
導讀:我們介紹過用matplotlib製作圖表的一些tips,感興趣的同學可以戳→純乾貨:手把手教你用Python做資料視覺化(附程式碼)。matplotlib是一個相當底層的工具。你可以從其基本元件中組裝一個圖表:資料顯示(即繪圖的型別:線、條、框、散點圖、輪廓等)、圖例、標題、刻度標記和其他註釋。
在pandas中,我們可能有多個資料列,並且帶有行和列的標簽。pandas自身有很多內建方法可以簡化從DataFrame和Series物件生成視覺化的過程。另一個是seaborn,它是由Michael Waskom建立的統計圖形庫。seaborn簡化了很多常用視覺化型別的生成。
匯入seaborn會修改預設的matplotlib配色方案和繪圖樣式,這會提高圖表的可讀性和美觀性。即使你不適用seaborn的API,你可能更喜歡匯入seaborn來為通用matplotlib圖表提供更好的視覺美觀度。
作者:Wes McKinney
本文摘編自《利用Python進行資料分析》(原書第2版),如需轉載請聯絡我們
01 折線圖
Series和DataFrame都有一個plot屬性,用於繪製基本的圖型。預設情況下,plot()繪製的是折線圖(見圖9-13):
In [60]: s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))In [61]: s.plot()
▲圖9-13 簡單序列圖形
Series物件的索引傳入matplotlib作為繪圖的x軸,你可以透過傳入use_index=False來禁用這個功能。x軸的刻度和範圍可以透過xticks和xlim選項進行調整,相應地y軸使用yticks和ylim進行調整。表9-3是plot的全部選項串列。本節我會介紹這些選項中的一些,其餘你可以自行探索。
大部分pandas的繪圖方法,接收可選的ax引數,該引數可以是一個matplotlib子圖物件。這使你可以更為靈活的在網格佈局中放置子圖。
DataFrame的plot方法在同一個子圖中將每一列繪製為不同的折線,並自動生成圖例(見圖9-14):
In [62]: df = pd.DataFrame(np.random.randn(10, 4).cumsum(0),....: columns=['A', 'B', 'C', 'D'],....: index=np.arange(0, 100, 10))In [63]: df.plot()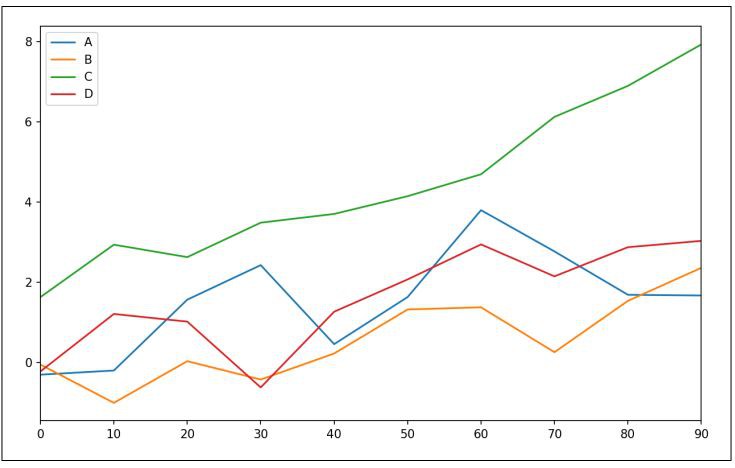
▲圖9-14 簡單DataFrame繪圖
plot屬性包含了不同繪圖型別的方法族。例如,df.plot( )等價於df.plot.line( )。我們之後將會探索這些方法中的一部分。
要繪製的其他關鍵字引數會傳遞到相應的matplotlib繪圖函式,因此你可以透過瞭解更多的matplotlib的 API資訊來進一步定製這些圖表。
|
引數 |
描述 |
|
label |
圖例標簽 |
|
ax |
繪圖所用的matplotlib子圖物件;如果沒傳值,則使用當前活動的matplotlib子圖 |
|
style |
傳給matplotlib的樣式字串,比如‘ko–‘ |
|
alpha |
圖片不透明度(從0到1) |
|
kind |
可以是 ‘area’、 ‘bar’、 ‘barh’、 ‘density’、‘hist’、 ‘kde’、 ‘line’、 ‘pie’ |
|
logy |
在y軸上使用對數縮放 |
|
use_index |
使用物件索引刻度標簽 |
|
rot |
刻度標簽的旋轉(0到360) |
|
xticks |
用於x軸刻度的值 |
|
yticks |
用於y軸 |
|
xlim |
x軸範圍(例如[0,10]) |
|
ylim |
y軸範圍 |
|
grid |
