編者按:Python學習和實踐資料科學,Python和Python庫能夠方便地完成資料獲取,資料探索,資料處理,資料建模和模型應用與部署的工作,對於資料科學工作中各個環節都有合適的解決方案。對於新手,建議按著本教程學習與實踐。
2018年2月15日,除夕佳節,祝願各位資料人,團圓美滿,幸福安康,心想事成。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
我在SAS工作了5年多之後,決定走出舒適區。作為一名資料科學家,我在尋找其他好用的工具,幸運的是,沒過多久,我發現了Python。
一直以來,我喜歡敲程式碼。事實證明,有了Python,敲程式碼變得更為容易。
我花了一週時間來學習Python的基礎知識,從那時起,我不僅深入鑽研Python,而且還幫助許多其他人學習這門語言。起初,Python是門通用語言,多年來,隨著社群的大力支援,現在有了資料分析及預測建模庫。
由於缺少Python資料科學資源,我決定建立本教程,旨在幫助大家快速入門。在本教程中,我們將討論如何使用Python來進行資料分析,在實踐中總結方法。
Python資料分析基礎
為什麼要學習使用Python來進行資料分析?
使用Python來進行資料分析的原因有很多,過去一段時間透過對比SAS和R,有以下幾點理由:
-
開源免費
-
強大社群支援
-
易學
-
成為資料科學和web產品分析的通用語言
誠然,它還有很多缺點:
Python是一種解釋語言而不是編譯語言,因此佔用更多的CPU時間。然而,由於節省了程式員時間(易學),Python仍然是一個不錯的選擇。
Python 2.7與3.4版本的比較
這是Python中最受爭議的話題之一,作為初學者,你繞不開這個問題。其實選擇哪個版本都沒有對錯,完全取決於你的需要和實際使用場景。我會嘗試給大家一些指引,幫助大家做出明智的選擇。
為什麼選擇Python 2.7?
社群支援,這是早期需要的,Python 2版本在2000年下半年釋出,超過15年的使用了。
第三方庫支援,雖然許多庫提供3.X的支援,但仍然有大量庫只能在2.X版本上執行。如果你打算將Python用於特定的場景,如網頁開發,高度依賴外部模組,你可能選擇2.7版本會更好。
3.X版本的一些功能向後相容,可以使用2.7版本。
為什麼選擇Python 3.4?
簡潔快速,Python開發人員已經修複了一些自身的Bug,為其發展打下更堅實的基礎。最初這些可能與你不是很相關,終將是很重要的。
未來趨勢,2.7版本是2.X系列的最後一個版本,最終大家都必須轉到3.X版本。Python 3已經釋出了5年的穩定版本,並將持續推進。
沒有明確顯示到底誰好,但我認為最重要的是大家應該專註於將Python當作一門語言來學習。版本之間的轉換是一個時間的問題。遲點,繼續關註Python 2.X與3.X比較的文章。
如何安裝Python?
有兩種安裝Python的方法:
你可以直接在官網上下載Python,並安裝所需要的元件和庫。
或者,你可以下載安裝預裝庫的軟體包,我建議你下載Anaconda,另外可以是Canopy Express。
第二種方法免去安裝其他庫的麻煩,因此我會推薦給初學者。如果你對單個庫的最新版本感興趣,你必須等到整個軟體包的更新。除非你在做前沿的統計研究,否則應該沒有什麼影響。
選擇開發環境
一旦安裝了Python,就有各種各樣的開發環境,以下是常見的3種:
-
Terminal / Shell
-
IDLE (預設)
-
iPython notebook(類似R中的markdown)

正確的開發環境取決於你的需要,我個人更喜歡iPython Notebook。它有很多好的功能,編寫程式碼時提供了檔案記錄功能,可以選擇執行程式碼塊(而不是逐行執行)。
我們將使用iPython開發環境完成本教程。
預熱:執行你的第一個Python程式
你可以使用Python作為簡單的計算器開始

