作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
我們知道普通的模型都是搭好架構,然後定義好 loss,直接扔給最佳化器訓練就行了。但是 GAN 不一樣,一般來說它涉及有兩個不同的 loss,這兩個 loss 需要交替最佳化。
現在主流的方案是判別器和生成器都按照 1:1 的次數交替訓練(各訓練一次,必要時可以給兩者設定不同的學習率,即 TTUR),交替最佳化就意味我們需要傳入兩次資料(從記憶體傳到視訊記憶體)、執行兩次前向傳播和反向傳播。
如果我們能把這兩步合併起來,作為一步去最佳化,那麼肯定能節省時間的,這也就是 GAN 的同步訓練。
註:本文不是介紹新的 GAN,而是介紹 GAN 的新寫法,這隻是一道程式設計題,不是一道演演算法題。
如果在TF中
如果是在 TensorFlow 中,實現同步訓練並不困難,因為我們定義好了判別器和生成器的訓練運算元了(假設為 D_solver 和 G_solver ),那麼直接執行:
sess.run([D_solver, G_solver], feed_dict={x_in: x_train, z_in: z_train})
就行了。這建立在我們能分別獲取判別器和生成器的引數、能直接操作 sess.run 的基礎上。
更通用的方法
但是如果是 Keras 呢?Keras 中已經把流程封裝好了,一般來說我們沒法去操作得如此精細。
所以,下麵我們介紹一個通用的技巧,只需要定義單一一個 loss,然後扔給最佳化器,就能夠實現 GAN 的訓練。同時,從這個技巧中,我們還可以學習到如何更加靈活地操作 loss 來控制梯度。
判別器的最佳化
我們以 GAN 的 hinge loss 為例子,它的形式是:

註意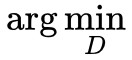 意味著要固定 G,因為 G 本身也是有最佳化引數的,不固定的話就應該是
意味著要固定 G,因為 G 本身也是有最佳化引數的,不固定的話就應該是![]() 。
。
為了固定G,除了“把 G 的引數從最佳化器中去掉”這個方法之外,我們也可以利用 stop_gradient 去手動固定:
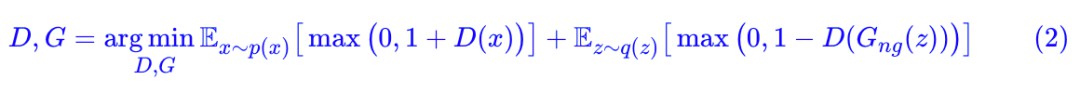
這裡:

這樣一來,在式 (2) 中,我們雖然同時放開了 D,G 的權重,但是不斷地最佳化式 (2),會變的只有 D,而 G 是不會變的,因為我們用的是基於梯度下降的最佳化器,而 G 的梯度已經被停止了,換句話說,我們可以理解為 G 的梯度被強行設定為 0,所以它的更新量一直都是 0。
生成器的最佳化
現在解決了 D 的最佳化,那麼 G 呢? stop_gradient 可以很方便地放我們固定裡邊部分的梯度(比如 D(G(z)) 的 G(z)),但 G 的最佳化是要我們去固定外邊的 D,沒有函式實現它。但不要灰心,我們可以用一個數學技巧進行轉化。
首先,我們要清楚,我們想要 D(G(z)) 裡邊的 G 的梯度,不想要 D 的梯度,如果直接對 D(G(z)) 求梯度,那麼同時會得到 D,G 的梯度。如果直接求 的梯度呢?只能得到 D 的梯度,因為 G 已經被停止了。那麼,重點來了,將這兩個相減,不就得到單純的 G 的梯度了嗎!
的梯度呢?只能得到 D 的梯度,因為 G 已經被停止了。那麼,重點來了,將這兩個相減,不就得到單純的 G 的梯度了嗎!
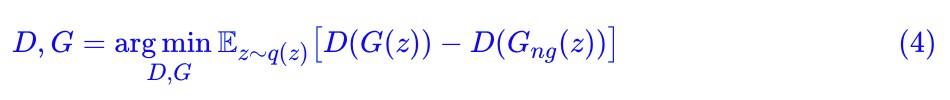
現在最佳化式 (4) ,那麼 D 是不會變的,改變的是 G。
值得一提的是,直接輸出這個式子,結果是恆等於 0,因為兩部分都是一樣的,直接相減自然是 0,但它的梯度不是 0。也就是說,這是一個恆等於 0 的 loss,但是梯度卻不恆等於 0。
合成單一loss
好了,現在式 (2) 和式 (4) 都同時放開了 D,G,大家都是 arg min,所以可以將兩步合成一個 loss:

寫出這個 loss,就可以同時完成判別器和生成器的優化了,而不需要交替訓練,但是效果基本上等效於 1:1 的交替訓練。引入 λ 的作用,相當於讓判別器和生成器的學習率之比為 1:λ。
參考程式碼:
https://github.com/bojone/gan/blob/master/gan_one_step_with_hinge_loss.py
文章小結
文章主要介紹了實現 GAN 的一個小技巧,允許我們只寫單個模型、用單個 loss 就實現 GAN 的訓練。它本質上就是用 stop_gradient 來手動控制梯度的技巧,在其他任務上也可能用得到它。
所以,以後我寫 GAN 都用這種寫法了,省力省時。當然,理論上這種寫法需要多耗些視訊記憶體,這也算是犧牲空間換時間吧。
