
-
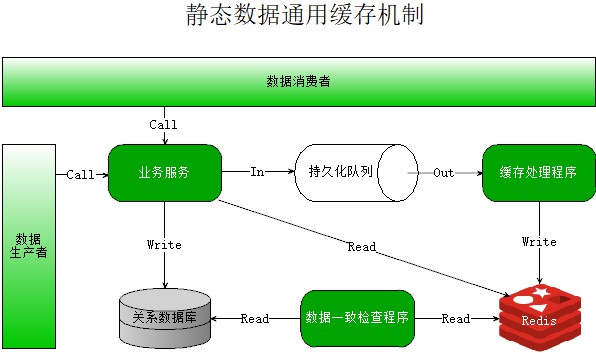
業務服務:提供對某種業務資料的操作介面,比如車輛服務,提供對車輛基本資訊的增刪改查服務。
-
關係資料庫:使用若干表持久化業務資料,比如SQLServer、MySQL、Oracle等。
-
持久化佇列:可獨立部署的佇列程式,支援資料持久化,比如RabbitMQ、RocketMQ、Kafka等。
-
快取處理程式:從佇列接收資料,然後寫入快取。
-
資料一致處理程式:負責檢查快取資料庫和關係型資料庫中資料是否一致,如果不一致則使用關係資料庫進行更新。
-
快取資料庫(Redis):支援持久化的快取資料庫,這裡直接選了Redis,這個基本是業界標準了。
-
資料生產者:業務靜態資料的來源,可以理解為前端APP、Web系統的某個功能或者模組。
-
資料消費者:需要使用這些業務靜態資料的服務或者系統,比如報警系統需要獲取車輛對應的使用者資訊以便傳送報警。
-
快取資料的大小:行程可以快取資料的大小受限於系統可用記憶體,同時如果機器上部署了多個服務,某個服務使用了太多的記憶體,則可能會影響其它服務的正常訪問,因此不適合大量資料的快取。
-
快取雪崩:快取同時大量過期或者行程重啟的情況下,可能產生大量的快取穿透,過多的請求打到關係資料庫上,可能導致關係資料庫的崩潰,引發更大的不可用問題。
-
獨立部署,不影響其它業務,還可以做叢集,記憶體擴容比較方便。
-
支援資料持久化,即使Redis重啟了,快取的資料自身就可以很快恢復。
-
透過業務服務來包裝對資料的操作,不管是操作關係資料庫還是快取資料庫,資料消費者其實不需要關心,它只關心業務服務能不能提供高併發實時資料的查詢能力。
-
利用分散式系統中經常使用佇列進行解耦的方式,業務服務不乾寫入快取的事,增加一個佇列訂閱資料變更,然後從佇列取資料寫入快取資料庫。
-
對於絕大部分正常的情況,透過佇列更新快取資料和業務服務中更新快取資料,其實時性是差不多的,同時實現了業務操作和寫快取的解耦。
-
在極端崩潰導致資料不一致的情況下,透過資料一致檢查程式進行補救,儘快更新快取資料。
-
現在業務服務可以透過訪問Redis快取來提供對靜態資料的高併發準實時查詢能力,快取中不存在的資料就是不存在,沒有快取穿透。
