導讀:Java是最廣泛使用的程式語言之一。近日,Oracle釋出了Java的最新版本,Java10。在這個版本中,Oracle引入109項新特性,其中最引人註目的就是Java的新Jit編譯器Graal。在這個編譯器中,我們可以使用Java來做Java的Jit編譯器。本文作者詳細介紹了該特性,十分值得一讀。
Introduction
對於大部分應用開發者來說,Java編譯器指的是JDK自帶的javac指令。這一指令可將Java源程式編譯成.class檔案,其中包含的程式碼格式我們稱之為Java bytecode(Java位元組碼)。這種程式碼格式無法直接執行,但可以被不同平臺JVM中的interpreter解釋執行。由於interpreter效率低下,JVM中的JIT compiler(即時編譯器)會在執行時有選擇性地將執行次數較多的方法編譯成二進位制程式碼,直接執行在底層硬體上。Oracle的HotSpot VM便附帶兩個用C++實現的JIT compiler:C1及C2。
與interpreter,GC等JVM的其他子系統相比,JIT compiler並不依賴於諸如直接記憶體訪問的底層語言特性。它可以看成一個輸入Java bytecode輸出二進位制碼的黑盒,其實現方式取決於開發者對開發效率,可維護性等的要求。Graal是一個以Java為主要程式語言,面向Java bytecode的編譯器。與用C++實現的C1及C2相比,它的模組化更加明顯,也更加容易維護。Graal既可以作為動態編譯器,在執行時編譯熱點方法;亦可以作為靜態編譯器,實現AOT編譯。在Java 10中,Graal作為試驗性JIT compiler一同釋出(JEP 317)。這篇文章將介紹Graal在動態編譯上的應用。有關靜態編譯,可查閱JEP 295或Substrate VM。
Tiered Compilation
在介紹Graal前,我們先瞭解HotSpot中的tiered compilation。前面提到,HotSpot集成了兩個JIT compiler — C1及C2(或稱為Client及Server)。兩者的區別在於,前者沒有應用激進的最佳化技術,因為這些最佳化往往伴隨著耗時較長的程式碼分析。因此,C1的編譯速度較快,而C2所編譯的方法執行速度較快。在Java 7前,使用者需根據自己的應用場景選擇合適的JIT compiler。舉例來說,針對偏好高啟動效能的GUI使用者端程式則使用C1,針對偏好高峰值效能的伺服器端程式則使用C2。
Java 7引入了tiered compilation的概念,綜合了C1的高啟動效能及C2的高峰值效能。這兩個JIT compiler以及interpreter將HotSpot的執行方式劃分為五個級別:
-
level 0:interpreter解釋執行
-
level 1:C1編譯,無profiling
-
level 2:C1編譯,僅方法及迴圈back-edge執行次數的profiling
-
level 3:C1編譯,除level 2中的profiling外還包括branch(針對分支跳轉位元組碼)及receiver type(針對成員方法呼叫或類檢測,如checkcast,instnaceof,aastore位元組碼)的profiling
-
level 4:C2編譯
其中,1級和4級為接受狀態 — 除非已編譯的方法被invalidated(通常在deoptimization中觸發),否則HotSpot不會再發出該方法的編譯請求。

上圖列舉了4種編譯樣式(非全部)。通常情況下,一個方法先被解釋執行(level 0),然後被C1編譯(level 3),再然後被得到profile資料的C2編譯(level 4)。如果編譯物件非常簡單,虛擬機器認為透過C1編譯或透過C2編譯並無區別,便會直接由C1編譯且不插入profiling程式碼(level 1)。在C1忙碌的情況下,interpreter會觸發profiling,而後方法會直接被C2編譯;在C2忙碌的情況下,方法則會先由C1編譯並保持較少的profiling(level 2),以獲取較高的執行效率(與3級相比高30%)。
Graal可替換C2成為HotSpot的頂層JIT compiler,即上述level 4。與C2相比,Graal採用更加激進的最佳化方式,因此當程式達到穩定狀態後,其執行效率(峰值效能)將更有優勢。
