導讀:RPC,微服務,Service Mesh這些服務之間的呼叫是什麼原理?
作者 codedump codedump.info 博主,多年從事網際網路伺服器後臺開發工作。可訪問作者部落格閱讀 codedump 更多文章。
本文專註於演化過程中每一步的為什麼(Why)和是什麼(What)上面,儘量不在技術細節(How)上面做太多深入。
服務的三要素
一般而言,一個網路服務包括以下的三個要素:
-
地址:呼叫方根據地址訪問到網路介面。地址包括以下要素:IP地址、服務埠、服務協議(TCP、UDP,etc)。
-
協議格式:協議格式指的是該協議都有哪些欄位,由介面提供者與協議呼叫者協商之後確定下來。
-
協議名稱:或者叫協議型別,因為在同一個服務監聽埠上面,可能同時提供多種介面服務於呼叫方,這時候需要協議型別(名稱)來區分不同的網路介面。
需要說明在服務地址中:
-
IP地址提供了在網際網路上找到這臺機器的憑證。
-
協議以及服務埠提供了在這臺機器上找到提供服務的行程的憑證。
這都屬於TCPIP協議棧的知識點,不在這裡深入詳述。
這裡還需要對涉及到服務相關的一些名詞做解釋。
-
服務實體:服務對應的IP地址加埠的簡稱。需要訪問服務的時候,需要先定址知道該服務每個執行實體的地址加埠,然後才能建立連線進行訪問。
-
服務註冊:某個服務實體宣稱自己提供了哪些服務,即某個IP地址+埠都提供了哪些服務介面。
-
服務發現:呼叫方透過某種方式找到服務提供方,即知道服務執行的IP地址加埠。
基於IP地址的呼叫
最初的網路服務,透過原始的IP地址暴露給呼叫者。這種方式有以下的問題:
-
IP地址是難於記憶並且無意義的。
-
另外,從上面的服務三要素可以看到,IP地址其實是一個很底層的概念,直接對應了一臺機器上的一個網路介面,如果直接使用IP地址進行定址,更換機器就變的很麻煩。
“儘量不使用過於底層的概念來提供服務”,是這個演化流程中的重要原則,好比在今天已經很少能夠看到直接用組合語言編寫程式碼的場景了,取而代之的,就是越來越多的抽象,本文中就展現了服務呼叫這一領域在這個過程中的演進流程。
在現在除非是測試階段,否則已經不能直接以IP地址的形式將服務提供出去了。
域名系統
前面的IP地址是給主機做為路由器定址的數字型標識,並不好記憶。此時產生了域名系統,與單純提供IP地址相比,域名系統由於使用有意義的域名來標識服務,所以更容易記憶。另外,還可以更改域名所對應的IP地址,這為變換機器提供了便利。有了域名之後,呼叫方需要訪問某個網路服務時,首先到域名地址服務中,根據DNS協議將域名解析為相應的IP地址,再根據傳回的IP地址來訪問服務。
從這裡可以看到,由於多了一步到域名地址服務查詢對映IP地址的流程,所以多了一步解析,為了減少這一步帶來的影響,呼叫方會快取解析之後的結果,在一段時間內不過期,這樣就省去了這一步查詢的代價。
協議的接收與解析
以上透過域名系統,已經解決了服務IP地址難以記憶的問題,下麵來看協議格式解析方面的演進。
一般而言,一個網路協議包括兩部分:
-