提醒幾點
你可以在terminal / cmd上輸入“ipython notebook”來啟動iPython Notebook,這取決於你正在使用的作業系統。
可以透過點選“UntitledO”來重新命名。
介面顯示In [*]表示輸入,Out[*]表示輸出。
執行當前程式碼塊按快捷鍵“Shift + Enter”,執行當前塊並插入額外的塊按快捷鍵“ALT + Enter”。
在深入解決問題之前,讓我們回顧一下,瞭解Python的基礎知識。 我們知道資料結構、迭代和條件結構構成任何語言的關鍵。 在Python中,這些包括串列,字串,元組,字典,for迴圈,while迴圈,if-else等。我們來看看其中的一些。
Python庫及資料結構
Python資料結構
以下是一些在Python中使用的資料結構。你應該熟悉它們,以便適當使用它們。
Lists – 串列是Python中最常用的資料結構之一。 可以透過在方括號中寫入逗號分隔值的序列來簡單地定義串列。串列可以包含不同型別的項,但通常這些項都具有相同的型別。 Python串列是可變的,可以更改串列的各個元素。
下麵是一個快速定義一個串列然後訪問它的例子:

Strings – 字串可以簡單地透過使用單個(’),雙(“)或三個(’’’)的逗號來定義。 用三引號(’’’)括起來的字串允許跨行,並且在檔案字串中經常使用(Python的記錄函式的方法)。 “\”用作跳脫字元。 請註意,Python字串是不可變的,因此不能更改字串的一部分。

Tuples – 一個元組用逗號分隔的值來表示。元組是不可變的,輸出被圓括號包圍,以便巢狀元組被正確處理。 此外,即使元組是不可變的,如果需要,可以儲存可變資料。

