此需要更新p值和q值,以得到這些矩陣的最佳化值,這樣誤差最小。現在我們將為puk和qki定義一個更新規則,在梯度下降中的更新規則是由要最小化的誤差梯度定義的。

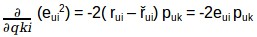
因為我們現在有了梯度,我們可以為puk和qki應用更新規則:


α是學習率,它決定每次更新的大小。重覆上述更新過程,直到誤差最小化為止,最後我們可以得到最優的P和Q矩陣,可以用來預測評分。我們快速回顧一下這個演演算法是如何工作的,然後我們來構建推薦引擎預測未評分電影的評分。
下麵是矩陣分解預測評分的工作原理:
# for f = 1,2,….,k :
# for rui ε R :
# predict rui
# update puk and qki
基於每個潛在特徵,R矩陣中所有缺失的評分都將使用預測的rui值進行填充。然後利用梯度下降法對puk和qki進行更新,得到它們的最優值。過程如下圖所示:

現在已經瞭解了這個演演算法的內部工作原理,接下來我們將舉一個例子,看看如何將矩陣分解成它的組成部分。
使用一個2×3矩陣,如下圖所示:

這裡我們有2個使用者和3部電影的相應評分。現在,我們將這個矩陣分解成子部分,如下所示:
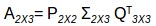
AAT的特徵值會給我們P矩陣而ATA的特徵值會給我們Q矩陣,Σ是AAT或ATA矩陣特徵值的平方根。
計算AAT的特徵值:
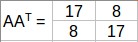
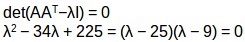
AAT的特徵值是25,9同樣道理,我們可以計算出ATA的特徵值。這些值是25,9,0,現在我們可以計算AAT和ATA對應的特徵向量。
特徵值λ= 25,我們有:
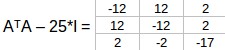
可以按行簡化為:
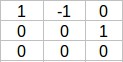
該矩陣核心中的單位向量為:

同樣,λ= 9我們有:

可以按行簡化為:

該矩陣核心中的單位向量為:

對於最後一個特徵向量,我們可以找到一個單位向量垂直於q1和q2。所以,

Σ2X3矩陣是AAT或ATA特徵值的平方根即25和9:

最後,我可可以透過公式σpi = Aqi, or pi = 1/σ(Aqi) 計算P2X2 :

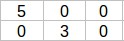
所以由A矩陣分解出的矩陣如下所示:


我們有了P和Q矩陣,我們可以使用梯度下降法得到它們的最佳化版本,現在我們來使用矩陣分解來構建推薦引擎。
7 使用矩陣分解構建一個推薦引擎
我們首先定義一個函式來預測使用者對所有未被他或她評分的所有電影的評分。
class MF():
# Initializing the user-movie rating matrix, no. of latent features, alpha and beta.
def __init__(self, R, K, alpha, beta, iterations):
self.R = R
self.num_users, self.num_items = R.shape
self.K = K
self.alpha = alpha
self.beta = beta
self.iterations = iterations
# Initializing user-feature and movie-feature matrix
def train(self):
self.P = np.random.normal(scale=1./self.K, size=(self.num_users, self.K))
self.Q = np.random.normal(scale=1./self.K, size=(self.num_items, self.K))
# Initializing the bias terms
self.b_u = np.zeros(self.num_users)
self.b_i = np.zeros(self.num_items)
self.b = np.mean(self.R[np.where(self.R != 0)])
# List of training samples
self.samples = [
(i, j, self.R[i, j])
for i in range(self.num_users)
for j in range(self.num_items)
if self.R[i, j] > 0
]
# Stochastic gradient descent for given number of iterations
training_process = []
for i in range(self.iterations):
np.random.shuffle(self.samples)
self.sgd()
mse = self.mse()
training_process.append((i, mse))
if (i+1) % 20 == 0:
print(“Iteration: %d ; error = %.4f” % (i+1, mse))
return training_process
# Computing total mean squared error
def mse(self):
xs, ys = self.R.nonzero()
predicted = self.full_matrix()
error = 0
for x, y in zip(xs, ys):
error += pow(self.R[x, y] – predicted[x, y], 2)
return np.sqrt(error)
# Stochastic gradient descent to get optimized P and Q matrix
def sgd(self):
for i, j, r in self.samples:
prediction = self.get_rating(i, j)
e = (r – prediction)
self.b_u[i] += self.alpha * (e – self.beta * self.b_u[i])
self.b_i[j] += self.alpha * (e – self.beta * self.b_i[j])
self.P[i, :] += self.alpha * (e * self.Q[j, :] – self.beta * self.P[i,:])
self.Q[j, :] += self.alpha * (e * self.P[i, :] – self.beta * self.Q[j,:])
# Ratings for user i and moive j
def get_rating(self, i, j):
prediction = self.b + self.b_u[i] + self.b_i[j] + self.P[i, :].dot(self.Q[j, :].T)
return prediction
# Full user-movie rating matrix
def full_matrix(self):
return mf.b + mf.b_u[:,np.newaxis] + mf.b_i[np.newaxis:,] + mf.P.dot(mf.Q.T)
現在我們有了一個可以預測評分的函式,這個函式的輸入是:
-
R-使用者-電影評分矩陣
-
K-潛在特徵的個數
-
Alpha-隨機梯度下降的學習率
-
Beta-正則化引數偏差
-
Iterations-執行隨機梯度下降的迭代次數
我們必須將使用者-電影評分轉換為矩陣形式,在python中使用pivot函式來完成轉換。
R= np.array(ratings.pivot(index = ‘user_id’, columns =’movie_id’, values = ‘rating’).fillna(0))
fillna(0),表示將所有缺失值都用0來填充。現在我們有了R矩陣,可以初始化潛在特徵的數量,但是這些特徵的數量必須小於或等於原始特徵的數量。
現在我們預測所有的缺失的評分
引數初始化為:K=20,alpha=0.001,
beta=0.01,迭代次數=100。
mf = MF(R, K=20, alpha=0.001, beta=0.01, iterations=100)
training_process = mf.train()
print()
print(“P x Q:”)
print(mf.full_matrix())
print()
下麵給我們提供了每20次迭代後的誤差值,最後是完整的使用者-電影評分矩陣,輸出是這樣的:

我們已經建立了我們的推薦引擎,接下來我們關註下一節如何評估推薦引擎的效能。
8 推薦引擎的評價指標
為了評估推薦引擎的效能,我們可以使用以下評價指標。
8.1 召回率
-
實際推薦的電影中,使用者喜歡的比例有多少
-
公式如下:

-
這裡的tp表示推薦給使用者電影中他或她喜歡的數量tp+fn表示他或她喜歡的總數量
-
如果一個使用者喜歡5個電影而推薦引擎決定顯示其中的3個,那麼召回率就是0.6
-
召回率越大,推薦效果越好
8.2 精確度
-
在所有推薦的電影中,使用者實際喜歡多少?
-
計算公式如下:

-
這裡的tp表示推薦給他/她喜歡的電影數量,tp+fp代表了向用戶推薦的全部電影數量。
-
如果向用戶推薦5部電影,他喜歡其中4部,那麼精度將是0.8。
-
精度越高,推薦效果越好
-
但是考慮一下這樣的情況:如果我們簡單地推薦所有的電影,它們肯定會改寫使用者喜歡的電影。所以我們有百分之百的召回率!但是仔細考慮一下精確度,如果我們推薦1000部電影,而使用者只喜歡其中的10部,那麼精確度是0.1%,這真的很低。所以,我們的標的應該是最大化精確度和召回率。
8.3 均方誤差(RMSE)
它衡量的是預測評分中的誤差:

-
Predicted 是模型預測的評分,Actual是原始評分
-
如果一個使用者給一部電影打5分,我們預測它的打分是4,那麼RMSE是1。
-
RMSE越小,推薦效果越好
上面的指標告訴我們模型給出的推薦有多準確,但它們並不關註推薦的順序,也就是說,它們不關註首先推薦的產品,以及之後的順序。我們還需要一些度量標準,它們需要考慮了推薦產品的順序。接下來我們來看看一些排名指標(ranking metrics):
8.4 MRR(Mean Reciprocal Rank)
-
評估推薦的串列

-
假設我們已經向用戶推薦了3部電影A,B,C,並且它們順序是給定的。但是使用者只喜歡電影C,因為電影C的等級是3,所以Reciprocal Rank是1/3。
-
MRR越大,代表推薦效果越好
8.5 MAP at k(Mean Average Precision at cutoff k K位置截止的平均精度均值)
-
精確度和召回率並不關係推薦中的順序
-
截止k的精度是透過只考慮從1到k推薦的子集來計算的精度

