(點選上方公眾號,可快速關註)
來源:liuinsect ,
www.liuinsect.com/2016/05/14/edm-performance/
寫在之前的話,最近一年多來幾乎沒更新部落格,更多的原因是自知資歷尚潛,要學習的東西太多,要接觸的東西也太多,沒有足夠的精力投入到部落格上,或許有一天時機成熟會再提高更新頻率吧,但有一點不會變的是,學習的路上數十年如一日,我會一直堅持,爭取有更多的機會可以走出來,但前提是我有了足夠的深度和廣度。
謝謝大家的支援。
從今年一月份開始,我們團隊陸續完成了郵件服務的架構升級。新平臺上線執行的過程中也發生了一系列的效能問題,即使很多看起來來微不足道的點也會讓整個系統執行得不是那麼平穩,今天就將這段時間的問題以及解決方案統一整理下,希望能起到拋磚的作用,讓讀者在遇到類似問題的時候能多一個解決方案。
新平臺上線後第一版架構如下:

整個平臺的資料流程是:
資料透過MQ訊息和遠端服務呼叫進入新平臺;
透過生產平臺生成郵件傳送任務資料,同步Push進Redis佇列中;
傳送平臺輪詢Redis佇列並Pull訊息到本地,然後連線郵件服務商伺服器進行郵件傳送,傳送完畢後將結果更新回資料庫;
有一個全域性的Checker掃表,將待傳送的郵件任務投遞到Redis佇列中(包括傳送失敗,需要重試的任務)。
這版架構上線後,我們遇到的第一個問題:資料庫讀寫壓力過大後影響整體服務穩定。
表現為:
-
資料庫主庫壓力高,同時伴有大量的讀,寫操作。
-
遠端服務介面效能不穩定,業務繁忙時資料庫的插入操作延遲升高,介面響應變慢,介面監控頻繁報警,影響業務方。
經過分析後,我們做瞭如下最佳化:
-
資料庫做讀寫分離,將Checker的掃表操作放到從庫上去(主從庫中的同步延遲不影響我們傳送,這次掃描不到的下次掃表到即可,因為每條郵件任務上有版本號控制,所以也不擔心會掃描到“舊記錄”的問題)。
-
將Push到Redis的操作變成批次+非同步的方式,減少介面同步執行邏輯中的操作,主庫只做最簡單的單條資料的Insert和Update,提高資料庫的吞吐量,儘量避免因為大量的讀庫請求引起資料庫的效能波動。
這麼做還有一個原因是經過測試,對於Redis的lpush命令來說每次Push1K大小的元素和每次Push20K的元素耗時沒有明顯增加。
因此,我們使用了EventDrieven模型將Push操作改成了定時+批次+非同步的方式往Redis Push郵件任務,這版最佳化上線後資料庫主庫CPU利用率基本在5%以下。
總結:這次最佳化的經驗可以總結為:用非同步縮短住業務流程 +用批次提高執行效率+資料庫讀寫分離分散讀寫壓力。
最佳化後的架構圖:

最佳化上線後,我們又遇到了第二個問題:JVM假死。
表現為:
-
單位時間內JVM Full GC次數明顯升高,GC後記憶體居高不下,每次GC能回收的記憶體非常有限。
-
介面效能下降,處理延遲升高到幾十秒。
-
應用基本不處理業務。
-
JVM行程還在,能響應jmap,jstack等命令。
-
jstack命令看到絕大多數執行緒處於block狀態。
堆資訊大致如下(註意紅色標註的點):


