
在大資料領域,使用者畫像的作用遠不止於此。使用者的行為資料無法直接用於資料分析和模型訓練,我們也無法從使用者的行為日誌中直接獲取有用的資訊。而將使用者的行為資料標簽化以後,我們對使用者就有了一個直觀的認識。
同時計算機也能夠理解使用者,將使用者的行為資訊用於個性化推薦、個性化搜尋、廣告精準投放和智慧營銷等領域。
作者:馬海平 於俊 呂昕 向海
本文摘編自《Spark機器學習進階實戰》,如需轉載請聯絡我們
01 概述
使用者畫像的核心工作就是給使用者打標簽,標簽通常是人為規定的高度精煉的特徵標識,如年齡、性別、地域、興趣等。這些標簽集合就能抽象出一個使用者的資訊全貌,如圖10-1所示是某個使用者的標簽集合,每個標簽分別描述了該使用者的一個維度,各個維度之間相互聯絡,共同構成對使用者的一個整體描述。

▲圖10-1 使用者標簽集合
02 使用者畫像流程
1. 整體流程
我們對構建使用者畫像的方法進行總結歸納,發現使用者畫像的構建一般可以分為標的分析、體系構建、畫像建立三步。
畫像構建中用到的技術有資料統計、機器學習和自然語言處理技術(NLP)等,如圖10-3所示。具體的畫像構建方法會在本章後面的部分詳細介紹。
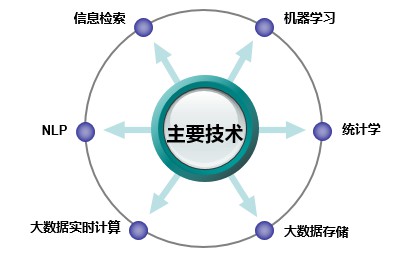
▲圖10-3 使用者畫像的構建技術
2. 標簽體系
目前主流的標簽體系都是層次化的,如下圖10-4所示。首先標簽分為幾個大類,每個大類下進行逐層細分。在構建標簽時,我們只需要構建最下層的標簽,就能夠對映到上面兩級標簽。
上層標簽都是抽象的標簽集合,一般沒有實用意義,只有統計意義。例如我們可以統計有人口屬性標簽的使用者比例,但使用者有人口屬性標簽本身對廣告投放沒有任何意義。

▲圖10-4 網際網路大資料領域常用標簽體系
用於廣告投放和精準營銷的一般是底層標簽,對於底層標簽有兩個要求:一個是每個標簽只能表示一種含義,避免標簽之間的重覆和衝突,便於計算機處理;另一個是標簽必須有一定的語意,方便相關人員理解每個標簽的含義。
此外,標簽的粒度也是需要註意的,標簽粒度太粗會沒有區分度,粒度過細會導致標簽體系太過複雜而不具有通用性。
表10-1列舉了各個大類常見的底層標簽。
|
標簽類別 |
標簽內容 |
|
人口標簽 |
性別、年齡、地域、教育水平、出生日期、職業、星座 |
|
興趣特徵 |
興趣愛好、使用APP/網站、瀏覽/收藏內容、互動內容、品牌偏好、產品偏好 |
|
社會特徵 |
婚姻狀況、家庭情況、社交/資訊渠道偏好 |
|
消費特徵 |
收入狀況、購買力水平、已購商品、購買渠道偏好、最後購買時間、購買頻次 |
▲表10-1:常見標簽
最後介紹一下各類標簽構建的優先順序。構建的優先順序需要綜合考慮業務需求、構建難易程度等,業務需求各有不同,這裡介紹的優先順序排序方法主要依據構建的難易程度和各類標簽的依存關係,優先順序如圖10-5所示。