由於元組是不可變的,不能改變,與串列相比,它的處理速度更快。 因此,如果你的串列不太可能更改,應該使用元組,而不是串列。
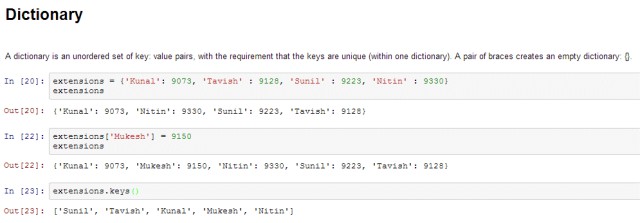
Dictionary – 字典是一組無序的鍵:值對,要求鍵是唯一的(在一個字典內)。一對大括號建立一個空字典:{}。
Python迭代和條件構造
像大多數語言一樣,Python也有一個FOR迴圈,它是最廣泛使用的迭代方法。它有一個簡單的語法:
for i in [Python Iterable]: expression(i)
這裡“Python Iterable”可以是串列,元組或其他高階資料結構,我們將在後面的部分中討論。我們來看一個簡單的例子,確定一個數字的階乘。
fact = 1 for i in range(1,N+1): fact *= i
根據條件陳述句,這些陳述句用於根據條件執行程式碼片段。最常用的結構是if-else,具有以下語法:
if [condition]: __execution if ture__ else: __execution if false__
例如,如果我們要列印數字N是偶數還是奇數:
if N%2 == 0: print 'Even' else: print 'Odd'
現在,你已經熟悉Python的基礎知識了,我們進一步瞭解一下,如果必須執行以下任務,該怎麼辦?
1.兩個矩陣相乘
2.找到二次方程的根
3.繪製條形圖和直方圖
4.網頁訪問
如果你嘗試從頭開始編寫程式碼,那將成為一場惡夢,你將在Python上不會堅持超過2天!但是不用擔心, 幸運的是,有許多預定義的庫,我們可以直接匯入到我們的程式碼中,使我們的程式設計工作變得容易。
例如,考慮我們剛剛看到的階乘例子。完成只需一個步驟:
math.factorial(N)
當然,我們需要匯入math庫。我們來研究一下各種庫。
Python庫
透過瞭解一些有用的庫,將在我們學習Python的過程中領先一步。第一步顯然是學會將它們匯入我們的環境中。在Python中有以下幾種方法:
import math as m from math import *
在第一種方式中,我們定義了一個別名為m的math庫。現在我們可以使用別名m.factorial()取用它,從math庫(例如階乘)中使用各種函式。
第二種方式,匯入了math庫的整個名稱空間,即可以直接使用factorial()而不取用math。
提示:Google建議你使用第一種匯入庫方式,因為你將知道函式來自哪裡。
以下是庫串列,任何科學計算和資料分析會用到:
-
NumPy:代表的是Numerical Python。NumPy最強大的功能是n維陣列。該庫還包含基本的線性代數函式,傅裡葉變換,隨機數函式和與其他底層語言(如Fortran,C和C ++)整合的工具。
-
SciPy:代表的是Scientific Python。SciPy建立在NumPy基礎上。它是離散傅裡葉變換,線性代數,最佳化和稀疏矩陣等多種高階科學和工程模組最有用的庫之一。
-
Matplotlib:用於繪製各種各樣的圖形,從直方圖到線圖、熱力圖。你可以使用ipython notebook中的Pylab功能(ipython notebook -pylab = inline)線上使用這些繪圖功能。如果忽略行內選項,pylab將ipython環境轉換為與Matlab非常相似的環境。還可以使用Latex命令在影象新增數學符號。
-
Pandas:用於結構化資料的運算和操作。廣泛用於資料整理和預處理。相較而言,Pandas被新增到Python時間不久,其有助於提高Python在資料科學社群的使用。
-
Scikit:用於機器學習。該庫建立在NumPy,SciPy和matplotlib基礎上,包含許多有效的機器學習和統計建模工具,例如分類,回歸,聚類和降維。
-
Statsmodels:用於統計建模。Statsmodels是一個Python中提供使用者探索資料、估計統計模型和執行統計測試的模組。可用於不同型別資料的描述性統計,統計測試,繪圖功能和結果統計。
-
Seaborn:用於資料視覺化。Seaborn是一個用於在Python中製作有吸引力和翔實的統計圖形庫。它是基於matplotlib。Seaborn旨在使視覺化成為探索和理解資料的核心組成。
-
Bokeh:用於在現代網路瀏覽器上建立互動式圖表,儀錶盤和資料應用程式。它賦予使用者以D3.js的風格生成優雅簡潔的圖形。此外,它具有超大型或流式資料集的高效能互動能力。
-
Blaze:將Numpy和Pandas的能力擴充套件到分散式和流式傳輸資料集。它可以用於從眾多來源(包括Bcolz,MongoDB,SQLAlchemy,Apache Spark,PyTables等)訪問資料。與Bokeh一起,Blaze可以作為在巨型資料塊上建立有效視覺化和儀錶盤的強大的工具。
-
Scrapy:用於網路爬蟲。它是獲取特定樣式資料的非常有用的框架。它從網站首頁url開始,然後挖掘網站內的網頁內容來收集資訊。
-
SymPy:用於符號計算。它具有從基本算術符號到微積分,代數,離散數學和量子物理學的廣泛能力。另一個有用的功能是將計算結果格式化為LaTeX程式碼。
-
Requests:用於web訪問。它類似於標準python庫urllib2,但是程式碼更容易。你會發現與urllib2的微妙差異,但是對於初學者來說,Requests可能更方便。
你可能需要的額外的庫:
-
os用於作業系統和檔案操作
-
networkx和igraph為基於圖的資料操作
-
regular expressions用於在文字中查詢特定樣式的資料
-
BeautifulSoup用於網路爬蟲。它不如Scrapy,因為它只是單個網頁中提取資訊。
既然我們熟悉Python基礎知識和庫,那麼我們可以透過Python深入解決問題。做預測模型過程中,我們會使用到一些功能強大的庫,也會遇到不同的資料結構。我們將帶你進入三個關鍵階段:
-
資料探索 – 詳細瞭解我們的資料
-
資料清洗 – 清理資料,使其更適合統計建模
-
預測建模 – 執行實際演演算法並獲得結果
使用pandas進行資料探索
為了進一步探索我們的資料,給你介紹另一個動物(好像Python還不夠!)- Pandas