早期的Graal同C1及C2一樣,與HotSpot是緊耦合的。這意味著每次編譯Graal均需重新編譯HotSpot。JEP 243將Graal中依賴於HotSpot的程式碼分離出來,形成Java-Level JVM Compiler Interface(JVMCI)。該介面主要提供如下三種功能:
-
響應HotSpot的編譯請求,並分發給Java-Level JIT compiler
-
允許Java-Level JIT compiler訪問HotSpot中與JIT compilation相關的資料結構,包括類,欄位,方法及其profiling資料等,並提供這些資料結構在Java層面的抽象
-
提供HotSpot codecache的Java抽象,允許Java-Level JIT compiler部署編譯完成的二進位制程式碼
綜合利用這三種功能,我們可以將Java-Level編譯器(不侷限於Graal)整合至HotSpot中,響應HotSpot發出的level 4的編譯請求並將編譯後的二進位制程式碼部署到HotSpot的codecache中。此外,單獨利用上述第三種功能可以繞開HotSpot的編譯系統 — Java-Level編譯器將作為上層應用的類庫直接部署編譯後的二進位制程式碼。Graal自身的單元測試便是依賴於直接部署而非等待HotSpot發出編譯請求;Truffle亦是透過此機制部署編譯後的語言直譯器。
Graal v.s. C2
前面提到,JIT Compiler並不依賴於底層語言特性,它僅僅是一種程式碼形式到另一種程式碼形式的轉換。因此,理論上任意C2中以C++實現的最佳化均可以在Graal中透過Java實現,反之亦然。事實上,許多C2中實現的最佳化均被移植到Graal中,如近期由其他開發者貢獻的String.compareTo intrinsic的移植。當然,侷限於C++的開發/維護難度(個人猜測),許多Graal中被證明有效的最佳化並沒有被成功移植到C2上,這其中就包含Graal的inlining演演算法及partial escape analysis(PEA)。
Inlining是指在編譯時識別callsite的標的方法,將其方法體納入編譯範圍並用其傳回結果替換原callsite。最簡單直觀的例子便是Java中常見的getter/setter方法 — inlining可以將一個方法中呼叫getter/setter的callsite最佳化成單一記憶體訪問指令。Inlining被業內戲稱為最佳化之母,其原因在於它能引發更多最佳化。然而在實踐中我們往往受制於編譯單元大小或編譯時間的限制,無法無限制地遞迴inline。因此,inlining的演演算法及策略很大程度上決定了編譯器的優劣,尤其是在使用Java 8的stream API或使用Scala語言的場景下。這兩種場景對應的Java bytecode包含大量的多層單方法呼叫。
Graal擁有兩個inliner實現。社群版的inliner採用的是深度優先的搜尋方式,在分析某一方法時,一旦遇到不值得inline的callsite時便回溯至該方法的呼叫者。Graal允許自定義策略以判斷某一callsite值不值得inline。預設情況下,Graal會採取一種相對貪婪的策略,根據callsite的標的方法的大小做出相應的決定。Graal enterprise的inliner則對所有callsite進行加權排序,其加權演演算法取決於標的方法的大小以及可能引發的最佳化。當標的方法被inline後,其包含的callsite同樣會進入該加權佇列中。這兩種搜尋方式都較為適合擁有多層單方法呼叫的應用場景。
Escape analysis(逃逸分析,EA)是一類識別物件動態範圍的程式分析。編譯器中常見的應用有兩類:如果物件僅被單一執行緒訪問,則可去除針對該物件的鎖操作;如果物件為堆分配且僅被單一方法訪問(inlining的重要性再次體現),則可將該物件轉化成棧分配。後者通常伴隨著scalar replacement,即將對物件欄位的訪問替換成對虛擬區域性運算元的訪問,從而進一步將物件由棧分配轉換成虛擬分配。這不僅節省了原本用於存放物件essay-header的記憶體空間,而且可以在register allocator的幫助下將(部分)物件欄位存放在暫存器中,在節省記憶體的同時提高執行效率(記憶體訪問轉換成暫存器訪問)。