▲圖10-5 各類標簽的構建優先順序
基於原始資料首先構建的是事實標簽,事實標簽可以從資料庫直接獲取(如註冊資訊),或透過簡單的統計得到。這類標簽構建難度低、實際含義明確,且部分標簽可用作後續標簽挖掘的基礎特徵(如產品購買次數可用來作為使用者購物偏好的輸入特徵資料)。
事實標簽的構造過程,也是對資料加深理解的過程。對資料進行統計的同時,不僅完成了資料的處理與加工,也對資料的分佈有了一定的瞭解,為高階標簽的構造做好了準備。
模型標簽是標簽體系的核心,也是使用者畫像工作量最大的部分,大多數使用者標簽的核心都是模型標簽。模型標簽的構造大多需要用到機器學習和自然語言處理技術,我們下文中介紹的標簽構造方法主要指的是模型標簽,具體的構造演演算法會在本文第03章詳細介紹。
最後構造的是高階標簽,高階標簽是基於事實標簽和模型標簽進行統計建模得出的,它的構造多與實際的業務指標緊密聯絡。只有完成基礎標簽的構建,才能夠構造高階標簽。構建高階標簽使用的模型,可以是簡單的資料統計,也可以是複雜的機器學習模型。
03 構建使用者畫像
我們把標簽分為三類,這三類標簽有較大的差異,構建時用到的技術差別也很大。
第一類是人口屬性,這一類標簽比較穩定,一旦建立很長一段時間基本不用更新,標簽體系也比較固定;第二類是興趣屬性,這類標簽隨時間變化很快,標簽有很強的時效性,標簽體系也不固定;第三類是地理屬性,這一類標簽的時效性跨度很大,如GPS軌跡標簽需要做到實時更新,而常住地標簽一般可以幾個月不用更新,挖掘的方法和前面兩類也大有不同,如圖10-6所示。
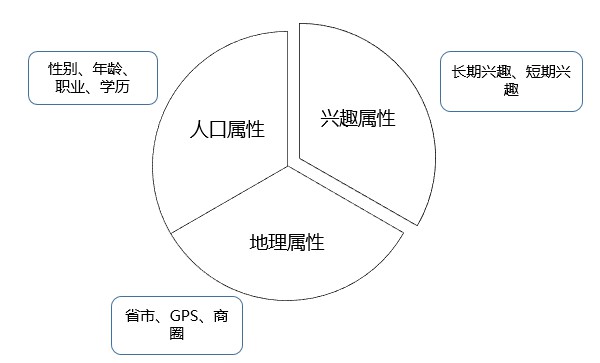
▲圖10-6 三類標簽屬性
1. 人口屬性畫像
人口屬性包括年齡、性別、學歷、人生階段、收入水平、消費水平、所屬行業等。這些標簽基本是穩定的,構建一次可以很長一段時間不用更新,標簽的有效期都在一個月以上。同時標簽體系的劃分也比較固定,表10-2是MMA中國無線營銷聯盟對人口屬性的一個劃分。
大部分主流的人口屬性標簽都和這個體系比較類似,有些在分段上有一些區別。
|
性別 |
男 |
|
女 |
|
|
未知 |
|
|
年齡 |
12 以下 |
|
12-17 |
|
|
18-19 |
|
|
20-24 |
|
|
25-29 |
|
|
30-34 |
|
|
35-39 |
|
|
40-44 |
|
|
45-49 |
|
|
50-54 |
|
|
55-59 |
|
|
60-64 |
|
|
65 及以上 |
|
|
未知 |
|
|
月收入 |
3500 元以下 |
|
3500-5000 元 |
|
|
5000-8000 元 |
|
|
8000-12500 元 |
|
|
12500-25000 元 |
|
|
25001-40000 |
|
|
40000 元以上 |
|
|
未知 |
|
|
婚姻狀態 |
未婚 |
|
已婚 |
|
|
離異 |
|
|
未知 |
|
|
從事行業 |
廣告/營銷/公關 |
|
航天 |
|
|
農林化工 |
|
|
汽車 |
|
|
計算機/網際網路 |
|
|
建築 |
|
|
教育/學生 |
|
|
能源/採礦 |
|
|
金融/保險/房地產 |
|
|
政府/軍事/房地產 |
|
|
服務業 |
|
|
傳媒/出版/娛樂 |
|
|
醫療/保險服務 |
|
|
製藥 |
|
|
零售 |
|
|
電信/網路 |
|
|
旅遊/交通 |
|
|
其它 |
|
|
教育程度 |
初中及以下 |
|
高中 |
|
|
中專 |
|
|
大專 |
|
|
本科 |
|
|
碩士 |
|
|
博士 |
▲表10-2 人口標簽
很多產品(如QQ、facebook等)都會引導使用者填寫基本資訊,這些資訊就包括年齡、性別、收入等大多數的人口屬性,但完整填寫個人資訊的使用者只佔很少一部分。而對於無社交屬性的產品(如輸入法、團購APP、影片網站等)使用者資訊的填充率非常低,有的甚至不足5%。
在這種情況下,我們一般會用填寫了資訊的這部分使用者作為樣本,把使用者的行為資料作為特徵訓練模型,對無標簽的使用者進行人口屬性的預測。這種模型把使用者的標簽傳給和他行為相似的使用者,可以認為是對人群進行了標簽擴散,因此常被稱為標簽擴散模型。
下麵我們用影片網站性別年齡畫像的例子來說明標簽擴散模型是如何構建的。
一個影片網站,希望瞭解自己的使用者組成,於是對使用者的性別進行畫像。透過資料統計,有大約30%的使用者註冊時填寫了個人資訊,我們將這30%的使用者作為訓練集,來構建全量使用者的性別畫像,我們的資料如表10-3所示。
|
Uid |
Gender |
Watched videos |
|
525252 |
Male |
Game of throat |
|
532626 |
Runing men、最強大腦 |
|
|
526267 |
琅琊榜、偽裝者 |
|
|
573373 |
Female |
歡樂喜劇人 |
▲表10-3:影片網站使用者資料
下麵我們來構建特徵。透過分析,我們發現男性和女性,對於影片的偏好是有差別的,因此使用觀看的影片串列來預測使用者性別有一定的可行性。此外我們還可以考慮使用者的觀看時間、瀏覽器、觀看時長等,為了簡化,這裡我們只使用使用者觀看的影片特徵。
由於觀看影片特徵是稀疏特徵,我們可以使用呼叫MLlib,使用LR、線性SVM等模型進行訓練。考慮到註冊使用者填寫的使用者資訊本身的準確率不高,我們可以從30%的樣本集中提取準確率較高的部分(如使用者資訊填寫較完備的)用於訓練,因此我們整體的訓練流程如圖10-7所示。
對於預測性別這樣的二分類模型,如果行為的區分度較好,一般準確率和改寫率都可以達到70%左右。
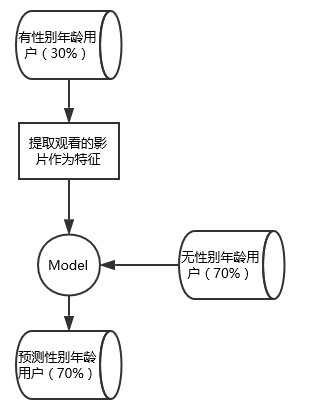
▲圖10-7 訓練流程
對於人口屬性標簽,只要有一定的樣本標簽資料,並找到能夠區分標簽分類的使用者行為特徵,就可以構建標簽擴散模型。其中使用的技術方法主要是機器學習中的分類技術,常用的模型有LR、FM、SVM、GBDT等。
2. 興趣畫像
興趣畫像是網際網路領域使用最廣泛的畫像,網際網路廣告、個性化推薦、精準營銷等各個領域最核心的標簽都是興趣標簽。興趣畫像主要是從使用者海量行為日誌中進行核心資訊的抽取、標簽化和統計,因此在構建使用者興趣畫像之前需要先對使用者有行為的內容進行內容建模。
內容建模需要註意粒度,過細的粒度會導致標簽沒有泛化能力和使用價值,過粗的粒度會導致沒有區分度。
為了保證興趣畫像既有一定的準確度又有較好的泛化性,我們會構建層次化的興趣標簽體系,使用中同時用幾個粒度的標簽去匹配,既保證了標簽的準確性,又保證了標簽的泛化性。下麵我們用新聞的使用者興趣畫像舉例,介紹如何構建層次化的興趣標簽。
2.1 內容建模
新聞資料本身是非結構化的,首先需要人工構建一個層次的標簽體系。我們考慮如下圖10-9的一篇新聞,看看哪些內容可以表示使用者的興趣。