Pandas是Python中最有好用的資料分析庫之一(我知道這些名字聽起來很奇怪,先這樣!)促使越來越多資料科學界人士使用Python。現在我們將使用pandas從Analytics Vidhya比賽中讀取資料集,進行探索性分析,並構建我們的第一個基礎分類演演算法來解決這個問題。
在資料載入之前,先瞭解Pandas中2個關鍵資料結構 – Series和DataFrames。
Series及DataFrame介紹
Series可以理解為1維標簽/索引陣列。你可以透過這些標簽訪問series的各個元素。
Dataframe類似於Excel工作簿,列名稱取用列,使用行號訪問行。本質區別在於dataframes中列名稱和行號稱為列和行索引。
Series和DataFrames構成了Pandas在Python中的核心資料模型。資料集首先被讀入Dataframes,然後各種操作(例如分組、聚合等)可以非常容易地應用於其列。
應用案例 – 貸款預測問題
以下是變數的描述:
| 變數 | 描述 |
| Loan_ID | 貸款ID |
| Gender | 男/女 |
| Married | 已婚(Y/N) |
| Dependents | 贍養人數 |
| Education | 教育程度(Graduate/Under Graduate) |
| Self_Employed | 自僱人士(Y/N) |
| ApplicantIncome | 申報收入 |
| CoapplicantIncome | 綜合收入 |
| LoanAmount | 貸款金額 |
| Loan_Amount_Term | 貸款月數 |
| Credit_History | 信用記錄 |
| Property_Area | 房產位置(Urban/Semi Urban/Rural) |
| Loan_Status | 貸款批准狀態(Y/N) |
開始資料探索
首先,在terminal/ Windows命令提示符下鍵入以下命令,以Inline Pylab樣式啟動iPython介面:
ipython notebook --pylab=inline
這樣在pylab環境中開啟了iPython notebook,它已經匯入了一些有用的庫。此外,可以行內繪製資料,這使得它成為一個非常好的互動式資料分析環境。 你可以透過鍵入以下命令(並獲得如下圖所示的輸出)來檢查環境是否載入正確:
plot(arange(5))

我當前在Linux中工作,並將資料集儲存在以下位置: /home/kunal/Downloads/Loan_Prediction/train.csv
匯入庫和資料集:
以下是我們將在本教程中使用的庫:
numpy matplotlib pandas
請註意,由於Pylab環境,你不需要匯入matplotlib和numpy。我仍然將它們保留在程式碼中,以便在不同的環境中使用程式碼。
匯入庫後,使用函式read_csv()讀取資料集。程式碼如下:
import pandas as pd
import numpy as np
import matplotlib as plt
df = pd.read_csv("/home/kunal/Downloads/Loan_Prediction/train.csv") #使用Pandas讀入資料集轉換成dataframe
快速資料探索
讀取資料集後,可以使用head()函式檢視前幾行
df.head(10)

這樣輸出了10行,或者,也可以列印檢視更多行資料集。
接下來,可以使用describe()函式來檢視數值欄位的摘要
df.describe()

describe()函式將在其輸出中提供計數、平均值、標準偏差(std)、最小值、四分位數和最大值。
這裡有幾個發現,你可以透過看看describe()函式的輸出來繪製:
1.LoanAmount有(614 – 592)22個缺失值。
2.Loan_Amount_Term有(614 – 600)14個缺失值。
3.Credit_History有(614 – 564)50個缺失值。
4.我們也可以看到,約84%的申請人有信用記錄,怎麼樣?Credit_History欄位的平均值為0.84(記住,Credit_History對於具有信用記錄的使用者而言為1,否則為0)
5.申請人收入分佈似乎符合預期。與CoapplicantIncome相同。
請註意,我們可以透過比較平均值與中位數來瞭解資料中可能的偏差。
對於非數值(例如Property_Area,Credit_History等),我們可以檢視頻率分佈來瞭解它們是否有意義。頻率表可以透過以下命令列印輸出:
df['Property_Area'].value_counts()
同樣,我們可以看看信用歷史的獨特價值。請註意,dfname [‘column_name’]是一種基本的索引方法來訪問dataframe的特定列。它也可以是一個列名的串列。
分佈分析
現在我們熟悉基本的資料特徵,我們來研究各種變數的分佈。從數字變數ApplicantIncome和LoanAmount開始。
首先使用以下命令繪製ApplicantIncome的直方圖:
df['ApplicantIncome'].hist(bins=50)
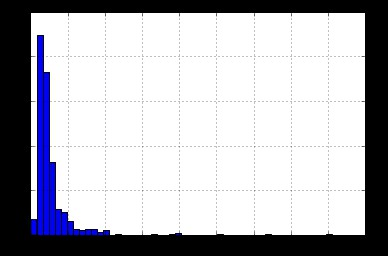
在這裡我們觀察到很少極端值。這也是為什麼需要50個箱子來明確分配分配的原因。
接下來,我們來看一下箱線圖來瞭解分佈。箱線圖可以透過以下方式繪製:
df.boxplot(column='ApplicantIncome')

