作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
高舉“讓 Keras 更酷一些!”大旗,讓 Keras 無限可能。
今天我們會用 Keras 做到兩件很重要的事情:分層設定學習率和靈活操作梯度。
首先是分層設定學習率,這個用途很明顯,比如我們在 fine tune 已有模型的時候,有些時候我們會固定一些層,但有時候我們又不想固定它,而是想要它以比其他層更低的學習率去更新,這個需求就是分層設定學習率了。
對於在 Keras 中分層設定學習率,網上也有一定的探討,結論都是要透過重寫最佳化器來實現。顯然這種方法不論在實現上還是使用上都不友好。
然後是操作梯度。操作梯度一個最直接的例子是梯度裁剪,也就是把梯度控制在某個範圍內,Keras 內建了這個方法。但是 Keras 內建的是全域性的梯度裁剪,假如我要給每個梯度設定不同的裁剪方式呢?甚至我有其他的操作梯度的思路,那要怎麼實施呢?不會又是重寫最佳化器吧?
本文就來為上述問題給出盡可能簡單的解決方案。
分層的學習率
對於分層設定學習率這個事情,重寫最佳化器當然是可行的,但是太麻煩。如果要尋求更簡單的方案,我們需要一些數學知識來指導我們怎麼進行。
引數變換下的最佳化
首先我們考慮梯度下降的更新公式:

其中 L 是帶引數 θ 的 loss 函式,α 是學習率,![]() 是梯度,有時候我們也寫成
是梯度,有時候我們也寫成 。記號是很隨意的,關鍵是理解它的含義。
。記號是很隨意的,關鍵是理解它的含義。
然後我們考慮變換 θ=λϕ,其中 λ 是一個固定的標量,ϕ 也是引數。現在我們來最佳化 ϕ,相應的更新公式為:

其中第二個等號其實就是鏈式法則。現在我們在兩邊乘上 λ,得到:
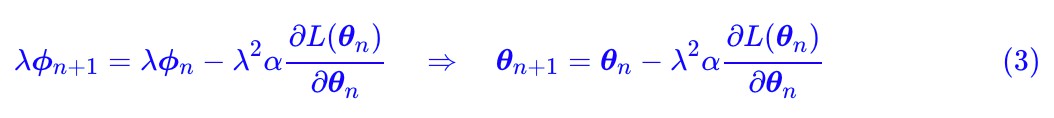
對比 (1) 和 (3),大家能明白我想說什麼了吧:
在 SGD 最佳化器中,如果做引數變換 θ=λϕ,那麼等價的結果是學習率從 α 變成了
。
不過,在自適應學習率最佳化器(比如 RMSprop、Adam 等),情況有點不一樣,因為自適應學習率使用梯度(作為分母)來調整了學習率,抵消了一個 λ,從而(請有興趣的讀者自己推導一下):
在 RMSprop、Adam 等自適應學習率最佳化器中,如果做引數變換 θ=λϕ,那麼等價的結果是學習率從 α 變成了 λα。
移花接木調整學習率
有了前面這兩個結論,我們就只需要想辦法實現引數變換,而不需要自己重寫最佳化器,來實現逐層設定學習率了。
實現引數變換的方法也不難,之前我們在《 “讓Keras更酷一些!”:隨意的輸出和靈活的歸一化》[1] 一文討論權重歸一化的時候已經講過方法了。因為 Keras 在構建一個層的時候,實際上是分開了 build 和 call 兩個步驟,我們可以在 build 之後插一些操作,然後再呼叫 call 就行了。
下麵是一個封裝好的實現:
import keras.backend as K
class SetLearningRate:
"""層的一個包裝,用來設定當前層的學習率
"""
def __init__(self, layer, lamb, is_ada=False):
self.layer = layer
self.lamb = lamb # 學習率比例
self.is_ada = is_ada # 是否自適應學習率最佳化器
def __call__(self, inputs):
with K.name_scope(self.layer.name):
if not self.layer.built:
input_shape = K.int_shape(inputs)
self.layer.build(input_shape)
self.layer.built = True
if self.layer._initial_weights is not None:
self.layer.set_weights(self.layer._initial_weights)
for key in ['kernel', 'bias', 'embeddings', 'depthwise_kernel', 'pointwise_kernel', 'recurrent_kernel', 'gamma', 'beta']:
if hasattr(self.layer, key):
weight = getattr(self.layer, key)
if self.is_ada:
lamb = self.lamb # 自適應學習率最佳化器直接保持lamb比例
else:
lamb = self.lamb**0.5 # SGD(包括動量加速),lamb要開平方
K.set_value(weight, K.eval(weight) / lamb) # 更改初始化
setattr(self.layer, key, weight * lamb) # 按比例替換
return self.layer(inputs)
使用示例:
x_in = Input(shape=(None,))
x = x_in
# 預設情況下是x = Embedding(100, 1000, weights=[word_vecs])(x)
# 下麵這一句表示:後面將會用自適應學習率最佳化器,並且Embedding層以總體的十分之一的學習率更新。
# word_vecs是預訓練好的詞向量
x = SetLearningRate(Embedding(100, 1000, weights=[word_vecs]), 0.1, True)(x)
# 後面部分自己想象了~
x = LSTM(100)(x)
model = Model(x_in, x)
model.compile(loss='mse', optimizer='adam') # 用自適應學習率最佳化器最佳化