協議包頭:這裡儲存協議的元資訊(meta infomation),其中可能會包括協議型別、報體長度、協議格式等。需要說明的是,包頭一般為固定大小,或者有明確的邊界(如HTTP協議中的\r\n結束符),否則無法知道包頭何時結束。
-
協議包體:具體的協議內容。
無論是HTTP協議,又或者是自定義的二進位制網路協議,大體都由這兩部分組成。

由於很多時候不能一口氣接收完畢客戶端的協議資料,因此在接收協議資料時,一般採用狀態機來做協議資料的接收:

接收完畢了網路資料,在協議解析方面卻長期停滯不前。一個協議,有多個欄位(field),而這些不同的欄位有不同的型別,簡單的raw型別(如整型、字串)還好說,但是遇到複雜的型別如字典、陣列等就比較麻煩。
當時常見的手段有以下幾種:
-
使用json或者xml這樣的資料格式。好處是可視性強,表達起上面的複雜型別也方便,缺陷是容易被破解,傳輸過去的資料較大。
-
自定義二進位制協議。每個公司做大了,在這一塊難免有幾個類似的輪子。筆者見過比較典型的是所謂的TLV格式(Type-Length-Value),自定義二進位制格式最大的問題出現在協議聯調與協商的時候,由於可視性比較弱,有可能這邊少了一個欄位那邊多了一個欄位,給聯調流程帶來麻煩。
上面的問題一直到Google的Protocol Buffer(以下簡稱PB)出現之後才得到很大的改善。PB出現之後,也有很多類似的技術出現,如Thrift、MsgPack等,不在這裡闡述,將這一類技術都以PB來描述。
與前面的兩種手段相比,PB具有以下的優點:
-
使用proto格式檔案來定義協議格式,proto檔案是一個典型的DSL(domain-specific language)檔案,檔案中描述了協議的具體格式,每個欄位都是什麼型別,哪些是可選欄位哪些是必選欄位。有了proto檔案之後,C\S兩端是透過這個檔案來進行協議的溝通交流的,而不是具體的技術細節。
-
PB能透過proto檔案生成各種語言對應的序列化反序列化程式碼,給跨語言呼叫提供了方便。
-
PB自己能夠對特定型別進行資料壓縮,減少資料大小。
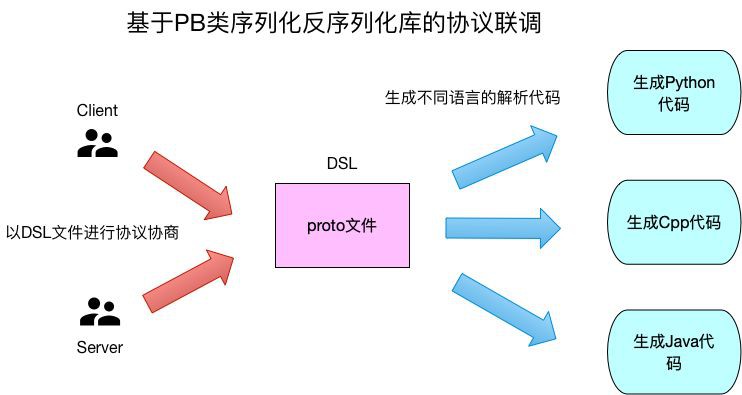
服務閘道器
有了前面的演化之後,寫一個簡單的單機伺服器已經不難。然而,當隨著訪問量的增大,一臺機器已經不足以支撐所有的請求,此時就需要橫向擴充套件多加一些業務伺服器。
而前面透過域名訪問服務的架構就遇到了問題:如果有多個服務實體可以提供相同的服務,那麼勢必需要在DNS的域名解析中將域名與多個地址進行系結。這樣的方案就有如下的問題:
-
如何檢查這些實體的健康情況,同時在發現出現問題的時候增刪服務實體地址?即所謂的服務高可用問題。
-
把這些服務實體地址都暴露到外網,會不會涉及到安全問題?即使可以解決安全問題,那麼也需要每臺機器都做安全策略。
-
由於DNS協議的特點,增刪服務實體並不是實時的,有時候會影響到業務。
為瞭解決這些問題,就引入了反向代理閘道器這一元件。它提供如下的功能:
-
負載均衡功能:根據某些演演算法將請求分派到服務實體上。
-
提供管理功能,可以給運維管理員增減服務實體。
