
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @jamiechoi。本文提出了一種將對比學習(CL)用於 Image Captioning 的方法,透過在參考模型上設立兩個約束,鼓勵獨特性,從而提高標記質量。
如果你對本文工作感興趣,點選底部的閱讀原文即可檢視原論文。
關於作者:蔡文傑,華南理工大學碩士生,研究方向為Image Caption。
■ 論文 | Contrastive Learning for Image Captioning
■ 連結 | https://www.paperweekly.site/papers/1344
■ 原始碼 | https://github.com/doubledaibo/clcaption_nips2017
論文動機
本文提出的 Contrastive Learning (CL) 主要是為瞭解決 Image Caption 任務中生成的 Caption 缺少 Distinctiveness 的問題。
這裡的 Distinctiveness 可以理解為獨特性,指的是對於不同的圖片,其 caption 也應該是獨特的、易於區分的。即在所有圖片中,這個 caption 與這幅圖片的匹配度是最高的。
然而現在大多數的模型生成的 caption 都非常死板,尤其是對於那些屬於同一類的圖片,所生成的 caption 都非常相似,而且 caption 並沒有描述出這些圖片在其他方面的差異。
Empirical Study
文章提出了一個 self-retrieval study,來展示缺少 Distinctiveness 的問題。作者從 MSCOCO test set 上隨機選取了 5000 張圖片 I1,…I5000,並且用訓練好的 Neuraltalk2 和 AdaptiveAttention 分別對這些圖片生成對應的 5000 個 caption c1,…,c5000。
用 pm(:,θ) 表示模型,對於每個 caption ct,計算其對於所有圖片的條件機率 pm(ct|I1),…,pm(ct|I5000),然後對這些機率做一個排序,看這個 caption 對應的原圖片是否在這些排序後的結果的 top-k 個裡,具體可見下圖。

可見加入了 CL 來訓練以後,模型的查詢準確率明顯提高了,並且 ROUGE_L 以及 CIDEr 的分數也提高了,準確度與這兩個評價標準的分數呈正相關關係。這說明提高 Distinctiveness 是可以提高模型的 performance 的。
Contrastive Learning
先介紹通常使用 Maximum Likelihood Estimation (MLE) 訓練的方式,這裡借用 show and tell 論文裡面的圖:
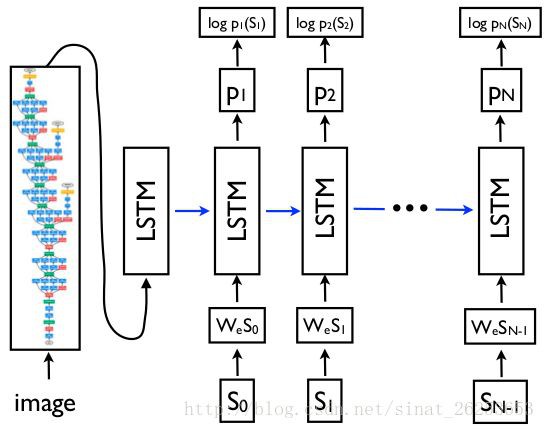
輸入一副圖片以後,我們會逐個地得到下一個標的單詞的機率 pt(St),我們需要最大化這個機率,而訓練標的則透過最小化 來實現這一標的。
來實現這一標的。
而使用 MLE 訓練會導致缺少 Distinctiveness 的問題,作者在他之前的文章 Towards Diverse and Natural Image Descriptions via a Conditional GAN 裡面已經解釋過了,大家可以讀一讀。
CL 的中心思想是以一個參考模型 (reference model,如 state-of-the-art 的模型,本文以 Neuraltalk2 和 AdaptiveAttention 為例) 作為 baseline,在此基礎上提高 Distinctiveness,同時又能保留其生成 caption 的質量。參考模型在訓練過程中是固定的。
CL 同時還需要正樣本和負樣本作為輸入,正負樣本都是圖片與 ground-truth caption 的 pair,只不過正樣本的 caption 與圖片是匹配的;而負樣本雖然圖片與正樣本相同,但 caption 卻是描述其他圖片的。
具體符號:
-
標的模型 target model:pm(:,θ)
-
參考模型 reference model:pn(:,ϕ)
-
正樣本 ground-truth pairs: X=((c1,I1),…,(cTm,ITm))
-
負樣本 mismatched pairs: Y=((c/1,I1),…,(c/Tn,ITn))
標的模型和參考模型都對所有樣本給出其估計的條件機率 pm(c|I,θ) 和 pn(c|I,θ),這裡的 pm(c|I,θ) 應該是輸入圖片後,依次輸入 caption 中的單詞S0,…,SN−1,並且依次把得到的下一個標的單詞機率 p1(S1),…,pN(SN) 相乘所得到的。結合上圖看會更清晰。
並且希望對於所有正樣本來說,pm(c|I,θ) 大於 pn(c|I,θ);對於所有負樣本,pm(c|I,θ) 小於 pn(c|I,θ)。意思就是標的模型對於正樣本要給出比參考模型更高的條件機率,對於負樣本要給出比參考模型更低的條件機率。
定義 pm(c|I,θ) 和 pn(c|I,θ) 的差為 D((c,I);θ,ϕ)=pm(c|I,θ)−pn(c|I,θ),而 loss function 為:

這裡應該是最大化 loss 進行求解。
然而實際上這裡會遇到幾個問題:
首先 pm(c|I,θ) 和 pn(c|I,θ) 都非常小(~ 1e-8),可能會產生 numerical problem。因此分別對 pm(c|I,θ) 和 pn(c|I,θ) 取對數,用 G((c,I);θ,ϕ)=lnpm(c|I,θ)−lnpn(c|I,θ) 來取代 D((c,I);θ,ϕ)。
其次,由於負樣本是隨機取樣的,不同的正負樣本所產生的 D((c,I);θ,ϕ) 大小也不一樣,有些 D 可能遠遠大於 0,有些 D 則比較小。
而在最大化 loss 的過程中更新較小的 D 則更加有效,因此作者使用了一個 logistic function (其實就是 sigmoid) ,來 saturate 這些影響,其中 ν=Tn/Tm, 並且 Tn=Tm 來平衡正負樣本的數量。
,來 saturate 這些影響,其中 ν=Tn/Tm, 並且 Tn=Tm 來平衡正負樣本的數量。
因此,D((c,I);θ,ϕ) 又變成了:h((c,I);θ,ϕ)=rν(G((c,I);θ,ϕ)))。
由於 h((c,I);θ,ϕ)∈(0,1),於是 loss function 變成了:

等式的第一項保證了 ground-truth pairs 的機率,第二項抑制了 mismatched pairs 的機率,強制模型學習出 Distinctiveness。
另外,本文把 X 複製了 K 次,來對應 K 個不同的負樣本 Y,這樣可以防止過擬合,文中選擇 K=5。
最終的 loss function:

以上的這些變換的主要受 Noise Contrastive Estimation (NCE) 的啟發。
理想情況下,當正負樣本能夠被完美分辨時,J(θ)的上界是 0。即標的模型會對正樣本 p(ct|It) 給出高機率,負樣本 p(c/t|It) 給出低機率。
此時:
G((ct,It);θ,ϕ)=→∞,G((c/t,It);θ,ϕ)→−∞, h((ct,It);θ,ϕ)=1,h((c/t,It);θ,ϕ)=0, J(θ) 取得上界 0。
但實際上,當標的模型對正樣本給出最高機率 1 時,我認為 G((ct,It);θ,ϕ) 應該等於 lnpn(c|I,θ),因此 h((ct,It);θ,ϕ)<1,J(θ) 的上界應該是小於 0 的。
實驗結果
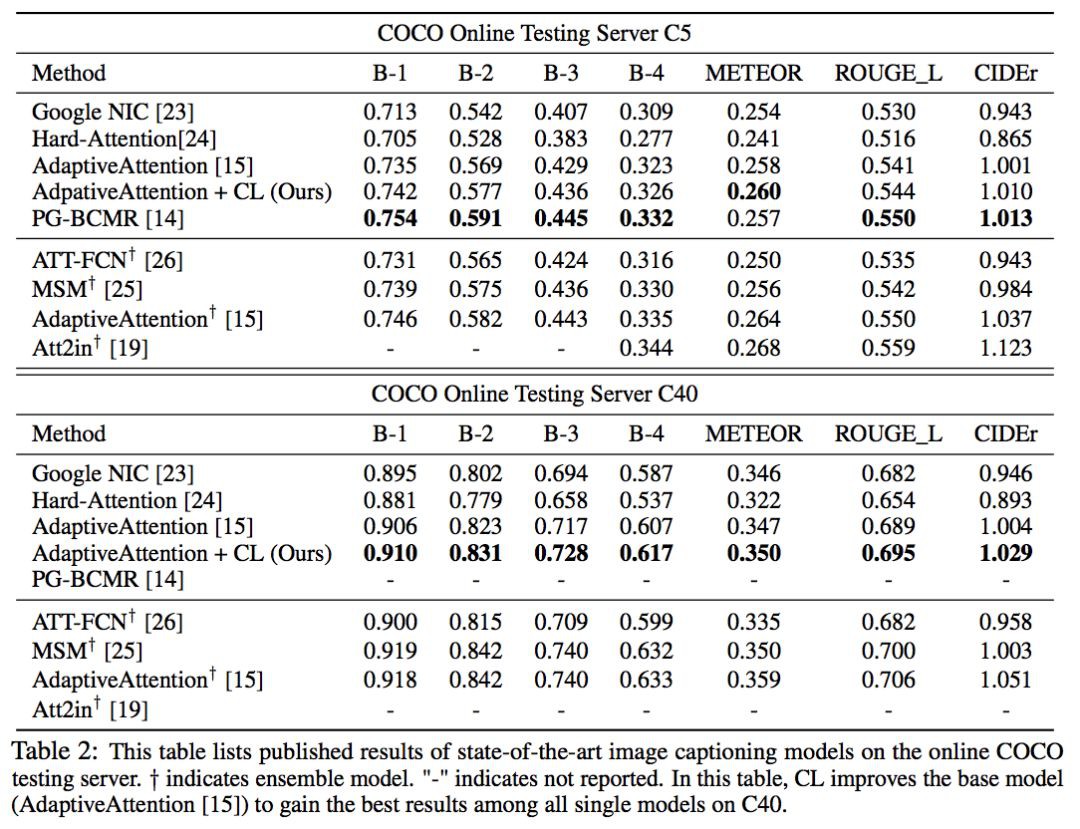
如上圖,可以看到,加入 CL 以後,模型的表現有較大提升。

