阿裡資深技術專家大沙,將為大家詳細介紹本次開源的 Blink 主要功能和最佳化點,希望與業界同仁共同攜手,推動 Flink 社群進一步發展。
Blink on GitHub
------
https://github.com/apache/flink/tree/blink
Blink 簡介
Apache Flink 是德國柏林工業大學的幾個博士生和研究生從學校開始做起來的專案,早期叫做 Stratosphere。2014 年,StratoSphere 專案中的核心成員從學校出來開發了 Flink,同時將 Flink 計算的主流方向定位為流計算,併在同年將 Flink 捐贈 Apache 基金會,後來快速孵化成為 Apache 基金會的頂級專案。現在 Flink 是業界公認的最好的大資料流計算引擎。

阿裡巴巴在 2015 年開始嘗試使用 Flink。但是阿裡的業務體量非常龐大,挑戰也很多。彼時的 Flink 不管是規模還是穩定性尚未經歷實踐,成熟度有待商榷。為了把這麼大的業務體量支援好,我們不得不在 Flink 之上做了一系列的改進,所以阿裡巴巴維護了一個內部版本的 Flink,它的名字叫做 Blink。
基於 Blink 的計算平臺於 2016 年正式上線。截至目前,阿裡絕大多數的技術部門都在使用 Blink。Blink 一直在阿裡內部錯綜複雜的業務場景中鍛煉成長著。對於內部使用者反饋的各種效能、資源使用率、易用性等諸多方面的問題,Blink 都做了針對性的改進。雖然現在 Blink 在阿裡內部用的最多的場景主要還是在流計算,但是在批計算場景也有不少業務上線使用了。例如,在搜尋和推薦的演演算法業務平臺中,它使用 Blink 同時進行流計算和批處理。Blink 被用來實現了流批一體化的樣本生成和特徵抽取這些流程,能夠處理的特徵數達到了數千億,而且每秒鐘處理數億條訊息。在這個場景的批處理中,我們單個作業處理的資料量已經超過 400T,並且為了節省資源,我們的批處理作業是和流計算作業以及搜尋的線上引擎執行在同樣的機器上。所以大家可以看到流批一體化已經在阿裡巴巴取得了極大的成功,我們希望這種成功和阿裡巴巴內部的經驗都能夠帶回給社群。
Blink 開源的背景
其實從我們選擇 Flink 的第一天開始我們就一直和社群緊密合作。過去的這幾年我們也一直在把阿裡對 Flink 的改進推回社群。從 2016 年開始我們已經將流計算 SQL 的大部分功能,針對 runtime 的穩定性和效能最佳化做的若干重要設計都推回了社群。但是 Blink 本身發展迭代的速度非常快,而社群有自己的步伐,很多時候可能無法把我們的變更及時推回去。對於社群來說,一些大的功能和重構,需要達成共識後,才能被接受,這樣才能更好地保證開源專案的質量,但是同時就會導致推入的速度變得相對較慢。經過這幾年的開發迭代,我們這邊和社群之間的差距已經變得比較大了。
Blink 有一些很好的新功能,比如效能優越的批處理功能,在社群的版本是沒有的。在過去這段時間裡,我們不斷聽到有人在詢問 Blink 的各種新功能。期望 Blink 儘快開源的呼聲越來越大。我們一直在思考如何開源的問題,一種方案就是和以前一樣,繼續把各種功能和最佳化分解,逐個和社群討論,慢慢地推回 Flink。但這顯然不是大家所期待的。另一個方案,就是先完整的盡可能的多的把程式碼開源,讓社群的開發者能夠儘快試用起來。第二個方案很快收到社群廣大使用者的支援。因此,從 2018 年中開始我們就開始做開源的相關準備。經過半年的努力,我們終於把大部分 Blink 的功能梳理好,開源了出來。