-
由於它決定了服務請求流量的走向,因此還可以做更多的其他功能:灰度引流、安全防攻擊(如訪問黑白名單、解除安裝SSL證書)等。
有四層和七層負載均衡軟體,其中四層負載均衡這裡介紹LVS,七層負載均衡介紹Nginx。
上圖是簡易的TCPIP協議棧層次圖,其中LVS工作在四層,即請求來到LVS這裡時是根據四層協議來決定請求最終走到哪個服務實體;而Nginx工作在七層,主要用於HTTP協議,即根據HTTP協議本身來決定請求的走向。需要說明的是,Nginx也可以工作在四層,但是這麼用的地方不是很多,可以參考nginx的stream模組。
做為四層負載均衡的LVS
(由於LVS有好幾種工作樣式,並不是每一種我都很清楚,以下表述僅針對Full NAT樣式,下麵的表述或者有誤)
LVS有如下的組成部分:
-
Direct Server(以下簡稱DS):前端暴露給客戶端進行負載均衡的伺服器。
-
Virtual Ip地址(以下簡稱VIP):DS暴露出去的IP地址,做為客戶端請求的地址。
-
Direct Ip地址(以下簡稱DIP):DS用於與Real Server互動的IP地址。
-
Real Server(以下簡稱RS):後端真正進行工作的伺服器,可以橫向擴充套件。
-
Real IP地址(以下簡稱RIP):RS的地址。
-
Client IP地址(以下簡稱CIP):Client的地址。
客戶端進行請求時,流程如下:
-
使用VIP地址訪問DS,此時的地址二元組為。
-
DS根據自己的負載均衡演演算法,選擇一個RS將請求轉發過去,在轉發過去的時候,修改請求的源IP地址為DIP地址,讓RS看上去認為是DS在訪問它,此時的地址二元組為。
-
RS處理並且應答該請求,這個回報的源地址為RS的RIP地址,目的地址為DIP地址,此時的地址二元組為。
-
DS在收到該應答包之後,將報文應答客戶端,此時修改應答報文的源地址為VIP地址,目的地址為CIP地址,此時的地址二元組為。
做為七層負載均衡的Nginx
在開始展開討論之前,需要簡單說一下正向代理和反向代理。
所謂的正向代理(proxy),我的理解就是在客戶端處的代理。如瀏覽器中的可以配置的訪問某些網站的代理,就屬於正向代理,但是一般而言不會說正向代理而是代理,即預設代理都是正向的。
而反向代理(reverse proxy)就是擋在伺服器端前面的代理,比如前面LVS中的DS伺服器就屬於一種反向代理。為什麼需要反向代理,大體的原因有以下的考量:
-
負載均衡:希望在這個反向代理的伺服器中,將請求均衡的分發到後面的伺服器中。
-
安全:不想向客戶端暴露太多的伺服器地址,統一接入到這個反向代理伺服器中,在這裡做限流、安全控制等。
-
由於統一接入了客戶端的請求,所以在反向代理的接入層可以做更多的控制策略,比如灰度流量釋出、權重控制等等。
反向代理與所謂的gateway、閘道器等,我認為沒有太多的差異,只是叫法不同而已,做的事情都是類似的。
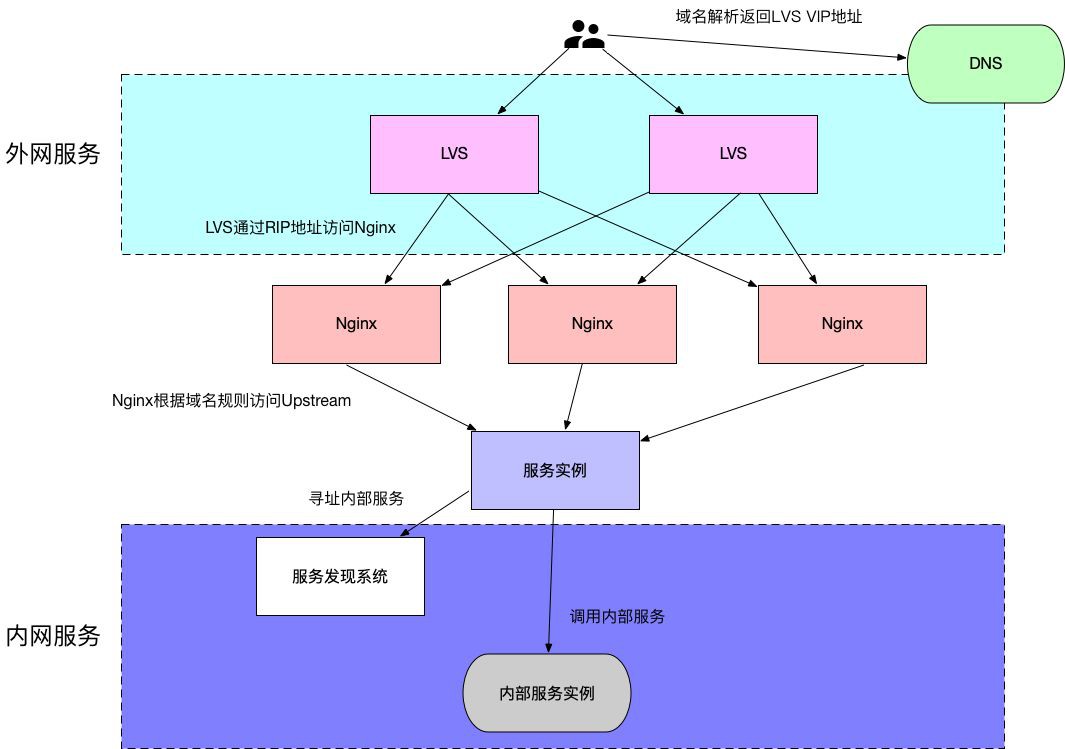
