

每當提到機器學習,大家總是被其中的各種各樣的演演算法和方法搞暈,覺得無從下手。確實,機器學習的各種套路確實不少,但是如果掌握了正確的路徑和方法,其實還是有跡可循的,這裡我推薦SAS的Li Hui的這篇部落格,講述瞭如何選擇機器學習的各種方法。
另外,Scikit-learn 也提供了一幅清晰的路線圖給大家選擇:

其實機器學習的基本演演算法都很簡單,下麵我們就利用二維資料和互動圖形來看看機器學習中的一些基本演演算法以及它們的原理。(另外向Bret Victor致敬,他的 Inventing on principle 深深的影響了我)。
所有的程式碼即演示可以在我的Codepen的這個Collection中找到。
首先,機器學習最大的分支的監督學習和無監督學習,簡單說資料已經打好標簽的是監督學習,而資料沒有標簽的是無監督學習。從大的分類上看,降維和聚類被劃在無監督學習,回歸和分類屬於監督學習。
無監督學習
如果你的資料都沒有標簽,你可以選擇花錢請人來標註你的資料,或者使用無監督學習的方法。首先你可以考慮是否要對資料進行降維。
降維
降維顧名思義就是把高維度的資料變成為低維度。常見的降維方法有PCA、LDA、SVD等。
主成分分析 PCA
降維裡最經典的方法是主成分分析PCA,也就是找到資料的主要組成成分,拋棄掉不重要的成分。

這裡我們先用滑鼠隨機生成8個資料點,然後繪製出表示主成分的白色直線。這根線就是二維資料降維後的主成分,藍色的直線是資料點在新的主成分維度上的投影線,也就是垂線。主成分分析的數學意義可以看成是找到這根白色直線,使得投影的藍色線段的長度的和為最小值。
聚類
因為在非監督學習的環境下,資料沒有標簽,那麼能對資料所做的最好的分析除了降維,就是把具有相同特質的資料歸併在一起,也就是聚類。
層級聚類 Hierachical Cluster
該聚類方法用於構建一個擁有層次結構的聚類
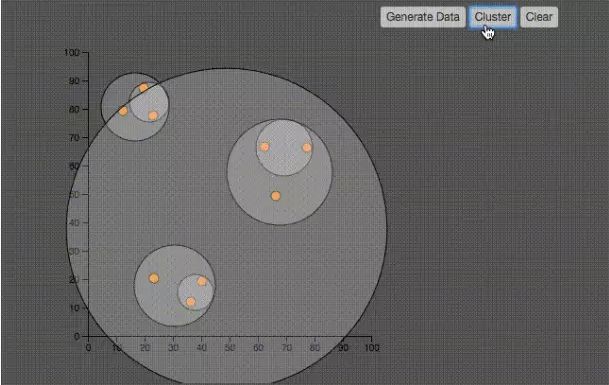
如上圖所示,層級聚類的演演算法非常的簡單
-
1、初始時刻,所有點都自己是一個聚類
-
2、找到距離最近的兩個聚類(剛開始也就是兩個點),形成一個聚類
-
3、兩個聚類的距離指的是聚類中最近的兩個點之間的距離
-
4、重覆第二步,直到所有的點都被聚集到聚類中。
KMeans
KMeans中文翻譯K均值演演算法,是最常見的聚類演演算法。

-
1、隨機在圖中取K(這裡K=3)個中心種子點。
-
2、然後對圖中的所有點求到這K個中心種子點的距離,假如點P離中心點S最近,那麼P屬於S點的聚類。
-
3、接下來,我們要移動中心點到屬於他的“聚類”的中心。
-
4、然後重覆第2和第3步,直到,中心點沒有移動,那麼演演算法收斂,找到所有的聚類。
KMeans演演算法有幾個問題:
-
1.如何決定K值,在上圖的例子中,我知道要分三個聚類,所以選擇K等於3,然而在實際的應用中,往往並不知道應該分成幾個類
-
2.由於中心點的初始位置是隨機的,有可能並不能正確分類,大家可以在我的Codepen中嘗試不同的資料
-
3.如下圖,如果資料的分佈在空間上有特殊性,KMeans演演算法並不能有效的分類。中間的點被分別歸到了橙色和藍色,其實都應該是藍色。

DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)中文是基於密度的聚類演演算法。DBSCAN演演算法基於一個事實:一個聚類可以由其中的任何核心物件唯一確定。演演算法的具體聚類過程如下:
-
1、掃描整個資料集,找到任意一個核心點,對該核心點進行擴充。擴充的方法是尋找從該核心點出發的所有密度相連的資料點(註意是密度相連)。
-
2、遍歷該核心點的鄰域內的所有核心點(因為邊界點是無法擴充的),尋找與這些資料點密度相連的點,直到沒有可以擴充的資料點為止。最後聚類成的簇的邊界節點都是非核心資料點。
-
3、之後就是重新掃描資料集(不包括之前尋找到的簇中的任何資料點),尋找沒有被聚類的核心點,再重覆上面的步驟,對該核心點進行擴充直到資料集中沒有新的核心點為止。資料集中沒有包含在任何簇中的資料點就構成異常點。
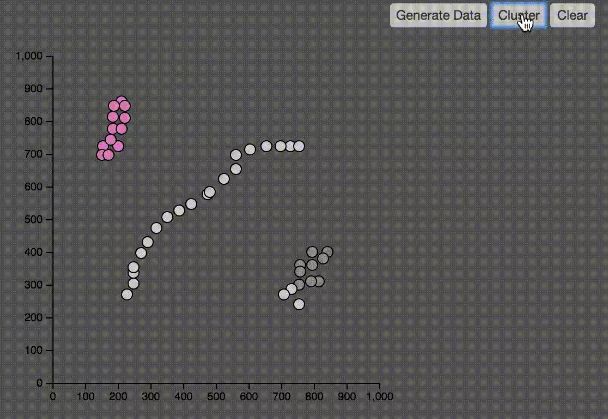
如上圖所示,DBSCAN可以有效的解決KMeans不能正確分類的資料集。並且不需要知道K值。當然,DBCSAN還是要決定兩個引數,如何決定這兩個引數是分類效果的關鍵因素:
-
1、一個引數是半徑(Eps),表示以給定點P為中心的圓形鄰域的範圍;
-
2、另一個引數是以點P為中心的鄰域內最少點的數量(MinPts)。如果滿足:以點P為中心、半徑為Eps的鄰域內的點的個數不少於MinPts,則稱點P為核心點。
監督學習
監督學習中的資料要求具有標簽。也就是說針對已有的結果去預測新出現的資料。如果要預測的內容是數值型別,我們稱作回歸,如果要預測的內容是類別或者是離散的,我們稱作分類。
其實回歸和分類本質上是類似的,所以很多的演演算法既可以用作分類,也可以用作回歸。
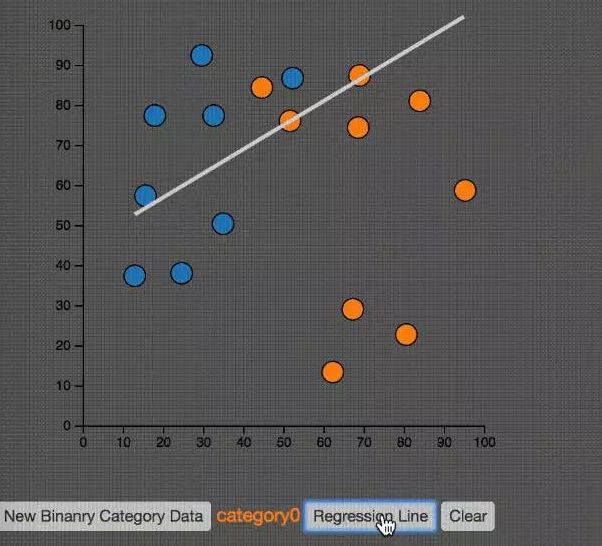
線性回歸
線性回歸是最經典的回歸演演算法。在統計學中,線性回歸(Linear regression)是利用稱為線性回歸方程的最小二乘函式對一個或多個自變數和因變數之間關係進行建模的一種回歸分析。
這種函式是一個或多個稱為回歸繫數的模型引數的線性組合。 只有一個自變數的情況稱為簡單回歸,大於一個自變數情況的叫做多元回歸。

如上圖所示,線性回歸就是要找到一條直線,使得所有的點預測的失誤最小。也就是圖中的藍色直線段的和最小。這個圖很像我們第一個例子中的PCA。仔細觀察,分辨它們的區別。
如果對於演演算法的的準確性要求比較高,推薦的回歸演演算法包括:隨機森林,神經網路或者Gradient Boosting Tree。如果要求速度優先,建議考慮決策樹和線性回歸。
分類
支援向量機 SVM,如果對於分類的準確性要求比較高,可使用的演演算法包括Kernel SVM,隨機森林,神經網路以及Gradient Boosting Tree。
給定一組訓練實體,每個訓練實體被標記為屬於兩個類別中的一個或另一個,SVM訓練演演算法建立一個將新的實體分配給兩個類別之一的模型,使其成為非機率二元線性分類器。
SVM模型是將實體表示為空間中的點,這樣對映就使得單獨類別的實體被盡可能寬的明顯的間隔分開。然後,將新的實體對映到同一空間,並基於它們落在間隔的哪一側來預測所屬類別。

如上圖所示,SVM演演算法就是在空間中找到一條直線,能夠最好的分割兩組資料。使得這兩組資料到直線的距離的絕對值的和盡可能的大。

上圖示意了不同的核方法的不同分類效果。
決策樹
如果要求分類結果是可以解釋的,可以考慮決策樹或者邏輯回歸。決策樹(decision tree)是一個樹結構(可以是二叉樹或非二叉樹)。
其每個非葉節點表示一個特徵屬性上的測試,每個分支代表這個特徵屬性在某個值域上的輸出,而每個葉節點存放一個類別。
使用決策樹進行決策的過程就是從根節點開始,測試待分類項中相應的特徵屬性,並按照其值選擇輸出分支,直到到達葉子節點,將葉子節點存放的類別作為決策結果。決策樹可以用於回歸或者分類,下圖是一個分類的例子。
如上圖所示,決策樹把空間分割成不同的區域。
邏輯回歸
邏輯回歸雖然名字是回歸,但是卻是個分類演演算法。因為它和SVM類似是一個二分類,數學模型是預測1或者0的機率。所以我說回歸和分類其實本質上是一致的。這裡要註意邏輯回歸和線性SVM分類的區別。

樸素貝葉斯
當資料量相當大的時候,樸素貝葉斯方法是一個很好的選擇。15年我在公司給小夥伴們分享過bayers方法,可惜speaker deck被牆了,如果有興趣可以自行想辦法。

如上圖所示,大家可以思考一下左下的綠點對整體分類結果的影響。
KNN
KNN分類可能是所有機器學習演演算法裡最簡單的一個了。

如上圖所示,K=3,滑鼠移動到任何一個點,就找到距離該點最近的K個點,然後,這K個點投票,多數表決獲勝。就是這麼簡單。
推薦閱讀
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多技術資料。

求知若渴, 虛心若愚—Stay hungry, Stay foolish