展示軸網格(預設是開啟的) |
▲表9-3 Series.plot方法引數
DataFrame擁有多個選項,允許靈活地處理列;例如,是否將各列繪製到同一個子圖中,或為各列生成獨立的子圖。參考表9-4瞭解更多選項。
|
引數 |
描述 |
|
subplots |
將DataFrame的每一列繪製在獨立的子圖中 |
|
sharex |
如果subplots=True,則共享相同的x軸、刻度和範圍 |
|
sharey |
如果subplots=True,則共享相同的y軸 |
|
figsize |
用於生成圖片尺寸的元組 |
|
title |
標題字串 |
|
legend |
新增子圖圖例(預設是True) |
|
sort_columns |
按字母順序繪製各列,預設情況下使用已有的列順序 |
▲表9-4
02 柱狀圖
plot.bar()和plot.barh()可以分別繪製垂直和水平的柱狀圖。在繪製柱狀圖時,Series或DataFrame的索引將會被用作x軸刻度(bar)或y軸刻度(barh)(參考圖9-15):
In [64]: fig, axes = plt.subplots(2, 1)In [65]: data = pd.Series(np.random.rand(16), index=list('abcdefghijklmnop'))In [66]: data.plot.bar(ax=axes[0], color='k', alpha=0.7)Out[66]: 0x7fb62493d470>In [67]: data.plot.barh(ax=axes[1], color='k', alpha=0.7)
▲圖9-15 水平柱狀圖和垂直柱狀圖
選項color=’k’和alpha=0.7將柱子的顏色設定為黑色,並將影象的填充色設定為部分透明。
在DataFrame中,柱狀圖將每一行中的值分組到併排的柱子中的一組。參考圖9-16:
In [69]: df = pd.DataFrame(np.random.rand(6, 4),....: index=['one', 'two', 'three', 'four', 'five', 'six'],....: columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus'))In [70]: dfOut[70]:Genus A B C Done 0.370670 0.602792 0.229159 0.486744two 0.420082 0.571653 0.049024 0.880592three 0.814568 0.277160 0.880316 0.431326four 0.374020 0.899420 0.460304 0.100843five 0.433270 0.125107 0.494675 0.961825six 0.601648 0.478576 0.205690 0.560547In [71]: df.plot.bar()
▲圖9-16 DataFrame柱狀圖
請註意DataFrame的列名稱”Genus”被用作了圖例標題。我們可以透過傳遞stacked=True來生成堆積柱狀圖,會使得每一行的值堆積在一起(參考圖9-17):
In [73]: df.plot.barh(stacked=True, alpha=0.5)
▲圖9-17 DataFrame堆積柱狀圖
使用value_counts: s.value_counts().plot.bar()可以有效的對Series值頻率進行視覺化。
回到本書之前使用的資料集,假設我們想要繪製一個堆積柱狀圖,用於展示每個派對在每天的資料點佔比。使用read_csv載入資料,並根據星期幾數值和派對規模進形成交叉表:
In [75]: tips = pd.read_csv('examples/tips.csv')In [76]: party_counts = pd.crosstab(tips['day'], tips['size'])In [77]: party_countsOut[77]:size 1 2 3 4 5 6dayFri 1 16 1 1 0 0Sat 2 53 18 13 1 0Sun 0 39 15 18 3 1Thur 1 48 4 5 1 3# 沒有太多的1人和6人派對In [78]: party_counts = party_counts.loc[:, 2:5]之後,進行標準化以確保每一行的值和為1,然後進行繪圖(見圖9-18):
# 標準化至和為1In [79]: party_pcts = party_counts.div(party_counts.sum(1), axis=0)In [80]: party_pctsOut[80]:size 2 3 4 5dayFri 0.888889 0.055556 0.055556 0.000000Sat 0.623529 0.211765 0.152941 0.011765Sun 0.520000 0.200000 0.240000 0.040000Thur 0.827586 0.068966 0.086207 0.017241In [81]: party_pcts.plot.bar()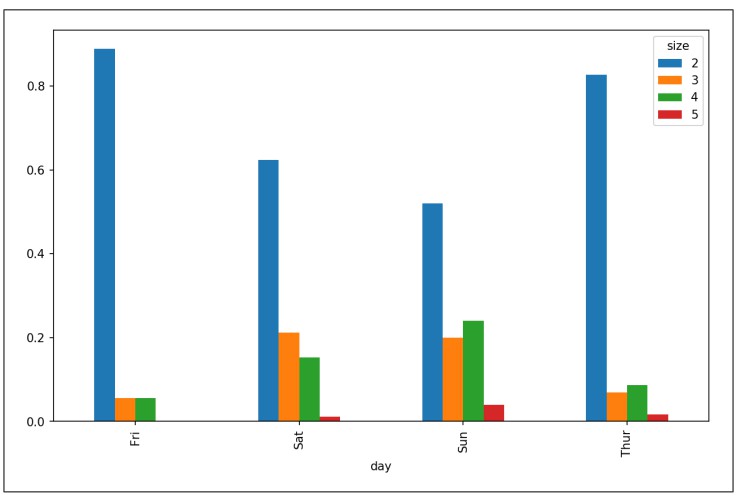
▲圖9-18 每天派對數量的百分比
你可以看到本資料集中的派對數量在週末會增加。
對於在繪圖前需要聚合或彙總的資料,使用seaborn包會使工作更為簡單。現在讓我們看下使用seaborn進行按星期幾數值計算小費百分比(見圖9-19中的結果圖):
In [83]: import seaborn as snsIn [84]: tips['tip_pct'] = tips['tip'] / (tips['total_bill'] - tips['tip'])In [85]: tips.head()Out[85]:total_bill tip smoker day time size tip_pct0 16.99 1.01 No Sun Dinner 2 0.0632041 10.34 1.66 No Sun Dinner 3 0.1912442 21.01 3.50 No Sun Dinner 3 0.1998863 23.68 3.31 No Sun Dinner 2 0.1624944 24.59 3.61 No Sun Dinner 4 0.172069In [86]: sns.barplot(x='tip_pct', y='day', data=tips, orient='h')
▲圖9-19 用錯誤欄按天顯示小費百分比
seaborn中的繪圖函式使用一個data引數,這個引數可以是pandas的DataFrame。其他的引數則與列名有關。因為day列中有多個觀測值,柱子的值是tip_pct的平均值。柱子上畫出的黑線代表的是95%的置信區間(置信區間可以透過可選引數進行設定)。
seaborn.barplot擁有一個hue選項,允許我們透過一個額外的分類值將資料分離:
In [88]: sns.barplot(x='tip_pct', y='day', hue='time', data=tips, orient='h')
▲圖9-20 根據星期幾數值和時間計算的小費百分比
請註意seaborn自動改變了圖表的美觀性:預設的調色盤、圖背景和網格線條顏色。你可以使用seaborn.set在不同的繪圖外觀中進行切換:
In [90]: sns.set(style="whitegrid")03 直方圖和密度圖