Nginx應該是現在用的最多的HTTP 七層負載均衡軟體,在Nginx中,可以透過在配置的server塊中定義一個域名,然後將該域名的請求系結到對應的Upstream中,而實現轉發請求到這些Upstream的效果。
如:
upstream hello {server A:11001;server B:11001;}location / {root html;index index.html index.htm;proxy_pass http://hello;}
這是最簡單的Nginx反向代理配置,實際線上一個接入層背後可能有多個域名,如果配置變動的很大,每次域名以及對應的Upstream的配置修改都需要人工幹預,效率會很慢。這時候就要提到一個叫DevOps的名詞了,我的理解就是開發各種便於自動化運維工具的工程師。
有了上面的分析,此時一個提供七層HTTP訪問介面的服務架構大體是這樣的:

服務發現與RPC
前面已經解決單機伺服器對外提供服務的大部分問題,來簡單回顧:
-
域名系統解決了需要記住複雜的數字IP地址的問題。
-
PB類軟體庫的出現解決協議定義解析的痛點。
-
閘道器類元件解決客戶端接入以及伺服器橫向擴充套件等一系列問題。
然而一個服務,通常並不見得只由本身提供服務就可以,服務過程中可能還涉及到查詢其他服務的流程,常見的如資料類服務如Mysql、Redis等,這一類供服務內呼叫查詢的服務被成為內部的服務,通常並不直接暴露到外網去。
面向公網的服務,一般都是以域名的形式提供給外部呼叫者,然而對於服務內部之間的互相呼叫,域名形式還不夠,其原因在於:
-
DNS服務發現的粒度太粗,只能到IP地址級別,而服務的埠還需要使用者自己維護。
-
對於服務的健康狀況的檢查,DNS的檢查還不夠,需要運維的參與。
-
DNS對於服務狀態的收集很欠缺,而服務狀態最終應該是反過來影響服務被呼叫情況的。
-
DNS的變更需要人工的參與,不夠智慧以及自動化。
綜上,內網間的服務呼叫,通常而言會自己實現一套“服務發現”類的系統,其包括以下幾個元件:
-
服務發現系統:用於提供服務的定址、註冊能力,以及對服務狀態進行統計彙總,根據服務情況更改服務的呼叫情況。比如,某個服務實體的響應慢了,此時分配給該實體的流量響應的就會少一些。而由於這個系統能提供服務的定址能力,所以一些定址策略就可以在這裡做,比如灰度某些特定的流量只能到某些特定的實體上,比如可以配置每個實體的流量權重等。
-
一套與該服務系統搭配使用的RPC庫,其提供以下功能:
-
服務提供方:使用RPC庫註冊自己的服務到服務發現系統,另外上報自己的服務情況。
-
服務呼叫方:使用RPC庫進行服務定址,實時從服務發現系統那邊獲取最新的服務排程策略。
-
提供協議的序列化、反序列化功能,負載均衡的呼叫策略、熔斷限流等安全訪問策略,這部分對於服務的提供方以及呼叫方都適用。
-

有了這套服務發現系統以及搭配使用的RPC庫之後,來看看現在的服務呼叫是什麼樣的。
-
寫業務邏輯的,再也不用關註服務地址、協議解析、服務排程、自身服務情況上報等等與業務邏輯本身並沒有太多關係的工作,專註於業務邏輯即可。
