
導讀:搜尋“西紅柿”,你不但能知道它的營養功效、熱量,還能順帶學會煲個牛腩、炒個雞蛋!搜尋引擎何時變成“暖男”了?原來背後有“知識圖譜”這個強大的秘密武器。
作為近年來搜尋領域和自然語言處理領域的熱點,知識圖譜正引領著搜尋引擎向知識引擎的轉變。在阿裡的“神馬搜尋”中,知識圖譜及其相關技術的廣泛應用不僅能幫助使用者找到最想要的資訊,更能讓使用者有意想不到的知識收穫。
背景簡介
為了不斷提升搜尋體驗,神馬搜尋的知識圖譜與應用團隊,一直在不斷探索和完善圖譜的構建技術。其中,開放資訊抽取(Open Information Extraction),或稱通用資訊抽取,旨在從大規模無結構的自然語言文字中抽取結構化資訊。它是知識圖譜資料構建的核心技術之一,決定了知識圖譜可持續擴增的能力。
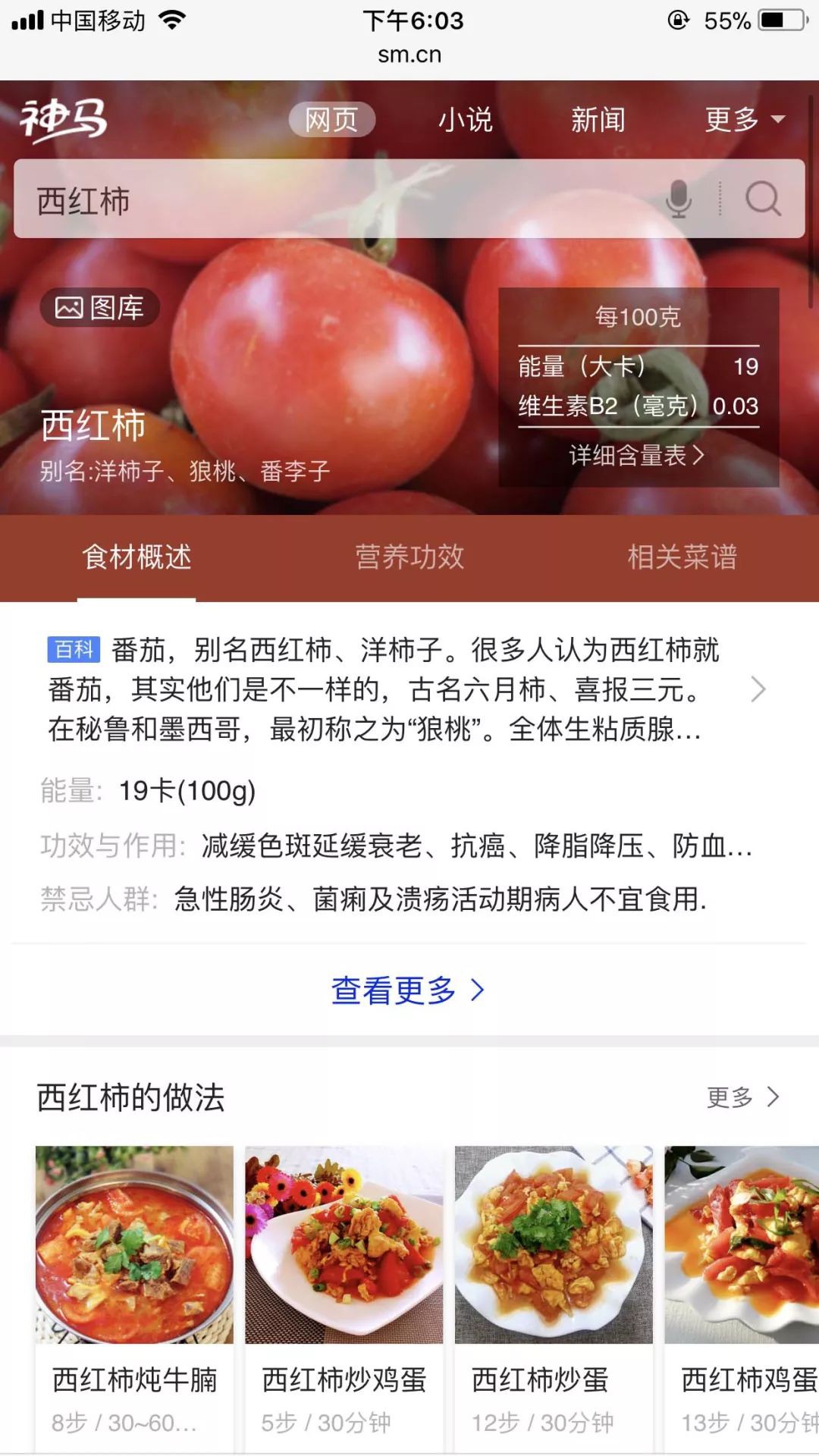
“神馬搜尋”介面
本文聚焦於開放資訊抽取中的重要子任務——關係抽取,首先對關係抽取的各種主流技術進行概述,而後結合業務中的選擇與應用,重點介紹了基於DeepDive的方法,並詳述它在神馬知識圖譜資料構建工作中的應用進展。
關係抽取概述
關係抽取技術分類
現有的關係抽取技術主要可分為三種 :
-
有監督的學習方法 :該方法將關係抽取任務當做分類問題,根據訓練資料設計有效的特徵,從而學習各種分類模型,然後使用訓練好的分類器預測關係。該方法的問題在於需要大量的人工標註訓練語料,而語料標註工作通常非常耗時耗力。
-
半監督的學習方法 :該方法主要採用Bootstrapping進行關係抽取。對於要抽取的關係,該方法首先手工設定若干種子實體,然後迭代地從資料從抽取關係對應的關係模板和更多的實體。
-
無監督的學習方法 :該方法假設擁有相同語意關係的物體對擁有相似的背景關係資訊。因此可以利用每個物體對對應背景關係資訊來代表該物體對的語意關係,並對所有物體對的語意關係進行聚類。
這三種方法中,有監督學習法因為能夠抽取並有效利用特徵,在獲得高準確率和高召回率方面更有優勢,是目前業界應用最廣泛的一類方法。
遠端監督演演算法
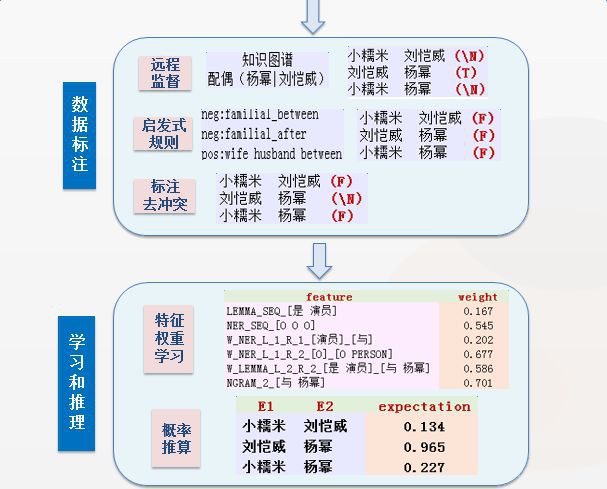
為了打破有監督學習中人工資料標註的侷限性,Mintz等人提出了遠端監督(Distant Supervision)演演算法,該演演算法的核心思想是將文字與大規模知識圖譜進行物體對齊,利用知識圖譜已有的物體間關係對文字進行標註。遠端監督基於的基本假設是:如果從知識圖譜中可獲取三元組R(E1,E2)(註:R代表關係,E1、E2代表兩個物體),且E1和E2共現與句子S中,則S表達了E1和E2間的關係R,標註為訓練正例。
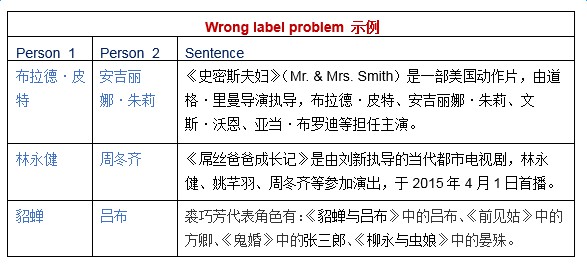