這證實了許多異常值/極端值的存在。這可歸因於社會的收入差距。部分原因可能是由於我們研究了不同教育水平的人。透過教育變數將其分離開:
df.boxplot(column='ApplicantIncome', by = 'Education')

我們可以看到大學學歷和非大學學歷的平均收入之間沒有實質性差異。但是,高學歷中高收入人數更多,這似乎是離群值。
現在,我們來看看變數LoanAmount的直方圖和boxplot,使用以下命令:
df['LoanAmount'].hist(bins=50) df.boxplot(column='LoanAmount')


再次,有一些離群值。顯然,ApplicantIncome和LoanAmount都需要一定量的資料清洗。 LoanAmount有缺失值和離群值,同時,ApplicantIncome有一些離群值,接下來我們將分幾個部分,做更深入的瞭解。
分類變數的分析
現在我們瞭解ApplicantIncome和LoanIncome的分佈,為了更詳細地理解分類變數,我們將使用Excel的透視表和交叉表。例如,我們來看根據信用記錄獲得貸款的機會,這可以在MS Excel中使用資料透視表來實現:

註意:這裡的貸款狀態重編碼了,1代表是,0代表否,平均值表示貸款的機率。
現在我們將看看使用Python生成類似洞察所需的步驟。
temp1 = df['Credit_History'].value_counts(ascending=True)
temp2=df.pivot_table(values='Loan_Status',index=['Credit_History'],aggfunc=lambda x: x.map({'Y':1,'N':0}).mean())
print 'Frequency Table for Credit History:'
print temp1
print '\nProbility of getting loan for each Credit History class:'
print temp2
現在可以看到,我們得到一個類似MS Excel一樣的透視表,這可以使用“matplotlib”庫,用以下程式碼畫條形圖:
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Credit_History')
ax1.set_ylabel('Count of Applicants')
ax1.set_title("Applicants by Credit_History")
temp1.plot(kind='bar')
ax2 = fig.add_subplot(122)
temp2.plot(kind = 'bar')
ax2.set_xlabel('Credit_History')
ax2.set_ylabel('Probability of getting loan')
ax2.set_title("Probability of getting loan by credit history")
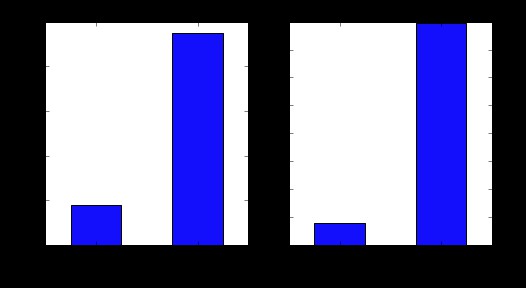
這表明如果申請人有有效的信用記錄,獲得貸款的機會是沒有有效信用記錄的8倍。你可以透過已婚,自僱,居住地區等繪製相似的圖表。
或者,這兩個圖也可以透過將它們組合在堆疊圖表中來進行視覺化:
temp3 = pd.crosstab(df['Credit_History'], df['Loan_Status']) temp3.plot(kind='bar', stacked=True, color=['red','blue'], grid=False)

還可以新增性別(類似於Excel中的資料透視表):

