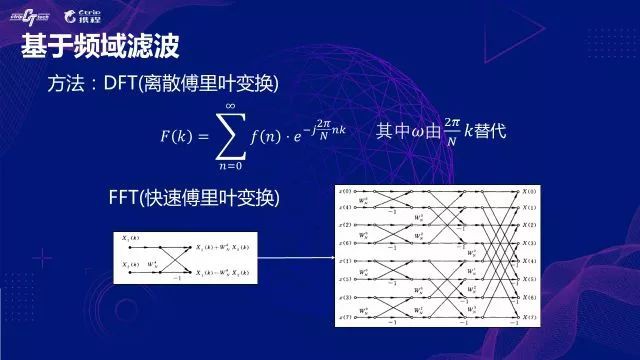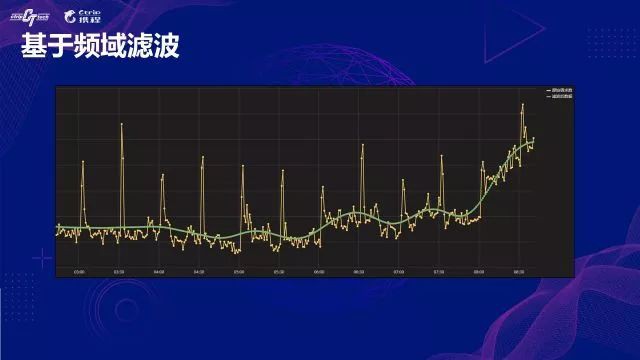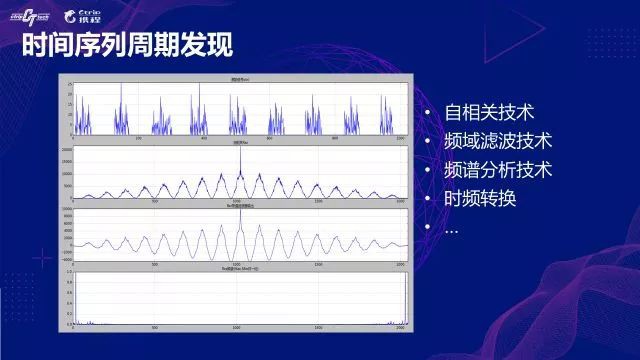


-
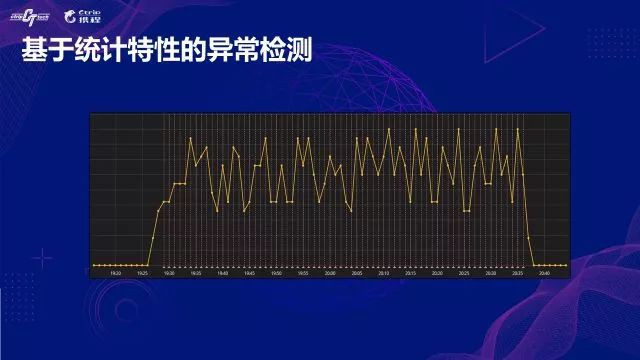
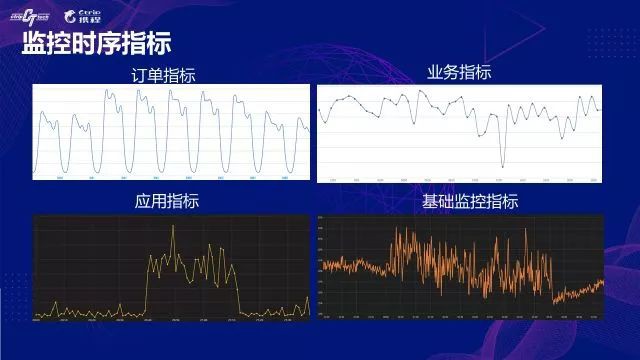
訂單指標,也是最核心的監控指標,從監控曲線看有非常強的週期性;
-
應用指標和業務指標,大部分是開發基於框架中介軟體做的一些業務埋點。這些指標正常情況下都會表現的很平穩,當有突髮狀況或異常時,指標會劇烈抖動;
-
基礎監控指標,涉及底層各種型別的監控,包括伺服器CPU、記憶體、磁碟IO、網路IO等指標,以及DB、Redis、代理、網路等相關監控指標。
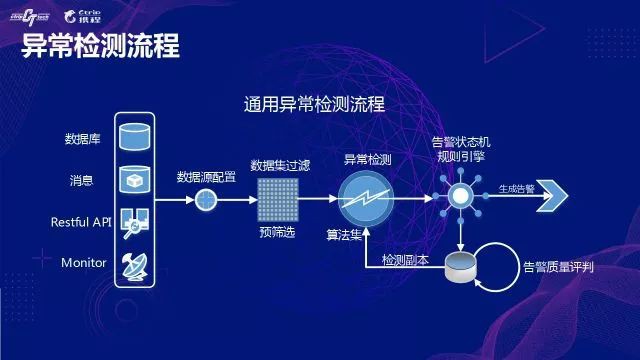
-
資料源配置:對於一個通用的異常檢測平臺而言,待檢測的時序資料源可能存在不同的物理介質上,也可能是不同的系統中,為了避免對業務系統的侵入性,異常檢測的邏輯一般都是旁路來實現。首先需要將這些不同系統、不同儲存介質中的時序進行採集(資料源可以是DB、HBase、訊息、API、以及特定的監控系統等),在異常檢測平臺中儲存一段副本資料,留作構建資料倉庫使用。
-
資料集過濾:實踐中我們並不會對所有的資料集都配置智慧檢測演演算法,是因為在很多真實的場景中,有些指標很難用被異常檢測的演演算法檢測,主要的原因是資料質量不高,有演演算法經歷的道友應該都清楚,資料質量的好壞決定了演演算法效果的上限。我們會事先配置了一個資料集過濾模組,過濾掉一些資料質量不高的資料集。實現的原理主要是基於資料集的一階和二階統計量、偏度、峰度、資訊熵等指標,將滿足一定統計特性的資料集篩選到後續流程處理。
-
異常檢測演演算法集:針對預篩選環節過濾得到的資料集,我們準備了常見的異常檢測演演算法集,這些演演算法大都是通用的機器學習演演算法根據實際情況和需要做了一定的二次定製,更詳細的介紹我們會在接下來的內容中展開。
-
告警狀態機:這個模組的功能主要是將時序異常轉變為一個有效的告警。從事過監控告警的道友應該有類似的共識,異常資料從統計角度看只是離群較遠的分佈,能不能當做一個業務告警處理呢?大部分時候是需要業務同事來給出規則,將一個無語意的時序異常轉變成一個業務告警。例如將連續三次或五次的時序異常轉變成一個業務告警,連續多少次之後恢復告警,同時告警狀態機會維護每個告警的生命週期,避免重覆的告警通知等。
-
告警質量評價:告警質量的評估可以說是最具挑戰性的工作了。一方面,我們檢測的指標基本都是無標註的資料集,產生的告警準確與否必須有人來判斷;另一方面,因為應用數量眾多,每天的告警量也非常的龐大,靠人力逐個去判斷幾乎是不可能實現的。如果不做告警質量的評價,就無法形成閉環,演演算法效果也無法得到後續的最佳化與提升。目前的評價一方面是靠專家經驗抽樣判斷,一方面是郵件將告警推送給監控負責人,透過一定的獎勵機制調動使用者來反饋告警結果。