遠端監督演演算法是目前主流的關係抽取系統廣泛採用的方法,也是該領域的研究熱點之一。該演演算法很好地解決了資料標註的規模問題,但它基於的基本假設過強,會引入大量噪音資料。例如,從知識圖譜獲取三元組:創始人(喬布斯,蘋果公司),下表句1和句2正確表達了該關係,但句3和句4並沒有表達這樣的關係,因此對句3和句4應用基本假設時會得到錯誤的標註資訊。這個問題通常稱為 the wrong label problem。

出現 the wrong label problem 的根本原因,是遠端監督假設一個物體對只對應一種關係,但實際上物體對間可以同時具有多種關係,如上例中還存在CEO(喬布斯,蘋果公司)的關係,物體對間也可能不存在通常定義的某種關係,而僅因為共同涉及了某個話題才在句中共現。
為了減小 the wrong label problem 的影響,學術界陸續提出了多種改進演演算法,主要包括:
-
基於規則的方法:透過對wrong label cases的統計分析,新增規則,將原本獲得正例標註的wrong label cases直接標為負例,或透過分值控制,抵消原有的正標註。
-
基於圖模型的方法:構建因子圖(factor graph)等能表徵變數間關聯的圖模型,透過對特徵的學習和對特徵權重的推算減小wrong label cases對全域性的影響。
-
基於多示例學習(multi-instance learning)的方法:將所有包含(E1,E2)的句子組成一個bag,從每個bag對句子進行篩選來生成訓練樣本。此類方法最早提出時假設如果知識圖譜中存在R(E1,E2),則語料中含(E1,E2)的所有instance中至少有一個表達了關係R。一般與無向圖模型結合,計算出每個包中置信度最高的樣例,標為正向訓練示例。該假設比遠端監督的假設合理,但可能損失很多訓練樣本,造成有用資訊的丟失和訓練的不充分。為了能得到更豐富的訓練樣本,又提出了multi-instance multi-labels的方法。該方法的假設是,同一個包中,一個sentence只能表示(E1,E2)的一種關係,也就是隻能給出一個label,但是不同的sentence可以表徵(E1,E2)的不同關係,從而得到不同的label。多label標註的label值不是正或負,而是某一種關係。它為同時挖掘一個物體對的多種關係提供了可能的實現途徑。另一種改進的方法是從一個包中選取多個valid sentences作為訓練集,一般與深度學習方法相結合,這種方法更詳細的講解和實現會安排在後續介紹深度學習模型的章節中。
神馬知識圖譜構建中的關係抽取方法選擇
知識圖譜的資料構建,就資料源而言,分為結構化資料,半結構化資料和無結構資料三類。其中,無結構資料是最龐大、最易獲取的資源,同時也是在處理和利用方面難度最大的資源。神馬知識圖譜構建至今,已經發展為一個擁有近5000萬物體,近30億關係的大規模知識圖譜。在經歷了前期以結構化和半結構化資料為主的領域圖譜構建階段,神馬知識圖譜的資料構建重點已經逐漸轉移為如何準確高效地利用無結構資料進行物體與關係的自動識別與抽取。這一構建策略使得神馬知識圖譜在通用領域的建設和可持續擴增方面有很強的競爭力。