Java中常見的for-each loop是EA的一大標的客戶。我們知道for-each loop會呼叫被遍歷物件的iterator方法,傳回一個實現interface Iterator的物件,並利用其hasNext及next介面進行遍歷。Java collections中的容器類(如ArrayList)通常會構造一個新的Iterator實體,其生命週期侷限於該for-each loop中。如若Iterator實體的建構式以及hasNext,next方法呼叫(連同它們方法體中以this為receiver的方法呼叫,如checkForComodification())都被inline,EA會認為該實體沒有逃逸,並採取棧分配及scalar replacement。
 理想情況下,Foo.bar會被最佳化成如下程式碼:
理想情況下,Foo.bar會被最佳化成如下程式碼:
 HotSpot的C2便已應用控制流無關的EA實現scalar replacement。而Graal的PEA則在此基礎上引入了控制流資訊,將所有的堆分配操作虛擬化,並僅在物件確定逃逸的分支materialize。與C2的EA相比,PEA分析效率較低,但能夠在物件沒有逃逸的分支上實現scalar replacement。如下例所示,如果then-branch的執行機率為1%,那麼被PEA最佳化後的程式碼在99%的情況下並不會執行堆分配,而C2的EA則100%會執行堆分配。另一個典型的例子是渲染引擎Sunflow — 在執行DaCapo benchmark suite所附帶的預設workload時,Graal的PEA判定約27%的堆分配(共佔700M)可被虛擬化。該數字遠超C2的EA。
HotSpot的C2便已應用控制流無關的EA實現scalar replacement。而Graal的PEA則在此基礎上引入了控制流資訊,將所有的堆分配操作虛擬化,並僅在物件確定逃逸的分支materialize。與C2的EA相比,PEA分析效率較低,但能夠在物件沒有逃逸的分支上實現scalar replacement。如下例所示,如果then-branch的執行機率為1%,那麼被PEA最佳化後的程式碼在99%的情況下並不會執行堆分配,而C2的EA則100%會執行堆分配。另一個典型的例子是渲染引擎Sunflow — 在執行DaCapo benchmark suite所附帶的預設workload時,Graal的PEA判定約27%的堆分配(共佔700M)可被虛擬化。該數字遠超C2的EA。

Using Graal
在Java 10 (Linux/x64, macOS/x64)中,預設情況下HotSpot仍使用C2,但透過向java命令新增-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler引數便可將C2替換成Graal。
 Oracle Labs GraalVM是由Oracle Labs直接釋出的JDK版本。它基於Java 8,並且囊括了Graal enterprise。如果對原始碼感興趣,可直接簽出Graal社群版的GitHub repo。原始碼的編譯需藉助mx工具及labsjdk(註:請下載頁面最下方的labsjdk,直接使用GraalVM可能會導致編譯問題)。
Oracle Labs GraalVM是由Oracle Labs直接釋出的JDK版本。它基於Java 8,並且囊括了Graal enterprise。如果對原始碼感興趣,可直接簽出Graal社群版的GitHub repo。原始碼的編譯需藉助mx工具及labsjdk(註:請下載頁面最下方的labsjdk,直接使用GraalVM可能會導致編譯問題)。
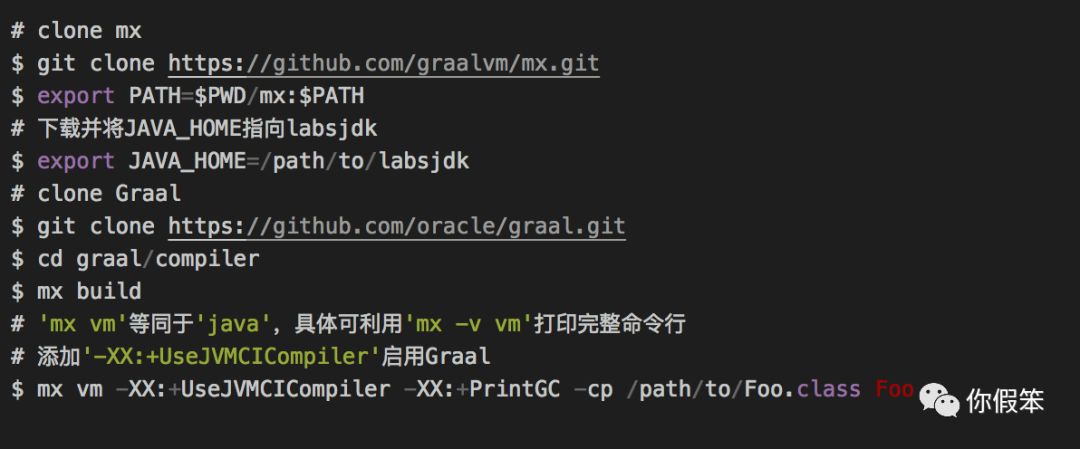 在graal/compiler目錄下使用mx eclipseinit,mx intellijinit或mx netbeansinit可分別生成Eclipse,IntelliJ或NetBeans的工程配置檔案。
在graal/compiler目錄下使用mx eclipseinit,mx intellijinit或mx netbeansinit可分別生成Eclipse,IntelliJ或NetBeans的工程配置檔案。
廣告時間
沒辦法,好多朋友要找我免費打點廣告,這次還不趁機說說估計會找我麻煩了,有需要的自取,打擾各位了
-
前不久我們釋出的JVM引數分析產品XXFox,可以一鍵生成JVM引數,並能檢查你們現有JVM引數是否存在一些問題,有沒有體驗過的可以體驗一下,http://xxfox.perfma.com,可以點選下麵的【原文閱讀】進去體驗
-
我們團隊Base在杭州,希望能圍繞JVM做一些效能分析相關的產品,有興趣的小夥伴請加入我們
-
相關閱讀:
本文作者二維碼