-
假設我們已經給出了三個推薦,[0,1,1]。這裡0表示推薦是不正確的,而1表示推薦是正確的。那麼k的精度是[0 ,1/2, 2/3],平均精度是(1/3)*(0+1/2+2/3)=0.38。
-
平均精度 越大,推薦的就越準確
8.6 NDCG(Normalized Discounted Cumulative Gain歸一化累積折損增益
-
MAP和NDCG的主要區別在於,MAP假設物品是感興趣的(或者不是),而NDCG給出了相關性評分。
-
我們透過一個例子來理解它:假設在10部電影中——A到J,我們可以推薦前五部電影,即A、B、C、D和E,而我們不能推薦其他5部電影,也就是F,G,H,I和J,最終推薦是[A B C D]。所以在這個例子中NDCG將是1因為推薦的產品與使用者相關。
-
NDCG值越大,推薦效果越好
9 還可以嘗試什麼?
到目前為止,我們已經瞭解了什麼是推薦引擎以及它的不同型別和它們的工作方式。基於內容的過濾和協同過濾演演算法都有各自的優點和缺點。
在某些領域,生成對商品的有用描述是非常困難的。如果使用者之前的行為沒有提供有用的資訊,基於內容的推薦模型將不會選擇該商品。我們還需要使用額外的技術,以便系統能夠在使用者已經顯示出興趣的範圍之外給出推薦。
協同過濾模型沒有這些缺點。因為不需要對所推薦的商品進行描述,系統可以處理任何型別的資訊。此外,它還可以推薦使用者以前沒有興趣的產品,但是,如果沒有使用者對新商品進行評分,那麼協同過濾就不能為新商品進行推薦。即使使用者開始對該商品進行評分,為了做出準確的推薦,也需要一段時間才能獲得足夠多的評分來做推薦。
一個將內容過濾和協同過濾結合起來的系統,可以潛在地從內容的表示和使用者的相似性中獲得更多資訊。將基於內容的推薦和協同過濾的推薦進行加權平均,這是把協同性和基於內容過濾結合起來的一種方法。
這樣做的各種方法有:
-
組合商品分數:
我們把從兩種推薦方法中得到的評分組合起來,最簡單的方式是取平均值。
假設有一種方法推薦對一部電影的評分為4,而另一種方法則推薦對同一部電影的評分為5。所以最終的建議是兩個評級的平均值,也就是4 .5。
我們也可以給不同的方法分配不同的權重。
-
組合商品排名
假設協同過濾推薦了5部電影A、B、C、D和E,並且按以下順序:A、B、C、D、E,而基於內容過濾則按照以下順序推薦:B、D、A、C、E。
那麼電影的順序如下所示:
協同過濾:
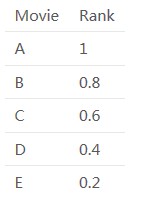
基於內容過濾:

因此,一個混合推薦引擎將結合這些排名,並根據綜合排名做出最終的推薦。合併後的排名是:

最後的推薦也會基於這個排名,可以看到推薦的順序會是:B, A, D, C, E。
透過這種方式,可以將兩種或更多的方法組合起來,構建一個混合的推薦引擎,並提高它們的總體推薦精度和效率。
尾註
本文全面講述了有關推薦引擎的內容,如果你想開始推薦引擎方面學習,本文也會是一個很好的幫助。我們不僅討論了基本的推薦技術,而且還寫到瞭如何實現當今業界的一些更先進的技術。
我們也針對每種技術聯絡到對應的現實問題,作為一個想要學習如何製作推薦引擎的人,我建議您學習本教程中討論的技術,併在您的模型中實現它們。
你覺得這篇文章有用嗎?可以在下方評論分享出你的觀點!
原文標題:
Comprehensive Guide to build a Recommendation Engine from scratch (in Python)
原文連結:
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-recommendation-engine-python/
譯者簡介:申利彬,研究生在讀,主要研究方向大資料機器學習。目前在學習深度學習在NLP上的應用,希望在THU資料派平臺與愛好大資料的朋友一起學習進步。
END
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
80%的運營註定了打雜?因為你沒有搭建出一套有效的使用者運營體系
合作請加qq:365242293
更多相關知識請回覆:“ 月光寶盒 ”;
資料分析(ID : ecshujufenxi )網際網路科技與資料圈自己的微信,也是WeMedia自媒體聯盟成員之一,WeMedia聯盟改寫5000萬人群。