Blink 開源的方式
我們把程式碼貢獻出來,是為了讓大家能先嘗試一些他們感興趣的功能。Blink 永遠不會單獨成為一個獨立的開源專案來運作,他一定是 Flink 的一部分。開源後我們期望能找到辦法以最快的方式將 Blink 合併到 Flink 中去。Blink 開源只有一個目的,就是希望 Flink 做得更好。Apache Flink 是一個社群專案,Blink 以什麼樣的形式進入 Flink 是最合適的,怎麼貢獻是社群最希望的方式,我們都要和社群一起討論。
在過去的一段時間內,我們在 Flink 社群徵求了廣泛的意見,大家一致認為將本次開源的 Blink 程式碼作為 Flink 的一個分支直接推回到 Apache Flink 專案中是最合適的方式。並且我們和社群也一起討論規劃出一套能夠快速合併 Blink 到 Flink 主幹中的方案(具體細節可以檢視 Flink 社群正在討論的 FLIP32)。我們期望這個合併能夠在很短的時間內完成。這樣我們之後的機器學習等其他新功能就可以直接推回到 Flink 主幹。相信用不了多久,Flink 和 Blink 就完全合二為一了。在那之後,阿裡巴巴將直接使用 Flink 用於生產,並同時協助社群一起來維護 Flink。
本次開源的 Blink 的主要功能和最佳化點
本次開源的 Blink 程式碼在 Flink 1.5.1 版本之上,加入了大量的新功能,以及在效能和穩定性上的各種最佳化。主要貢獻包括,阿裡巴巴在流計算上積累的一些新功能和效能的最佳化,一套完整的(能夠跑通全部 TPC-H/TPC-DS,能夠讀取 Hive 元資料和資料)高效能 Batch SQL,以及一些以提升易用性為主的功能(包括支援更高效的互動式程式設計,與 zeppelin 更緊密的結合, 以及體驗和效能更佳的 Flink web)。未來我們還將繼續給 Flink 貢獻在 AI、IoT 以及其他新領域的功能和最佳化。更多的關於這一版本 Blink 的細節,請參考 Blink 程式碼根目錄下的 README.md 檔案。下麵,我來分模組介紹下 Blink 主要的新的功能和最佳化點。
Runtime
為了更好的支援批處理,以及解決阿裡巴巴大規模生產場景中遇到的各種挑戰,Blink 對 Runtime 的架構、效率、穩定性方面都做了大量改進。在架構方面,首先 Blink 引入了可插拔 Shuffle 架構,開發者可以根據不同的計算模型或者新硬體的需要實現不同的 Shuffle 策略進行適配。此外 Blink 還引入新的排程架構,容許開發者根據計算模型自身的特點定製不同排程器。為了最佳化效能,Blink 可以讓運算元更加靈活的鏈在一起,避免了不必要的資料傳輸開銷。在 Pipeline Shuffle 樣式中,使用了 ZeroCopy 減少了網路層記憶體消耗。在 BroadCast Shuffle 樣式中,Blink 最佳化掉了大量的不必要的序列化和反序列化開銷。