遠端監督演演算法利用知識圖譜的已有資訊,使得有監督學習中所需的大規模文字標註成為可能。一方面,遠端監督在很大程度上提升了有監督學習關係抽取的規模和準確率,為大規模的知識圖譜資料構建和補充提供了可能;另一方面,遠端監督對現有知識圖譜的資料和規模有較強的依賴,豐富的標註資料對機器學習能力的提升有很大幫助。為了充分利用知識圖譜規模和遠端監督學習這種相輔相成的特性,在神馬知識圖譜的現階段資料構建業務中,我們採用了以圖譜現有的大規模物體與關係資料為依託,以遠端監督演演算法為工具的關係抽取技術。
在上一章的綜述中,我們介紹過多種基於遠端監督思想的改進方法。在具體的業務實現中,我們選取了領域內與業務需求最為契合的兩種代表性方法:基於DeepDive的抽取系統和基於深度學習抽取演演算法。兩種方法相輔相成,各有優勢:DeepDive系統較多依賴於自然語言處理工具和基於背景關係的特徵進行抽取,在語料規模的選擇上更為靈活,能進行有針對性的關係抽取,且能方便地在抽取過程中進行人工檢驗和幹預;而深度學習的方法主要應用了詞向量和摺積神經網路,在大規模語料處理和多關係抽取的人物中有明顯的優勢。在下麵的章節中,我們來更詳細地瞭解這兩種方法的實現與應用。
DeepDive系統介紹
DeepDive概述
DeepDive (http://deepdive.stanford.edu/) 是斯坦福大學開發的資訊抽取系統,能處理文字、表格、圖表、圖片等多種格式的無結構資料,從中抽取結構化的資訊。系統集成了檔案分析、資訊提取、資訊整合、機率預測等功能。Deepdive的主要應用是特定領域的資訊抽取,系統構建至今,已在交通、考古、地理、醫療等多個領域的專案實踐中取得了良好的效果;在開放領域的應用,如TAC-KBP競賽、維基百科的infobox資訊自動增補等專案中也有不錯的表現。
DeepDive系統的基本輸入包括:
-
無結構資料,如自然語言文字
-
現有知識庫或知識圖譜中的相關知識
-
若干啟髮式規則
DeepDive系統的基本輸出包括:
-
規定形式的結構化知識,可以為關係(物體1,物體2)或者屬性(物體,屬性值)等形式
-
對每一條提取資訊的機率預測
DeepDive系統執行過程中還包括一個重要的迭代環節,即每輪輸出生成後,使用者需要對執行結果進行錯誤分析,透過特徵調整、更新知識庫資訊、修改規則等手段幹預系統的學習,這樣的互動與迭代計算能使得系統的輸出不斷得到改進。
DeepDive系統架構和工作流程
DeepDive的系統架構如下圖所示,大致分為資料處理、資料標註、學習推理和互動迭代四個流程:

資料處理
1、 輸入與切分
在資料處理流程中,DeepDive首先接收使用者的輸入資料,通常是自然語言文字,以句子為單位進行切分。同時自動生成文字id和每個句子在文字中的index。doc_id + sentence_index 構成了每個句子的全域性唯一標識。