▲圖10-9 新聞例子
首先,這是一篇體育新聞,體育這個新聞分類可以表示使用者興趣,但是這個標簽太粗了,使用者可能只對足球感興趣,體育這個標簽就顯得不夠準確。
其次,我們可以使用新聞中的關鍵詞,尤其是裡面的專有名詞(人名、機構名),如“桑切斯”、“阿森納”、“厄齊爾”,這些詞也表示了使用者的興趣。關鍵詞的主要問題在於粒度太細,如果一天的新聞裡沒有這些關鍵詞出現,就無法給使用者推薦內容。
最後,我們希望有一個中間粒度的標簽,既有一定的準確度,又有一定的泛化能力。於是我們嘗試對關鍵詞進行聚類,把一類關鍵詞當成一個標簽,或者把一個分類下的新聞進行拆分,生成像“足球”這種粒度介於關鍵詞和分類之間的主題標簽。我們可以使用文字主題聚類完成主題標簽的構建。
至此我們就完成了對新聞內容從粗到細的“分類-主題-關鍵詞”三層標簽體系內容建模,新聞的三層標簽如表10-4所示。
|
分類 |
主題 |
關鍵詞 |
|
|
使用演演算法 |
文字分類、SVM、LR、Bayes |
PLSA、LDA |
Tf*idf、專門識別、領域詞表 |
|
粒度 |
粗 |
中 |
細 |
|
泛化性 |
好 |
中 |
差 |
|
舉例 |
體育、財經、娛樂 |
足球、理財 |
梅西、川普、機器學習 |
|
量級 |
10-30 |
100-1000 |
百萬 |
▲表10-4 三層標簽體系
既然主題的準確率和改寫率都不錯,我們只使用主題不就可以了嘛?為什麼還要構建分類和關鍵詞這兩層標簽呢?這麼做是為了給使用者進行盡可能精確和全面的內容推薦。
當使用者的關鍵詞命中新聞時,顯然能夠給使用者更準確的推薦,這時就不需要再使用主題標簽;而對於比較小眾的主題(如體育類的冰上運動主題),若當天沒有新聞改寫,我們就可以根據分類標簽進行推薦。層次標簽兼顧了對使用者興趣刻畫的改寫率和準確性。
2.2 興趣衰減
在完成內容建模以後,我們就可以根據使用者點選,計算使用者對分類、主題、關鍵詞的興趣,得到使用者興趣標簽的權重。最簡單的計數方法是使用者點選一篇新聞,就把使用者對該篇新聞的所有標簽在使用者興趣上加一,使用者對每個詞的興趣計算就使用如下的公式:

其中:詞在這次瀏覽的新聞中出現C=1,否則C=0,weight表示詞在這篇新聞中的權重。
這樣做有兩個問題:一個是使用者的興趣累加是線性的,數值會非常大,老的興趣權重會特別高;另一個是使用者的興趣有很強的時效性,昨天的點選要比一個月之前的點選重要的多,線性疊加無法突出近期興趣。
為瞭解決這個問題,需要要對使用者興趣得分進行衰減,我們使用如下的方法對興趣得分進行次數衰減和時間衰減。
次數衰減的公式如下:

其中,α是衰減因子,每次都對上一次的分數做衰減,最終得分會收斂到一個穩定值 ,α取0.9時,得分會無限接近10。
時間衰減的公式如下:

它表示根據時間對興趣進行衰減,這樣做可以保證時間較早的興趣會在一段時間以後變的非常弱,同時近期的興趣會有更大的權重。根據使用者興趣變化的速度、使用者活躍度等因素,也可以對興趣進行周級別、月級別或小時級別的衰減。
3. 地理位置畫像
地理位置畫像一般分為兩部分:一部分是常駐地畫像;一部分是GPS畫像。兩類畫像的差別很大,常駐地畫像比較容易構造,且標簽比較穩定,GPS畫像需要實時更新。
常駐地包括國家、省份、城市三級,一般只細化到城市粒度。常駐地的挖掘基於使用者的IP地址資訊,對使用者的IP地址進行解析,對應到相應的城市,對使用者IP出現的城市進行統計就可以得到常駐城市標簽。
使用者的常駐城市標簽,不僅可以用來統計各個地域的使用者分佈,還可以根據使用者在各個城市之間的出行軌跡識別出差人群、旅遊人群等,如圖10-10所示是人群出行軌跡的一個示例。
▲圖10-10 人群出行軌跡
GPS資料一般從手機端收集,但很多手機APP沒有獲取使用者 GPS資訊的許可權。能夠獲取使用者GPS資訊的主要是百度地圖、滴滴打車等出行導航類APP,此外收集到的使用者GPS資料比較稀疏。
百度地圖使用該方法結合時間段資料,構建了使用者公司和家的GPS標簽。此外百度地圖還基於GPS資訊,統計各條路上的車流量,進行路況分析,如圖10-11是北京市的實時路況圖,紅色表示擁堵線路。