此外,Blink 提供了全新的 JM FailOver 機制,JM 發生錯誤之後,新的 JM 會重新接管整個任務而不是重啟任務,從而大大減少了 JM FailOver 對任務的影響。最後,Blink 也開發了對 Kubernetes 的支援。不同於 Standalone 樣式在 Kubernetes 上的拉起方式,在基於 Flink FLIP6 的架構上基礎之上,Blink 根據任務的資源需求動態的申請/釋放 Pod 來執行 TaskExecutor,實現了資源彈性,提升了資源的利用率。
SQL/TableAPI
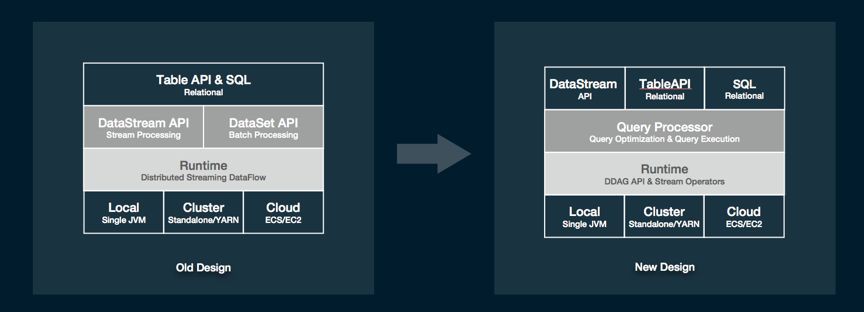
SQL/TableAPI 架構上的重構和效能的最佳化是 Blink 本次開源版本的一個重大貢獻。首先,我們對 SQL 引擎的架構做了較大的調整。提出了全新的 Query Processor(QP), 它包括了一個最佳化層(Query Optimizer)和一個運算元層(Query Executor)。這樣一來,流計算和批計算的在這兩層大部分的設計工作就能做到盡可能的復用。
另外,SQL 和 TableAPI 的程式最終執行的時候將不會翻譯到 DataStream 和 DataSet 這兩個 API 上,而是直接構建到可執行的 DAG 上來,這樣就使得物理執行運算元的設計不完全依賴底層的 API,有了更大的靈活度,同時執行程式碼也能夠被靈活的CodeGen 出來。唯一的一個影響就是這個版本的 SQL 和 TableAPI 不能和 DataSet 這個 API 進行互相轉換,但仍然保留了和 DataStream API 互相轉換的能力(將 DataStream 註冊成表,或將 Table 轉成 DataStream 後繼續操作)。未來,我們計劃把 Dataset 的功能慢慢都在 DataStream 和 TableAPI 上面實現。到那時 DataStream 和 SQL 以及 TableAPI 一樣,是一個可以同時描述 bounded/unbounded processing 的 API。
除了架構上的重構,Blink 還在具體實現上做了較多比較大的重構。首先,Blink 引入了二進位制的資料結構 BinaryRow,極大的減少了資料儲存上的開銷以及資料在序列化和反序列化上計算的開銷。其次,在運算元的實現層面,Blink 在更廣範圍內引入了 CodeGen 技術。由於預先知道運算元需要處理的資料的型別,在 QP 層內部就可以直接生成更有針對性更高效的執行程式碼。
Blink 的運算元會動態的申請和使用資源,能夠更好的利用資源,提升效率,更加重要的是這些運算元對資源有著比較好的控制,不會發生 OutOfMemory 的問題。此外,針對流計算場景,Blink 加入了 miniBatch 的執行樣式,在 aggregate、join 等需要和 state 頻繁互動且往往又能先做部分 reduce 的場景中,使用 miniBatch 能夠極大的減少 I/O,從而成數量級的提升效能。除了上面提到的這些重要的重構和功能點,Blink 還實現了完整的 SQL DDL,帶 emit 策略的流計算 DML,若干重要的 SQL 功能,以及大量的效能最佳化策略。
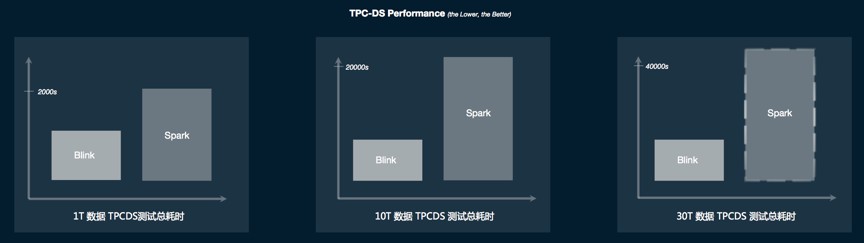