2、 NLP標註
對於每個切分好的句子,DeepDive會使用內嵌的Stanford CoreNLP工具進行自然語言處理和標註,包括token切分,詞根還原、POS標註、NER標註、token在文字中的起始位置標註、依存文法分析等。
3、 候選物體對提取
根據需要抽取的物體型別和NER結果,首先對物體mentions進行定位和提取,而後根據一定的配對規則生成候選物體對。需要特別註意,在DeepDive中,每一個物體mention的標定都是全域性唯一的,由doc_id、sentence_index以及該mention在句子中的起始和結束位置共同標識。因此,不同位置出現的同名的物體對(E1,E2)將擁有不同的(E1_id,E2_id),最終的預測結果也將不同。
4、 特徵提取
該步驟的目的是將每一個候選物體對用一組特徵表示出來,以便後續的機器學習模組能夠學習到每個特徵與所要預測關係的相關性。Deepdive內含自動特徵生成模組DDlib,主要提取基於背景關係的語意特徵,例如兩個物體mention間的token sequence、NER tag sequence、物體前後的n-gram等。Deepdive也支援使用者自定義的特徵提取演演算法。
資料標註
在資料標註階段,我們得到了候選物體對以及它們對應的特徵集合。在資料標註階段,我們將運用遠端監督演演算法和啟髮式規則,對每個候選物體對進行label標註,得到機器學習所需的正例和負例樣本。
1、 遠端監督
實現遠端監督標註,首先需要從已知的知識庫或知識圖譜中獲取相關的三元組。以婚姻關係為例,DeepDive從DBpedia中獲取已有的夫妻物體對。若候選物體對能在已知的夫妻物體對中找到匹配對映時,該候選對標記為正例。負例的標註針對需要抽取的不同關係有不同的可選方法。例如可以將沒有在知識庫中出現的物體對標註為負例,但在知識庫收入不完整的情況下該方法會引入噪音負例;也可以用知識庫中互斥關係下的實體來做負例標註,例如父母-子女關係,兄弟姐妹關係,都與婚姻關係互斥,用於標註負例基本不會引入噪音。
2、 啟髮式規則
正負樣本的標註還可以透過使用者編寫啟髮式規則來實現。以抽取婚姻關係為例,可以定義如下規則:
-
Candidates with person mentions that are too far apart in the sentence are marked as false.
-
Candidates with person mentions that have another person in between are marked as false.
-
Candidates with person mentions that have words like “wife” or “husband” in between are marked as true.