上圖為 CL 與原模型的一些視覺化結果。
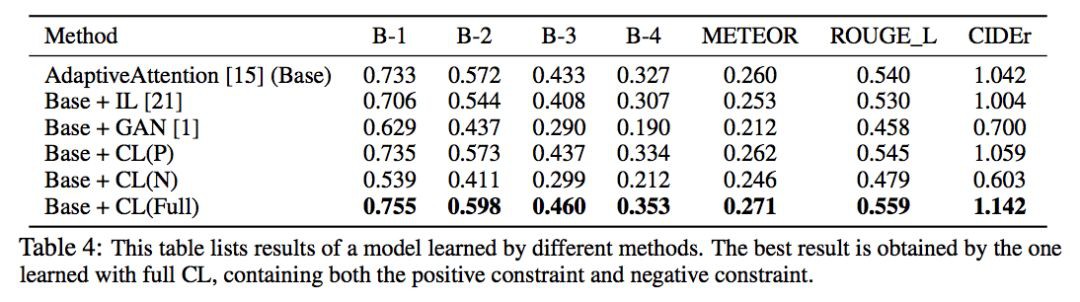
文章還對比了 CL 跟 GAN、IL (Introspective Learning) 之間的區別:
-
IL 把 target model 自身作為 reference,並且是透過比較 (I,c),(I/,c) 來進行學習的。 IL 的負樣本 (I/,c) 通常是預定義且固定的,而 CL 的負樣本則是動態取樣的。
-
GAN 中的 evaluator 直接測量 Distinctiveness,而不能保證其準確性。
另外,加入 IL 和 GAN 後模型的準確性都有所下降,說明模型為了提高 Distinctiveness 而犧牲了準確性。但 CL 在保持準確性的同時又能提高 Distinctiveness。
上圖還對比了分別隻有正負樣本的訓練情況,可以看到:
-
只有正樣本的情況下模型的表現只稍微提升了一些。我認為,這是因為參考模型給出的機率是恆定的,去掉負樣本以後的損失函式就相當於 MLE 的損失函式再減去一個常數,與 MLE 是等價的,因此相當於在原來的模型的基礎上多進行了一些訓練。
-
只有負樣本的情況下模型的表現是大幅下降的(因為沒有指定正樣本,且負樣本是隨機抽取的)。
而只有兩個樣本都參與訓練的時候能給模型帶來很大的提升。
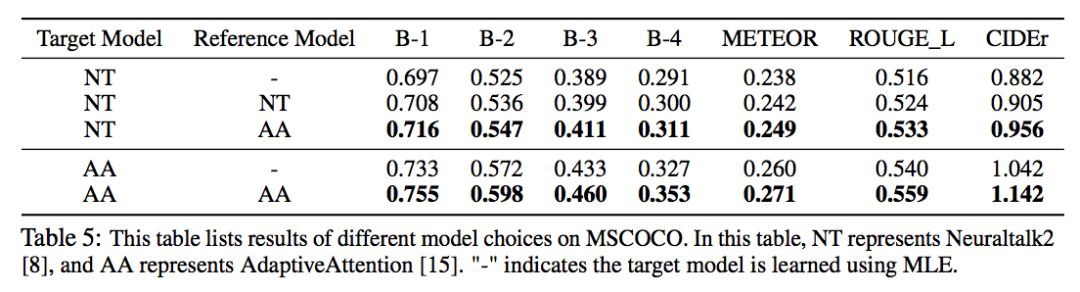
上圖測試了 CL 的泛化能力,可以看到,透過選擇更好的模型(AA)作為 reference,NT 的提升更大。(但是卻沒有超過 AA 本身,按理說不是應該比 reference 模型更好嗎?)

另外,還可以透過週期性地以訓練好的標的模型作為更好的參考模型,來提升模型的下界。然而在 Run 2 進行第二次替換的時候提升已經不大,證明沒有必要多次替換。
總結
總的來說,本文主要的貢獻在於提出了 Contrastive Learning 的方法,構造損失函式利用了負樣本來參與訓練,提高模型的 Distinctiveness。另外本文提出的 self-retrieval 實驗思路在同類論文裡也是挺特別的。
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

 #榜 單 公 布 #
#榜 單 公 布 #
2017年度最值得讀的AI論文 | NLP篇 · 評選結果公佈
2017年度最值得讀的AI論文 | CV篇 · 評選結果公佈
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot01)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視論文 & 原始碼