有了上面提到的諸多架構和實現上的重構。Blink 的 SQL/TableAPI 在功能和效能方面都取得了脫胎換骨的變化。在批計算方面,首先 Blink batch SQL 能夠完整的跑通 TPC-H 和 TPC-DS,且效能上有著極大的提升。如上圖所示,是這次開源的 Blink 版本和 Spark 2.3.1 的 TPC-DS 的基準效能對比。柱狀圖的高度代表了執行的總時間,高度越低說明效能越好。可以看出, Blink 在 TPC-DS 上和 Spark 相比有著非常明顯的效能優勢。而且這種效能優勢隨著資料量的增加而變得越來越大。在實際的場景這種優勢已經超過 Spark 的三倍。在流計算效能上我們也取得了類似的提升。我們線上的很多典型作業,它的效能是原來的 3 到 5 倍。在有資料傾斜的場景,以及若干比較有挑戰的 TPC-H Query,流計算效能甚至得到了數十倍的提升。
除了標準的關係型 SQL API。TableAPI 在功能上是 SQL 的超集,因此在 SQL 上所有新加的功能,我們在 TableAPI 也添加了相對應的 API。除此之外,我們還在 TableAPI 上引入了一些新的功能。其中一個比較重要是快取功能。在批計算場景下,使用者可以根據需要來快取計算的中間結果,從而避免不必要的重覆計算。它極大的增強了互動式程式設計體驗。我們後續會在 TableAPI 上新增更多有用的功能。其實很多新功能已經在社群展開討論並被社群接受,例如我們在 TableAPI 增加了對一整行操作的運算元:map、flatMap、aggregate、flatAggregate(Flink FLIP29)等等。
Hive 的相容性
我們這次開源的版本實現了在元資料和資料層將 Flink 和 Hive 對接和打通。國內外很多公司都還在用 Hive 在做自己的批處理。對於這些使用者,現在使用這次 Blink 開源的版本,就可以直接用 Flink SQL 去查詢 Hive 的資料,真正能夠做到在 Hive 引擎和 Flink 引擎之間的自由切換。
為了打通元資料,我們重構了 Flink catalog 的實現,並且增加了兩種 catalog,一個是基於記憶體儲存的 FlinkInMemoryCatalog,另外一個是能夠橋接 Hive metaStore 的 HiveCatalog。有了這個 HiveCatalog,Flink 作業就能讀取 Hive 的 metaData。為了打通資料,我們實現了 HiveTableSource,使得 Flink 任務可以直接讀取 Hive 中普通表和分割槽表的資料。因此,透過這個版本,使用者可以使用 Flink SQL 讀取已有的 Hive 元資料和資料,做資料處理。未來我們將在 Flink 上繼續加大對 Hive 相容性的支援,包括支援 Hive 特有的請求、資料型別和 Hive UDF 等等。
Zeppelin for Flink
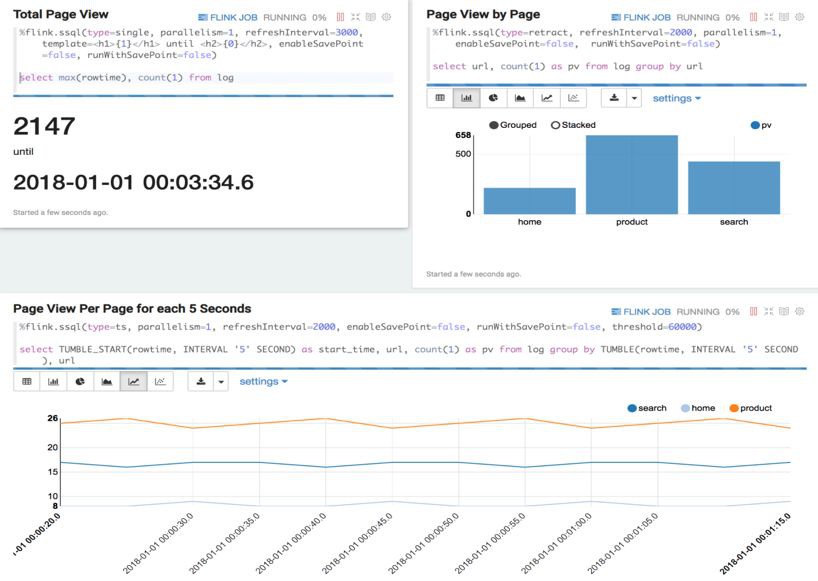
為了提供更好的視覺化和互動式體驗,我們做了大量的工作讓 Zeppelin 能夠更好的支援 Flink。這些改動有些是在 Flink 上的,有些是在 Zeppelin 上的。在這些改動全部推回 Flink 和 Zeppelin 社群之前,大家可以使用這個 Zeppelin 映象(具體細節請參考 Blink 程式碼裡的 docs/quickstart/zeppelin_quickstart.md)來測試和使用這些功能。這個用於測試的 Zeppelin版本,首先很好的融合和集成了 Flink 的多種執行樣式以及運維介面。使用文字 SQL 和 TableAPI 可以自如的查詢 Flink 的靜態表和動態表。