使用者可以透過預留的user defined function介面,對啟髮式規則進行編寫和修改。
3、 Label衝突的解決
當遠端監督生成和啟髮式規則生成的label衝突,或不同規則生成的label產生衝突時,DeepDive採用majority vote演演算法進行解決。例如,一個候選對在DBpedia中找到了對映,label為1,同時又滿足2中第2條規則,得到label 為-1,majority vote對所有label求和:sum = 1 – 1 = 0,最終得到的label為doubt。
學習與推理
透過資料標註得到訓練集後,在學習與推理階段,Deepdive主要透過基於因子圖模型的推理,學習特徵的權重,並最終得到對候選三元組為真的機率預測值。
因子圖是一種機率圖模型,用於表徵變數和變數間的函式關係,藉助因子圖可以進行權重的學習和邊緣機率的推算。DeepDive系統中,因子圖的頂點有兩種,一種是隨機變數,即提取的候選物體對,另一種是隨機變數的函式,即所有的特徵和根據規則得到的函式,比方兩個物體間的距離是否大於一定閾值等。因子圖的邊表示了物體對和特徵及規則的關聯關係。
當訓練文字的規模很大,涉及的物體眾多時,生成的因子圖可能非常複雜龐大,DeepDive採用吉布斯取樣(Gibbs sampling)進行來簡化基於圖的機率推算。在特徵權重的學習中,採用標準的SGD過程,並根據吉布斯取樣的結果預測梯度值。為了使特徵權重的獲得更靈活合理,除了系統預設的推理過程,使用者還可以透過直接賦值來調整某個特徵的權重。篇幅關係,更詳細的學習與推理過程本文不做展開介紹,更多的資訊可參考DeepDive的官網。
互動迭代
迭代階段保證透過一定的人工幹預對系統的錯誤進行糾正,從而使得系統的準召率不斷提升。互動迭代一般包括以下幾個步驟:
1、 準召率的快速估算
-
準確率:在P集中隨機挑選100個,看為TP的比例。
-
召回率:在輸入集中隨機挑選100個positive case,看有多少個落在計算出的P集中。
2、 錯誤分類與歸納
將得到的每個extraction failure(包括FP和FN)按錯誤原因進行分類和歸納,並按錯誤發生的頻率進行排序,一般而言,最主要錯誤原因包括:
-
在候選集生成階段沒有捕獲應捕獲的物體,一般是token切分、token拼接或NER問題
-
特徵獲取問題,沒能獲取到區分度高的特徵
-
特徵計算問題,區分度高的特徵在訓練中沒有獲得相應的高分(包括正負高分)
3、 錯誤修正
根據錯誤原因,透過新增或修改規則、對特徵進行新增或刪除、對特徵的權重進行調整等行為,調整系統,重新執行修改後的相應流程,得到新的計算結果。
神馬知識圖譜構建中的DeepDive應用與改進
在瞭解了DeepDive的工作流程之後,本章將介紹我們如何在神馬知識圖譜的資料構建業務中使用DeepDive。為了充分利用語料資訊、提高系統執行效率,我們在語料處理和標註、輸入規模的控制、輸入質量的提升等環節,對DeepDive做了一些改進,並將這些改進成功運用到業務落地的過程中。
中文NLP標註
NLP標註是資料處理的一個重要環節。DeepDive自帶的Stanford CoreNLP工具主要是針對英文的處理,而在知識圖譜的應用中,主要的處理需求是針對中文的。因此,我們開發了中文NLP標註的外部流程來取代CoreNLP,主要變動如下:
-
使用Ali分詞代替CoreNLP的token切分,刪除詞根還原、POS標註和依存文法分析,保留NER標註和token在文字中的起始位置標註。
-
token切分由以詞為單位,改為以物體為單位。在NER環節,將Ali分詞切碎的token以物體為粒度重新組合。例如分詞結果“華盛頓”、“州立”、“大學”將被組合為“華盛頓州立大學”,並作為一個完整的物體獲得“University”的NER標簽。
-
長句的切分:文字中的某些段落可能因為缺少正確的標點或包含眾多併列項等原因,出現切分後的句子長度超過一定閾值(如200個中文字元)的情況,使NER步驟耗時過長。這種情況將按預定義的一系列規則進行重新切分。
主語自動增補
資料處理環節的另一個改進是添加了主語自動補充的流程。以中文百科文字為例,統計發現,有將近40%的句子缺少主語。如下圖劉德華的百科介紹,第二段中所有句子均缺少主語。

主語的缺失很多時候直接意味著候選物體對中其中一個物體的缺失,這將導致系統對大量含有有用資訊的句子無法進行學習,嚴重影響系統的準確率和召回率。主語的自動補充涉及兩方面的判斷:
-