如上兩圖,可以看到RecommendGoodsService 類佔用了60%以上的記憶體空間,持有了34W個 “郵件任務物件”,非常可疑。
分析後發現製造平臺在生成“郵件任務物件”後使用了非同步佇列的方式處理物件中的推薦商品業務,因為某個低階的BUG導致處理佇列的執行緒數只有5個,遠低於預期數量, 因此佇列長度劇增導致的堆記憶體不夠用,觸發JVM的頻繁GC,導致整個JVM大量時間停留在”stop the world ” 狀態,JVM響應變得非常慢,最終表現為JVM假死,介面處理延遲劇增。
總結:
-
我們要儘量讓程式碼對GC友好,絕大部分時候讓GC執行緒“短,平,快”的執行並減少Full GC的觸發機率。
-
我們線上的容器都是多實體部署的,部署前通常也會考慮吞吐量問題,所以JVM直接掛掉一兩臺並不可怕,對於業務的影響也有限,但JVM的假死則是非常影響系統穩定性的,與其奈活,不如快死!
相信很多團隊在使用執行緒池非同步處理的時候都是使用的無界佇列存放Runnable任務的,此時一定要非常小心,無界意味著一旦生產執行緒快於消費執行緒,佇列將快速變長,這會帶來兩個非常不好的問題:
-
從執行緒池到無界佇列到無界佇列中的元素全是強取用,GC無法釋放。
-
佇列中的元素因為等不到消費執行緒處理,會在Young GC幾次後被移到年老代,年老代的回收則是靠Full GC才能回收,回收成本非常高。
經過一段時間的執行,我們將JVM記憶體從2G調到了3G,於是我們又遇到了第三個問題:記憶體變大的煩惱
JVM記憶體調大後,我們的JVM的GC次數減少了非常多,執行一段時間後加上了很多新功能,為了提高處理效率和減少業務之間的耦合,我們做了很多非同步化的處理。更多的非同步化意味著更多的執行緒和佇列,如上述經驗,很多元素被移到了年老代去,記憶體越用越小,如果正好在業務量不是特別大時,整個堆會呈現一個“穩步上升”的態勢,下一步就是記憶體閥值的持續報警了。

所以,無界佇列的使用是需要非常小心的。
我們把郵件服務分為生產郵件和促銷郵件兩部分,程式碼90%是復用的,但獨立部署,獨立的資料庫,促銷郵件上線後,我們又遇到了老問題:資料庫主庫壓力再次CPU100%
在經過生產郵件3個月的執行及最佳化後,我們對程式碼做了少許的改動用於支援促銷郵件的傳送,促銷的業務可以概括為:瞬間大量資料寫入,Checker每次需要掃描上百萬的資料,整個系統需要在大量待傳送資料中維持一個較穩定的傳送速率。上線後,資料庫又再次報出異常:
-
主庫的寫有大量的死鎖異常(原來的生產郵件就有,不過再促銷郵件的業務形態中影響更明顯)。
-
從庫有大量的全表掃描,讀壓力非常高。
死鎖的問題,原因是這樣的:
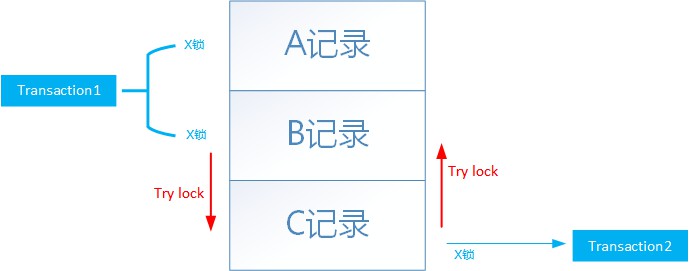
條件1.如果有Transaction1需要對ABC記錄加鎖,已經對A,B記錄加了X鎖,此刻在嘗試對C記錄枷鎖。
條件2.如果此前Transaction2已經對C記錄加了獨佔鎖,此刻需要對B記錄加X鎖。
就會產生dead lock。實際情況是:如果兩條update陳述句同一時刻既需要掃描ABC又需要掃描DCB,那麼死鎖就出現了。
儘管Mysql做了最佳化,比如增加超時時間:innodb_lock_wait_timeout,超時後會自動釋放,釋放的結果是Transaction1和Transaction2全部Rollback(死鎖問題並沒有解決,如果不幸,下次執行還會重現)。再如果每個Transaction都是update數萬,數十萬的記錄(我們的業務就是),那事務的回滾代價就非常高了。
解決辦法很多,比如先select出來再做逐條做update,或者update加上一個limit限制每次的更新次數,同時避免兩個Transaction併發執行等等。我們選擇了第一種,因為我們的業務對於時間上要求並不高,可以“慢慢做”。
全表掃表的問題發生在Checker上,我們封裝了很多操作郵件任務的邏輯在不同的Checker中,比如:過期Checker,重置Checker,Redis Push Checker等等。他們負責將郵件任務更新為業務需要的各種狀態,大部分時候他們是並行執行的,會產生很多select請求。嚴重時,讀庫壓力基本維持在95%上長達數小時。
全表掃描99%的原因是因為select沒有使用索引,所以往往開發同學的第一反應是加索引,然後讓資料庫“死扛”讀壓力 ,但索引是有成本的,佔用硬碟空間不說,insert/delete操作都需要維護索引,
其實我們還有另外好幾種方案可以選擇,比如:是不是需要這麼頻繁的執行select? 是不是每次都要select這麼多資料?是不是需要同一時間併發執行?
我們的解決辦法是:合理利用索引+降低掃描頻率+掃描適量記錄。
首先,將Checker裡的SQL統一化,每個Checker產生的SQL只有條件不同,使用的欄位基本一樣,這樣可以很好的使用索引。
其次,我們發現傳送端的消費能力是整個郵件傳送流程的制約點,消費能力決定了某個時間內需要多少郵件傳送任務,Checker掃描的量只要剛剛夠傳送端滿負荷傳送就可以了,因此,Checker不再每個幾分鐘掃表一次,只在佇列長度低於某個下限值時才掃描,
並且一次掃描到佇列的上限值,多一個都不掃。
經過以上最佳化後,促銷的庫也沒有再報警了。
直到兩周以前,我們又遇到了一個新問題:傳送節點CPU100%.
這個問題的表象為:CPU正常執行業務時保持在80%以上,高峰時超過95%數小時。監控圖示如下:

在說這個問題前,先看下傳送節點的執行緒模型:
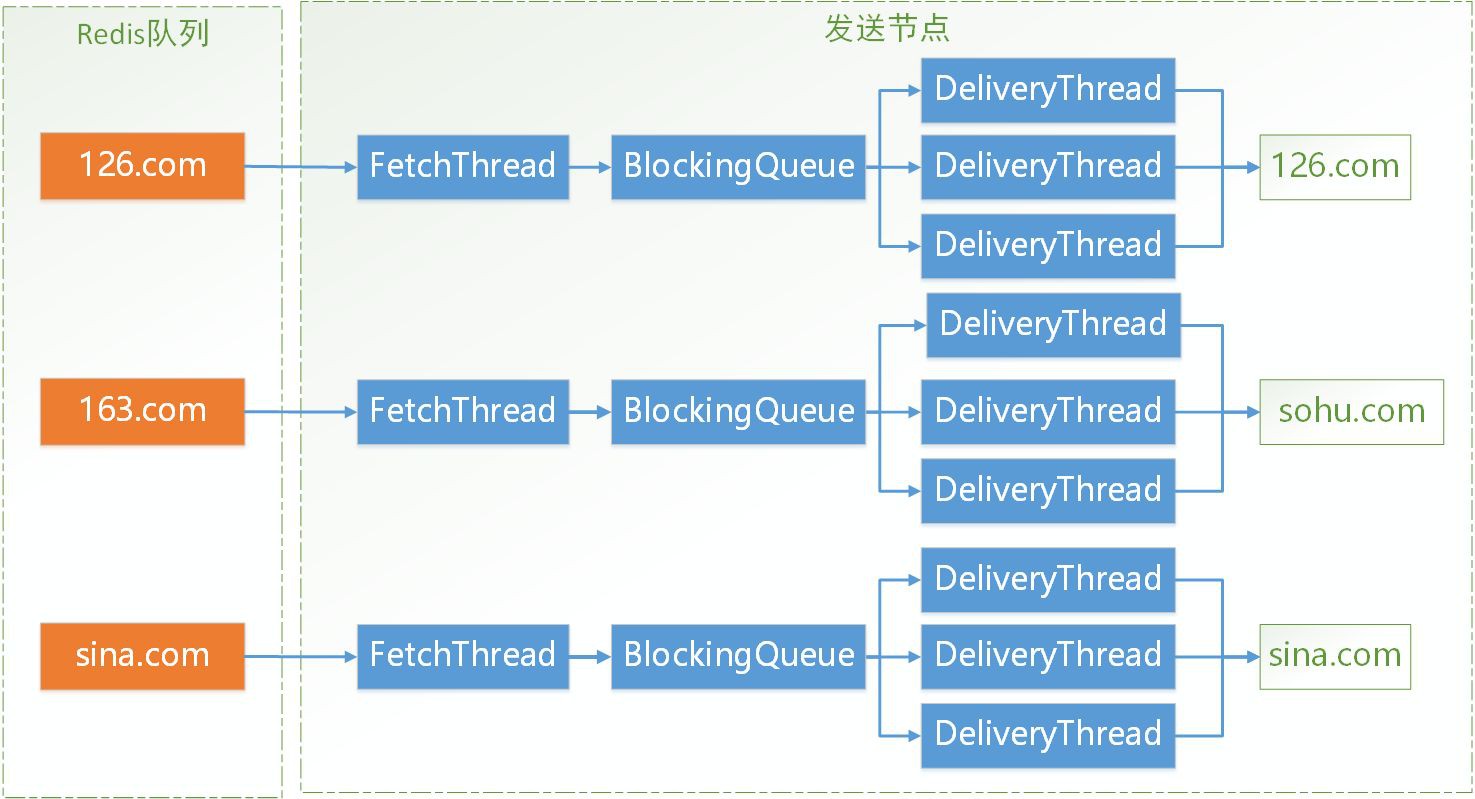
Redis中根據標的郵箱的域名有一到多個Redis佇列,每個傳送節點有一個跟標的郵箱相對應的FetchThread用於從Redis Pull郵件傳送任務到傳送節點本地,然後透過一個BlockingQueue將任務傳遞給DeliveryThread,DeliveryThread連線具體郵件服務商的伺服器傳送郵件。考慮到每次連線郵件服務商的伺服器是一個相對耗時的過程,因此同一個域名的DeliveryThread有多個,是多執行緒併發執行的。
既然表象是CPU100%,根據這個執行緒模型,第一步懷疑是不是執行緒數太多,同一時間併發導致的。檢視配置後發現執行緒數只有幾百個,同時一時間執行的只有十多個,是相對合理的,不應該是引起CPU100%的根因。
但是在檢查程式碼時發現有這麼一個業務場景:
-
由於JIMDB的封裝,傳送平臺採用的是輪詢的方式從Redis佇列中Pull郵件傳送任務,Redis佇列為空時FetchThread會sleep一段時間,然後再檢查。
-
從業務上說網易+騰訊的郵件佔到了整個郵件總量的70%以上,對非前者的FetchThread來說,Pull不到機率非常高。
那就意味著傳送節點上的很多FetchThread執行的是不必要的喚醒->檢查->sleep的流程,白白的浪費CPU資源。
於是我們利用事件驅動的思想將模型稍稍改變一下:

每次FetchThread對應的Redis佇列為空時,將該執行緒阻塞到Checker上,由Checker統一對多個Redis佇列的Pull條件做判斷,符合Pull條件後再喚醒FetchThread。
Pull條件為:
1.FetchThread的本地佇列長度小於初始長度的一半。
2.Redis佇列不為空。
同時滿足以上兩個條件,視為可以喚醒對應的FetchThread。
以上的改造本質上還是在降低執行緒背景關係切換的次數,將簡單工作歸一化,並將多路併發改為阻塞+事件驅動和降低拉取頻率,進一步減少執行緒佔用CPU的時間片的機會。
上線後,傳送節點的CPU佔用率有了20%左右的下降,但是並沒有直接將CPU的利用率最佳化為非常理想的情況(20%以下),我們懷疑並沒有找到真正的原因。

於是我們接著對郵件傳送流程做了進一步的梳理,發現了一個非常奇怪的地方,程式碼如下:

我們在傳送節點上使用了Handlebars做郵件內容的渲染,在初始化時使用了Concurrent相關的Map做模板的快取,但是每次渲染前卻要重新new一個HandlebarUtil,那每個HandlebarUtil豈不是用的都是不同的TemplateCache物件?既然如此,為什麼要用Concurrent(意味著執行緒安全)的Map?
進一步閱讀原始碼後發現無論是Velocity還是Handlebars在渲染先都需要對模板做語法解析,構建抽象語法樹(AST),直至生成Template物件。構建的整個過程是相對消耗計算資源的,因此猜想Velocity或者Handlebars會對Template做快取,只對同一個模板解析一次。
為了驗證猜想,可以把渲染的過程單獨執行下:

可以看到Handlebars的確可以對Template做了快取,並且每次渲染前會優先去快取中查詢Template。而除了同樣執行5次,耗時開銷特別大以外,CPU的開銷也同樣特別大,上圖為使用了快取CPU利用率,下圖為沒有使用到快取的CPU利用率:

找到了原因,修改就比較簡單了保證handlebars物件是單例的,能夠儘量使用快取即可。
上線後結果如下:


至此,整個效能最佳化工作已經基本完成了,從每個案例的最佳化方案來看,有以下幾點經驗想和大家分享:
-
效能最佳化首先應該定位到真正原因,從原因下手去想方案。
-
方案應該貼合業務本身,從客觀規律、業務規則的角度去分析問題往往更容易找到突破點。
-
一個細小的問題在業務量巨大的時候甚至可能壓垮服務的根因,開發過程中要註意每個細節點的處理。
-
平時多積累相關工具的使用經驗,遇到問題時能結合多個工具定位問題。
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