如果你還沒有意識到,我們在這裡建立了兩個基本的分類演演算法,一個基於信用記錄,另一個基於2分類變數(包括性別)。你可以快速編碼,以便在AV Datahacks上建立你的第一次提交版本。
我們看到如何在Python中使用pandas進行探索性資料分析,希望你對pandas(熊貓)的愛將會增加,pandas庫為你的資料集分析提供一些幫助。
接下來,我們進一步探討ApplicantIncome和LoanStatus變數,執行資料運算並建立一個資料集以應用各種建模技術。強烈建議再選擇一個資料集和問題,閱讀一個獨立的例子,然後再做進一步分析。
python資料清洗:Pandas
對於從事資料分析的人來說,下麵這些是你必須要做的。
資料清洗 – 重構資料
在資料探索時,為了構建一個好的模型,需要先解決掉資料集中發現了的一些問題。這個過程通常稱為“資料清洗”。針對以下問題,我們看到:
1.變數缺失值。我們應該根據缺失值的數量和變數的預期重要性明智地估計這些值。
2.在分析這些分佈的同時,我們看到變數ApplicantIncome和LoanAmount似乎都包含了離群值。雖然他們可能會有直觀的意義,但應該得到適當的處理。
除了這些數值型的資料問題之外,我們還應該關註非數值型資料,如性別、區域、已婚、教育程度和贍養人數,用以挖掘任何有用的資訊。
檢查資料集中的缺失值
一起看看所有變數中的缺失值,因為大多數模型不能使用含缺失值的資料,缺失值填補很重要。所以,我們檢查資料集中的null / NaN的數量。
df.apply(lambda x: sum(x.isnull()),axis=0)
如果值為null則isnull()傳回1,那麼該命令計算出每個列中缺失值的數量。
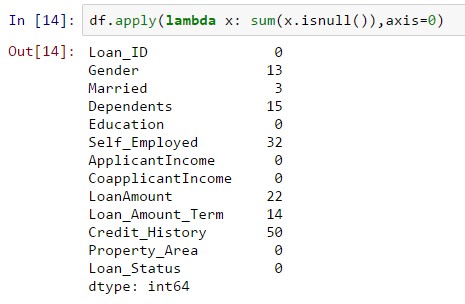
雖然缺失值數量不是很多,但是大多變數都有缺失值,需要估算並填補缺失值。
註意:缺失值可能並不總是NaN。例如,如果Loan_Amount_Term為0,那麼是否有意義,或者是否是缺失值?我想你的答案是缺失值,你是對的。所以我們應該檢查資料是否有實際意義。
如何填補LoanAmount中的缺失值?
有許多方法來填補貸款額度的缺失值,最簡單的是用均值替換,可以透過以下程式碼來完成:
df['LoanAmount'].fillna(df['LoanAmount'].mean(), inplace=True)
另外也可以是建立一個監督學習模型,以其他變數如年齡等為基礎預測貸款額度。
既然現在是資料清洗的步驟,我寧願採取介於兩者之間的一種方法。一個關鍵的假設是,一個人教育程度或者個體經營戶與否,可以結合起來給出一個很好的貸款額度的估計。
首先,我們來看一下箱線圖,看看是否存在趨勢規律:

因此,我們看到每個組的貸款額中位數有一些變化,可以用來作估算值。但是,我們必須先確保Self_Employed和Education變數中的每一個都不應該有缺少值。
如前所述,Self_Eployee有一些缺失的值。看看頻率表:

大約86%的值為“No”,將缺失值估計為“No”是安全的,因為正確的機率會更高。可以使用以下程式碼完成:
df['Self_Employed'].fillna('No',inplace=True)
現在,我們將建立一個資料透視表,它提供了貸款額度中位數按Self_Eployed和Education交叉分組。接下來,我們定義一個函式,它傳回這些單元格的值並應用它來填補貸款金額的缺失值:
table = df.pivot_table(values='LoanAmount', index='Self_Employed' ,columns='Education', aggfunc=np.median) # Define function to return value of this pivot_table def fage(x): return table.loc[x['Self_Employed'],x['Education']] # Replace missing values df['LoanAmount'].fillna(df[df['LoanAmount'].isnull()].apply(fage, axis=1), inplace=True)
這樣為你提供一個很好的方式來估算貸款額度的缺失值。
如何處理LoanAmount和ApplicantIncome分佈中的極端值?
我們首先分析LoanAmount。 極端值可能有實際意義的,有些人可能因為特殊需要才申請高額貸款,所以不用把它們視為離群值,我們來嘗試用對數變換來消除它們的影響:
df['LoanAmount_log'] = np.log(df['LoanAmount']) df['LoanAmount_log'].hist(bins=20)
再次檢視直方圖:

現在分佈看起來更加接近正態分佈,極端值的影響已經顯示減弱。
對於變數ApplicantIncome,一個可能的直覺是,一些申請人申報收入較低,但是綜合收入高也獲得支援。所以把申報收入作為總收入結合在一起是一個好主意,並採取同樣的對數變換。
df['TotalIncome'] = df['ApplicantIncome'] + df['CoapplicantIncome'] df['TotalIncome_log'] = np.log(df['TotalIncome']) df['LoanAmount_log'].hist(bins=20)
現在我們看到分佈比以前好多了。我會把性別、已婚、贍養者、貸款月數、信用歷史等缺失值的估算留給大家完成。此外,我鼓勵大家考慮可能從資料中發掘附加資訊,例如,建立列LoanAmount / TotalIncome可能是有道理的,因為它給出了申請人如何適應償還貸款的想法。
接下來,我們將看看建立預測模型。
在Python中構建一個預測模型
現在,我們已經有對建模有用的資料,現在我們來看看python程式碼,在我們的資料集上建立一個預測模型。Skicit-Learn(sklearn)是Python中最常用的機器學習庫,我們將會藉助它來建模。
既然,sklearn要求所有輸入都是數字,所以我們應該對類別進行編碼,將所有的分類變數轉換為數值變數。這可以使用以下程式碼完成:
from sklearn.preprocessing import LabelEncoder var_mod = ['Gender','Married','Dependents','Education','Self_Employed','Property_Area','Loan_Status'] le = LabelEncoder() for i in var_mod: df[i] = le.fit_transform(df[i]) df.dtypes
接下來,我們將匯入所需的模組。然後我們將定義一個通用分類函式,它將模型作為輸入,並確定準確度和交叉驗證得分。既然這是一個介紹性的文章,我將不再贅述編碼的細節。
#Import models from scikit learn module:
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import KFold #For K-fold cross validation
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn import metrics
#Generic function for making a classification model and accessing performance:
def classification_model(model, data, predictors, outcome):
#Fit the model:
model.fit(data[predictors],data[outcome])
#Make predictions on training set:
predictions = model.predict(data[predictors])
#Print accuracy
accuracy = metrics.accuracy_score(predictions,data[outcome])
print "Accuracy : %s" % "{0:.3%}".format(accuracy)
#Perform k-fold cross-validation with 5 folds
kf = KFold(data.shape[0], n_folds=5)
error = []
for train, test in kf:
# Filter training data
train_predictors = (data[predictors].iloc[train,:])
# The target we're using to train the algorithm.
train_target = data[outcome].iloc[train]
# Training the algorithm using the predictors and target.
model.fit(train_predictors, train_target)
#Record error from each cross-validation run
error.append(model.score(data[predictors].iloc[test,:],data[outcome].iloc[test]))
print "Cross-Validation Score : %s" % "{0:.3%}".format(np.mean(error))
#Fit the model again so that it can be refered outside the function:
model.fit(data[predictors],data[outcome])
邏輯回歸
我們來做第一個邏輯回歸模型。一種方法是將所有變數都放入模型中,但這可能會導致過擬合。 簡單來說,模型採用所有變數,有可能理解資料的特定的複雜關係,並不能很好地推廣。
我們可以很容易地做出一些直觀的假設,獲得貸款的機會會更高:
1.具有信用記錄的申請人
2.具有較高申請收入和綜合收入的申請人
3.高等教育水平的申請人
4.具有高增長前景的城市地產
我們用’Credit_History’做我們的第一個模型。
outcome_var = 'Loan_Status' model = LogisticRegression() predictor_var = ['Credit_History'] classification_model(model, df,predictor_var,outcome_var)
準確度:80.945%,交叉驗證得分:80.946%
#We can try different combination of variables: predictor_var = ['Credit_History','Education','Married','Self_Employed','Property_Area'] classification_model(model, df,predictor_var,outcome_var)
準確度:80.945%交叉驗證得分:80.946%
一般來說,我們期望透過增加變數數量來提高準確度,但這是一個更具挑戰性的案例,準確度和交叉驗證得分不受重要性較小的變數的影響。信用歷史是主導樣式。我們現在有兩個選擇:
1.特徵工程:挖掘新資訊,並嘗試預測。這個留給大家去發揮創造力。
2.更好的建模技術。接下來我們來探討一下。
決策樹
決策樹是構建預測模型的另一種方法,通常比邏輯回歸模型具有更高的精度。
model = DecisionTreeClassifier() predictor_var = ['Credit_History','Gender','Married','Education'] classification_model(model, df,predictor_var,outcome_var)
準確度:81.930%,交叉驗證得分:76.656%
這裡,基於分類變數的模型不會受信用歷史產生影響。我們來嘗試幾個數值型變數:
#We can try different combination of variables: predictor_var = ['Credit_History','Loan_Amount_Term','LoanAmount_log'] classification_model(model, df,predictor_var,outcome_var)
準確度:92.345%交叉驗證得分:71.009%
在這裡我們觀察到,新增變數後模型準確度上升,交叉驗證錯誤率下降。這是模型資料過擬合的結果。我們嘗試一個更複雜的演演算法,看看是否有幫助。
隨機森林
隨機森林是解決分類問題的另一種演演算法。
隨機森林的一個優點是我們可以將所有特徵放在一起,並傳回一個可用於選擇的特徵重要性矩陣。 model = RandomForestClassifier(n_estimators=100) predictor_var = ['Gender', 'Married', 'Dependents', 'Education', 'Self_Employed', 'Loan_Amount_Term', 'Credit_History', 'Property_Area', 'LoanAmount_log','TotalIncome_log'] classification_model(model, df,predictor_var,outcome_var)
準確度:100.000%交叉驗證得分:78.179%
訓練集的準確度是100%,這是過擬合的最終結果,可以透過兩種方式解決:
1.減少預測數量
2.調整模型引數
我們來試試這兩種方法,首先我們看到特徵重要性矩陣,我們將從中篩選最重要的特徵變數。
#Create a series with feature importances: featimp = pd.Series(model.feature_importances_, index=predictor_var).sort_values(ascending=False) print featimp