幾個註意事項:
1. 目前這種方式,只能用於自己動手寫程式碼來構建模型的時候插入,無法對建立好的模型進行操作;
2. 如果有預訓練權重,有兩種載入方法。第一種是像剛才的使用示例一樣,在定義層的時候透過 weights 引數傳入;第二種方法是建立好模型後(已經在相應的地方插入好 SetLearningRate),用 model.set_weights (weights) 來賦值,其中 weights 是“在 SetLearningRate 的位置已經被除以了 λ 或![]() 的原來模型的預訓練權重”;
的原來模型的預訓練權重”;
3. 載入預訓練權重的第二種方法看起來有點不知所云,但如果你已經理解了這一節的原理,那麼應該能知道我在說什麼。因為設定學習率是透過 weight * lamb 來實現的,所以 weight 的初始化要變為 weight / lamb;
4. 這個操作基本上不可逆,比如你一開始設定了 Embedding 層以總體的 1/10 比例的學習率來更新,那麼很難在這個基礎上,再將它改為 1/5 或者其他比例。(當然,如果你真的徹底搞懂了這一節的原理,並且也弄懂了載入預訓練權重的第二種方法,那麼還是有辦法的,那時候相信你也能搞出來);
5. 這種做法有以上限制,是因為我們不想透過修改或者重寫最佳化器的方式來實現這個功能。如果你決定要自己修改最佳化器,請參考《“讓Keras更酷一些!”:小眾的自定義最佳化器》[2]。
自由的梯度操作
在這部分內容中,我們將學習對梯度的更為自由的控制。這部分內容涉及到對最佳化器的修改,但不需要完全重寫最佳化器。
Keras最佳化器的結構
要修改最佳化器,必須先要瞭解 Keras 最佳化器的結構。在《“讓Keras更酷一些!”:小眾的自定義最佳化器》[2] 一文我們已經初步看過了,現在我們重新看一遍。
Keras 最佳化器程式碼:
https://github.com/keras-team/keras/blob/master/keras/optimizers.py
隨便觀察一個最佳化器,就會發現你要自定義一個最佳化器,只需要繼承 Optimizer 類,然後定義 get_updates 方法。但本文我們不想做新的最佳化器,只是想要對梯度有所控制。可以看到,梯度的獲取其實是在父類 Optimizer 的 get_gradients 方法中:
def get_gradients(self, loss, params):
grads = K.gradients(loss, params)
if None in grads:
raise ValueError('An operation has `None` for gradient. '
'Please make sure that all of your ops have a '
'gradient defined (i.e. are differentiable). '
'Common ops without gradient: '
'K.argmax, K.round, K.eval.')
if hasattr(self, 'clipnorm') and self.clipnorm > 0:
norm = K.sqrt(sum([K.sum(K.square(g)) for g in grads]))
grads = [clip_norm(g, self.clipnorm, norm) for g in grads]
if hasattr(self, 'clipvalue') and self.clipvalue > 0:
grads = [K.clip(g, -self.clipvalue, self.clipvalue) for g in grads]
return grads
其中方法中的第一句就是獲取原始梯度的,後面則提供了兩種梯度裁剪方法。不難想到,只需要重寫最佳化器的 get_gradients 方法,就可以實現對梯度的任意操作了,而且這個操作不影響最佳化器的更新步驟(即不影響 get_updates 方法)。
處處皆物件:改寫即可
怎麼能做到只修改 get_gradients 方法呢?這得益於 Python 的哲學——“處處皆物件”。Python 是一門面向物件的程式語言,Python 中幾乎你能碰到的一切變數都是一個物件。我們說 get_gradients 是最佳化器的一個方法,也可以說 get_gradients 的一個屬性(物件),既然是屬性,直接改寫賦值即可。
我們來舉一個最粗暴的例子(惡作劇):
def our_get_gradients(loss, params):
return [K.zeros_like(p) for p in params]
adam_opt = Adam(1e-3)
adam_opt.get_gradients = our_get_gradients
model.compile(loss='categorical_crossentropy',
optimizer=adam_opt)
其實這樣做的事情很無聊,就是把所有梯度置零了(然後你怎麼最佳化它都不動了),但這個惡作劇例子已經足夠有代表性了——你可以將所有梯度置零,你也可以將梯度做任意你喜歡的操作。比如將梯度按照 l1 範數而非 l2 範數裁剪,又或者做其他調整。
假如我只想操作部分層的梯度怎麼辦?那也簡單,你在定義層的時候需要起一個能區分的名字,然後根據 params 的名字做不同的操作即可。都到這一步了,我相信基本是“一法通,萬法皆通”的了。
飄逸的Keras
也許在很多人眼中,Keras 就是一個好用但是封裝得很“死”的高層框架,但在我眼裡,我只看到了它無限的靈活性——那是一個無懈可擊的封裝。
相關連結
[1] https://kexue.fm/archives/6311
[2] https://kexue.fm/archives/5879