此外,針對 Flink 的流計算的特點,這一版 Zeppelin 也很好的支援了 savepoint,使用者可以在介面上暫停作業,然後再從 savepoint 恢復繼續執行作業。在資料展示方面,除了傳統的資料分析介面,我們也添加了流計算的翻牌器和時間序列展示等等功能。為了方便使用者試用,我們在這一版 Zeppelin 中提供 3 個內建的 Flink 教程例子: 一個是做 StreamingETL 的例子,另外兩個分別是做 Flink Batch、Flink Stream 的基礎樣例。
Flink Web
我們對 Flink Web 的易用性與效能等多個方面做了大量的改進,從資源使用、作業調優、日誌查詢等維度新增了大量功能,使得使用者可以更方便的對 Flink 作業進行運維。在資源使用方面,新增了 Cluster、TaskManager 與任務三個級別的資源資訊,使得資源的申請與使用情況一目瞭然。作業的拓撲關係及資料流向可以追溯至 Operator 級別,Vertex 增加了 InQueue、OutQueue 等多項指標,可以方便的追蹤資料的反壓、過濾及傾斜情況。TaskManager 和 JobManager 的日誌功能得到大幅度加強,從 Job、Vertex、SubTask 等多個維度都可以關聯至對應日誌,提供多日誌檔案訪問入口,以及分頁展示查詢和日誌高亮功能。
另外,我們使用了較新的 Angular 7.0 對 Flink web 進行了全面重構,頁面執行效能有了一倍以上的提升。在大資料量情況下也不會發生頁面卡死或者卡頓情況。同時對頁面的互動邏輯進行了整體最佳化,絕大部分關聯資訊在單個頁面就可以完成查詢和比對工作,減少了大量不必要的跳轉。
未來的規劃
Blink 邁出了全面開源的第一步,接下來我們會和社群合作,盡可能以最快的方式將 Blink 的功能和效能上的優化合併回 Flink。本次的開源版本一方面貢獻了 Blink 多年在流計算的積累,另一方面又重磅推出了在批處理上的成果。接下來,我們會持續給 Flink 社群貢獻其他方面的功能。我們期望每過幾個月就能看到技術上有一個比較大的亮點貢獻到社群。下一個亮點應該是對機器學習的支援。要把機器學習支援好,有一系列的工作要做,包括引擎的功能,效能,和易用性。這裡面大部分的工作我們已經開發完成,並且很多功能都已經在阿裡巴巴內部服務上線了。
除了技術上創新以及新功能之外,Flink 的易用性和外圍生態也非常重要。我們已經啟動了若干這方面的專案,包括 Python 以及 Go 等多語言支援,Flink 叢集管理,Notebook,以及機器學習平臺等等。這些專案有些會成為 Flink 自身的一部分貢獻回社群,有些不是。但它們都基於 Flink,是 Flink 生態的一個很好的補充。獨立於 Flink 之外的那些專案,我們都也在認真的考慮開源出來。總之,Blink 在開源的第一天起,就已經完全的融入了 Flink 社群,我們希望所有的開發者看到我們的誠意和決心。
未來,無論是功能還是生態,我們都會在 Flink 社群加大投入,我們也將投入力量做 Flink 社群的運營,讓 Flink 真正在中國、乃至全世界大規模地使用起來。我們衷心的希望更多的人加入,一起把 Apache Flink 開源社群做得更好!