直方圖是一種條形圖,用於給出值頻率的離散顯示。資料點被分成離散的,均勻間隔的箱,並且繪製每個箱中資料點的數量。使用之前的小費資料,我們可以使用Series的plot.hist方法製作小費佔總費用百分比的直方圖(見圖9-21):
In [92]: tips['tip_pct'].plot.hist(bins=50)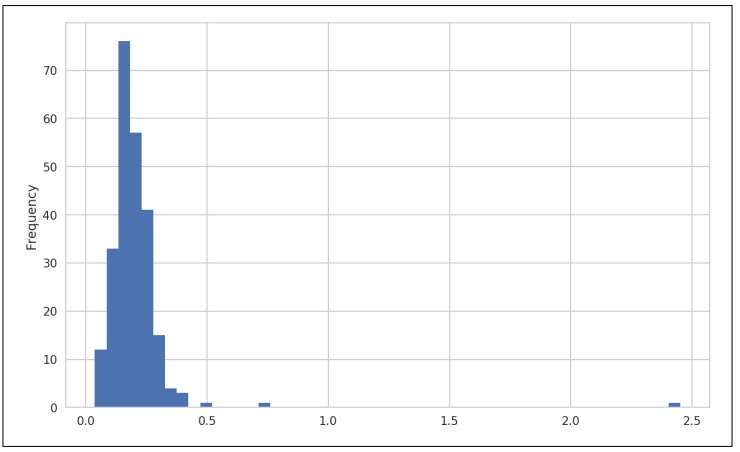
▲圖9-21 小費百分比的直方圖
密度圖是一種與直方圖相關的圖表型別,它透過計算可能產生觀測資料的連續機率分佈估計而產生。通常的做法是將這種分佈近似為“核心”的混合,也就是像正態分佈那樣簡單的分佈。因此,密度圖也被成為核心密度估計圖(KDE)。plot.kde使用傳統法定混合法估計繪製密度圖(見圖9-22):
In [94]: tips['tip_pct'].plot.density()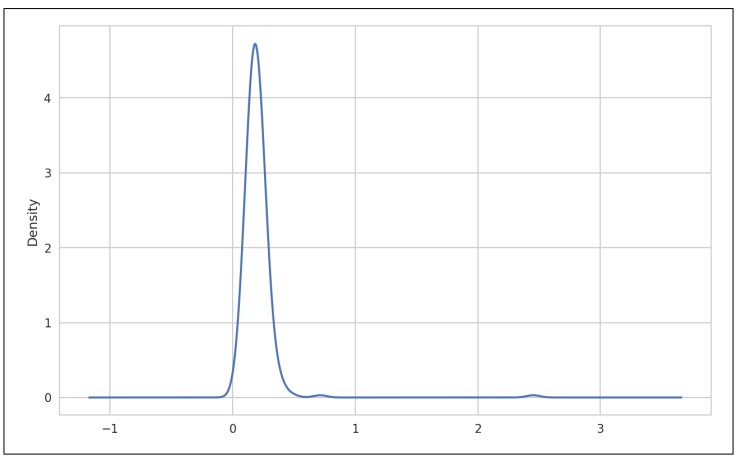
▲圖9-22 小費百分比密度圖
distplot方法可以繪製直方圖和連續密度估計,透過distplot方法seaborn使直方圖和密度圖的繪製更為簡單。作為例子,考慮由兩個不同的標準正態分佈組成的雙峰分佈(見圖9-23):
In [96]: comp1 = np.random.normal(0, 1, size=200)In [97]: comp2 = np.random.normal(10, 2, size=200)In [98]: values = pd.Series(np.concatenate([comp1, comp2]))In [99]: sns.distplot(values, bins=100, color='k')
▲圖9-23 正態混合的標準化直方圖與密度估計
04 散點圖或點圖
點圖或散點圖可以用於檢驗兩個一維資料序列之間的關係。例如,這裡我們從statsmodels專案中載入了macrodata資料集,並選擇了一些變數,之後計算對數差:
In [100]: macro = pd.read_csv('examples/macrodata.csv')In [101]: data = macro[['cpi', 'm1', 'tbilrate', 'unemp']]In [102]: trans_data = np.log(data).diff().dropna()In [103]: trans_data[-5:]Out[103]:cpi m1 tbilrate unemp198 -0.007904 0.045361 -0.396881 0.105361199 -0.021979 0.066753 -2.277267 0.139762200 0.002340 0.010286 0.606136 0.160343201 0.008419 0.037461 -0.200671 0.127339202 0.008894 0.012202 -0.405465 0.042560然後我們可以使用seaborn的reglot方法,該方法可以繪製散點圖,並擬合出一個條線性回歸線(見圖9-24):
In [105]: sns.regplot('m1', 'unemp', data=trans_data)Out[105]: 0x7fb613720be0>In [106]: plt.title('Changes in log %s versus log %s' % ('m1', 'unemp'))
▲圖9-24 seaborn回歸/散點圖
在探索性資料分析中,能夠檢視一組變數中的所有散點圖是有幫助的; 這被稱為成對圖或散點圖矩陣。從頭開始繪製這樣一個圖是有點工作量的,所以seaborn有一個方便的成對圖函式,它支援在對角線上放置每個變數的直方圖或密度估計值(結果圖見圖9-25):
In [107]: sns.pairplot(trans_data, diag_kind='kde', plot_kws={'alpha': 0.2})