主語缺失的判斷
-
缺失主語的新增
由於目前業務應用中涉及的絕大多數是百科文字,缺失主語的新增採用了比較簡單的策略,即從當前句的上一句提取主語,如果上一句也缺失主語,則將百科標題的NER結果作為要新增的主語。主語缺失的判斷相對複雜,目前主要採用基於規則的方法。假設需要提取的候選對(E1, E2)對應的物體型別為(T1, T2),則判定流程如下圖所示:

具體的主語補充實體和處理過程舉例如下:

以百科文字為例,經實驗統計,上述主語自動補充演演算法的準確率大約在92%。從關係抽取的結果來看,在所有的錯誤抽取case中,由主語增補導致的錯誤比例不超過2%。
基於關係相關關鍵詞的輸入過濾
DeepDive是一個機器學習系統,輸入集的大小直接影響系統的執行時間,尤其在耗時較長的特徵計算和學習推理步驟。在保證系統召回率的前提下,合理減小輸入集規模能有效提升系統的執行效率。
假設需要提取的三元組為R(E1, E2)且(E1, E2)對應的物體型別為(T1, T2)。DeepDive的預設執行機制是:在資料處理階段,提取所有滿足型別為(T1,T2)的物體對作為候選,不考慮背景關係是否有表達關係R的可能性。例如,抽取婚姻關係時,只要一個句子中出現大於等於兩個的人物物體,該句子就會作為輸入參與系統整個資料處理、標註和學習的過程。以下五個例句中,除了句1,其它4句完全不涉及婚姻關係:

尤其當句中的兩個人物物體無法透過遠端監督獲取正例或負例標簽時,此類輸入無法在學習環節為系統的準確率帶來增益。為減小此類輸入帶來的系統執行時間損耗,我們提出了以下改進演演算法:

實驗證明,利用改進演演算法得到的輸入集規模有顯著的減小,以百科文字的抽取為例,婚姻關係的輸入集可縮小至原輸入集的13%,人物和畢業院校關係的輸入集可縮小至原輸入集的36%。輸入集的縮小能顯著減少系統執行時間,且實驗證明,排除了大量doubt標註物體候選對的幹擾,系統的準確率也有較大幅度的提升。
需要指出的是,雖然在輸入環節透過關係相關關鍵詞進行過濾減小輸入規模,能最有效地提高系統執行效率(因為跳過了包含特徵提取在內的所有後續計算步驟),但該環節的過濾是以句子為單位,而非作用於抽取的候選物體對。來看一個婚姻關係提取的多人物示例:
-
除了孫楠、那英等表演嘉賓盛裝出席外,擔任本場音樂會監製的華誼兄弟總裁王中磊先生、馮小剛導演和夫人徐帆,以及葛優、宋丹丹、李冰冰等演藝明星也一一現身紅毯,到場支援此次音樂會。
因為含有婚姻關係相關的關鍵詞“夫人”,該句子將被保留為系統輸入。從該句提取的多個人物候選物體對需要依靠更完善的啟髮式規則來完成進一步的標註和過濾。
物體對到多物體的擴充套件
關係抽取的絕大部分任務僅涉及三元組的抽取。三元組一般有兩種形式,一種是兩個物體具有某種關係,形如R(E1, E2),例如:婚姻關係(劉德華,朱麗倩);另一種是物體的屬性值,形如P(E,V),例如:身高(劉德華,1.74米)。DeepDive預設的關係抽取樣式都是基於三元組的。但在實際應用中,有很多複雜的關係用三元組難以完整表達,例如,人物的教育經歷,包括人物、人物的畢業院校、所學專業、取得學位、畢業時間等。這些複雜的多物體關係在神馬知識圖譜中用複合型別來表示。因此,為使抽取任務能相容複合型別的構建時,我們對DeepDive的程式碼做了一些修改,將候選物體對的提取,擴充套件為候選物體組的提取。程式碼修改涉及主抽取模組中的app.ddlog、底層用於特徵自動生成的DDlib和udf中的map_entity_mention.py、extract_relation_features.py等檔案。下圖展示了一個擴充套件後的物體組抽取實體,抽取關係為(人物、所在機構、職位):

應用DeepDive的資料構建工作
本節首先給出一個輸入示例以及該示例在DeepDive執行過程中每一步的輸出結果,如下圖所示。透過這個示例,我們可以對DeepDive各模組的功能和輸出有更直觀的認識。

為了更詳細地瞭解DeepDive的應用和改進演演算法的效果,以下我們給出一個具體的婚姻關係抽取任務的相關執行資料。
下表顯示了該抽取任務在資料處理階段各步驟的的耗時和產出數量:

在資料標註的遠端監督階段,我們除了使用知識圖譜中已有的夫妻關係做正例標註,還使用了已有的父母-子女關係和兄弟姐妹關係做負例標註,得到正例數千個,正負標註候選物體的比例約為1:2。