我們使用前5個變數來建立一個模型。另外,我們將修改一點點隨機森林模型的引數:
model = RandomForestClassifier(n_estimators=25, min_samples_split=25, max_depth=7, max_features=1) predictor_var = ['TotalIncome_log','LoanAmount_log','Credit_History','Dependents','Property_Area'] classification_model(model, df,predictor_var,outcome_var)
準確度:82.899%,交叉驗證得分:81.461%
雖然準確度降低,但交叉驗證分數在提高,表明該模型的適用性很好。記住,隨機森林模型不是完全可復用的。不同的變數執行結果會有變化,但輸出儘量保持正確。
你會註意到,即使在對隨機森林進行了一些基本的引數調整之後,我們交叉驗證的精度只比原始邏輯回歸模型略好一些。這個案例給了我們一些非常有趣、特別的學習體驗:
1.使用更複雜的模型不能保證更好的預測結果。
2.避免使用複雜的建模技術作為黑盒子而不瞭解基本概念。這樣做會增加過擬合趨勢,從而降低模型解釋力。
3.特徵工程是成功的關鍵。大家可以使用Xgboost模型,但真正的藝術和創造力在於增強特徵能力以更好地適應模型。
你準備好迎接挑戰嗎?藉助貸款預測問題開始資料科學之旅。
結束教程
我希望本教程將幫助你在使用Python開展資料科學分析時能最大限度地提高效率。我相信,這不僅給你提供一個基本的資料分析方法的引導,而且還向你展示瞭如何實現一些更先進的程式設計技術。
Python真的是一個強大的工具,並且日益成為資料科學家中流行的程式語言。原因在於Python很容易學習,與其他資料庫和工具(如Spark和Hadoop)整合很好。最主要還是因為Python具有很強的計算能力和強大的資料分析庫。
學習利用Python來完成任何資料科學專案的完整過程包括閱讀、分析、視覺化和結果預測。
想加入資料人網Python,請加微信:luqin360。
公眾號推薦:
好又樂書屋,分享有益處,有趣味的內容,傳播正能量。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