▲圖9-25 statsmodels macro資料的成對圖矩陣
你可能會註意到plot_ksw引數,這個引數使我們能夠將配置選項傳遞給非對角元素上的各個繪圖呼叫。參考seaborn.pairplot的檔案字串可以看到更多細節的設定選項。
05 分面網格和分類資料
如果資料集有額外的分組維度怎麼辦?使用分面網格是利用多種分組變數對資料進行視覺化的方式。seaborn擁有一個有效的內建函式factorplot,可以簡化多種分面繪圖(見圖9-26):
In [108]: sns.factorplot(x='day', y='tip_pct', hue='time', col='smoker',.....: kind='bar', data=tips[tips.tip_pct 1])
▲圖9-26 按星期幾數值/時間/是否吸煙劃分的小費百分比
除了根據’time’在一個面內將不同的柱分組為不同的顏色,我們還可以透過每個時間值新增一行來擴充套件分面網格(見圖9-27):
In [109]: sns.factorplot(x='day', y='tip_pct', row='time',.....: col='smoker',.....: kind='bar', data=tips[tips.tip_pct 1])
▲圖9-27 根據時間/是否吸煙分面後按星期幾數值劃分的小費百分比
factorplot 支援其他可能有用的圖型別,具體取決於你要顯示的內容。 例如,箱形圖(顯示中位值,四分位數和異常值)可以是有效的視覺化型別(圖9-28):
In [110]: sns.factorplot(x='tip_pct', y='day', kind='box',.....: data=tips[tips.tip_pct 0.5])
▲圖9-28 根據星期幾數值繪製的小費百分比箱型圖
你可以使用更通用的seaborn.FacetGrid類建立自己的分面網格圖。 具體請檢視更多的seaborn檔案。
06 其他Python視覺化工具
和開原始碼一樣,在Python語言下建立圖形的選擇有很多(太多而無法一一列舉)。自從2010年以來,很多開發工作都集中在建立web互動式圖形上。藉助像Bokeh和Plotly這樣的工具,在web瀏覽器中建立動態的、互動式影象的工作現在已經可以實現。
如果是建立用於印刷或網頁的靜態圖形,我建議根據你的需要使用預設的matplotlib以及像pandas和seaborn這樣的附加庫。 對於其他資料視覺化要求,學習其他可用工具之一可能是有用的。我鼓勵你探索Python視覺化生態系統,因為它將持續增添新內容併在未來進行更多創新。
關於作者:韋斯·麥金尼(Wes McKinney)是流行的Python開源資料分析庫pandas的創始人。他是一名活躍的演講者,也是Python資料社群和Apache軟體基金會的Python/C++開源開發者。目前他在紐約從事軟體架構師工作。
本文摘編自《利用Python進行資料分析》(原書第2版),經出版方授權釋出。

延伸閱讀《利用Python進行資料分析》
點選上圖瞭解及購買
轉載請聯絡微信:togo-maruko
推薦語:Python資料分析經典暢銷書全新升級,第1版中文版累計銷售100000冊。針對Python 3.6進行全面修訂和更新,涵蓋新版的pandas、NumPy、IPython和Jupyter。

更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單
Python | 機器學習 | 深度學習 | 神經網路
區塊鏈 | 揭秘 | 乾貨 | 數學
猜你想看
Q: 你還知道哪些資料視覺化技巧?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

 點選閱讀原文,瞭解更多
點選閱讀原文,瞭解更多