-
服務發現系統一般還有與之搭配的管理後臺介面,可以透過這裡對服務的策略進行修改檢視等操作。
-
對應的還會有服務監控系統,對應的這是一臺實時採集服務資料進行計算的系統,有了這套系統服務質量如何一目瞭然。
-
服務健康狀態的檢查完全自動化,在狀況不好的時候對服務進行降級處理,人工幹預變少,更加智慧以及自動化。
現在服務的架構又演進成了這樣:
ServiceMesh
架構發展到上面的程度,實際上已經能夠解決大部分的問題了。這兩年又出現了一個很火的概念:ServiceMesh,中文翻譯為“服務網格”,來看看它又能解決什麼問題。
前面的服務發現系統中,需要一個與之配套的RPC庫,然而這又會有如下的問題:
-
如果需要支援多語言,該怎麼做?每個語言實現一個對應的RPC庫嗎?
-
庫的升級很麻煩,比如RPC庫本身出了安全漏洞,比如需要升級版本,一般推動業務方去做這個升級是很難的,尤其是系統做大了之後。
可以看到,由於RPC庫是嵌入到行程之中的元件,所以以上問題很麻煩,於是就想出了一個辦法:將原先的一個行程拆分成兩個行程,如下圖所示。
在服務mesh化之前,服務呼叫方實體透過自己內部的RPC庫來與服務提供方實體進行通訊。
在服務mesh化之後,會與服務呼叫方同機部署一個local Proxy也就是ServiceMesh的proxy,此時服務呼叫的流量會先走到這個proxy,再由它完成原先RPC庫響應的工作。至於如何實現這個流量的劫持,答案是採用iptables,將特定埠的流量轉發到proxy上面即可。
有了這一層的分拆,將業務服務與負責RPC庫作用的Proxy分開來,上面的兩個痛點問題就變成了對每臺物理機上面的mesh proxy的升級維護問題,多語言也不是問題了,因為都是透過網路呼叫完成的RPC通訊,而不是行程內使用RPC庫。
然而這個方案並不是什麼問題都沒有的,最大的問題在於,多了這一層的呼叫之後,勢必有影響原來的響應時間。
截止目前(2019.6月),ServiceMesh仍然還是一個概念大於實際的產品。
從上面的演進歷史可以看到,所謂的“中間層理論”,即“Any problem in computer science can be solved by another layer of indirection(電腦科學領域的任何問題都可以透過增加一個間接的中間層來解決)”在這個過程中被廣泛使用,比如為瞭解決IP地址難於記憶的問題,引入了域名系統,比如為瞭解決負載均衡問題引入了閘道器,等等。然而每引入一個中間層,勢必帶來另外的影響,比如ServiceMesh多一次到Proxy的呼叫,如何權衡又是另外的問題了。
另外,回到最開始的服務三要素中,可以看到整個演化的歷史也是逐漸遮蔽了下層元件的流程,比如:
-
域名的出現遮蔽了IP地址。
-
服務發現系統遮蔽協議及埠號。
-
PB類序列化庫遮蔽了使用者自己對協議的解析。
可以看到,演進流程讓業務開發者更加專註在業務邏輯上,這類的演進流程不只發生在今天,也不會僅僅發生在今天,未來類似的演進也將再次發生。
朋友會在“發現-看一看”看到你“在看”的內容