在DeepDive系統中,遠端監督的wrong label problem可以依靠合理編寫的啟髮式規則得到一定程度的糾正。觀察婚姻關係的wrong label樣例,我們發現較大比例的wrong label是夫妻物體以某種合作形式(如合作演出、合作演唱、合作著書等)共現在一個句子中,夫妻物體有一個出現在書名號中時,也容易發生誤判。例如:
類似的觀察和總結可以編寫成啟髮式規則,依靠從規則得到的負標註抵償遠端監督得到的正標註,減小系統在學習和推理時的偏差。
雖然啟髮式規則的編寫大多依靠專家知識或人工經驗完成,但規則的完善和擴充可以依靠某些自動機制來輔助實現。例如,規則定義:句中出現“P_1和P_2結婚”,則(P_1,P_2)得到正標註。根據對“和”和“結婚”等token的擴充套件,我們可以得到“P_1與P_2結婚”、“P_1和P2婚後”、“P_1和P_2的婚禮”等類似應該標註為正的語境。這裡,token的擴充套件可以透過word2vec演演算法加人工過濾實現。下表給出了該抽取任務中用到的規則和相應的統計資料。整個資料標註過程耗為14m21s。

學習與推理過程耗時約38m50s。我們隨機截取了部分知識圖譜未收錄的預測物體對的輸出結果展示如下:

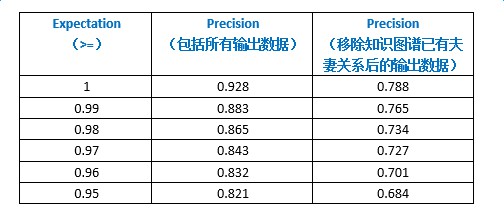
對於系統的準確率,我們取expectation為 [0.95,1][0.95,1] 區間內的輸出結果進行分段統計,統計結果如下列圖表所示:
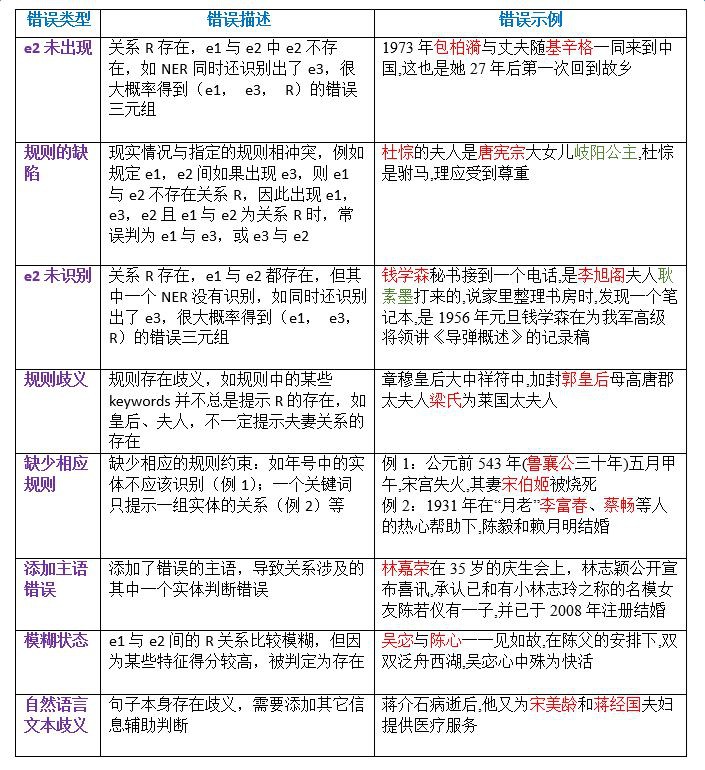
對系統預測的錯誤樣例進行分析,我們總結了幾種錯誤型別,下表按照出現頻率從高到低,給出了錯誤描述和錯誤示例:
系統召回率的計算相比準確率的計算更為複雜,在語料規模較大的情況下,準確估算召回率將耗費大量的人力。我們採用了抽樣檢測的方式來估算召回率,具體實踐了以下三種方法(統計中expectation均取>=0.95):
-
抽樣含有某個指定物體的所有sentences,計算召回:含物體 “楊冪” 的sentences共78例,含 (楊冪, 劉愷威)物體對的sentences共13例,人工判斷其中9例描述了該物體對的婚姻關係,其中5例被召回,召回率為0.556。
-
用於遠端監督正例標註的知識圖譜物體對超過4000對,統計表明,其中42.7%的物體對出現在了語料中,26.5%的物體對被召回,召回率為0.621。
-
輸入集隨機挑選100例positive cases,其中49例的expectation值>=0.95, 召回率為0.49。
基於DeepDive的關係抽取研究目前已較為完整,並已經在神馬知識圖譜的構建業務中落地。目前在資料構建中的應用涉及人物、歷史、組織機構、圖書、影視等多個核心領域,已抽取關係包括人物的父母、子女、兄弟姐妹、婚姻、歷史事件及人物的合稱、圖書的作者、影視作品的導演和演員、人物的畢業院校和就業單位等。以百科全量語料為例,每個關係抽取任務候選sentence集合的規模在80w至1000w,經改進演演算法過濾,輸入規模在15w至200w之間,生成的候選物體對規模在30w至500w之間。系統每輪迭代執行的時間在1小時至8小時之間,約經過3-4輪迭代可產出準確率和召回率都較高的資料給運營審核環節。系統執行至今,已累計產出候選三元組近3千萬。
除此之外,基於深度學習模型的關係抽取技術及其在神馬知識圖譜資料構建中的應用,我們也在不斷探索和實踐。明天,阿裡妹將繼續為大家介紹相關的技術進展和業務落地過程中遇到的一些挑戰,敬請關註哦。
參考文獻
[1]. 林衍凱、劉知遠,基於深度學習的關係抽取
[2]. Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao. 2015. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In EMNLP. 1753–1762.
[3]. Guoliang Ji, Kang Liu, Shizhu He, Jun Zhao. 2017. Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions. Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence
[4]. Siliang Tang, Jinjian Zhang, Ning Zhang, Fei Wu, Jun Xiao, Yueting Zhuang. 2017. ENCORE: External Neural Constraints Regularized Distant Supervision for Relation Extraction. SIGIR’17