▲圖10-11 北京的實時路況圖
04 使用者畫像評估和使用
人口屬性畫像的相關指標比較容易評估,而興趣畫像的標簽比較模糊,興趣畫像的人為評估比較困難,我們對於興趣畫像的常用評估方法是設計小流量的A/B-test進行驗證。
我們可以篩選一部分標簽使用者,給這部分使用者進行和標簽相關的推送,看標簽使用者對相關內容是否有更好的反饋。
例如,在新聞推薦中,我們給使用者構建了興趣畫像,我們從體育類興趣使用者中選取一小批使用者,給他們推送體育類新聞,如果這批使用者的點選率和閱讀時長明顯高於平均水平,就說明標簽是有效的。
1. 效果評估
使用者畫像效果最直接的評估方法就是看其對實際業務的提升,如網際網路廣告投放中畫像效果主要看使用畫像以後點選率和收入的提升,精準營銷過程中主要看使用畫像後銷量的提升等。
但是如果把一個沒有經過效果評估的模型直接用到線上,風險是很大的,因此我們需要一些上線前可計算的指標來衡量使用者畫像的質量。
使用者畫像的評估指標主要是指準確率、改寫率、時效性等指標。
1.1 準確率
標簽的準確率指的是被打上正確標簽的使用者比例,準確率是使用者畫像最核心的指標,一個準確率非常低的標簽是沒有應用價值的。準確率的計算公式如下:
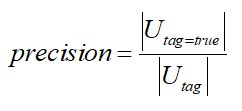
其中| Utag |表示被打上標簽的使用者數,| Utag=true |表示有標簽使用者中被打對標簽的使用者數。準確率的評估一般有兩種方法:一種是在標註資料集裡留一部分測試資料用於計算模型的準確率;另一種是在全量使用者中抽一批使用者,進行人工標註,評估準確率。
由於初始的標註資料集的分佈和全量使用者分佈相比可能有一定偏差,故後一種方法的資料更可信。準確率一般是對每個標簽分別評估,多個標簽放在一起評估準確率是沒有意義的。
1.2 改寫率
標簽的改寫率指的是被打上標簽的使用者佔全量使用者的比例,我們希望標簽的改寫率盡可能的高。但改寫率和準確率是一對矛盾的指標,需要對二者進行權衡,一般的做法是在準確率符合一定標準的情況下,盡可能的提升改寫率。
我們希望改寫盡可能多的使用者,同時給每個使用者打上盡可能多的標簽,因此標簽整體的改寫率一般拆解為兩個指標來評估。一個是標簽改寫的使用者比例,另一個是改寫使用者的人均標簽數,前一個指標是改寫的廣度,後一個指標表示改寫的密度。
使用者改寫比例的計算方法是:

其中| U |表示使用者的總數,| Utag |表示被打上標簽的使用者數。
人均標簽數的計算方法是:
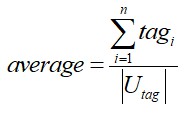
其中| tagi |表示每個使用者的標簽數,| Utag |表示被打上標簽的使用者數。改寫率既可以對單一標簽計算,也可以對某一類標簽計算,還可以對全量標簽計算,這些都是有統計意義的。
1.3 時效性
有些標簽的時效性很強,如興趣標簽、出現軌跡標簽等,一週之前的就沒有意義了;有些標簽基本沒有時效性,如性別、年齡等,可以有一年到幾年的有效期。對於不同的標簽,需要建立合理的更新機制,以保證標簽時間上的有效性。
1.4 其他指標
標簽還需要有一定的可解釋性,便於理解;同時需要便於維護且有一定的可擴充套件性,方便後續標簽的新增。這些指標難以給出量化的標準,但在構架使用者畫像時也需要註意。
2. 畫像使用
使用者畫像在構建和評估之後,就可以在業務中應用,一般需要一個視覺化平臺,對標簽進行檢視和檢索。畫像的視覺化一般使用餅圖、柱狀圖等對標簽的改寫人數、改寫比例等指標做形象的展示,如下圖10-12所示是使用者畫像的一個視覺化介面。

▲圖10-12 使用者畫像的視覺化介面
此外,對於構建的畫像,我們還可以使用不同維度的標簽,進行高階的組合分析,產出高質量的分析報告。在智慧營銷、計算廣告、個性化推薦等領域使用者畫像都可以得到應用,具體的應用方法,與其應用領域結合比較緊密,我們不再詳細介紹。
本文摘編自《Spark機器學習進階實戰》,經出版方授權釋出。
延伸閱讀《Spark機器學習進階實戰》
點選上圖瞭解及購買
轉載請聯絡微信:togo-maruko
推薦語:科大訊飛大資料專家撰寫,從基礎到應用,面面俱到。

據統計,99%的大咖都完成了這個神操作
▼
更多精彩 在公眾號後臺對話方塊輸入以下關鍵詞 檢視更多優質內容! PPT | 報告 | 讀書 | 書單 Python | 機器學習 | 深度學習 | 神經網路 區塊鏈 | 揭秘 | 乾貨 | 數學
誰再問你“天天爬那些資料有什麼用”,就把這5本書扔給他!
Q: 你都做過哪些網站、app的使用者畫像?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

 點選閱讀原文,瞭解更多
點選閱讀原文,瞭解更多