[5]. Zeng, D.; Liu, K.; Chen, Y.; and Zhao, J. 2015. Distant supervision for relation extraction via piecewise convolutional neural networks. EMNLP.
[6]. Riedel, S.; Yao, L.; and McCallum, A. 2010. Modeling relations and their mentions without labeled text. In Machine Learning and Knowledge Discovery in Databases. Springer. 148–163.
[7]. Ce Zhang. 2015. DeepDive: A Data Management System for Automatic Knowledge Base Construction. PhD thesis.
[8]. Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; and Weld, D. S. 2011. Knowledge-based weak supervision for information extraction of overlapping relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, 541–550. Association for Computational Linguistics.
[9]. Surdeanu, M.; Tibshirani, J.; Nallapati, R.; and Manning, C. D. 2012. Multi-instance multi-label learning for relation extraction. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 455–465. Association for Computational Linguistics.
[10]. Shingo Takamatsu, Issei Sato and Hiroshi Nakagawa. 2012. Reducing Wrong Labels in Distant Supervision for Relation Extraction. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, pages 721–729
[11]. Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J.; et al. 2014. Relation classification via convolutional deep neural network. In COLING, 2335–2344.
[12]. Ce zhang, Cheistopher Re; et al. 2017. Communications of the ACM CACM Homepage archive
Volume 60 Issue 5, Pages 93-102
[13]. Mintz, M.; Bills, S.; Snow, R.; and Jurafsky, D. 2009. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2, 1003–1011. Association for Computational Linguistics.
[14]. http://deepdive.stanford.edu/

 #榜 單 公 布 #
#榜 單 公 布 #
2017年度最值得讀的AI論文 | NLP篇 · 評選結果公佈
2017年度最值得讀的AI論文 | CV篇 · 評選結果公佈
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot02)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 加入社群一起刷論文
